文章目录
- 摘要
- 引言
- 相关工作
- 文档布局的自动标注
- 布局类别
- 标注算法
- PMCOA XML预处理和解析
- PMCOA PDF解析
- 字符串预处理
- PDF-XML匹配算法
- 生成实例分割
- 质量控制
- 数据划分
- 结果
- 基于深度学习的文档分布识别
- 表格检测
- 微调用于不同的领域
- 讨论
- 结论
- 附录
- 论文中的一些英文单词
- 论文中的其他一些专有名词
摘要
- 重要性:识别一个无结构的电子文档中的元素布局并将其转换为计算机可以理解的格式,对于下游的任务非常重要。
- 当前的不足:现有的可以公开获得的用于深度神经网络训练的文档布局数据集都太小,使得所有处理这一类任务的模型都必须使用基于传统图像数据集训练的深度神经网络经过迁移学习获得。
- 本文贡献:提出了一个用于文档布局分析的大型数据集,共包含有超过100万篇PDF文章,超过36万张文档页图片。这些文章中的内容与XML的表示进行了匹配。
- 实验结果:使用该数据集进行训练的神经网络能够准确地检测出电子文档的页面布局,同时预训练好的模型也可以很好地应用于迁移学习。
- 数据集发布网站:https://github.com/ibm-aur-nlp/PubLayNet。
引言
- PDF格式的文件被广泛使用,但是对这种格式文件的自动化处理过程非常复杂。
- 如果通过机器学习(深度学习)的方法训练一个处理PDF文件的模型需要大量的人工标注的数据集,这是一项费时费钱的任务。
- 本文提出了一种可以在大规模PDF数据集上自动标注的方法和一个高质量的PDF文档布局数据集PubLayNet。
- 实验结果表明通过自动标注的数据集训练的模型适合于识别科学文章中的布局,并且在该数据集上预训练的模型的迁移学习后可以达到更好的效果。
相关工作
- 现有的用于文档布局分析的数据集依赖于人工标注,并且都非常小。
文档布局的自动标注
- 数据来源:PubMed Central Open Access(PMCOA)上的文档,这些文档都有PDF和XML两种格式。在自动标注阶段,需要使用到同一个文档的两种不同格式。
布局类别
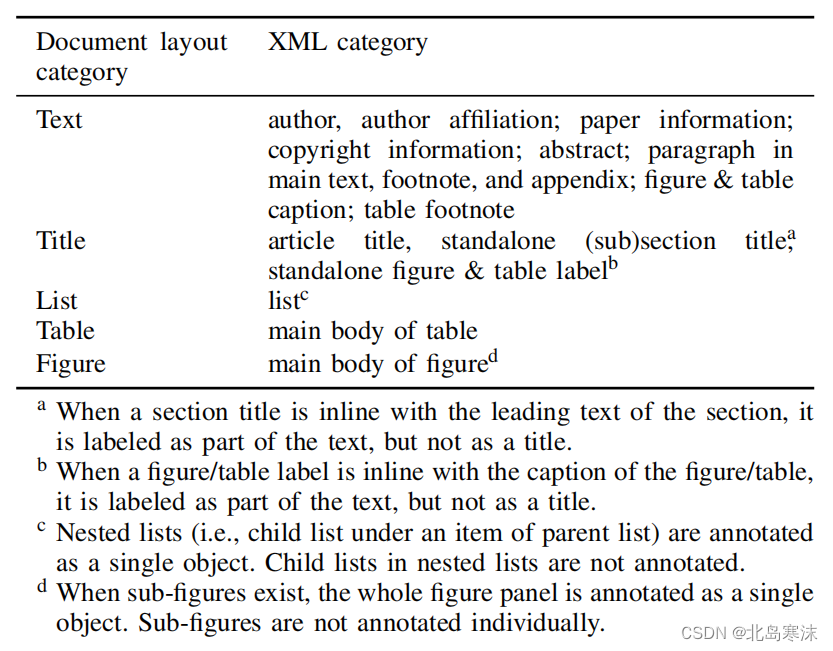
- 文档的XML表示含有很多不同类型的结点,即使对于人类来说,仅仅通过文档图片很难对这些不同类型的结点进行区分。
- 作者们权衡了多个因素,选择了文本、标题、列表、表格和图像五种文档布局元素。
标注算法
- 标注算法概述:首先将PDF文档中的布局元素与XML格式的文档中的结点进行匹配;接着计算PDF文档中布局元素的边界框和分割;XML中的结点名称用于给每个边界框确定类别标签;最后,通过一个质量控制指标将标注过程中的噪音限制到一个很低的水平。
PMCOA XML预处理和解析
- XML预处理:首先移除了XML文档树中不适用匹配的结点标签,确保这些标签不影响结果。
- 将XML树中的节点分为五类:
- 论文标题、摘要、关键词、小节标题和主要文本分为一类,因为这些都是与阅读顺序相同的。
- 版权声明、证件、作者、附属机构、致谢和缩略放在一页,因为这些与PDF文档的阅读顺序不一定相同。
- 图像单独分为一类(包括图像的说明文字和图像本身)。
- 表格单独分为一类(包括表格文字、脚注和表格本身)。
- 列表单独分为一类。
PMCOA PDF解析
作者们将PDF中的元素划分为三大类,分别如下:
- 文本框(用红色标出):由文本行组成。每个文本框都包含文本框中的文本、文本框的边界框和文本框中的文本行。文本行又包含文本行中的文本和文本行的边界框。
- 图像(用绿色标出):由图片组成,每张图片都包含一个边界框。
- 几何图形(用黄色标出):由直线、曲线和矩形组成,每一个几何框都与一个边界框相关联。
字符串预处理
- XML和PDF文件中的字符串都采用Unicode进行编码;
- 为了让XML格式和PDF格式之间的匹配更加稳健,对字符串都进行了KD正则化。
PDF-XML匹配算法
- 通过PDFMiner解析出的PDF内容和XML结点构成的文本之间总是存在微小的差异,因此,作者们借助模糊字符串匹配算法,因为这种算法可以接受较小的差异。
- 使用fuzzysearch包来查找与已知字符串最匹配(也就是距离最近)的字符串,这里的距离是指两个字符串之间的莱文斯坦距离。
- 对于越长的字符串,对匹配的距离要求越高。
生成实例分割
质量控制
- 有一些PDF的解析结果和该文档对应的XML文件之间可能有很大的差距,当差距大于一个阈值时,标注算法也许就不能识别一个文档页中的元素。因此,需要一种方式评价对PDF页标注的好坏并消除PubLayNet中标注的不好的PDF页。
- 标注质量的评价指标:标注出的文本框、图片和几何形状的面积和实际的文本框、图片和几何形状的面积之比。对于非标题页,比值小于99%的PDF页都被移除了(这是一个很高的标准)
数据划分
- 进行标注的PDF文档按照在期刊的层次进行划分,分为训练集、验证集和测试集三部分。
- 对于选入验证集和测试集中的每一本期刊,都要求其页数不能过多,图像、表格和列表不能过少,防止该集合受到某一本期刊的的支配。
- 一半的期刊被随机提取出来作为验证集,另外的一半被提取出来作为测试集。为了消除验证集和测试集中的噪音,其中本质性错误的页被人为移除,略微错误的页被经过人为纠正。
- 不满足选入验证集和测试集要求的期刊被用来生成训练集。
- PubLayNet数据集比现有的任何文档分布数据集大一到两个数量级。
结果
基于深度学习的文档分布识别
- 作者们首先将PDF文档页转换为图像形式,然后分别训练了一个Fast-RCNN模型和Mask-RCNN模型。
- 每一个模型的迭代次数都是18万轮,基础学习率为0.01。学习率在迪12万轮和第16万轮分别下降10倍,使用的批次大小是8。模型在8个GPU上进行训练,每个模型的骨干网络都是在ImageNet上预训练好的ResNet-101。模型的评价指标是MAP和IOU。
- 实验结果表明,Fast-RCNN模型和Mask-RCNN模型都能实现大于0.9的MAP值。
- 模型在识别表格和图像上的准确度高于识别文本、标题和列表的准确度。另外,模型识别标题的准确度最低。
- 作者们认为模型效果仍然可以提升的另一个原因是PubLayNet数据集中的噪音,并承诺将提高这个数据集的质量。
表格检测
- ICDAR 2013表格竞赛是最著名的PDF文档表格检测大赛之一。
- 作者们根据自己的所获得的PDF文档也创建了一个包含表格的PDF页数据集,并且分别使用这些数据集训练了一个Fast-RCNN模型和Mask-RCNN模型,然后使用170张由比赛方提供的PDF页进行微调。
- 微调过程的配置:初始学习率设置为0.001,每迭代10轮学习率降低十倍,总共迭代200轮。
- 微调后的Fast-RCNN模型在ICDAR 2013的评测结果中,取得了目前为止最优秀的结果,精确率达到0.972。
微调用于不同的领域
- 人工标注了2131份健康保险公司的总结计划描述PDF文件(SPD)。
- 分别使用预训练好的Fast-RCNN和Mask-RCNN模型进行微调,使用五折交叉验证比较结果。
- 使用了三种微调方式,分别是使用在ImageNet上预训练好的模型初始化骨干网络、使用在COCO上预训练好的模型初始化整个网络和使用在PubLayNet上预训练好的模型初始化整个网络。另外,还比较了不进行微调的,直接使用PubLayNet预训练好的网络。
- 结果中,不经过微调的模型的效果显著低于其他预训练好的模型的微调结果,微调能够很好的提升结果。
- 三种都经过了微调的模型中,总体而言基于PubLayNet进行微调的模型具有最好的效果。
- 另外,作者们还发现对于表格类型,微调带来的识别性能提升是最小的。
讨论
- 自动标注过程表现最差的一种类型:作者们发现,文章的标题标注过程是表现最差的一部分,这是因为在不同文章中标题的展示方式不一样所引起的。
- 为了使得PubLayNet能够适用于更多的领域,,作者们验证了训练集的期刊种类已经足够丰富使得模型能够对未见过的期刊布局进行很好的预测;对于其他类型的PDF文件,仍然可以通过迁移学习得到很好的效果。
结论
- 自动生成了文档布局标注数据集中目前最大的数据集,PubLayNet。
- 基于PubLayNet训练的最先进的目标检测神经网络在生物医学文章的布局识别上取得了很好的效果。
- 使用PubLayNet预训练好的目标检测模型能够在健康保险文档的布局元素识别中起到帮助。
- 作者们公开了数据集的github网址。
- 未来工作:使用PMCOA作为数据获取来源,为其他的文档分析问题提供大的数据集。
附录
论文中的一些英文单词
- parse:语法分析。
- ubiquitous:无处不在的。
- heuristic:启发式的。
- schema:概要。
- distinctive:独特的。
- redundancy:冗余。
- heterogeneity:异质性。
- partition:分割。
- prestigious:有声望的。
- moderate:不严重的。
- discrepancy:差异。
- inline:内联。
- Levenshtein distance:莱文斯坦距离,用于衡量两个字符串之间的距离。
- miscellaneous:各种各样的。
- polygon:多边形。
- fuzzy:模糊的。
- canonical:经典的。
- aggregate:总计。
- placement:安置。
- Creative Commons license:知识共享许可协议。
论文中的其他一些专有名词
- XML:可扩展标记语言,一种用于编码文档的标记语言。XML文件格式是一种结构和内容的描述方式,用于存储和传输数据。它广泛应用于各种领域,包括网络传输、数据存储、配置文件等。XML文件的基本结构包括标签(tags)和元素(elements)。标签用于定义元素,并且通常成对出现,包括开始标签和结束标签。元素是标签所包围的数据。
- PubMed Central(PMC):美国国立卫生研究院(NIH)旗下的国立医学图书馆(NLM)建立的一个生物医学和生命科学期刊文献全文数据库。该数据库由NLM下属的美国国家生物技术信息中心(NCBI)负责开发与维护。PMC于2000年2月起向全球公众免费开放。
- PDFMiner:美国国立卫生研究院(NIH)旗下的国立医学图书馆(NLM)建立的一个生物医学和生命科学期刊文献全文数据库。该数据库由NLM下属的美国国家生物技术信息中心(NCBI)负责开发与维护。PMC于2000年2月起向全球公众免费开放。