概念:
批量处理数据是指在一个事务场景中处理大量数据。
在应用程序中难以避免进行批量操作,Hibernate提供了以下方式进行批量处理数据:
(1)使用HQL进行批量操作 数据库层面 executeUpdate()
(2)使用JDBC API进行批量操作 数据库层面
(3)使用Session进行批量操作 会进缓存
1.使用HQL进行批量操作
HQL可以查询数据,也可以批量插入、更新和删除数据。HQL批量操作实际上直接在数据库中完成,处理的数据不需要加载到Session缓存中。使用Query接口的executeUpdate()方法执行用于插入、更新和删除的HQL语句。
01.批量插入数据
@Test//03.HQL 批量添加public void multiInsertTest(){String hql="insert into Dept(deptName) select d.deptName||d.deptNo from Dept d where d.deptNo>0";session.createQuery(hql).executeUpdate();}


02.批量修改
@Test//03.HQL 批量修改public void multiUpdateTest(){String hql="update Dept set deptName=:name where deptNo>2";session.createQuery(hql).setParameter("name","财务部").executeUpdate();}

03.批量删除
![]()
@Test//03.HQL 批量删除public void multiDeleteTest(){String hql="delete from Dept d where d.deptNo>:deptNo";session.createQuery(hql).setParameter("deptNo",20).executeUpdate();}

2.使用JDBC API进行批量操作
@Test//04.JDBC API 批量修改public void insertTest(){Work work=new Work() {public void execute(Connection connection) throws SQLException {PreparedStatement ps = connection.prepareStatement("update DEPT set deptName='业务部'where DEPTNO>?");ps.setInt(1,1);ps.executeUpdate();}};//sessionsession.doWork(work);}
操作前: 操作后:

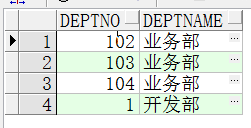
注意:该方式使用的连接依然是最初的连接对象,并且命令对象依然是根据连接创建的,注意这里是SQL语句,不是HQL语句
3.使用Session进行批量操作
使用Session对象也可以进行批量操作。使用Session对象处理大量持久化对象,需及时从缓存中清空已经处理完毕并且不会再访问的对象。可以在处理完成一个对象或小批量对象后,调用flush()方法强制同步缓存和数据库,然后调用clear()方法清空缓存。
@Testpublic void testAdd(){Emp emp=null;for (int i = 0; i < 10000; i++) {emp=new Emp(i, "emp"+i);session.save(emp);if (i%30==0) {session.flush();session.clear();}}
}