目录
- Elasticsearch逻辑设计和物理设计
- 逻辑设计
- 物理设计
- Elasticsearch原理
- 倒排索引
- 文档的分析过程
- 保存文档
- 搜索文档
- 写数据的底层原理
- 数据刷新(fresh)
- 事务日志的写入
- ES在大数据量下的性能优化
- 文件系统缓存优化
- 数据预热
- 文档(Document)模型设计
- 分页性能优化
- Elasticsearch和DB的差异
- 参考
Elasticsearch逻辑设计和物理设计
逻辑设计
- 索引(Index):类似于ES中的一张表,可以通过映射(Mapping)定义索引的结构和设置。
- 类型(Type):可以对ES的索引进一步做划分。ES 7中已经移除类型,建议一个索引一个类型即可
- 映射(Mapping):索引结构的定义,包括索引的字段,字段类型,索引的设置等。
- 文档(Document):索引中的一条记录。
物理设计
Elasticsearch本身是分布式搜索引擎。它的高可用、高性能就是通过分片实现的。
- 主分片:一个索引可以划分成多个主分片,通过将主分片分布到不同的ES节点,从而实现高性能。
- 副本分片:副本分片和主分片保持数据同步,和主分片不能分布在同一个节点,从而实现主分片的读能力的横向扩展,同时保证主分片不可用时实现故障转移。

Elasticsearch原理
倒排索引
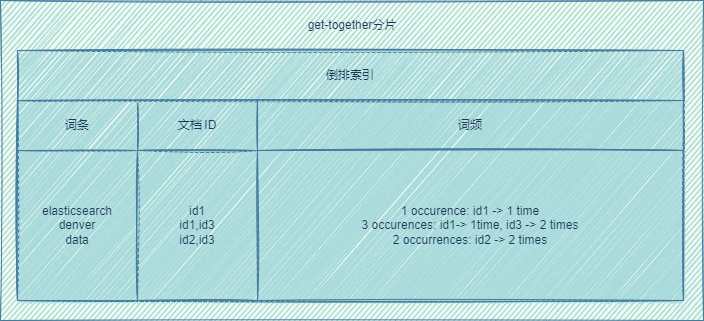
每个文档都有唯一的文档ID,一个文档经过分析器变成一组词条。
倒排索引:记录词条以及词条出现的文档ID的数据结构,同时倒排索引还会记录词条在文档中出现的频率。
文档的分析过程
示例引用自《Elasticsearch实战》。
在文档加入倒排索引之前,需要经过分析器执行分析,转换成一组词条(Term)。
以下是文档“share your experience with Nosql & big data technologies”的分析过程。
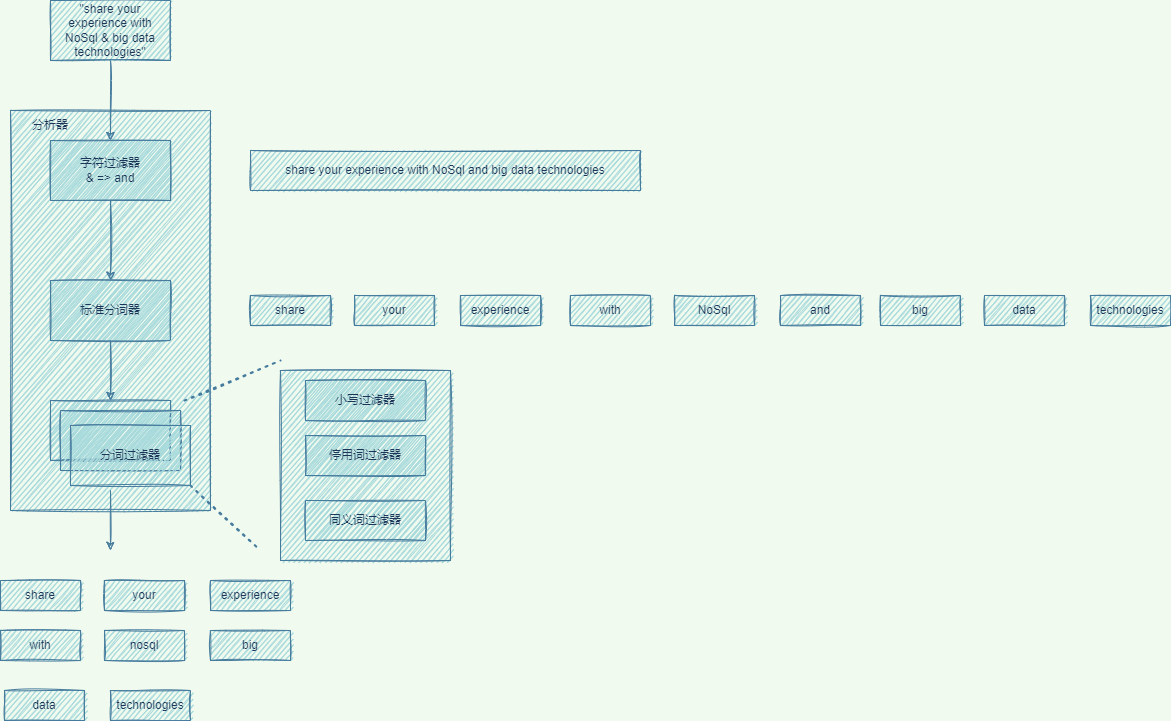
- 过滤字符:字符过滤器转换个别字符。如:将
&转换成and - 切分文本:分词器将文本切分成多个词条
- 过滤分词:一组分词过滤器按序转换每个分词。如:小写分词过滤器,将所有的分词转换成小写。
- 创建索引:为词条创建倒排索引
保存文档
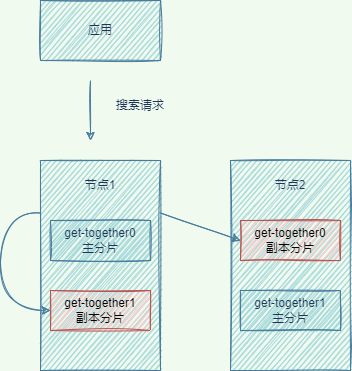
保存文档是写入主分片,然后,同步到副本分片;搜索文档是根据轮询算法,从主分片或副本分片读取。
- 通过计算
文档ID的哈希值,决定文档的目标分片。如果文档的目标分片不在当前节点,将文档转发到目标分片的节点。 - 将文档加入倒排索引
- 将数据同步到所有的副本分片,即在副本分片创建倒排索引
- 所有的副本分片创建倒排索引成功,节点响应结果给客户端
说明:
- 协调节点:接收客户端请求/响应客户端的节点,负责数据的请求转发,数据的汇总。

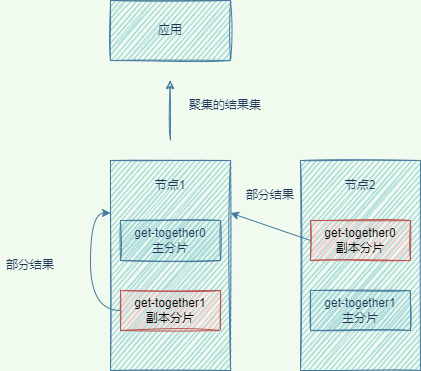
搜索文档
-
协调节点使用round-robin随机循环算法,将请求转发到包含完整数据集合的分片集合(包括主分片和副本分片)。
-
协调节点收集各节点的返回结果,将结果返回客户端:
2.1 查询阶段(Query Phase):每个分片将自己的搜索结果的
文档ID返回给协调节点,协调节点进行数据的合并、排序、分页,得到最终结果。2.2 拉取阶段(Fetch Phase):协调节点根据
文档ID取各个节点上拉取文档数据,最终返回给客户端。
写数据的底层原理
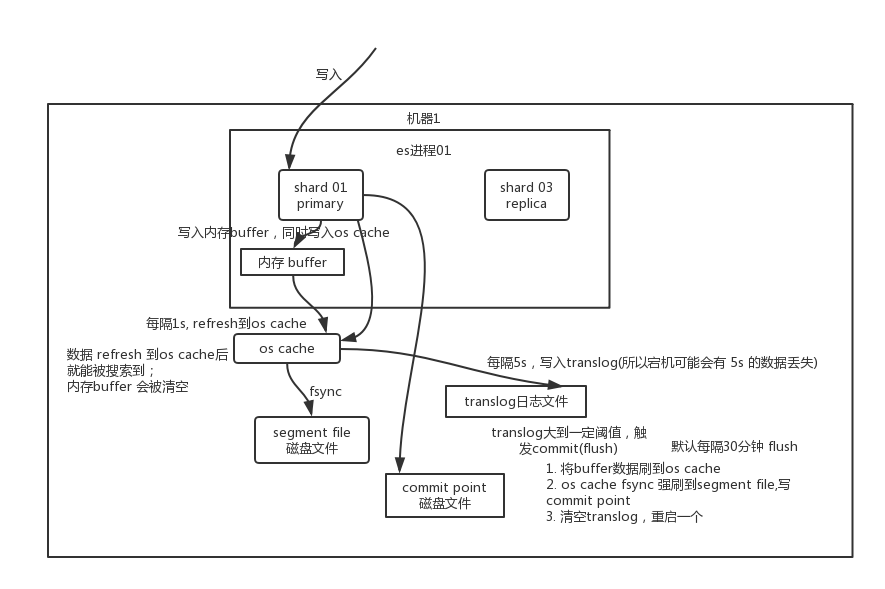
Elasticsearch会将数据先写入内存的缓冲区,这时数据并不能用于查询。
- 刷新数据:缓冲区过大或者默认每隔1秒,将缓冲区中的数据写入段文件(segment file),然后清空缓冲区。数据在缓冲区时是不可见的,变成段文件后,就可以用于查询。段文件不可变,所以每隔一秒ES就会生成一个新的段文件。
- 事务日志的写入:为了防止数据丢失,ES会实时将数据写入事务日志(tranlog)文件,事务日志文件是在磁盘里的。
- 数据冲刷:事务日志过大或者默认每隔30分钟,会触发数据冲刷,会将一个提交点(commit point)中的所有段文件(在操作系统缓冲区中的数据)和缓冲区所有的数据写入磁盘,然后,删除事务日志。
数据刷新(fresh)
数据刷新负责将缓冲区的数据写入段文件。段文件实际上就Lucene索引。出于性能考虑,数据并不是直接写入磁盘的,而是默认每隔1秒,数据从缓冲区写入系统缓存(OS Cache),变成段文件。之后,就可以通过搜索接口查询到对应的数据了。因为,数据都是在内存中的,所以一旦宕机,数据会丢失。ES通过事务日志保存了数据,所以,能够保证数据的恢复。
ES是接近实时的(Near Real-time)
因为,数据是每1秒刷新的系统缓存,之后才可以访问,所以是接近实时的。
事务日志的写入
为了防止数据丢失,数据在写入缓冲区的同时写入事务日志文件。事务日志同样是先写入系统缓存(OS Cache),然后刷新到磁盘。
index.translog.durability参数- 刷盘策略
index.translog.durability取值:
- request:每次请求都执行fsync刷盘,ES要等待日志文件刷盘后才返回成功响应。能够保证数据基本不丢失,但是,性能低下,不推荐使用。
- async:每隔5秒fsync一次translog数据到磁盘,默认值。兼顾数据的持久化和性能。
数据丢失
因为事务日志的默认刷盘方式是每隔5秒fsync一次,所以如果ES宕机,最多可能丢失5秒的数据。
ES在大数据量下的性能优化
文件系统缓存优化
ES中的索引数据会持久化到磁盘中,查询的时候,索引数据从磁盘加载到系统缓存中。
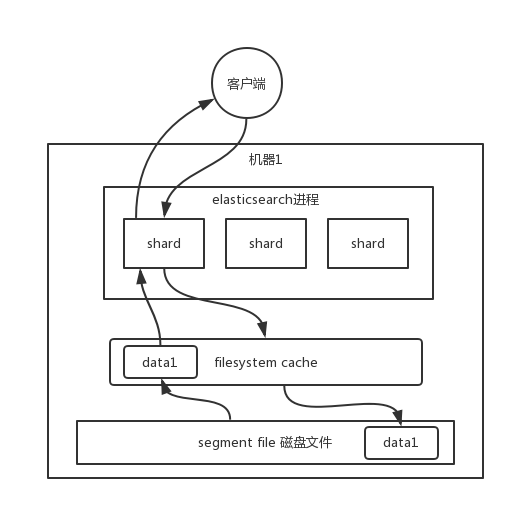
这里的filesystem cache就是上文的OS cache,都是指系统缓存。
ES搜索性能非常依赖于系统缓存,因为系统缓存是在内存中的。如果查询走系统缓存,可以达到几毫秒到几百毫秒不等的查询效率;但是,查询走磁盘的话,搜索性能就要达到秒级。
最佳的情况下,机器的内存要达到容纳总数据量的一半。
ES + HBase
为了减少ES的数据量,可以仅在ES索引中保存用于检索的几个字段,将完整的记录保存在HBase中。查询时,先通过ES获取doc id,然后,根据doc id到HBase获取完整的数据。
数据预热
开启定时任务,定时加载一些频繁被访问的热点数据。如:电商系统中,如iphone,后台开个任务,每隔1分钟访问一次相关数据,刷新到系统缓存中。
文档(Document)模型设计
ES尽量不要使用复杂的操作,如:join(关联)/nested/parent-child,对性能影响很大。
可以在Java应用里完成关联,将关联好的数据写入ES中。
分页性能优化
如果要取第100页的10条数据,那么ES的分页流程如下:
- 将每个分片上的前1000条数据都查到协调节点上,如果有5个分片,那就是5000条数据。
- 接着协调节点对这5000条数据做合并、排序
- 返回第100页的10条数据。
所以,ES的分页越深,查询越慢。
有两种优化方案:
- 不允许深度分页:系统直接不允许深度的分页。
- 通过scroll API:类似于游标,或者Java中的迭代器,访问效率可以达到毫秒级。不过只能一页页的访问,不能随机跳到任意一页访问。
Elasticsearch和DB的差异
- Elasticsearch不支持事务,表连接。
- ES是个自带分布式属性的,高可用、可扩展、高性能,传统关系型数据库存在单机的性能瓶颈
- ES单个字段的数据类型丰富,除了核心的数据类型,还支持多字段,对象类型、数组类型等。
参考
部分图片引用自:advanced-Java
- 《Elasticsearch实战》
- Elasticsearch如何做到亿级数据查询毫秒级返回的:Elasticsearch如何做到亿级数据查询毫秒级返回的? - 掘金
- 互联网 Java 工程师进阶知识完全扫盲 - Doocs 技术社区
- 互联网 Java 工程师进阶知识完全扫盲 - Doocs 技术社区