聚类是一种无监督学习方法,其目标是将数据集中的样本分成不同的组别,使得同一组内的样本相似度较高,而不同组之间的样本相似度较低。聚类算法模型通常通过计算样本之间的相似度或距离来实现这一目标。以下是聚类算法模型的概念、评估及应用的一些关键方面:
1. 概念:
a. K均值聚类(K-Means):
- 原理: 将样本划分为K个簇,使得每个样本与其所属簇的中心点之间的距离平方和最小化。
- 优点: 简单、易于理解。
- 缺点: 对初始中心点敏感。
b. 层次聚类(Hierarchical Clustering):
- 原理: 构建一棵层次树,树的节点代表簇,树的叶子节点是样本。
- 优点: 不需要预先指定簇的数量。
- 缺点: 计算复杂度较高。
c. DBSCAN(Density-Based Spatial Clustering of Applications with Noise):
- 原理: 基于样本分布的密度,将高密度区域划分为簇。
- 优点: 可处理不规则形状的簇,对噪声具有鲁棒性。
- 缺点: 对密度变化较大的数据集可能不适用。
K均值聚类(K-Means)是一种常用的聚类算法,它将样本分成K个簇,使得每个样本与其所属簇的中心点之间的距离平方和最小化。以下是关于K均值聚类的一些关键概念和步骤:
1. 算法步骤:
a. 选择簇的数量(K):
- 在算法开始之前,需要预先指定要形成的簇的数量K。
b. 初始化中心点:
- 随机选择K个样本作为初始簇中心点。
c. 分配样本到簇:
- 对每个样本计算其与各个簇中心点的距离,将样本分配给距离最近的簇。
d. 更新簇中心点:
- 对每个簇,计算其所有样本的平均值,并将该平均值作为新的簇中心点。
e. 重复步骤c和步骤d:
- 重复步骤c和步骤d,直到簇中心点不再发生显著变化或达到预定的迭代次数。
2. 优缺点:
优点:
- 简单且易于实现。
- 对于大型数据集效果较好。
- 对于密集型簇的形状,表现较好。
缺点:
- 对初始中心点的选择敏感,可能会陷入局部最小值。
- 不适用于非凸形状的簇。
- 对异常值和噪声敏感。
3. 评估:
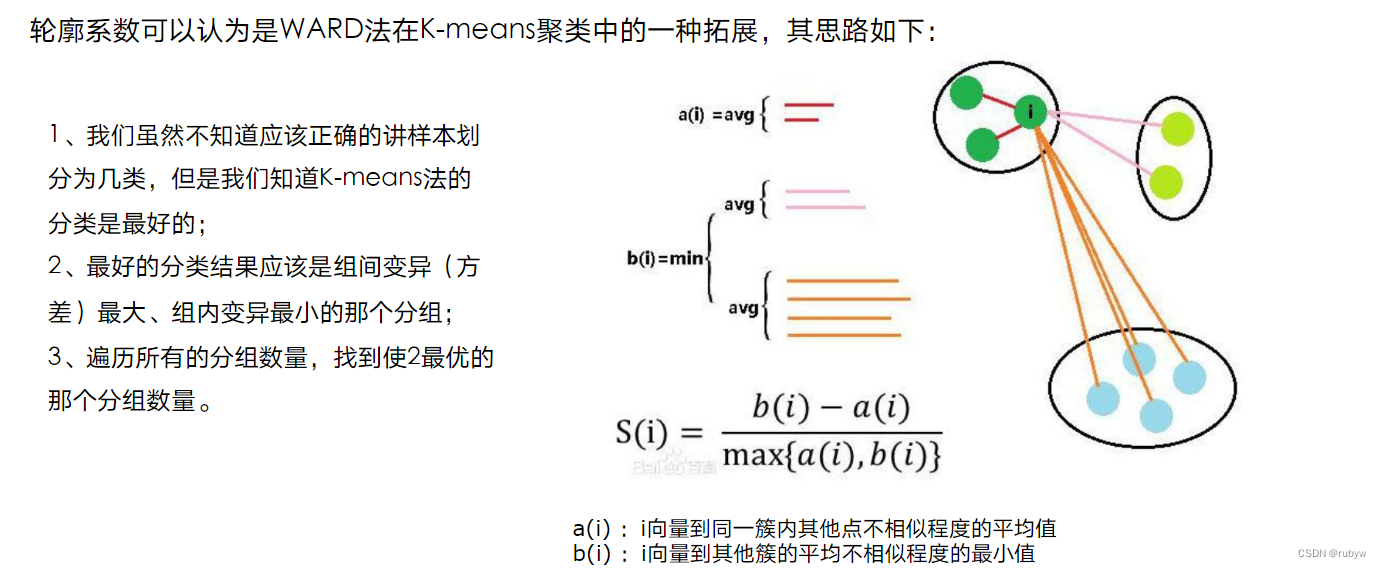
a. 轮廓系数(Silhouette Score):
- 衡量样本与其自身簇内距离与其他簇的距离之间的关系,取值范围在[-1, 1],越接近1表示聚类效果越好。
b. 手肘法(Elbow Method):
- 通过绘制簇数量和聚类损失之间的关系图,找到一个肘部(elbow)点,该点对应的簇数量可以被认为是数据的自然分割点。
4. 应用:
- 图像压缩:通过将相似颜色的像素聚类到同一簇,实现图像的压缩。
- 客户分群:根据客户的购买行为将其分为不同的群体,以便更好地定制营销策略。
- 数据预处理:作为数据分析的一部分,可以使用K均值聚类来对数据进行初步的分组。
总体而言,K均值聚类是一个常用的聚类算法,但在应用中需要注意对初始中心点的选择以及对数据分布的假设。在某些情况下,可能需要尝试多次运行算法并选择效果最好的结果。
2. 评估:
a. 内部评估指标:
- 轮廓系数(Silhouette Score): 衡量样本与其自身簇内距离与其他簇的距离之间的关系。
- Davies-Bouldin Index: 衡量簇的紧密度和分离度。
b. 外部评估指标:
- ARI(Adjusted Rand Index): 衡量聚类结果与真实标签的一致性。
- NMI(Normalized Mutual Information): 衡量两个分组之间的相似性。
3. 应用:
a. 图像分割:
- 使用聚类算法对图像进行分割,将相似的像素分配到同一簇,以便更好地识别和处理图像的不同部分。
b. 社交网络分析:
- 在社交网络中,可以使用聚类算法识别具有相似兴趣或行为模式的用户群体。
c. 生物信息学:
- 对基因表达数据进行聚类,以发现潜在的基因模式,帮助理解基因在不同条件下的表达情况。
d. 无监督特征学习:
- 聚类算法可以用于无监督学习中,帮助发现数据中的潜在结构,作为特征学习的一部分。
总体而言,聚类算法模型是数据挖掘和机器学习领域中重要的工具,广泛应用于各种领域,以发现数据中的隐藏模式和结构。