MySQL是一个广泛使用的关系型数据库管理系统。通过SQL语言进行数据操作和查询,还支持多用户、多线程和分布式操作等功能。
在实际使用中,我们会遇到各种查询条件,如字段名、表名、逻辑运算符、比较运算符、函数等。其中,有些查询条件可能数据量比较大,导致查询速度变慢。下面就来探讨一下如果通过利用内存过滤方式来进行效率优化。

相信各位应用研发小伙伴在日常研发过程中,会经常遇到批量入参场景,需要根据入参信息从数据库获取相应资讯。
常规的做法,大家更多的会采用对入参数据拼接形成执行SQL方式,因为这种方式编写简单,逻辑清晰,但是面临的可能是严重的效能问题。
【场景举例】
接口API - data.get 入参集合ParamLists为1000笔数据,业务逻辑需要根据入参条件批量获取业务数据,并进行业务后续业务处理:

目前应用研发常用方式【SQL拼接】:

当前方式是否存在效能风险?
是
- 因为每个条件都需要进行判断,并且需要根据条件进行索引以查找匹配值。如果条件过多,则检索的数据量就会变得非常大,因此查询效率会降低。
- 查询条件也会影响索引的使用。如果一个查询条件没有索引,那么MySQL就需要扫描整个表来找到匹配值,这也是很耗时,根据以往慢SQL表现,一般耗时会在5s以上。
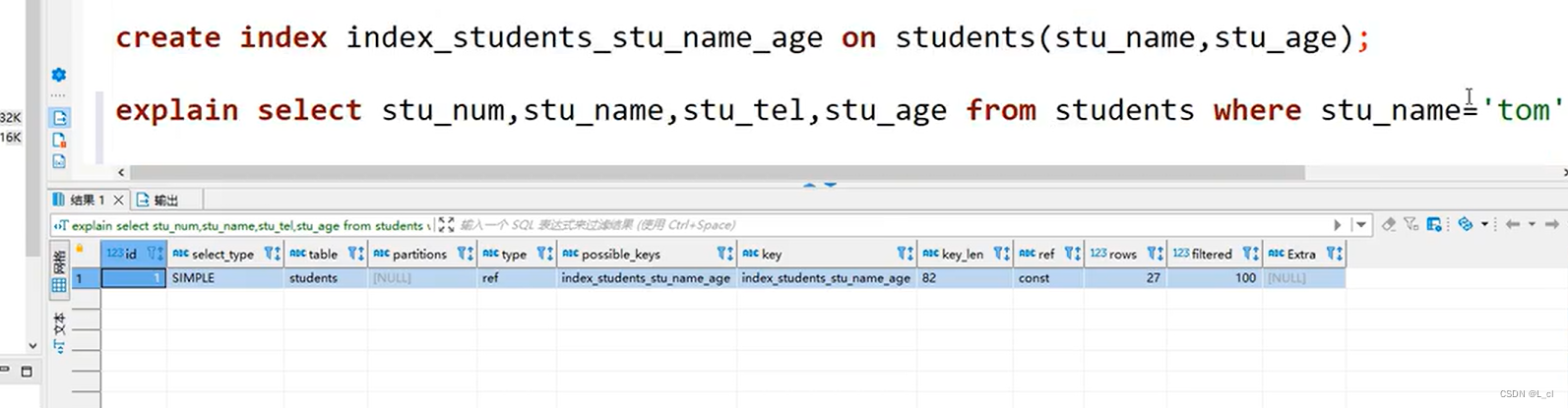
先可以通过执行计划,判断当前SQL是否有效或者正确的使用到索引。在索引分析时,需要注意的是,并不是SQL有使用到索引就排除索引问题,执行计划索引分析时,需要关注type栏位,判断出当前是否使用到索引,以及索引使用类型,range、index、all都是需要被重点关注的。同时结合ref,key_len栏位判断索引使用是否合理 ,以及extra判断是否有额外操作消耗,比如排序、临时表等。
下面主要说明下,对于这种大量入参拼接查询场景,怎么可以通过内存过滤方式处理。思想是,在一定数据量前提下,利用索引快速查询冗余数据,同时结合内存快速过滤需要的数据。
(1)数据量评估
评估使用索引栏位查询后的数据量,比如以上案例tenatsid为wo_detail索引栏位,则查看该租户下数据量,如果数据量为2w以内(这里为初略标准,具体可以根据需要输出的栏位以及数据量做内存评估),
则可以考虑使用内存方式解决,如果数据量过大,可能会带来额外的内存或者效能问题。
(2)SQL调整
此时SQL可以调整为:

因为整体数据量少,且能有效使用到索引查询,因此SQL查询效率快,一般在毫秒级,如果索引条件更加精确可以减少更多数据量。但需要注意的是,当前获取到数据集是冗余的,它包含了我们需要的数据集以及其它数据集。接下来就是期望在内存中过滤出我们需要的数据
(3)内存数据过滤优化
到此我们期望从2w笔数据在内存中快速找到1000笔数据信息:
验证数据准备:
1、datas 为数据库读取数据约2w笔
2、param 为入参数据量约1000笔
数据对应关系:1v1,即1个入参条件对应1条数据库数据
(为了测试内存数据过滤优化带来的效能提升,我这里提前将入参和数据库数据按统一条件排序)
【常规循环读取】
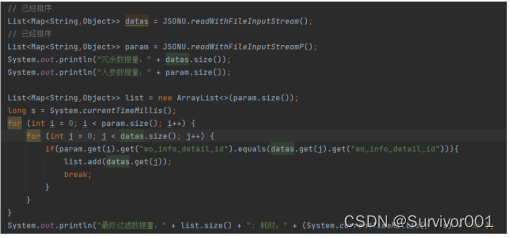
结果:
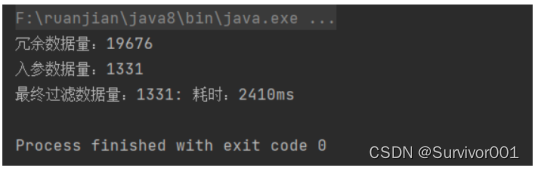
过滤耗时约2秒,相对于直接从数据库读取数据,在一定数据量下前提下,内存过滤时间相对更快。
是否有更快的过滤优化方式呢?
当然有
- 确保入参数据和查找数据的保持相同的栏位顺序,减少无效查找次数。
- 内循环查找中记录index,减少时间复杂度。
思路如下:
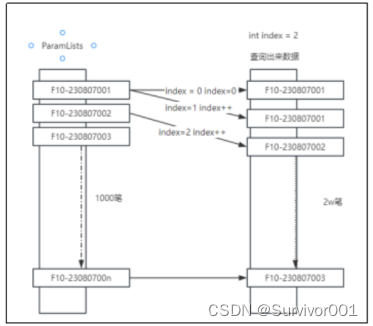
因为ParmList与查询数据保持相同栏位顺序,再过滤过程中,每处理扫描一条数据数组则index++
当进行F10-230807002数据查找时,此时index=2,这时直接从数据库集合中index为2位置开始读取数据。
如此,在1v1数据查询中,可以将时间复杂度从O(N*M)将到O(N),在1vN中数据库集合越大,则提效越明显。
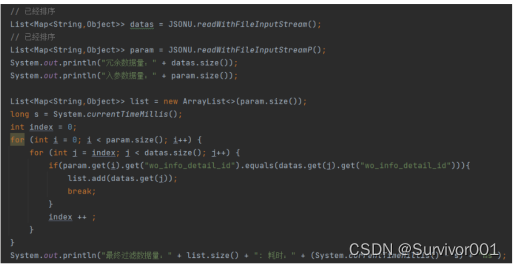
结果:
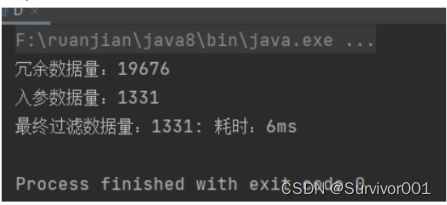
可以看到耗时时间从2s - >6ms
如果:入参和数据库场景为1vn场景下,这个时候就不能使用break,可以定义一个标识来记录当前入参数据的读取是否结束
结论
在大数据量拼接SQL查询业务中,根据场景数据量、复杂程度等条件综合判断优化方案,一般场景中数据量不是很大时可以考虑使用【冗余读取+内存过滤优化方案】来处理。如果数据集合过大,可能带来内存和更多的效能问题时,可以考虑采用其他方案,比如分批处理、临时表关联处理等