scrapy介绍安装--架构
Scrapy 是一个爬虫框架(底层代码封装好了,只需要在固定位置写固定代码即可),应用领域比较广泛---》爬虫界的django# 安装
#Windows平台1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs3、pip3 install lxml4、pip3 install pyopenssl5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl8、pip3 install scrapy#Linux,mac平台1、pip3 install scrapy# scrapy架构
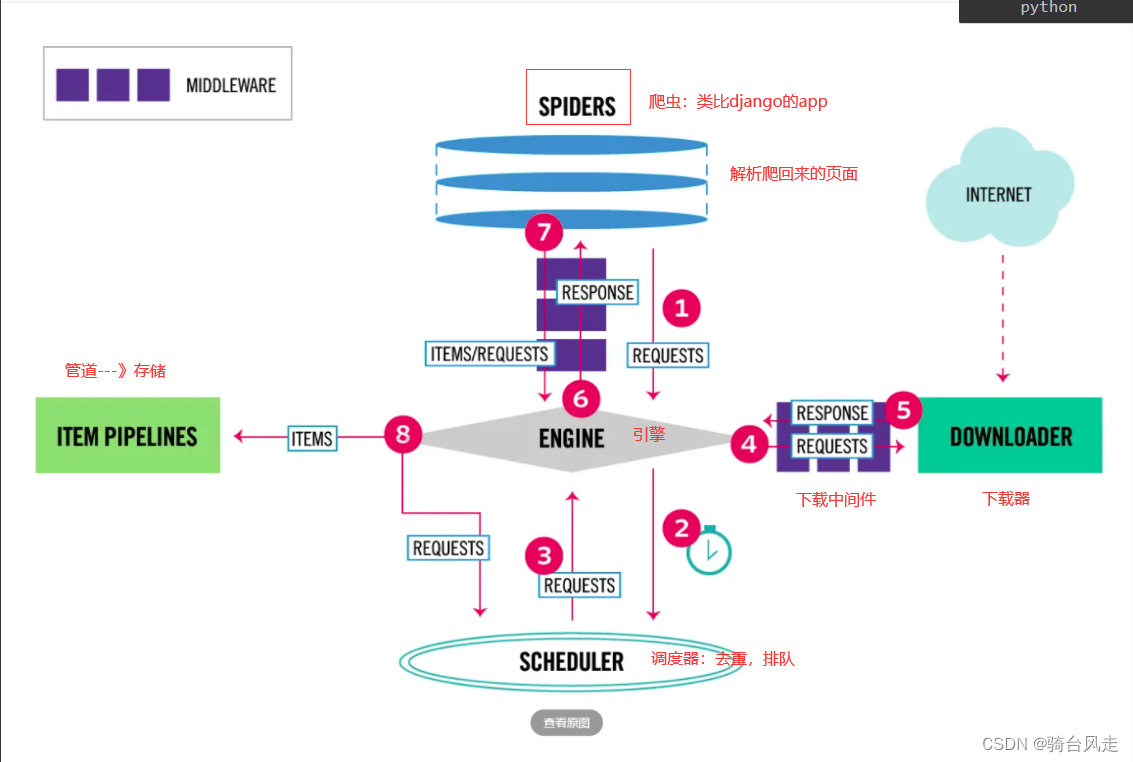
# 引擎(EGINE):引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。大总管,负责整个爬虫数据的流动# 调度器(SCHEDULER)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址#下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的(效率很高,同时可以发送特别多请求出出)#爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求#项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作# 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事# 爬虫中间件(Spider Middlewares)位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)# 创建scrapy项目---》使用命令# 创建项目-scrapy startproject 项目名字# 创建爬虫 -scrapy genspider cnblogs www.cnblogs.com# 启动爬虫scrapy crawl cnblogs# 使用脚本运行爬虫
# run.py
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'cnblogs','--nolog'])
scrapy项目目录结构
mysfirstscrapy # 项目名mysfirstscrapy # 包spiders # 包,里面放了自定义的爬虫,类似于app__init__.pybaidu.py # 百度爬虫cnblogs.py#cnblogs爬虫items.py #类似于django的 models表模型,一个个模型类middlewares.py # 中间件pipelines.py #管道---》写持久化settings.py #项目配置文件scrapy.cfg # 项目上线配置# 后期我们只关注spiders中得爬虫和pipelines持久化即可
scrapy解析数据
1 response对象有css方法和xpath方法-css中写css选择器-xpath中写xpath选择
2 重点1:-xpath取文本内容'.//a[contains(@class,"link-title")]/text()'-xpath取属性'.//a[contains(@class,"link-title")]/@href'-css取文本'a.link-title::text'-css取属性'img.image-scale::attr(src)'
3 重点2:.extract_first() 取一个.extract() 取所有
import scrapy# 爬虫类,继承了scrapy.Spider
class CnblogsSpider(scrapy.Spider):name = 'cnblogs' # 爬虫名字allowed_domains = ['www.cnblogs.com'] # 允许爬取的域---》start_urls = ['http://www.cnblogs.com/'] # 开始爬取的地址# css解析解析方法# def parse(self, response):# # print(response.text) # http响应包装成了response# # scrapy 内置了解析库,不需要使用第三方:支持xpath和css# ######css选择器###### # 解析出所有文章# article_list = response.css('article.post-item') # 列表中放对象# print(len(article_list))# # 继续解析文章详情:文章标题,文章摘要,作者图片,作者名字,文章详情地址# for article in article_list:# title = article.css('section>div>a.post-item-title::text').extract_first()# desc = article.css('p.post-item-summary::text').extract()# real_desc = desc[0].replace('\n', '').replace(' ', '')# if real_desc:# desc = real_desc# else:# real_desc = desc[1].replace('\n', '').replace(' ', '')# desc = real_desc# author_img = article.css('p.post-item-summary img::attr(src)').extract_first()# author_name = article.css('footer.post-item-foot span::text').extract_first()# url = article.css('div.post-item-text a::attr(href)').extract_first()# print('''# 文章名字:%s# 文章摘要:%s# 作者图片:%s# 作者名字:%s# 文章地址:%s# ''' % (title, desc, author_img, author_name, url))def parse(self, response):######xpath选择器###### 解析出所有文章article_list = response.xpath('//article[contains(@class,"post-item")]') # 列表中放对象print(len(article_list))# 继续解析文章详情:文章标题,文章摘要,作者图片,作者名字,文章详情地址for article in article_list:# title = article.xpath('./section/div/a/text()').extract_first()title = article.xpath('.//a/text()').extract_first()desc = article.xpath('.//p[contains(@class,"post-item-summary")]/text()').extract()real_desc = desc[0].replace('\n', '').replace(' ', '')if real_desc:desc = real_descelse:real_desc = desc[1].replace('\n', '').replace(' ', '')desc = real_desc# p.post-item-summary img::attr(src)author_img = article.xpath('.//p//img/@src').extract_first()#div.post-item-text a::attr(href)author_name = article.xpath('.//footer//span/text()').extract_first()url = article.xpath('.//div[contains(@class,"post-item-text")]//a/@href').extract_first()print('''文章名字:%s文章摘要:%s作者图片:%s作者名字:%s文章地址:%s''' % (title, desc, author_img, author_name, url))'''
一启动爬虫:把start_urls地址包装成request对象---》
丢给引擎---》调度器---》排队---》引擎---》下载中间件---》下载器---》下载完成---》引擎---》爬虫----》就回到了parse'''
setting配置
基础配置
#1 了解
BOT_NAME = "firstscrapy" #项目名字,整个爬虫名字
#2 爬虫存放位置 了解
SPIDER_MODULES = ["firstscrapy.spiders"]
NEWSPIDER_MODULE = "firstscrapy.spiders"#3 记住 是否遵循爬虫协议,一般都设为False
ROBOTSTXT_OBEY = False
# 4 记住
USER_AGENT = "firstscrapy (+http://www.yourdomain.com)"#5 记住 日志级别
LOG_LEVEL='ERROR'#6 记住 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}#7 记住 后面学 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
#8 后面学 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}#9 后面学 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {'cnblogs.pipelines.CnblogsPipeline': 300,
}
高级配置(提高爬虫效率--scarpy框架)
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s