Gitee作业链接:https://gitee.com/zheng-qijian33/crawl_project/tree/master/作业4
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
实验代码
点击查看代码
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver.common.by import Byclass MySpider:headers = {"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/109.0.0.0 Safari/537.36 ""SLBrowser/9.0.3.5211 SLBChan/112")}def __init__(self, url):self.url = urlself.page = 0 # 爬取页数self.section = ["nav_hs_a_board", "nav_sh_a_board", "nav_sz_a_board"] # 要点击的板块的属性self.sectionid = 0 # 当前板块索引def startUp(self):chrome_options = Options()chrome_options.add_argument('--headless') # 无头模式chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')self.driver = webdriver.Chrome(options=chrome_options)self.driver.get(self.url)# 建立与MySQL的连接,并创建三个表来保存三个板块的数据try:print("Connecting to MySQL...")self.con = pymysql.connect(host="localhost",port=3306,user="root",passwd="密码",db="stocks",charset="utf8")self.cursor = self.con.cursor(pymysql.cursors.DictCursor)for stocks_table in self.section:self.cursor.execute(f"DROP TABLE IF EXISTS {stocks_table}")self.cursor.execute(f"""CREATE TABLE {stocks_table} (id INT(4) PRIMARY KEY,StockNo VARCHAR(16),StockName VARCHAR(32),StockQuote VARCHAR(32),Changerate VARCHAR(32),Chg VARCHAR(32),Volume VARCHAR(32),Turnover VARCHAR(32),StockAmplitude VARCHAR(32),Highest VARCHAR(32),Lowest VARCHAR(32),Pricetoday VARCHAR(32),PrevClose VARCHAR(32))""")print("MySQL tables created successfully.")except Exception as err:print(f"Error during MySQL setup: {err}")def closeUp(self):try:self.con.commit()self.con.close()self.driver.quit()print("Spider closed successfully.")except Exception as err:print(f"Error during closing: {err}")def insertDB(self, section, id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover, StockAmplitude, Highest, Lowest, Pricetoday, PrevClose):try:sql = f"""INSERT INTO {section} (id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover,StockAmplitude, Highest, Lowest, Pricetoday, PrevClose) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""self.cursor.execute(sql,(id, StockNo, StockName, StockQuote, Changerate, Chg, Volume,Turnover, StockAmplitude, Highest, Lowest, Pricetoday, PrevClose))except Exception as err:print(f"Error inserting data into MySQL: {err}")def processSpider(self):time.sleep(2)try:tr_elements = self.driver.find_elements(By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr")for tr in tr_elements:id = tr.find_element(By.XPATH, ".//td[1]").textStockNo = tr.find_element(By.XPATH, "./td[2]/a").textStockName = tr.find_element(By.XPATH, "./td[3]/a").textStockQuote = tr.find_element(By.XPATH, "./td[5]/span").textChangerate = tr.find_element(By.XPATH, "./td[6]/span").textChg = tr.find_element(By.XPATH, "./td[7]/span").textVolume = tr.find_element(By.XPATH, "./td[8]").textTurnover = tr.find_element(By.XPATH, "./td[9]").textStockAmplitude = tr.find_element(By.XPATH, "./td[10]").texthighest = tr.find_element(By.XPATH, "./td[11]/span").textlowest = tr.find_element(By.XPATH, "./td[12]/span").textPricetoday = tr.find_element(By.XPATH, "./td[13]/span").textPrevClose = tr.find_element(By.XPATH, "./td[14]").textsection = self.section[self.sectionid]self.insertDB(section, id, StockNo, StockName, StockQuote, Changerate, Chg,Volume, Turnover, StockAmplitude, highest, lowest, Pricetoday, PrevClose)# 爬取前2页if self.page < 2:self.page += 1print(f"第 {self.page} 页已经爬取完成")next_page = self.driver.find_element(By.XPATH, "//div[@class='dataTables_paginate paging_input']/a[2]")next_page.click()time.sleep(10)self.processSpider()elif self.sectionid < 3:# 爬取下一个板块print(f"{self.section[self.sectionid]} 爬取完成")self.sectionid += 1self.page = 0next_section = self.driver.find_element(By.XPATH, f"//li[@id='{self.section[self.sectionid]}']/a")self.driver.execute_script("arguments[0].click();", next_section)time.sleep(10)self.processSpider()except Exception as err:print(f"Error during spider processing: {err}")def executeSpider(self):print("Spider starting...")self.startUp()print("Spider processing...")self.processSpider()print("Spider closing...")self.closeUp()if __name__ == "__main__":url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"spider = MySpider(url)spider.executeSpider()
Gitee作业链接:https://gitee.com/zheng-qijian33/crawl_project/tree/master/作业4
运行结果
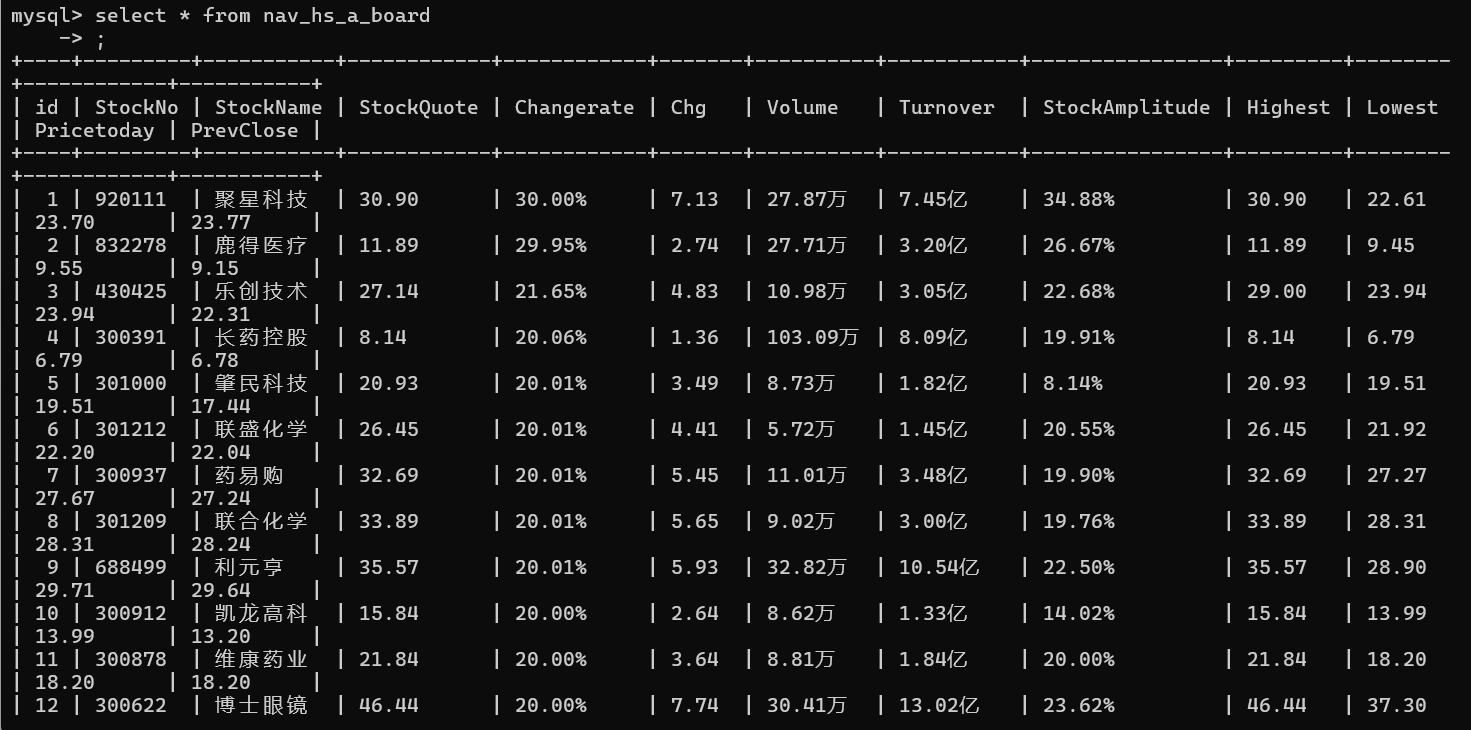
沪深A股:
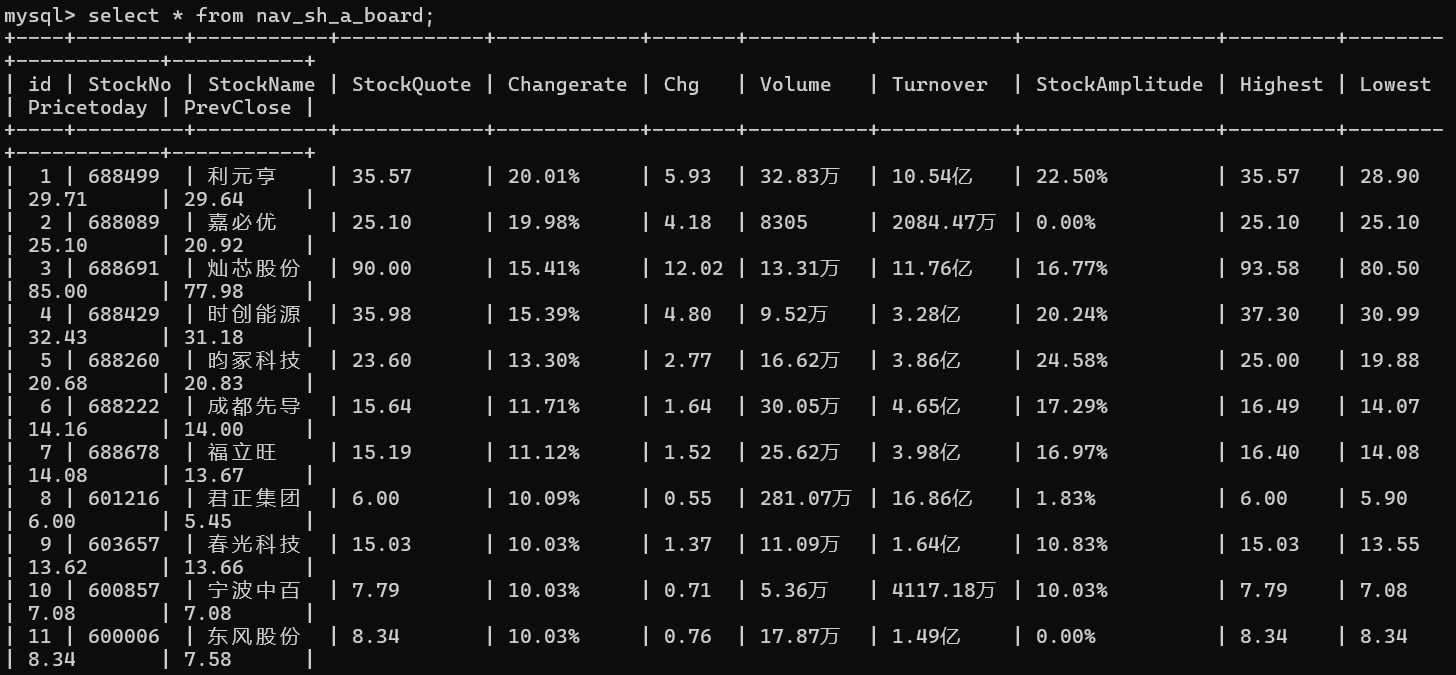
深证A股:
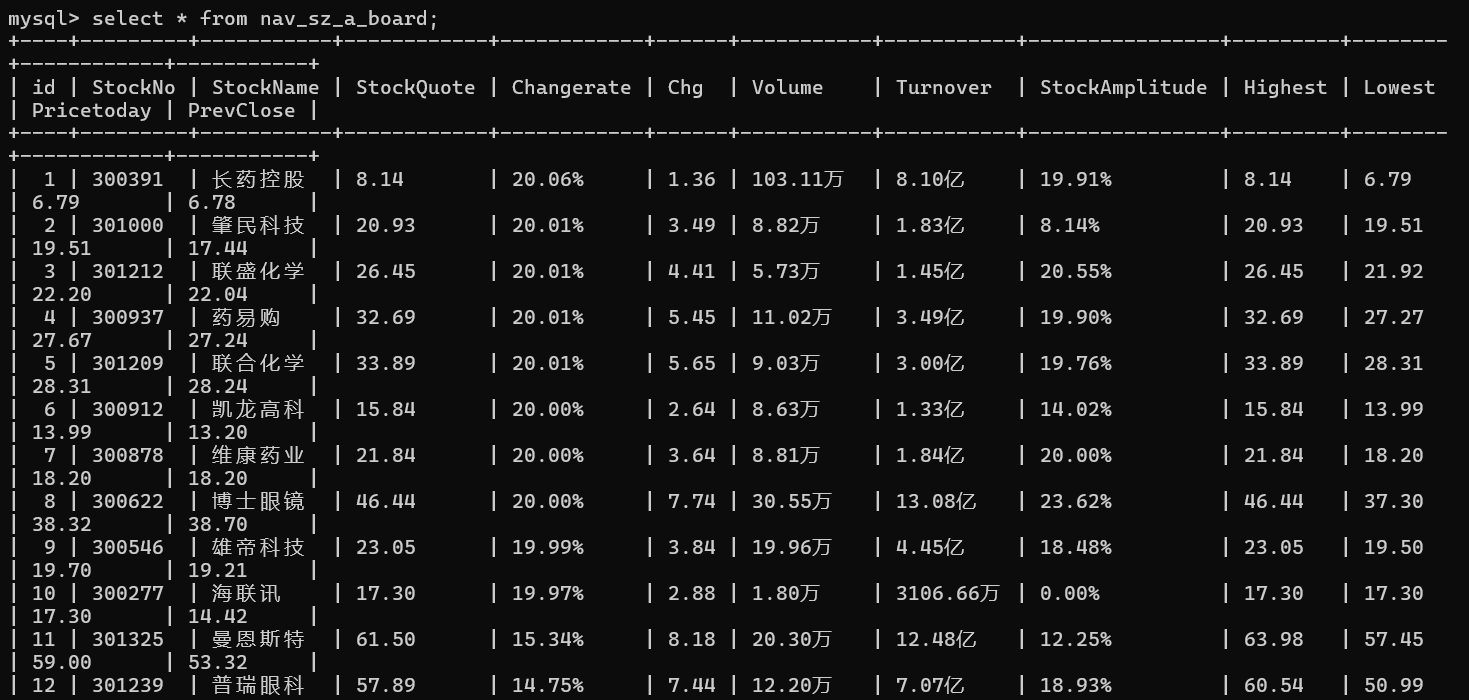
上证A股:
心得体会
编写这段爬虫代码让我深刻体会到,自动化数据抓取需要综合考虑网页结构、元素定位、数据库操作以及异常处理等多个方面。使用 Selenium 的无头模式进行网页操作虽然灵活,但需要合理控制页面加载时间以提高效率。动态切换板块和翻页的逻辑需要仔细处理,确保数据完整性和避免重复抓取。同时,数据库操作的封装和错误处理至关重要,能有效防止数据丢失和程序崩溃。整体而言,代码的模块化和清晰的逻辑结构是实现稳定、高效爬虫的关键。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
实验代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from lxml import etree
import time
import pymysqldriver = webdriver.Chrome()
driver.get("https://www.icourse163.org/")driver.maximize_window()
# 找到登录按钮并点击
button = driver.find_element(By.XPATH,'//div[@class="_1Y4Ni"]/div')
button.click()# 转换到iframe
frame = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)
# 输入账号密码并点击登录
account = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys('手机号')
code = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys('密码')
login_buttom = driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
login_buttom.click()
# 切回正常模式并等待页面加载
driver.switch_to.default_content()
time.sleep(10)
# 导航到搜索页面
search_url = "https://www.icourse163.org/search.htm?search=%20#/"
driver.get(search_url)
time.sleep(10)driver.get('https://www.icourse163.org/search.htm?search=%E8%AE%A1%E7%AE%97%E6%9C%BA#/')
time.sleep(2)
next_button = driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[1]/div[1]/label/div')
next_button.click()
time.sleep(2)js = '''timer = setInterval(function(){var scrollTop=document.documentElement.scrollTop||document.body.scrollTop;var ispeed=Math.floor(document.body.scrollHeight / 100);if(scrollTop > document.body.scrollHeight * 90 / 100){clearInterval(timer);}console.log('scrollTop:'+scrollTop)console.log('scrollHeight:'+document.body.scrollHeight)window.scrollTo(0, scrollTop+ispeed)}, 20)'''
for i in range(1,5):driver.execute_script(js)time.sleep(4)html = driver.page_sourcebs = etree.HTML(html)lis = bs.xpath('/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')for link in lis:a = link.xpath('./div[2]/div/div/div[1]/a[2]/span/text()')if len(a) != 0:if a[0] == '国家精品':b = link.xpath('./div[2]/div/div/div[1]/a[1]/span/text()')[0]c = link.xpath('./div[2]/div/div/div[2]/a[1]/text()')[0]d = link.xpath('./div[2]/div/div/div[2]/a[2]/text()')[0]e = link.xpath('./div[2]/div/div/div[2]/a[2]/text()')[0]f = link.xpath('./div[2]/div/div/div[3]/span[2]/text()')[0]try:g = link.xpath('./div[2]/div/div/div[3]/div/span[2]/text()')[0]except IndexError:g = '已结束'try:h = link.xpath('./div[2]/div/div/a/span/text()')[0]except IndexError:h = '空'mydb = pymysql.connect(host="localhost",user="root",password="密码",database="stocks",charset='utf8mb4')try:with mydb.cursor() as cursor:sql = "INSERT INTO mooc (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)"val = (b, c, d, e, f, g, h)cursor.execute(sql, val)mydb.commit()print(b, c, d, e, f, g, h)except Exception as e:print(f"Error: {e}")finally:mydb.close()next_button = driver.find_element(By.XPATH, '//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]')next_button.click()time.sleep(2)
Gitee作业链接:https://gitee.com/zheng-qijian33/crawl_project/tree/master/作业4
运行结果

心得体会
编写这段代码让我深刻体会到,Selenium 在处理复杂网页交互和数据抓取时非常强大,但也需谨慎使用以避免效率低下。显式等待(WebDriverWait)比 time.sleep 更可靠,确保元素加载完成后再操作,显著提升脚本稳定性。同时,精准的 XPath 或 CSS 选择器是数据抓取的关键,需深入理解网页结构并选择稳定路径。此外,异常处理和日志记录至关重要,能有效防止程序崩溃并提供调试信息,使脚本更健壮和易于维护。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
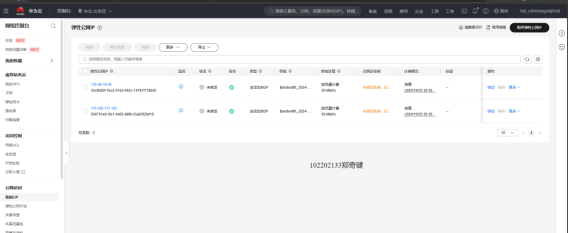
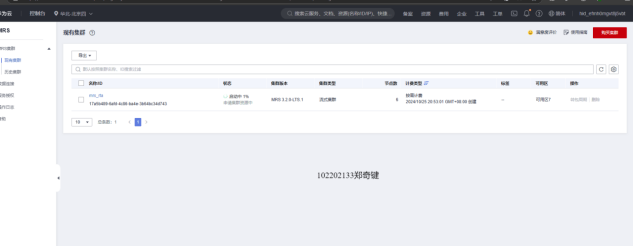
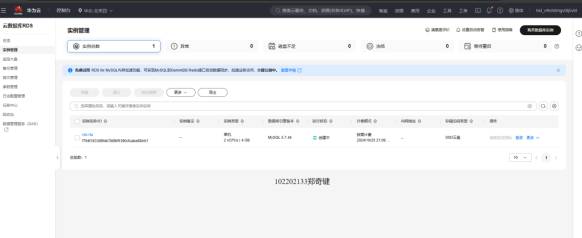
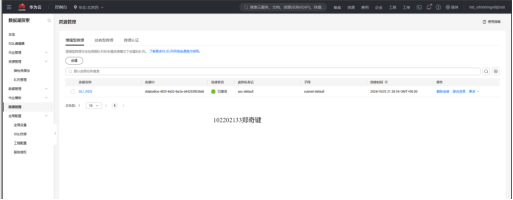
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
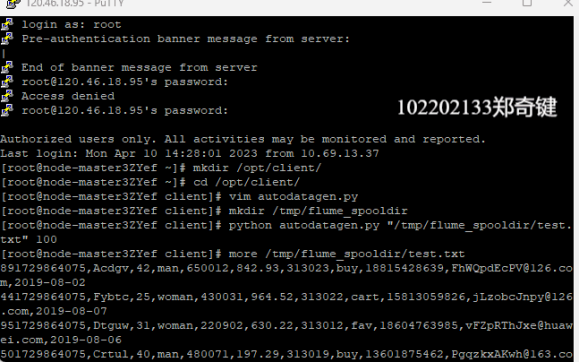
任务二:配置Kafka
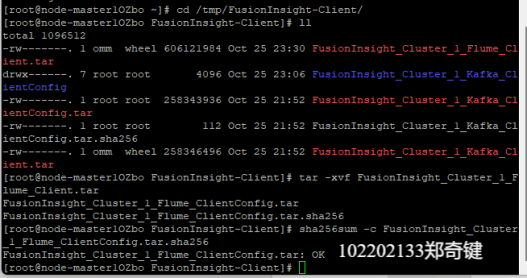
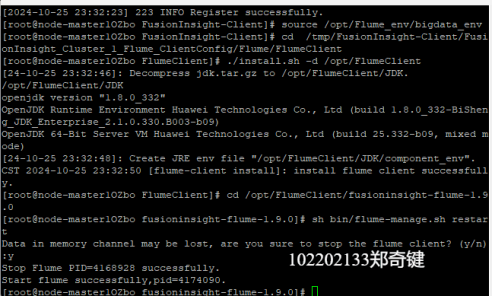
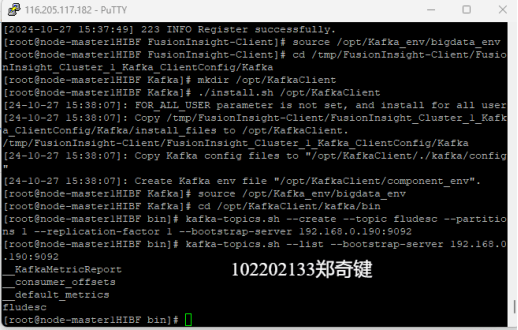
任务三: 安装Flume客户端
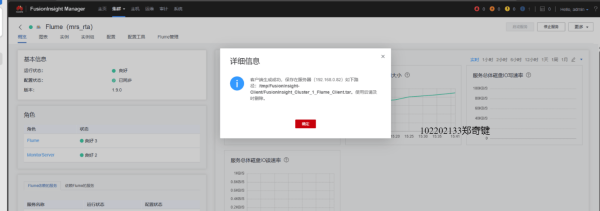
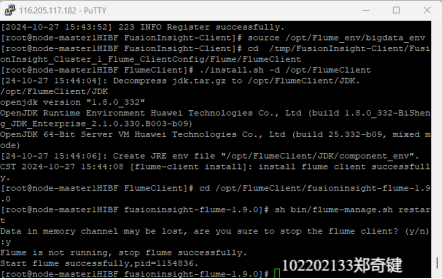
任务四:配置Flume采集数据
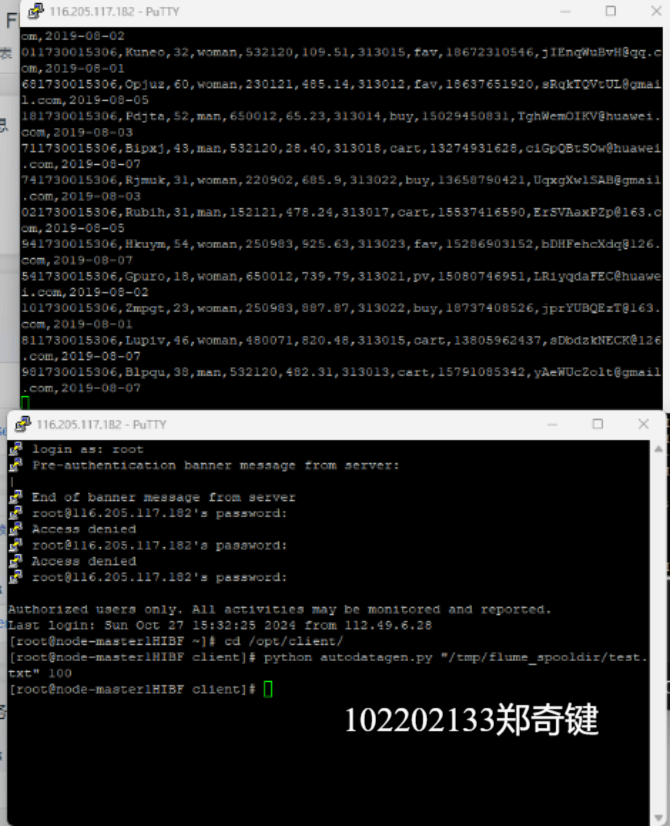
心得体会:
通过完成华为云大数据实时分析处理实验,我深刻体会到云平台在资源调度上的灵活性和高效性,掌握了MapReduce服务开通、Python数据生成、Kafka配置、Flume安装及数据采集等关键技术。这些任务让我认识到,数据采集和传输是实时分析的核心,Kafka和Flume的结合能有效实现高吞吐量、可靠的数据流处理。同时,实验过程中遇到的配置和网络问题也让我意识到分布式系统管理的复杂性,为后续实际应用打下了坚实基础。