在某客户日志数据迁移到火山引擎使用 ELK 生态的案例中,由于客户反馈之前 Logstash 经常发生数据丢失和收集性能较差的使用痛点,我们尝试使用 Flink 替代了传统的 Logstash 来作为日志数据解析、转换以及写入 ElasticSearch 的组件,得到了该客户的认可,并且已经成功协助用户迁移到火山。目前,Flink 已经支持该业务高峰期 1000+k/s 的数据写入。
本文主要介绍 Logstash 的使用痛点以及迁移到 Flink 的优势,探索在 ELK 生态中,Flink 替换 Logstash 的更多可能,推动用户从 EL(Logstash)K 迁移到 EF(Flink)K。

Logstash 简介
ELK 是一套开源的日志及数据监控和分析系统,主要是三个组件的简称:Elasticsearch, Logstash and Kibana,功能涵盖了从日志收集、解析、查询、分析、可视化等完整的解决方案。
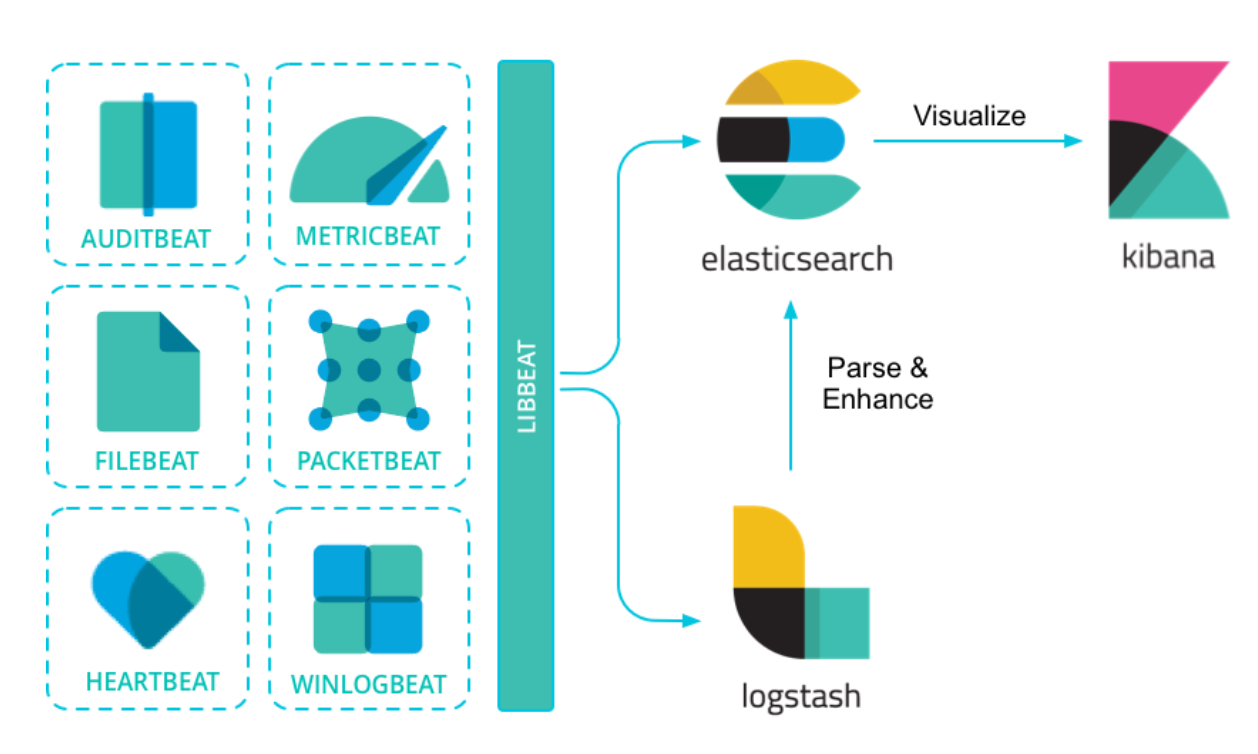
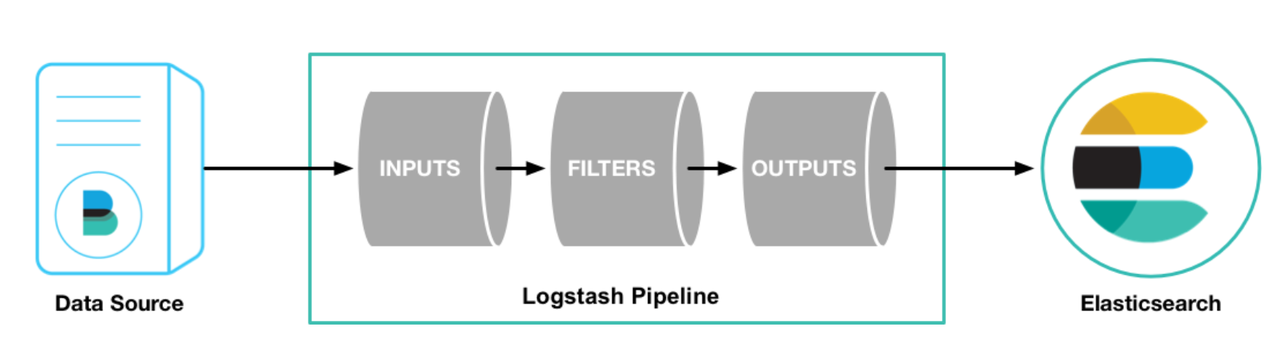
上图描述了 ELK 里各组件的关系,基于 libbeat 框架的各种 beats 工具将日志及各种数据进行收集,可以直接写入 ES,也可以先写入到 Logstash 进行解析和处理再写入到 ES。如下图所示,Logstash 主要包括三个部分:
-
输入插件:负责从各种不同的 source 读取数据,如文件、beats、Kafka等;
-
过滤插件:负责按照指定的配置修改和处理数据,如 grok 插件可以从固定日志格式中提取对应信息,drop 插件可以丢失诸如 debug 日志等能力;
-
输出插件:负责将结果数据输出,如将处理后的日志数据写入 ES 中。
Logstash 使用痛点
数据易丢失
Logstash 默认使用内存作为写入数据的缓存,一旦发生重启或者异常退出的时候,这部分数据就会发生丢失。虽然 Logstash 也提供了持久化队列来解决这个问题,但是由于数据仍然是写入机器磁盘中,当发生单机故障的时候,数据同样也会丢失。同时,数据周期性的落盘也会对数据的处理性能带来巨大的影响。
排查成本高
当日志数据格式不符合规范(如非标准 Json)造成丢失数据较多的情况时,需要在数据收集、数据解析、写 ES 等全链路排查数据丢失的原因,一般需要查看机器日志,收集、处理节点较多的时候,排查成本也比较高。
除了日志数据本身不规范外,当由于其他原因导致数据不能正确处理的其他情况,比如写 ES 各种异常,这部分数据也极易发生丢失,也需要查看日志进行跟踪和定位。虽然 Logstash 单独提供了死信队列来处理这些情况,但是在这个链路丢失的数据仍然有排查的成本。
收集、解析性能差
Logstash 提供的各种插件基本都是用 Ruby 实现的,虽然 Logstash 本身也运行在 Java 的 JVM 上,并通过 JRuby 将各种插件也跑在 JVM 上,但是相比 Flink 100% Java 语言运行和执行效率会更低一些。
当开启持久化队列(为了保证数据尽可能少丢失),由于数据需要频繁写磁盘,Logstash 处理性能会进一步降低。同时,Logstash 处理性能较差也是业界的一大共识。
不支持资源动态扩缩容
由于 Logstash 本身的资源部署不支持动态扩缩容,会造成低峰期较大的资源浪费。在该客户的案例中,业务高峰期的日志数据和活动期间的日志数据是在低峰期数据的 24 倍左右(高峰期 100w+ QPS,低峰期 50k QPS),且呈周期性变化。因此实际在业务低峰期,使用很少的资源就能够保证日志数据的收集和解析,所以支持资源动态扩缩容是必须且必要的。
Flink 使用优势
数据处理支持“at-least-once”语义
Flink 基于状态引入分布式 checkpoint 机制,用于保证数据消费的“at-least-once”语义。其中状态保存通过定期持久化到远端可靠存储(HDFS)来保证状态不丢失。
需要说明的是,Flink 本身基于状态是能够做到严格意义上的“exactly-once”语义的,即消费和处理的不丢不重。如果 ES 支持了主键的配置,也就是相同主键写入是幂等的情况下,则能在全链路做到“exactly-once”语义。
在该客户的案例中,我们通过工具读 Kafka 来统计写入条数,跟实际 Flink 写入 ES 的条数进行对比,证明了数据消费的“at-least-once”语义,解决了客户在友商上使用 Logstash 经常发生数据丢失的痛点。
灵活的异常数据处理
对于 Kafka 中解析失败的数据(比如格式为非 Json 的数据),在该客户的案例中,我们支持了这部分的异常数据写入独立的 ES 索引,同时标识数据写入原因(非标准 Json);对于写 ES 异常失败的数据,我们同样会将这部分数据写入独立的 ES 索引,并且记录写 ES 失败的原因,比如字段数超 1000,数据类型和模板定义的不一致等。
可以方便用户对异常日志数据做治理,如该客户推所有的上游业务日志标准 Json 化写入 Kafka 等。相对的,在该客户使用原友商的 Lostash 写入 ES 的时候,这部分的数据丢失不仅不易排查(甚至不易知晓),而且也难以治理(丢失了写 ES 失败的原因)。
高吞吐、低延迟的处理性能
Flink 作为当前最热的流式处理引擎,支持高吞吐、低延迟的处理日志数据,对数据处理能够达到秒级的延迟且经过业内在其他 Kafka 数据更复杂处理场景的大量验证,稳定而可靠。
资源自动扩缩容
在字节 Serverless Flink 中,我们也将支持资源随着写入 QPS 的动态调整,能够节省较大的资源。目前,该功能已经在字节内部得到了实际验证,在资源利用上取得了较大的收益。
更复杂的数据分析能力
相较于传统的 ELK 链路,在 Logstash 中对日志数据进行简单的数据格式匹配、内容替换等处理,Flink 还支持更强大的数据分析和处理,支持事件和业务处理时间,支持窗口计算、聚合、去重等。能对日志数据做更强大的数据处理和分析,将处理数据写入 ES 后,能实现 OLAP 数据查询和分析。
这部分数据处理和分析的能力也在字节内部得到了广泛的应用,为业务带来了很多实际的收益。
Flink vs Logstash 总结
对 Logstash 进行简单介绍后,结合该客户的案例,这里对比下 Flink 和 Logstash 的优劣:
| Logstash | Flink | 实际用户案例 | |
| 数据一致性 | 数据消费和写入均可能发生数据丢失,且开启持久化队列后对性能影响较大 | 基于状态提供严格意义上的“at-least-once”语义 |
|
| 异常数据处理 | 需要单独配置死信队列和对应的处理私信队列的逻辑,且处理失败原因不易追踪 | 提供数据解析失败和写 ES 失败数据单独往独立索引写入的能力,且同时记录处理失败原因,方便上游对日志进行治理 |
|
| 处理性能 | Ruby 语言本身执行效率低,且开启持久化队列后性能下降明显 | 纯 Java 执行语言,在大数据处理场景得到了广泛的验证,具有高吞吐、低延迟的特点 |
|
| 弹性扩缩容 | 无 | (未来)提供自动弹性扩缩容机制,在业务低峰期节省资源和成本 |
|
| 复杂数据分析 | 不支持,官方插件仅支持基本日志字段处理 | 提供基于处理时间和事件时间,窗口计算等强大的处理语义和逻辑 | 暂未使用 |
【火山引擎流式计算 Flink版】
火山引擎流式计算 Flink版是脱胎于字节跳动最佳实践的新一代全托管、云原生实时计算平台。一套代码轻松搞定流批一体,助力企业将大数据平台向云原生、实时化、智能化方向升级。
目前,流式计算 Flink版 新人首购专享活动正在进行中。注册用户首次购买 Flink 产品包年包月,即可享受首月4折优惠,欢迎咨询体验。

「了解更多产品信息」
参考资料
ELK Introduction — Log Consolidation with ELK Stack 1.2 documentation
Filebeat overview | Filebeat Reference [8.10] | Elastic
How Logstash Works | Logstash Reference [8.10] | Elastic
Persistent queues (PQ) | Logstash Reference [8.10] | Elastic
http://thomaslau.xyz/2019/08/14/2019-08-14-on_logstash_quiz1/
Mid-uh 对比(图表)