1.研究背景与意义
随着社交媒体和在线通信的普及,人们越来越多地使用表情符号来表达情感和情绪。表情识别系统的发展成为一个重要的研究领域,旨在通过计算机自动识别和理解人类的表情,从而提高人机交互的效果和用户体验。
传统的表情识别方法主要基于手工设计的特征提取和分类算法,这些方法通常需要大量的人工参与和专业知识,且对于复杂的表情模式识别效果有限。然而,随着深度学习的兴起,特别是卷积神经网络(CNN)的发展,基于深度学习的表情识别系统取得了显著的进展。
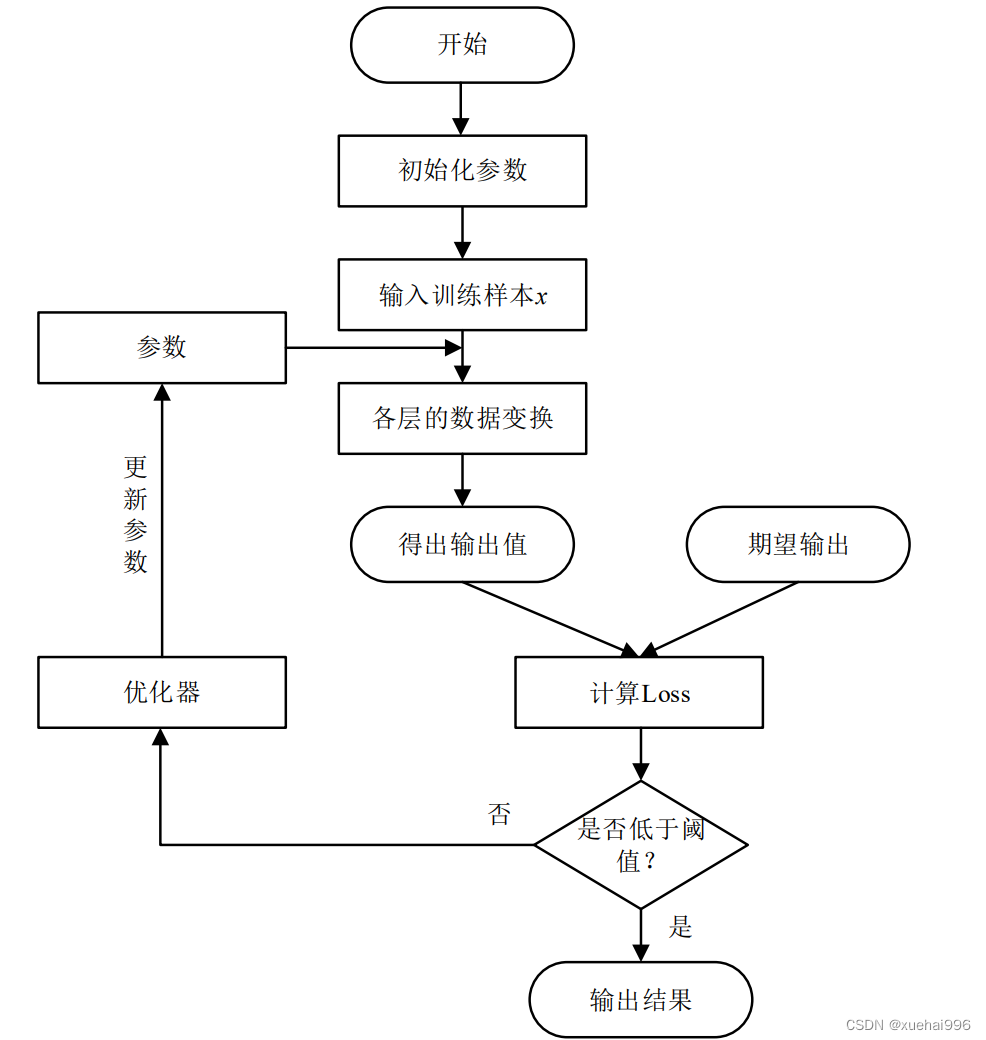
深度学习是一种模仿人脑神经网络结构和工作原理的机器学习方法。卷积神经网络是深度学习中最常用的模型之一,其通过多层卷积和池化操作,可以有效地从原始图像数据中提取特征,并进行分类和识别。在表情识别领域,卷积神经网络可以自动学习和提取图像中的表情特征,从而实现准确的表情分类和识别。
基于深度学习卷积神经网络的表情识别系统具有以下几个重要的意义:
-
提高表情识别的准确性:传统的表情识别方法往往依赖于人工设计的特征和分类算法,其准确性受限。而基于深度学习的表情识别系统可以自动学习和提取图像中的表情特征,从而实现更准确的表情分类和识别。
-
降低人工成本和专业知识要求:传统的表情识别方法需要大量的人工参与和专业知识,而基于深度学习的表情识别系统可以自动学习和提取特征,减少了人工成本和专业知识要求。
-
提高人机交互的效果和用户体验:表情识别系统可以应用于人机交互领域,例如智能机器人、虚拟现实和增强现实等。基于深度学习的表情识别系统可以更准确地理解用户的情感和情绪,从而提高人机交互的效果和用户体验。
-
推动深度学习和人工智能的发展:基于深度学习的表情识别系统是深度学习和人工智能领域的重要应用之一。通过研究和开发基于深度学习的表情识别系统,可以推动深度学习和人工智能的发展,为其他领域的研究和应用提供借鉴和启示。
综上所述,基于深度学习卷积神经网络的表情识别系统在提高表情识别准确性、降低人工成本和专业知识要求、提高人机交互效果和用户体验以及推动深度学习和人工智能的发展等方面具有重要的研究背景和意义。随着深度学习技术的不断发展和应用,基于深度学习的表情识别系统有望在实际应用中发挥更大的作用,并为人们提供更好的用户体验和服务。
2.图片演示



3.视频演示
基于深度学习卷积神经网络的表情识别系统_哔哩哔哩_bilibili
4.人脸表情识别流程
传统的人脸表情识别一般包括人脸检测、表情特征提取、表情分类三个主要步
骤。基于传统方法的表情识别流程如图 a)所示。
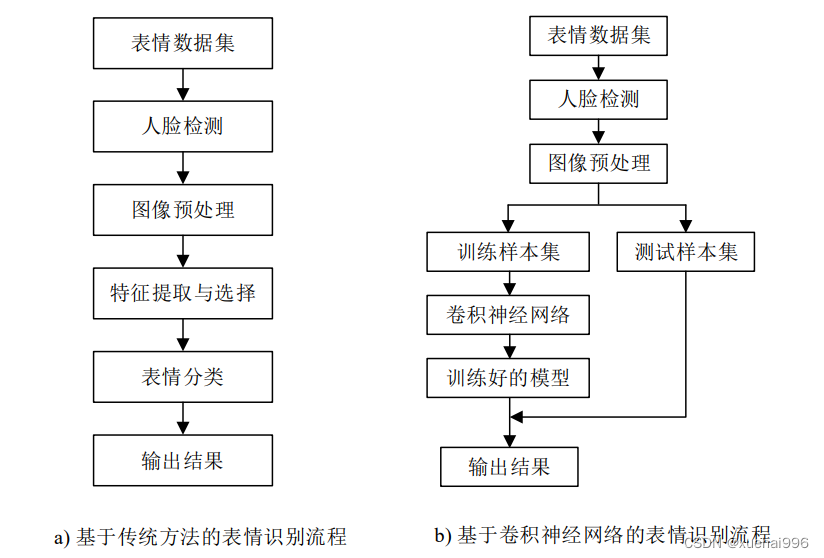
构建一个传统的表情识别系统,第一步通过人脸检测算法对输入的静态图像或图像视频序列进行人脸检测,第二步对检测到的人脸图像进行特征提取,去除一些与表情无关的信息,最后对测试样本进行表情分类。
基于卷积神经网络的人脸表情识别将表情特征提取过程与表情分类过程整合到一起,通过训练表情数据集来提取不同的表情特征,基于卷积神经网络的表情识别流程如图b)所示。人脸检测是表情识别中较为重要的一步,常用的人脸检测算法如下。
5.核心代码讲解
5.1 CK.py
class CK(data.Dataset):def __init__(self, split='Training', fold = 1, transform=None):self.transform = transformself.split = split # training set or test setself.fold = fold # the k-fold cross validationself.data = h5py.File('./data/CK_data.h5', 'r', driver='core')number = len(self.data['data_label']) #981sum_number = [0,135,312,387,594,678,927,981] # the sum of class numbertest_number = [12,18,9,21,9,24,6] # the number of each classtest_index = []train_index = []for j in range(len(test_number)):for k in range(test_number[j]):if self.fold != 10: #the last fold start from the last elementtest_index.append(sum_number[j]+(self.fold-1)*test_number[j]+k)else:test_index.append(sum_number[j+1]-1-k)for i in range(number):if i not in test_index:train_index.append(i)print(len(train_index),len(test_index))# now load the picked numpy arraysif self.split == 'Training':self.train_data = []self.train_labels = []for ind in range(len(train_index)):self.train_data.append(self.data['data_pixel'][train_index[ind]])self.train_labels.append(self.data['data_label'][train_index[ind]])elif self.split == 'Testing':self.test_data = []self.test_labels = []for ind in range(len(test_index)):self.test_data.append(self.data['data_pixel'][test_index[ind]])self.test_labels.append(self.data['data_label'][test_index[ind]])def __getitem__(self, index):if self.split == 'Training':img, target = self.train_data[index], self.train_labels[index]elif self.split == 'Testing':img, target = self.test_data[index], self.test_labels[index]img = img[:, :, np.newaxis]img = np.concatenate((img, img, img), axis=2)img = Image.fromarray(img)if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self):if self.split == 'Training':return len(self.train_data)elif self.split == 'Testing':return len(self.test_data)
该程序文件名为CK.py,主要是一个名为CK的数据集类。该类继承自torch.utils.data.Dataset类,用于加载CK+数据集。
该类的构造函数有三个参数:split、fold和transform。split参数用于指定数据集是训练集还是测试集,默认为训练集。fold参数用于指定k-fold交叉验证的折数,默认为1。transform参数是一个可调用的函数/变换,用于对图像进行变换,默认为None。
在构造函数中,首先通过h5py库打开名为CK_data.h5的HDF5文件,该文件包含了CK+数据集的图像和标签数据。然后根据split参数选择加载训练集数据还是测试集数据。
加载训练集数据时,根据fold参数确定训练集的索引。根据数据集的类别数和每个类别的图像数量,计算出每个类别在训练集中的图像数量。根据fold参数和类别数量,确定每个类别在训练集中的起始索引和结束索引。根据起始索引和结束索引,将训练集的图像数据和标签数据加载到self.train_data和self.train_labels中。
加载测试集数据时,根据fold参数确定测试集的索引。根据数据集的类别数和每个类别的图像数量,计算出每个类别在测试集中的图像数量。根据fold参数和类别数量,确定每个类别在测试集中的起始索引和结束索引。根据起始索引和结束索引,将测试集的图像数据和标签数据加载到self.test_data和self.test_labels中。
该类还实现了__getitem__和__len__方法。__getitem__方法用于获取指定索引的图像和标签数据,并进行一些预处理操作,如将图像数据转换为PIL图像、进行图像通道的拼接和应用指定的变换。__len__方法用于返回训练集或测试集的长度。
总结:该程序文件定义了一个名为CK的数据集类,用于加载CK+数据集的图像和标签数据。可以根据split参数指定加载训练集或测试集的数据,并根据fold参数指定k-fold交叉验证的折数。加载的数据可以通过__getitem__方法获取,并可以应用指定的变换进行预处理。
5.2 fer.py
class FER2013(data.Dataset):def __init__(self, split='Training', transform=None):self.transform = transformself.split = split # training set or test setself.data = h5py.File('./data/data.h5', 'r', driver='core')# now load the picked numpy arraysif self.split == 'Training':self.train_data = self.data['Training_pixel']self.train_labels = self.data['Training_label']self.train_data = np.asarray(self.train_data)self.train_data = self.train_data.reshape((28709, 48, 48))elif self.split == 'PublicTest':self.PublicTest_data = self.data['PublicTest_pixel']self.PublicTest_labels = self.data['PublicTest_label']self.PublicTest_data = np.asarray(self.PublicTest_data)self.PublicTest_data = self.PublicTest_data.reshape((3589, 48, 48))else:self.PrivateTest_data = self.data['PrivateTest_pixel']self.PrivateTest_labels = self.data['PrivateTest_label']self.PrivateTest_data = np.asarray(self.PrivateTest_data)self.PrivateTest_data = self.PrivateTest_data.reshape((3589, 48, 48))def __getitem__(self, index):if self.split == 'Training':img, target = self.train_data[index], self.train_labels[index]elif self.split == 'PublicTest':img, target = self.PublicTest_data[index], self.PublicTest_labels[index]else:img, target = self.PrivateTest_data[index], self.PrivateTest_labels[index]img = img[:, :, np.newaxis]img = np.concatenate((img, img, img), axis=2)img = Image.fromarray(img)if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self):if self.split == 'Training':return len(self.train_data)elif self.split == 'PublicTest':return len(self.PublicTest_data)else:return len(self.PrivateTest_data)
这个程序文件是用来处理FER2013数据集的。它定义了一个名为FER2013的类,继承自torch.utils.data.Dataset类,用于创建FER2013数据集。
FER2013数据集包含训练集、测试集和验证集。在FER2013类的构造函数中,可以通过传入参数split来选择创建训练集、测试集还是验证集的数据集对象。同时可以传入一个可选的transform参数,用于对图像进行预处理。
在构造函数中,程序会加载一个名为data.h5的HDF5文件,该文件包含了FER2013数据集的像素数据和标签数据。根据split参数的不同,程序会将数据集分别存储在train_data、train_labels、PublicTest_data、PublicTest_labels、PrivateTest_data和PrivateTest_labels这些成员变量中。
在__getitem__方法中,根据split参数的不同,程序会返回对应数据集中的图像和标签。图像会经过一系列的处理,包括将图像转换为PIL图像对象、进行预处理等。
在__len__方法中,根据split参数的不同,程序会返回对应数据集的长度。
总之,这个程序文件是用来创建FER2013数据集对象的,可以根据需要选择训练集、测试集或验证集,并对图像进行预处理。
5.3 k_fold_train.py
class TrainModel:def __init__(self):passdef train(self):for i in range(10):cmd = 'python mainpro_CK+.py --model VGG19 --bs 32 --lr 0.01 --fold %d' %(i+1)os.system(cmd)print("Train VGG19 ok!")这个程序文件名为k_fold_train.py,它的功能是使用k折交叉验证训练一个VGG19模型。程序首先导入了os模块。然后,通过一个循环,执行了10次以下操作:构建一个命令字符串cmd,其中包含了调用mainpro_CK+.py脚本的命令以及一些参数,其中fold参数的值在每次循环中递增1。然后,使用os.system函数执行这个命令。最后,打印出"Train VGG19 ok!"的提示信息。
5.4 plot_CK+_confusion_matrix.py
class ConfusionMatrixPlotter:def __init__(self, dataset, model):self.dataset = datasetself.model = modelself.class_names = ['Angry', 'Disgust', 'Fear', 'Happy', 'Sad', 'Surprise', 'Contempt']self.cut_size = 44self.transform_test = transforms.Compose([transforms.TenCrop(self.cut_size),transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),])self.net = self._get_model()self.all_targets = Noneself.all_predicted = Nonedef _get_model(self):if self.model == 'VGG19':return VGG('VGG19')elif self.model == 'Resnet18':return ResNet18()def _load_checkpoint(self, fold):path = os.path.join(self.dataset + '_' + self.model, '%d' %(fold+1))checkpoint = torch.load(os.path.join(path, 'Test_model.t7'))self.net.load_state_dict(checkpoint['net'])self.net.cuda()self.net.eval()def _get_testloader(self, fold):testset = CK(split='Testing', fold=fold+1, transform=self.transform_test)return torch.utils.data.DataLoader(testset, batch_size=5, shuffle=False, num_workers=1)def _compute_accuracy(self, targets, predicted):correct = predicted.eq(targets.data).cpu().sum()total = targets.size(0)acc = 100. * correct / totalreturn accdef _concatenate_predictions(self, predicted, targets):if self.all_predicted is None and self.all_targets is None:self.all_predicted = predictedself.all_targets = targetselse:self.all_predicted = torch.cat((self.all_predicted, predicted), 0)self.all_targets = torch.cat((self.all_targets, targets), 0)def _plot_confusion_matrix(self, cm, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title, fontsize=16)plt.colorbar()tick_marks = np.arange(len(self.class_names))plt.xticks(tick_marks, self.class_names, rotation=45)plt.yticks(tick_marks, self.class_names)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label', fontsize=18)plt.xlabel('Predicted label', fontsize=18)plt.tight_layout()def plot(self):for i in range(10):print("%d fold" % (i+1))self._load_checkpoint(i)testloader = self._get_testloader(i)for batch_idx, (inputs, targets) in enumerate(testloader):bs, ncrops, c, h, w = np.shape(inputs)inputs = inputs.view(-1, c, h, w)inputs, targets = inputs.cuda(), targets.cuda()inputs, targets = Variable(inputs, volatile=True), Variable(targets)outputs = self.net(inputs)outputs_avg = outputs.view(bs, ncrops, -1).mean(1) # avg over crops_, predicted = torch.max(outputs_avg.data, 1)acc = self._compute_accuracy(targets, predicted)self._concatenate_predictions(predicted, targets)print("accuracy: %0.3f" % acc)matrix = confusion_matrix(self.all_targets.data.cpu().numpy(), self.all_predicted.cpu().numpy())np.set_printoptions(precision=2)plt.figure(figsize=(10, 8))self._plot_confusion_matrix(matrix, classes=self.class_names, normalize=False,title='Confusion Matrix (Accuracy: %0.3f%%)' % acc)plt.savefig(os.path.join(self.dataset + '_' + self.model, 'Confusion Matrix.png'))plt.close()if __name__ == '__main__':parser = argparse.ArgumentParser(description='PyTorch CK+ CNN Training')parser.add_argument('--dataset', type=str, default='CK+', help='CNN architecture')parser.add_argument('--model', type=str, default='VGG19', help='CNN architecture')opt = parser.parse_args()plotter = ConfusionMatrixPlotter(opt.dataset, opt.model)plotter.plot()
这个程序文件的作用是绘制CK+数据集的混淆矩阵。它使用了PyTorch框架和一些相关的库来加载模型、进行预测和计算混淆矩阵。程序首先定义了一些必要的参数和函数,包括数据集的类别、模型的选择、绘制混淆矩阵的函数等。然后,程序加载模型并对测试集进行预测,计算出预测准确率,并将预测结果和真实标签保存起来。最后,程序根据预测结果和真实标签计算混淆矩阵,并将其绘制出来保存为图片文件。
5.5 plot_fer2013_confusion_matrix.py
class ConfusionMatrixPlotter:def __init__(self, model, dataset, split):self.model = modelself.dataset = datasetself.split = splitself.class_names = ['Angry', 'Disgust', 'Fear', 'Happy', 'Sad', 'Surprise', 'Neutral']self.cut_size = 44self.transform_test = transforms.Compose([transforms.TenCrop(self.cut_size),transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),])def plot_confusion_matrix(self, cm, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title, fontsize=16)plt.colorbar()tick_marks = np.arange(len(self.class_names))plt.xticks(tick_marks, self.class_names, rotation=45)plt.yticks(tick_marks, self.class_names)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label', fontsize=18)plt.xlabel('Predicted label', fontsize=18)plt.tight_layout()def plot(self):if self.model == 'VGG19':net = VGG('VGG19')elif self.model == 'Resnet18':net = ResNet18()path = os.path.join(self.dataset + '_' + self.model)checkpoint = torch.load(os.path.join(path, self.split + '_model.t7'))net.load_state_dict(checkpoint['net'])net.cuda()net.eval()Testset = FER2013(split=self.split, transform=self.transform_test)Testloader = torch.utils.data.DataLoader(Testset, batch_size=64, shuffle=False)correct = 0total = 0all_target = []for batch_idx, (inputs, targets) in enumerate(Testloader):bs, ncrops, c, h, w = np.shape(inputs)inputs = inputs.view(-1, c, h, w)inputs, targets = inputs.cuda(), targets.cuda()inputs, targets = Variable(inputs, volatile=True), Variable(targets)outputs = net(inputs)outputs_avg = outputs.view(bs, ncrops, -1).mean(1) # avg over crops_, predicted = torch.max(outputs_avg.data, 1)total += targets.size(0)correct += predicted.eq(targets.data).cpu().sum()if batch_idx == 0:all_predicted = predictedall_targets = targetselse:all_predicted = torch.cat((all_predicted, predicted), 0)all_targets = torch.cat((all_targets, targets), 0)acc = 100. * correct / totalprint("accuracy: %0.3f" % acc)matrix = confusion_matrix(all_targets.data.cpu().numpy(), all_predicted.cpu().numpy())np.set_printoptions(precision=2)plt.figure(figsize=(10, 8))self.plot_confusion_matrix(matrix, classes=self.class_names, normalize=True,title=self.split + ' Confusion Matrix (Accuracy: %0.3f%%)' % acc)plt.savefig(os.path.join(path, self.split + '_cm.png'))plt.close()这个程序文件的目的是绘制FER2013数据集中PublicTest和PrivateTest的混淆矩阵。它首先导入所需的库和模块,然后定义了一个用于绘制混淆矩阵的函数plot_confusion_matrix。接下来,它解析命令行参数,包括模型名称、数据集名称和划分名称。然后,它加载指定模型的权重,并将模型移动到GPU上进行评估。然后,它加载测试数据集,并使用模型对数据进行预测。最后,它计算准确率、绘制混淆矩阵,并将结果保存为图片文件。
5.6 preprocess_CK+.py
class CKData:def __init__(self, ck_path):self.ck_path = ck_pathself.data_x = []self.data_y = []def load_data(self):anger_path = os.path.join(self.ck_path, 'anger')disgust_path = os.path.join(self.ck_path, 'disgust')fear_path = os.path.join(self.ck_path, 'fear')happy_path = os.path.join(self.ck_path, 'happy')sadness_path = os.path.join(self.ck_path, 'sadness')surprise_path = os.path.join(self.ck_path, 'surprise')contempt_path = os.path.join(self.ck_path, 'contempt')files = os.listdir(anger_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(anger_path,filename))self.data_x.append(I.tolist())self.data_y.append(0)files = os.listdir(disgust_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(disgust_path,filename))self.data_x.append(I.tolist())self.data_y.append(1)files = os.listdir(fear_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(fear_path,filename))self.data_x.append(I.tolist())self.data_y.append(2)files = os.listdir(happy_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(happy_path,filename))self.data_x.append(I.tolist())self.data_y.append(3)files = os.listdir(sadness_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(sadness_path,filename))self.data_x.append(I.tolist())self.data_y.append(4)files = os.listdir(surprise_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(surprise_path,filename))self.data_x.append(I.tolist())self.data_y.append(5)files = os.listdir(contempt_path)files.sort()for filename in files:I = skimage.io.imread(os.path.join(contempt_path,filename))self.data_x.append(I.tolist())self.data_y.append(6)def save_data(self, datapath):datafile = h5py.File(datapath, 'w')datafile.create_dataset("data_pixel", dtype = 'uint8', data=self.data_x)datafile.create_dataset("data_label", dtype = 'int64', data=self.data_y)datafile.close()print("Save data finish!!!")这个程序文件的目的是为CK+数据集创建数据和标签。CK+数据集包含了7种情绪(愤怒、厌恶、恐惧、快乐、悲伤、惊讶、蔑视),每种情绪都有不同数量的图像。
程序首先定义了CK+数据集的路径,包括每种情绪的文件夹路径。
然后,程序创建了两个空列表data_x和data_y,用于存储数据和标签信息。
接下来,程序遍历每个情绪文件夹中的图像文件,并将图像读取为numpy数组,并将其添加到data_x列表中。同时,根据情绪的顺序,将相应的标签(0到6)添加到data_y列表中。
最后,程序将data_x和data_y保存为HDF5文件(CK_data.h5),并打印保存完成的消息。
总结起来,这个程序文件的功能是将CK+数据集的图像数据和标签保存为HDF5文件。
6.系统整体结构
整体功能和构架概述:
该表情识别系统基于深度学习卷积神经网络,用于识别人脸表情。系统包含多个程序文件,每个文件负责不同的功能,如数据预处理、模型训练、模型评估和可视化等。以下是每个文件的功能概述:
| 文件名 | 功能 |
|---|---|
| CK.py | 加载CK+数据集的图像和标签数据 |
| fer.py | 加载FER2013数据集的图像和标签数据 |
| k_fold_train.py | 执行k-fold交叉验证的训练过程 |
| mainpro_FER.py | 主程序,用于训练和测试FER2013数据集 |
| plot_CK+_confusion_matrix.py | 绘制CK+数据集的混淆矩阵 |
| plot_fer2013_confusion_matrix.py | 绘制FER2013数据集的混淆矩阵 |
| preprocess_CK+.py | 将CK+数据集的图像和标签保存为HDF5文件 |
| preprocess_fer2013.py | 将FER2013数据集的图像和标签保存为HDF5文件 |
| train.py | 训练模型的主程序 |
| transformer.py | 数据预处理的变换函数 |
| ui.py | 用户界面模块,用于交互式操作 |
| utils.py | 包含一些辅助函数和工具函数 |
| visualize.py | 可视化工具,用于绘制图像和结果 |
| models\resnet.py | ResNet模型的定义和实现 |
| models\vgg.py | VGG模型的定义和实现 |
| models_init_.py | 模型初始化文件 |
| transforms\functional.py | 数据预处理的函数实现 |
| transforms\transforms.py | 数据预处理的变换类实现 |
| transforms_init_.py | 数据预处理初始化文件 |
这些文件共同构成了一个完整的表情识别系统,包括数据集加载、数据预处理、模型训练、模型评估和结果可视化等功能。
7.深度学习常识
卷积神经网络结构
1962年日本科学家通过对猫视觉皮层的研究发现,人们对外界的认知是从局部到整体的,并提出了感受野的概念。卷积神经网络是一种用来处理相似结构的数据的神经网络,如时间序列数据和图像数据。
(1)卷积层
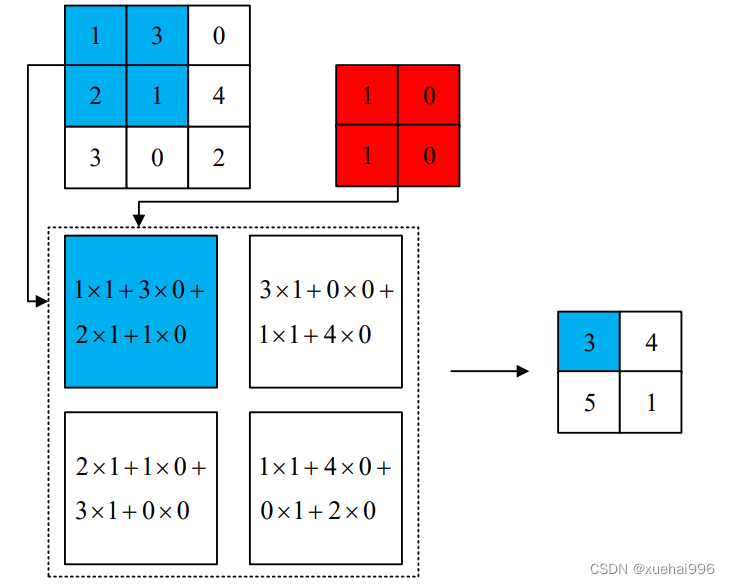
卷积计算是卷积神经网络的核心操作,也是一种特殊的线性运算。卷积层经过多个卷积核的计算后形成多个特征图(feature map),图2-4为一个卷积计算的示例,其中输入图像的尺寸为3×3,红色方块表示一个尺寸为2×2的卷积核,滑动步长为1,生成特征图的尺寸为2×2,虚线框内表示卷积计算过程。
设输入图片的尺寸为W×H,卷积核尺寸为K×K,滑动步长为S,填充(Padding)为Р,输出特征图的尺寸为W×H,,则W与H的计算公式如下:
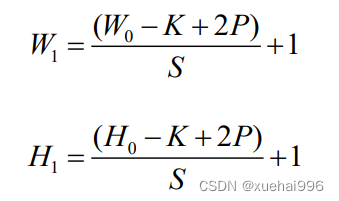
输出特征图的通道数等于卷积核的个数,填充的具体操作是在输入图像的外围补0,补一层,Padding记为1。填充的作用是防止图像边缘信息的丢失。
(2)池化层
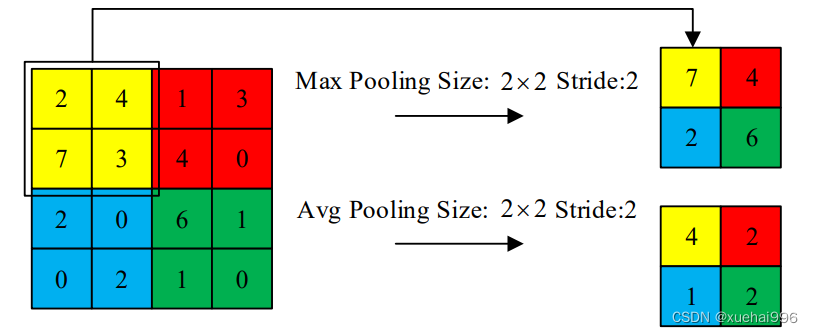
池化层又称下采样层,可以减少输入数据的空间大小。最大池化和平均池化是两种使用频率最高的池化方法。最大池化方法是保留池化区域元素的最大值,平均池化方法是保留池化区域元素的平均值。最大池化和平均池化的示意图如图2-5所示,图中,两种池化方法的尺寸均为2x2,步长均为2。根据步长的大小可以将池化分为重叠池化和非重叠池化,池化层可以降低特征图的维度,减少计算量,对图像变换和噪声的鲁棒性更强。
(3)全连接层
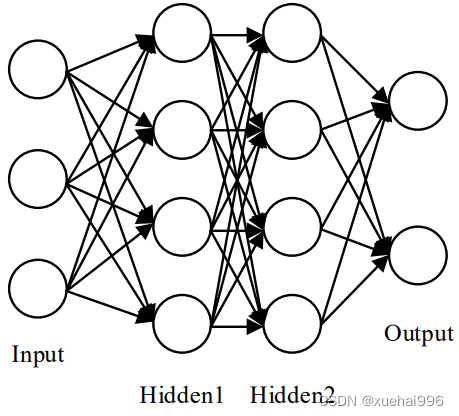
全连接层通常放在卷积神经网络的最后几层,在网络中起到“分类器”的作用。图2-6表示一个四层的前馈神经网络,该网络采用的就是全连接方式。从中可以看出,前馈神经网络每一层的神经元都与其上一层的每个神经元相连。卷积神经网络的参数量主要集中在全连接层,占比高达80%,容易造成参数冗余。
(4)激活函数层
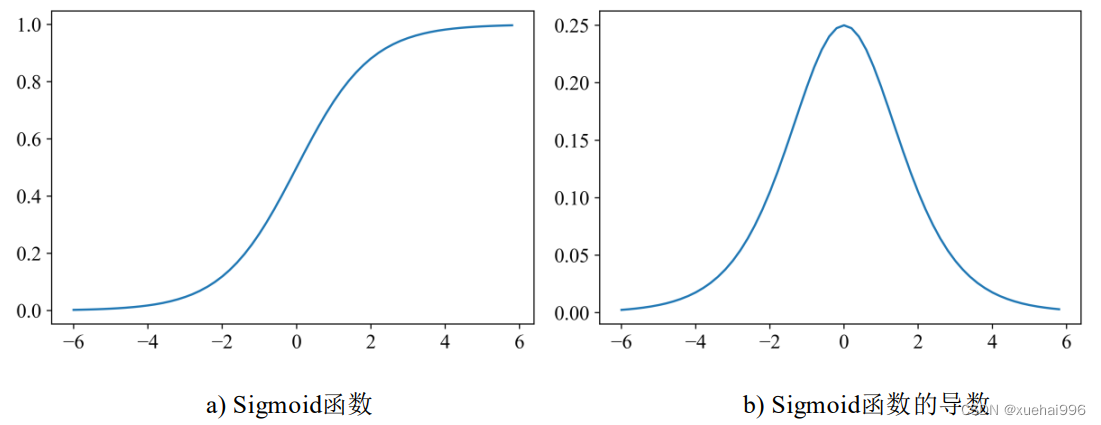
激活函数层通常放在卷积层之后,池化层之前。激活函数层可以增加卷积神经网络的非线性,让卷积神经网络可以解决更复杂的问题。如果没有激活函数层,无论有多少卷积层,都是输入和输出的线性组合,无法形成更复杂的表达空间。Sigmoid、Tanh、Relu是三种常用的激活函数。Sigmoid函数的数学计算式为o(z)=1/1+e",导数的数学计算式为o(z)=o(z)(1-o(z)),其函数图像和导数图像
8.卷积神经网络
Resnet
Resnet的出现为卷积神经网络向更多层数的发展提供了可能,具有里程碑意义。Resnet 通过捷径连接来解决过多层数引起的梯度消失及网络误差增大的问题,该网络由多个残差块组成,1.2.2小节中叙述了残差块的结构,实际的做法是在残差块中加入1x1卷积结构,起到改变输出通道的作用,新的模块被称为 Bottleneck结构,Bottleneck 的示意如所示。

常见的Rsenet的版本有 Resnet18、Resnet34、Resnet50、Resnet101等更多层的结构,每个版本的 Resnet 的前两层均为一个卷积层和一个最大池化层,最后两层均为一个全局平均池化层和一个全连接层。其中卷积核的尺寸为7×7,步长为2,最大池化层的尺寸为3×3,步长为2。中间有四个模块,每个模块含有不同个数的残差块或Bottleneck 结构。Resnet的输入尺寸为224×224。
VGG网络
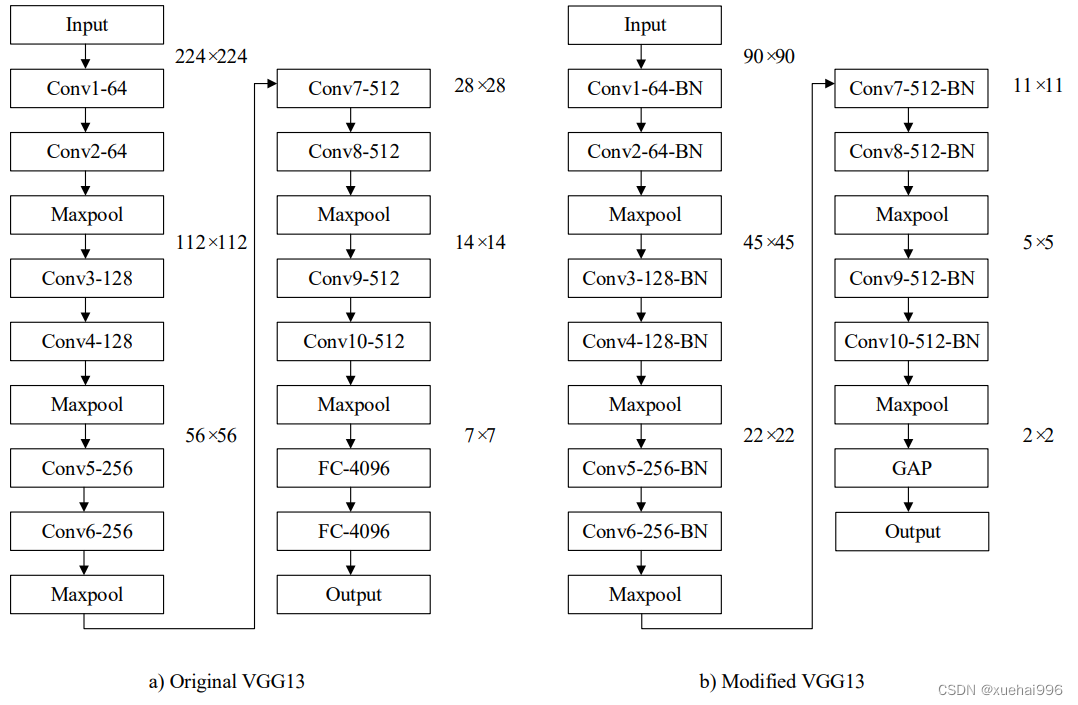
VGG是最经典的卷积神经网络之一, VGG网络分析了网络层数与网络识别效果的关系,使用多个3×3的小尺寸卷积核与2×2的最大池化层构建了多个不同深度的卷积神经网络。VGG卷积神经网络简单灵活、拓展性强,在多个图像识别任务上取得了很好的效果。与Alexnet 相比,VGG 网络在不同数据集上的泛化能力较为出色,与Inception 网络和 Resnet 网络相比,VGG 网络进行改进时更为灵活。然而传统的VGG卷积神经网络含有庞大的参数量和计算量,需要大量的内存空间和计算资源,实际应用时较为不便。
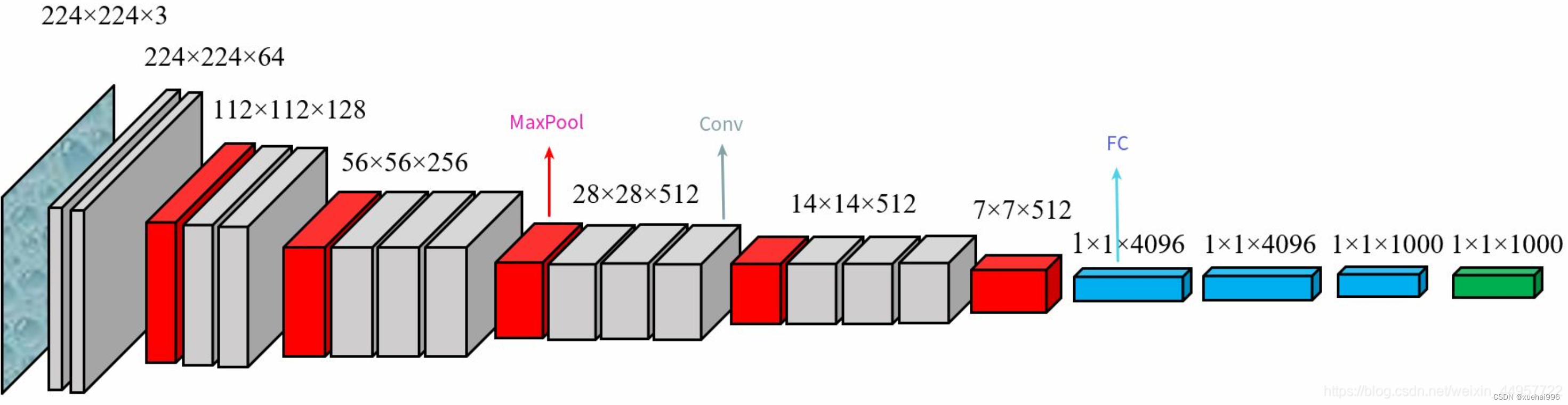
VGG网络的核心思想是通过叠堆小尺度卷积核来构造更深的卷积神经网络,以此来提升模型表现力,对比Alexnet网络,VGG 网络主要做了以下改进:
(1)移除原有的11×11,5x5卷积核,全部采用3×3的小尺度卷积核。两个串联的3x3卷积核与一个5x5的卷积核具有相同的感受野,三个串联的3x3的卷积核与一个7×7的卷积核具有相同的感受野。多次卷积可以增加网络的非线性,
并且参数量更少。假设输出的通道数为M﹐若经过一个5x5卷积,则对应的参数量为25M ,若经过两个3×3卷积,则对应的参数量为18M,由此可以看出,两个3×3卷积带来的参数量更少。
(2)移除原有的局部响应归一化层(LRN),通过实验对比发现,加入LRN层后,不但没有提升网络性能,反而会额外增加运行内存和计算时间。
(3)将最大池化层的尺寸由3x3变成2×2,相比3×3的最大池化层,2×2的最大池化层可以保留更多的特征信息。
传统的VGG网络包含六个版本,包括VGG11和带有LRN层的VGG11、VGG13、VGG16和带有1×1卷积的 VGG16、以及 VGG19。VGG网络的输入图像尺寸为224×224,每个版本具有相同的最大池化层和全连接层,都包含5个卷积模块。最大池化层在每个卷积模块之后,尺寸为2×2,全连接层都包含4096个神经元。VGG11的前两个卷积模块只有一个卷积层,后三个卷积模块都包含两个卷积层,卷积模块中卷积核的个数依次为64、128、256、512、512。带有LRN层的VGG11在第一个卷积层后加入LRN。VGG13的每个卷积模块都包含两个卷积层,其余结构与VGG11相同。VGG16与 VGG13相比,后三个卷积模块均含有三个卷积层,其余结构与VGG13相同。VGG16的另一个版本引入了lx1卷积,1×1卷积可以在不影响卷积层感受野的情况下增加网络的非线性。VGG19 与 VGG16相比,后三个卷积模块都包含四个卷积层,其余结构与VGG16相同。常用的三个版本为VGG13、VGG16、VGG19。
增加注意力机制
Transformer机制最初是由Bengio团队提出的,用于机器翻译,并在许多NLP任务中建立了最先进的技术。为了使Transformer也适用于计算机视觉任务,已经进行了一些修改。只在每个查询像素的局部邻域中应用自注意,而不是全局应用。本文提出了稀疏Transformer,它采用可扩展的近似来实现全局自注意。最近,视觉Transformer 通过直接将具有全局自关注的Transformer直接应用于全尺寸图像,实现了最先进的图像网分类技术。我们采用Transformer的核心思想,利用注意机制设计了Transformer层模块。Transformer层的结构如图1-3所示。变形器层包含多头注意结构。多头注意力模块的结构如图所示。
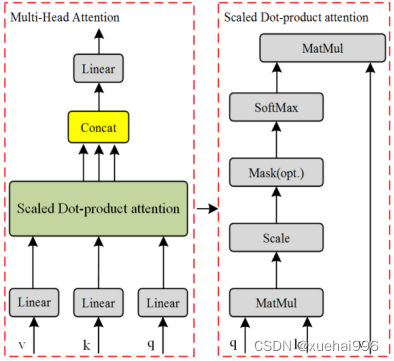
多头自注意力模块是设计特征融合网络的基本组成部分。计算公式(1)如下:
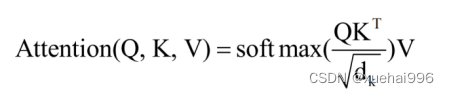
将注意机制扩展到多个头部,使该机制能够考虑不同的注意分布,并使模型关注信息的不同方面。多头注意机制见下公式(2):
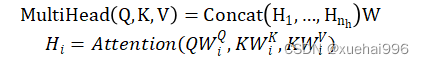
在模型通过迁移学习之后,微表达样本被馈送到微调模型并被分类为识别。VGG比传统CNN效率更高、延迟更小的主要原因是提出了可分离卷积。可分离卷积具有足够的通用性,可以在大多数视觉任务中取代网络模型。易于培训,有效减少网络模型的大小,减少延迟。然而,问题是可分离卷积仍然局限于空间,并且难以提取全局特征。Vit在作为变压器的计算机视觉平面的图像分类问题中获得了良好的结果。与Transformer的情况一样,每个块具有位置编码,该编码允许一维学习来保存空间信息。组件作为接头嵌入编码器中。vit插入可检索的类别标识符,该标识符使用Transformer编码器的输出状态作为性能分类标准。此外,二维放置方法补充了预训练的位置编码,以保持与任意分辨率图像的输入一致的块顺序,并获得全局特征。然而,没有引入图像中固有的感应偏差,并且当训练数据不足时不可能将其概括。
9.数据集的处理和训练
CK+数据集
CK+数据集是使用最广泛的实验室型数据集,由CK数据集扩展而来,包含123个不同种族的参与者。CK+数据集共有593个图片序列,这些序列的持续时间为10帧到60帧中的任意值,变化方式为从中性到其他表情峰值,实验中常使用每个序列的最后三帧作为样本图片。与JAFFE 数据集相同的是,CK+数据集同样包含七种面部表情,与JAFFE数据集不同的是,CK+数据集中没有中性表情,新增加了蔑视表情,同时年龄、种族、性别组成更为丰富。原始CK+数据集有很多与表情无关的信息﹐需要使用人脸检测并统一剪裁成大小为48×48的图片,图为处理后的CK+数据集的样本示例。

FER2013Plus 数据集
FER2013数据集是从互联网收集而来,每张图片剪裁后的大小为48×48,共有35887张图片,包含愤怒、厌恶、害怕、开心、悲伤、惊讶、中性七种表情。FFER2013同样属于非受控条件数据集,但是其标注准确率不高。为此 Barsoum等人l51重新标注了FER2013数据集,提出了FER2013Plus数据集。每张图片采用十名标注者进行标注,最后投票决定是哪一种表情。研究人员人发现,标注者人数越多,标注一致性越高。FER2013Plus数据集新增了蔑视表情、“未知表情”、“不是人脸”三个类别。由于“未知表情”和“不是人脸”对实际的研究没有意义,通常FER2013Plus数据集包含八种面部表情。图3-4是FER2013Plus和FER2013的标签对比图,黑色标签为FER2013数据集的样本标注,红色标签为FER2013Plus数据集重新标注后的样本标签,可以看出FER2013数据集出现了明显的标注错误,FER2013Plus的标注更为准确。

10.训练结果分析
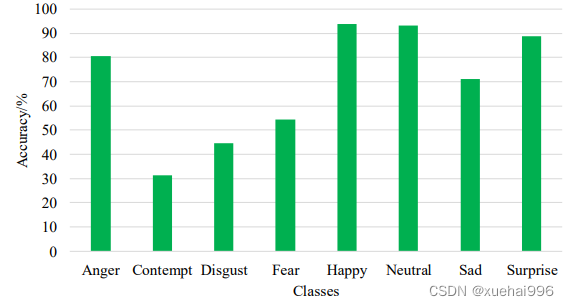
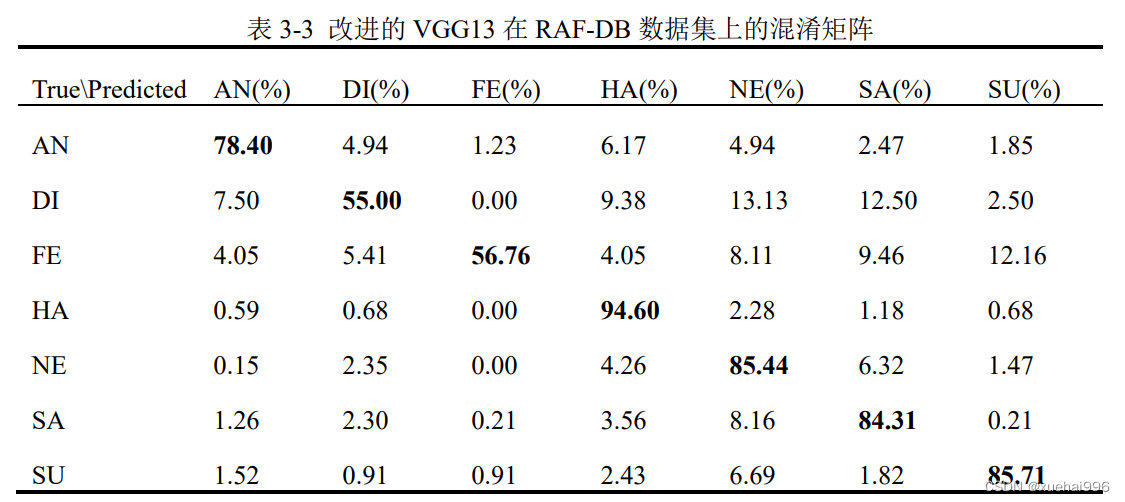
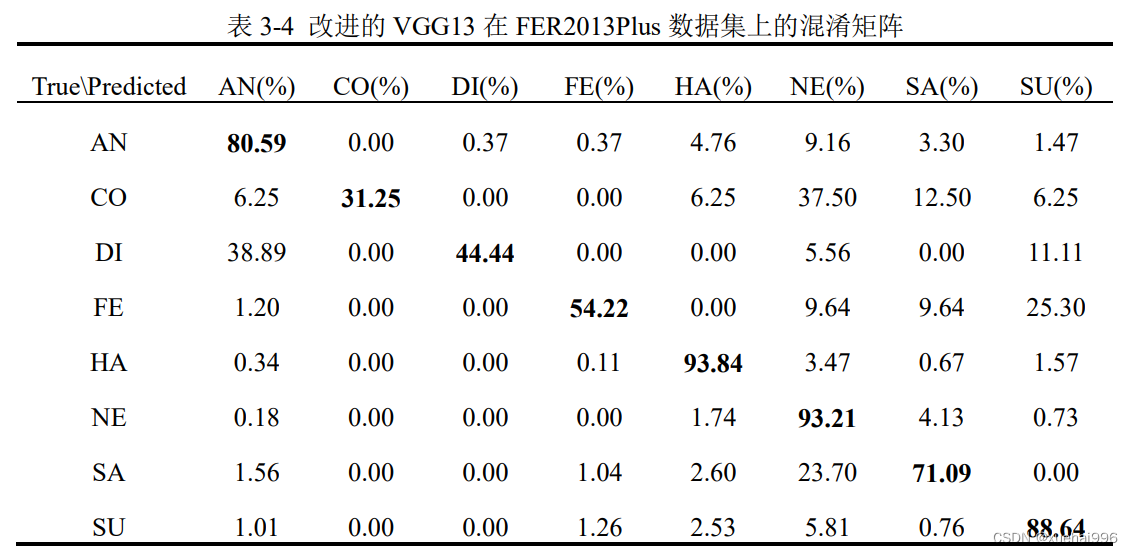
表3-3和表3-4表示改进的VGGG13在两个数据集上的混淆矩阵,混淆矩阵可以显示模型在进行预测时会对哪一类别产生混淆,横轴为预测标签,纵轴为真实标签,可以更好的呈现算法的性能,图表示两个数据集上每类表情的识别率。
由表3-3可知,在RAF-DB数据集上,M-VUG13 在L心、T、心了040种表情的识别率超过了84%,其中开心表情取得了最高的识别率,达到了94.6%。而厌恶和害怕两种表情的识别率明显低于其他五种表情,仅为55%和56.76%。厌恶表情有13.13%的概率被认为是中性表情,有12.5%的概率被认为成悲伤表情。害怕表情有12.16%的概率被认为是惊讶表情。
由表3-4可知,在FER2013Plus 数据集上,M-VGG13在开心和中性两种表情的识别率达到了93%以上,而在蔑视和厌恶两种表情的识别率仅为31.25%和44.44%,这是因为FER2013Plus训练集中两种表情样本数量较少。有些表情很容易被识别错误,例如厌恶表情有38.89%的概率被认为足愤芯衣情,舌"旧衣月1月./由万穴员认为是惊讶表情。这种高度的混淆在现买生活中是很典型的,即使定八’较区分这些表情。由图3-10可以发现,通常开心、中性、惊讶三种表情的识别率较高,其中开心表情是所有表情中识别率最高的,一方面由于开心表情的样本数量最多,另一方面说明与其他表情特征相比,开心表情的特征更容易识别。而蔑视、厌恶、害怕三种表情的识别率较低,其中蔑视表情是所有表情中识别率最低的,这是因为蔑视表情的样本数量最少。
11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于深度学习卷积神经网络的表情识别系统》