目录
1. 索引
1.1索引的概念
1.2索引的特点
1.3 索引的使用场景
1.4索引的使用
1.4.1查看索引
1.4.2创建索引
1.4.3删除索引
1.5索引保存的数据结构
2.事务
2.1经典例子
2.2事务的概念
2.3事务的使用
2.4事务的4个核心特性
2.5事务的并发问题
2.5.1脏读
2.5.2不可重复读
2.5.3幻读
1. 索引
1.1索引的概念
1.2索引的特点
(1)加快查询的速度。
(2)索引自身也是数据结构,也需要存储空间。
(3)当我们需要进行新增,删除,修改时,索引也需要更新(额外的开销)。
1.3 索引的使用场景
1.数据量较大,且经常对这些列进行条件查询。2.该数据库表的插入操作,及对这些列的修改操作频率较低。3.有足够大的磁盘空间,因为索引会占用额外的磁盘空间。
1.4索引的使用
使用博主已经建立好的student表。


1.4.1查看索引
语法:
show index from 表名;
查看某个表是否有索引,以及有几个索引。
展示:
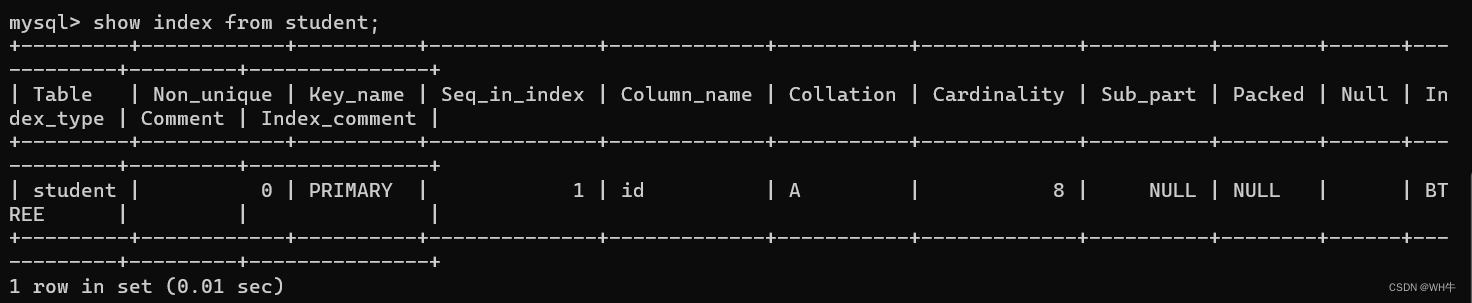
显示指定表中所有索引的详细信息
包括索引名称(Key_name)、索引列(Column_name)、是否是唯一索引(Non_unique)、排序方式(Collation)、索引的基数(Cardinality)等。
1.4.2创建索引
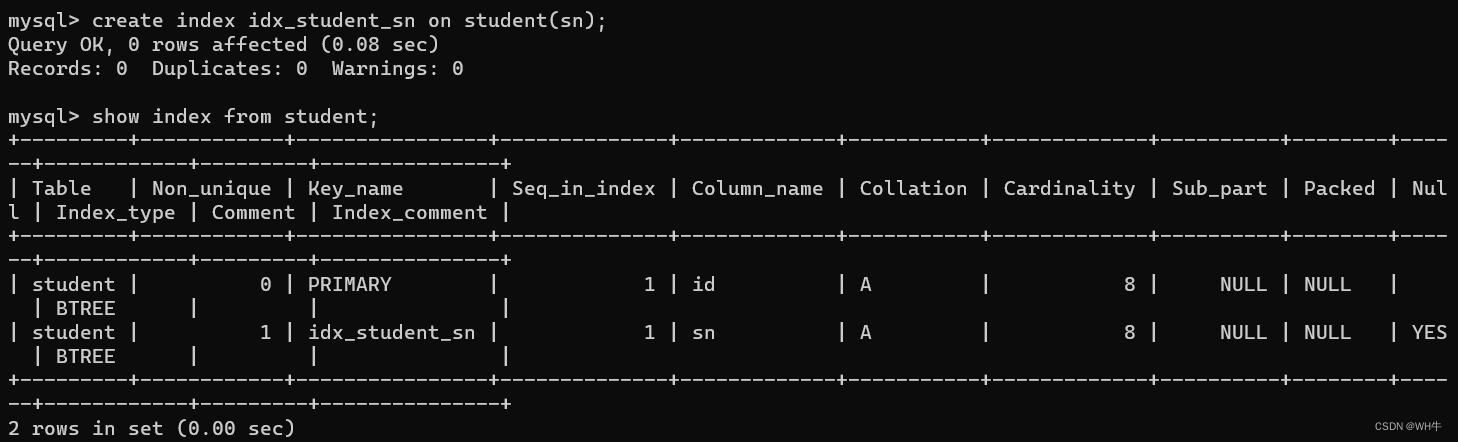
对于非主键、非唯一约束、非外键的字段,可以创建普通索引,普通索引是最常见的索引类型,用于加速对表中数据的查询。
语法:
create index 索引名 on 表名(字段名);
意思是:在那个表的那给字段上添加索引。
展示:
1.4.3删除索引
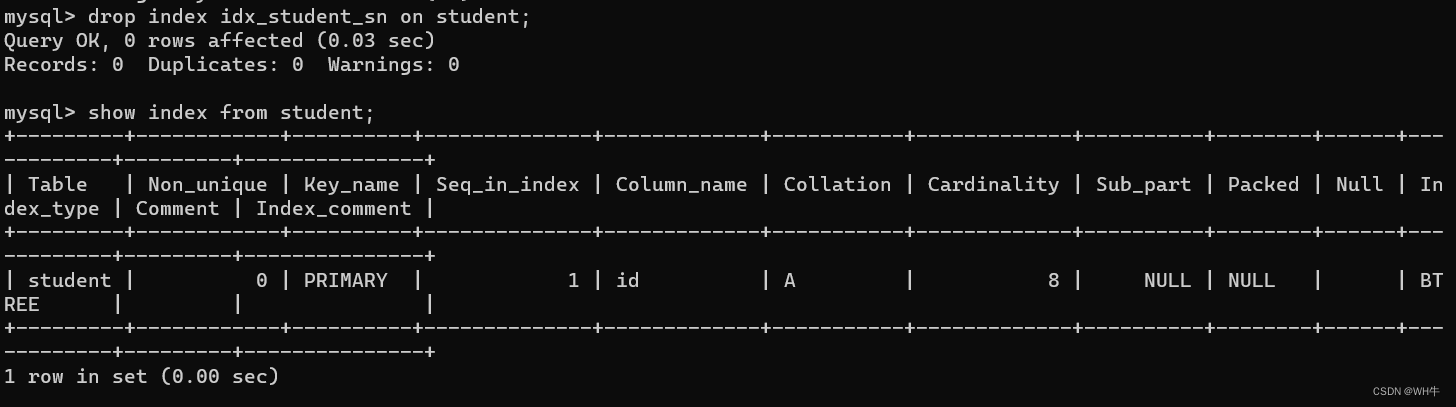
语法:
drop index 索引名 on 表名;
展示:
1.5索引保存的数据结构
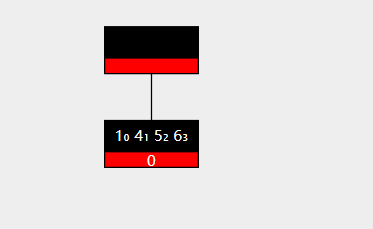
索引保存的数据结构主要为B+树
B+树的特点:
(1)为N叉二叉树,每个节点有n个key,n个key划分出n个区间。
(2)每个节点的n个key中,会存在最大(小)值。
(3)每个节点的key,都会在子树中重复出现。
(4)叶子节点之间使用链式结构相连。
结构如下:
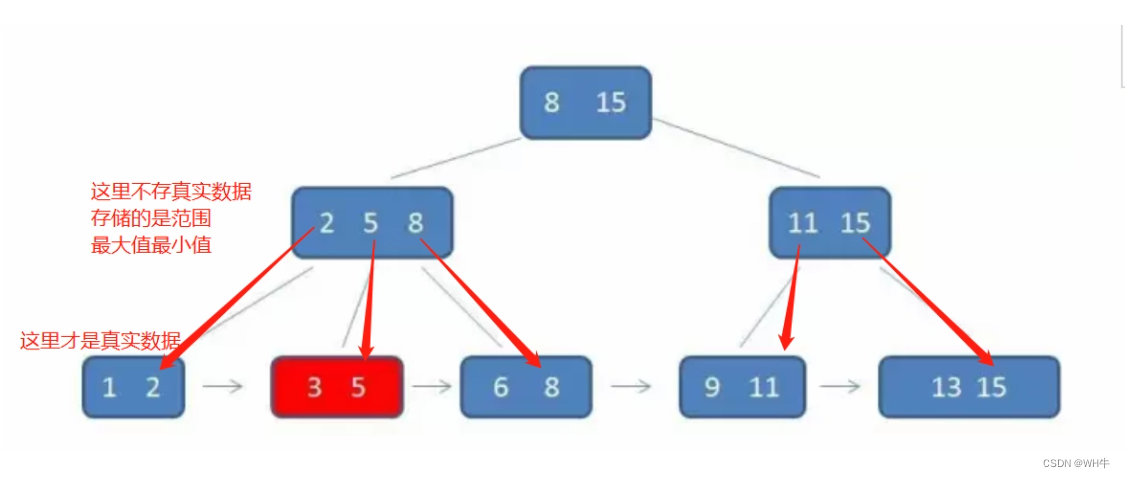
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率高。
为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
使用B+树的好处:
(1)所有数据都包含在叶子节点这一层中(数据全集数)进行范围查询时,只要找到对应初始位置,之后沿链表遍历即可。
(2)查询时间稳定。查询任意一个元素,都要从根节点查询到子节点。(稳定比单纯的快更有用)
(3)叶子节点这一层是数据全集数,故只存叶子节点在数据行,其他节点可以在缓存区。
2.事务
2.1经典例子
drop table if exists accout;create table accout(id int primary key auto_increment,name varchar ( 20 ) comment ' 账户名称 ' ,money decimal ( 11 , 2 ) comment ' 金额 ');insert into accout(name, money) values( ' 阿里巴巴 ' , 5000 ),( ' 四十大盗 ' , 1000 );
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
--阿里巴巴账户减少2000update accout set money=money- 2000 where name = ' 阿里巴巴 ' ;-- 四十大盗账户增加 2000update accout set money=money+ 2000 where name = ' 四十大盗 ' ;
2.2事务的概念
2.3事务的使用
( 1 )开启事务: start transaction;(2)执行多条 SQL 语句( 3 )回滚或提交: rollback/commit;
commit会提交事务,并使已对数据库进行的所有修改成为永久性的;
rollback会结束用户的事务,并撤销正在进行的所有未提交的修改;
只要没有commit,数据库就可以rollback复原到开始。
举例:
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;2.4事务的4个核心特性
(1)原子性:通过事务把多个操作打包在一起。
(2)一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
(3)事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
(4)隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
2.5事务的并发问题
2.5.1脏读
概念:一个事务读到另一个事务还没有提交的数据。
案例:
事务A修改了原来的数据但未提交,事务B读了事务A修改的数据提交了,但事务A进行了回滚,事务B就读了假数据。
解决:给操作加锁(在放锁之前不可访问),也就是写时不让读,写完才让读。
2.5.2不可重复读
概念:一个事务先后读取相同的数据,但两次读取的数据不同。
图示:
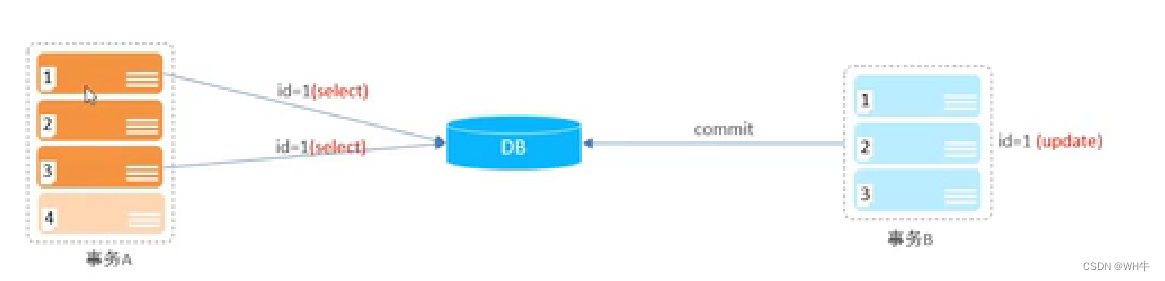
解决:给读操作也加锁,也就是读的时候也不让写。
2.5.3幻读
概念:一个事务按照条件查询时,此时无对应的数据行,但插入时又发现数据已经存在。
图示:
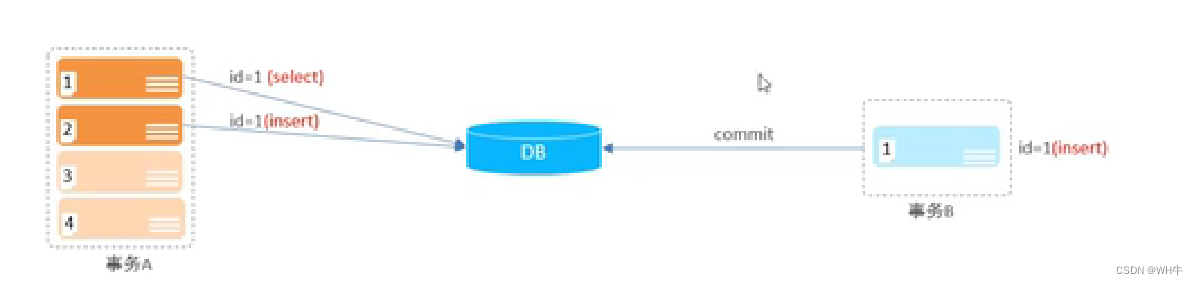
解决:串行化,不再进行任何并发。
2.6事务隔离级别
事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
(1)未提交(Read uncommitted)
并发程度最高,隔离程度最低,效果最高,数据最不靠谱。可能出现脏读,不可重复读,幻读。
(2)读提交(read committed)
相当给写操作加锁,可能出现不可重复读,幻读。
(3)可重复读(repeatable read)
相当给写和读操作都加锁,可能出现幻读。
(4)串行化(Serializable)
并发程度最低,隔离程度最高,效果最低,数据最靠谱。
都看到这了,不如关注一下,给个免费的赞 ![]()