题目:
表:
Scores+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | score | decimal | +-------------+---------+ 在 SQL 中,id 是该表的主键。 该表的每一行都包含了一场比赛的分数。Score 是一个有两位小数点的浮点值。查询并对分数进行排序。排名按以下规则计算:
- 分数应按从高到低排列。
- 如果两个分数相等,那么两个分数的排名应该相同。
- 在排名相同的分数后,排名数应该是下一个连续的整数。换句话说,排名之间不应该有空缺的数字。
按
score降序返回结果表。查询结果格式如下所示。
来源:力扣(LeetCode)
链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
示例:
示例 1:
输入:
Scores 表: +----+-------+ | id | score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+
输出:+-------+------+ | score | rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
解法:
先对score列降序排序,接着删除id列,然后使用rank函数排名。
知识点:
1.DataFrame.rank(axis=0, method='average', numeric_only=None, na_option='keep', ascending=True, pct=False):计算出axis方向上各个data的排名。axis:默认按沿着index方向排名;method有以下选择:
‘average’:默认,在每个组中分配平均排名(组,相同的值就是一个组,下同);
‘min’:对整个组使用最小排名;
‘max’:对整个组使用最大排名;
‘first’:按照值在数据中出现的次序分配排名;
‘dense’:类似于‘min’,但是组间排名总是增加1,而不是一个组中的相等元素的数量;
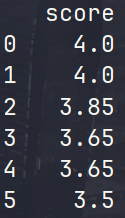
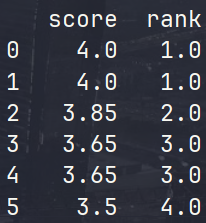
numeric_only:是否只对数值列处理;na_option:用于处理NaN值,'keep':保持NA;'top':升序时给NaN分配最小值;'bottom':升序时给NaN分配最大值;ascending:是否为升序,默认为True;pct:是否为百分数。举例,初始表如下,存在r:
r['rank'] = r.rank(method='dense', ascending=False)
代码:
import pandas as pddef order_scores(scores: pd.DataFrame) -> pd.DataFrame:r = scores.sort_values(['score'], ascending=False, ignore_index=True)del r['id']r['rank'] = r.rank(method='dense', ascending=False)return r