每日一题系列(day 03)
前言:
🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈
🔎🔎如果说代码有灵魂,那么它的灵魂一定是👉👉算法👈👈,因此,想要写出💚优美的程序💚,核心算法是必不可少的,少年,你渴望力量吗😆😆,想掌握程序的灵魂吗❓❗️那么就必须踏上这样一条漫长的道路🏇🏇,我们要做的,就是斩妖除魔💥💥,打怪升级!💪💪当然切记不可😈走火入魔😈,每日打怪,日日累积,终能成圣🙏🙏!开启我们今天的斩妖之旅吧!✈️✈️
LeetCode-102.二叉树的层序遍历
题目:
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例1:
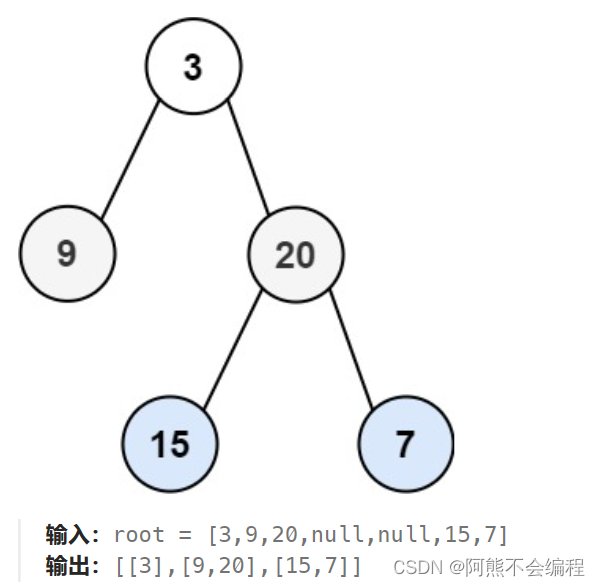
示例2:

注意事项:
- 树中节点数目在范围 [0, 2000] 内
- -1000 <= Node.val <= 1000
解法一:
思路:
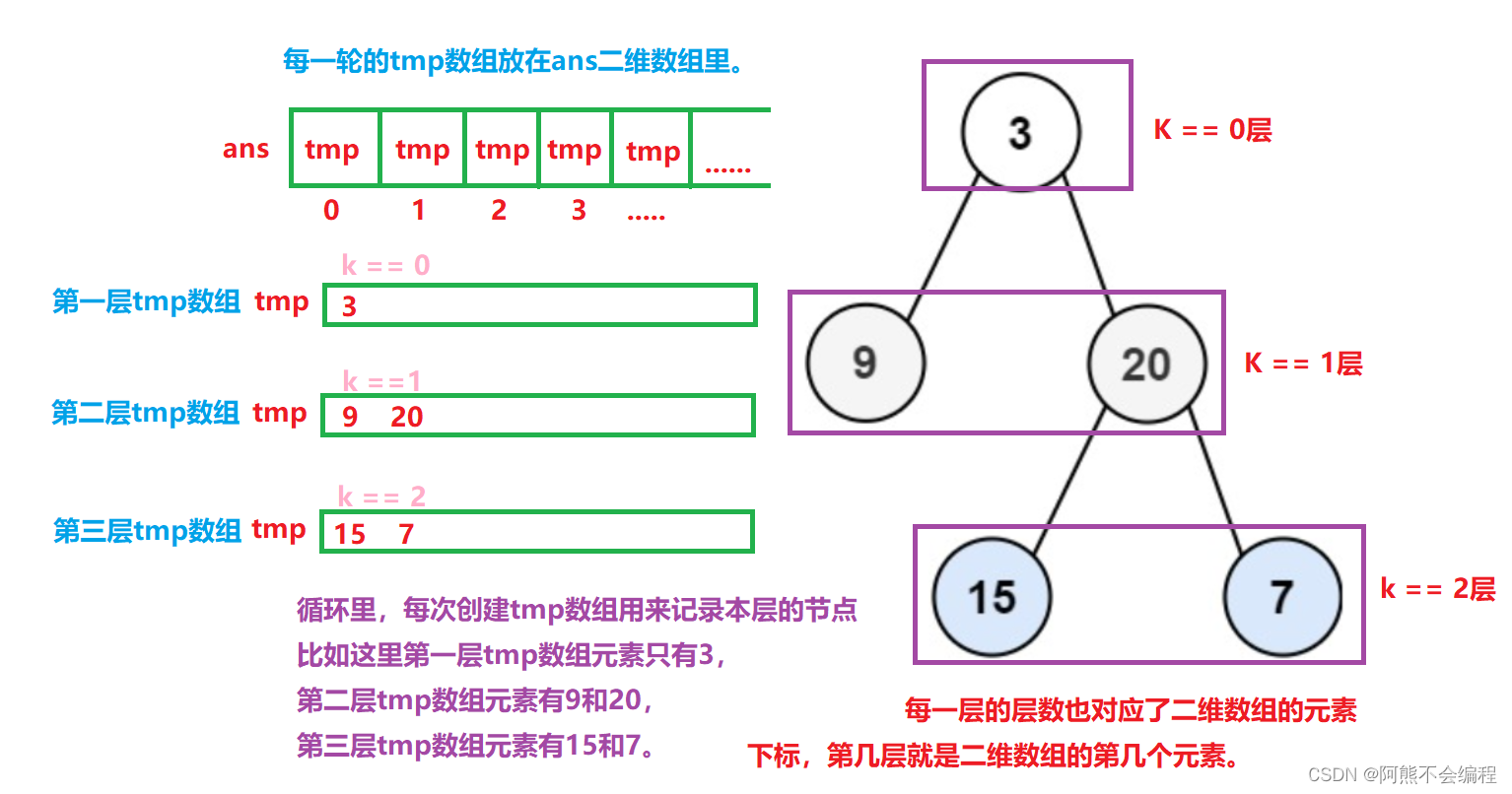
说到二叉树的层序遍历,我们第一反应肯定是用广度优先搜索,广搜需要队列存储每一层的节点,当一层节点处理完之后再将本层已处理的节点全部pop掉,接着处理下一层节点,直到处理完毕,深搜便完成了,这里题目要求用二维数组来接收深搜的结果,所以我们可以开个二维数组,在每层节点pop之前,把每层节点记录在一位数组中,最终把一维数组放到二维数组中。每一层的二维数组都代表每一层的节点的遍历结果。
1、首先,当节点为空的时候我们直接返回空的二维数组。不为空则根据题目要求创建一个二维数组,再创建队列来记录二叉树的每个节点,再将根节点压入到队列中。
2、节点已经入队,开始处理二叉树。我们知道,二叉树有很多层,所以我们需要一层一层来遍历,每一层处理完后,本层节点也被pop,再处理下一层,其实这就是一个循环的过程。条件是只要不为空就一直处理。
3、在循环内,创建一个临时一维数组来记录本层所有节点的值,用计数器来记录这层拥有的节点个数,再使用for循环处理每一层的节点。
4、for循环内,取队头元素,将队头的元素值压入本层的一维数组中,当处理的当前节点时,如果当前节点有子节点,就把下一层的子节点入队,用来下次的遍历,最后再将当前已经处理完了的节点pop出队列。
5、最后直接返回二维数组即可。
代码实现:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {if(root == NULL)vector<vector<int>> ans;//根据题目要求创建一个二维数组return vector<vector<int>>();//节点为空直接返回空的二维数组即可queue<TreeNode *> q;//创建一个队列用来记录每一层的节点TreeNode *node = nullptr;//记录队列的每个节点,便于处理单个节点q.push(root);//将根节点压入队列while(!q.empty())//只要队列不为空说明这一层还存在节点{int cnt = q.size();//记录队列节点数量vector<int> tmp;//使用tmp数组接收每一层的节点for(int i = 0 ; i < cnt ; i++)//处理每层的节点{node = q.front();//记录取队头节点tmp.push_back(node -> val);//在队列这层节点pop之前将节点值压入本层的一维数组,这个一维数组就是这层节点if(node -> left) q.push(node -> left);//本层节点的左子树存在就把左孩子入队列,下次处理if(node -> right) q.push(node -> right);//本层节点的右子树存在就把右孩子入队列,下次处理q.pop();//本层节点处理完,把本层pop掉,处理下一层节点}ans.push_back(tmp);//将一维数组(本层遍历结果)尾插进二维数组}return ans;//返回二维数组即可}
};
解法二:
思路:
其实这题完全可以不用广搜,使用深搜也能进行层序遍历,并且使用深搜的代码会更加简洁一些。使用深搜也就是dfs,那么如何深搜才是关键,其实我们只需要知道每个节点的层数就可以进行深搜了,我们可以直接用节点的层数把深搜的每个节点压入到对应层的数组中。
1、在深度优先搜索前,我们按照题目要求先创建一个二维数组,然后进行深搜,这里需要注意,dfs的参数首先要传入根节点,在传入从哪层开始处理的层次(从第0层开始处理),最后再传参二维数组的引用。
2、进入到深搜,如果节点为空的话直接返回。当本层层数与二维数组存储的一维数组数量相等,表示已经处理到当前的层数了,这个时候在二维数组当前层数(下标)插入一个空一维数组。
3、接下来就将每一层的节点插入到对应层的一维数组中,然后向左子树搜索,左子树为当前层的下一层,所以传参k + 1,然后向右子树搜索,同样层数为k + 1,最后return即可。
代码实现:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:void dfs(TreeNode *root, int k, vector<vector<int>> &ans)//传参需要根节点,节点所在层数,以及二维数组的引用传参{if(root == NULL) return;//根节点为null直接返回if(k == ans.size()) ans.push_back(vector<int>());//当当前层数与二维数组存储一维数组数量相同时,表示处理到当前的层数了,对二维数组进行尾插一个空一维数组ans[k].push_back(root -> val);//将每一层的节点尾插到每一层的数组里dfs(root -> left, k + 1, ans);//深搜左子树,下一层节点层数要加一dfs(root -> right, k + 1, ans);//同样,深搜下一层右子树,层数加一return;//深搜结束}vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> ans;//创建二维数组dfs(root, 0, ans);//进行深搜return ans;//返回深搜结果即可}
};
二叉树的层序遍历,我们通常是使用第一种队列的方式进行广度优先搜索,然而用深度优先搜索来对二叉树层序遍历的代码设计感更优美,可读性也更高。