浅谈扩散模型的有分类器引导和无分类器引导 - 知乎这篇文章主要比较一下扩散模型的引导生成的三种做法的区别。它们分别是用显式分类器引导生成的做法,用隐式无分类器引导的做法和用CLIP计算跨模态间的损失来引导生成的做法。 Classifier-Guidance: Diffusion Mode…![]() https://zhuanlan.zhihu.com/p/582880086通俗理解Classifier Guidance 和 Classifier-Free Guidance 的扩散模型 - 知乎【当一个扩散模型训练好了之后,如何进行条件生成,例如如何按类别生成?】一、 Classifier Guidance Diffusion2021年OpenAI在「 Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使…
https://zhuanlan.zhihu.com/p/582880086通俗理解Classifier Guidance 和 Classifier-Free Guidance 的扩散模型 - 知乎【当一个扩散模型训练好了之后,如何进行条件生成,例如如何按类别生成?】一、 Classifier Guidance Diffusion2021年OpenAI在「 Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使…![]() https://zhuanlan.zhihu.com/p/640631667Diffusion学习笔记(五)——Conditional Control(Classifier-Guidance and Classifier-Free) - 知乎前几篇文章都是讨论无条件生成式的Diffusion模型,只能随机采样,无法控制模型的输出。但很多时候,我们要求得到与指定文本信息或者与图像信息对应的输出(即文生图或图生图),这就需要用到条件控制生成技术了。…
https://zhuanlan.zhihu.com/p/640631667Diffusion学习笔记(五)——Conditional Control(Classifier-Guidance and Classifier-Free) - 知乎前几篇文章都是讨论无条件生成式的Diffusion模型,只能随机采样,无法控制模型的输出。但很多时候,我们要求得到与指定文本信息或者与图像信息对应的输出(即文生图或图生图),这就需要用到条件控制生成技术了。…![]() https://zhuanlan.zhihu.com/p/623837604[论文理解] Classifier-Free Diffusion Guidance – sunlin-ai关于 Classifier-Free Diffusion 的论文理解
https://zhuanlan.zhihu.com/p/623837604[论文理解] Classifier-Free Diffusion Guidance – sunlin-ai关于 Classifier-Free Diffusion 的论文理解![]() https://sunlin-ai.github.io/2022/06/01/Classifier-Free-Diffusion.htmlclassifer gudiance的classifer是用于生成任务还是分类任务? - 知乎和classifier-free guidance的区别是什么?
https://sunlin-ai.github.io/2022/06/01/Classifier-Free-Diffusion.htmlclassifer gudiance的classifer是用于生成任务还是分类任务? - 知乎和classifier-free guidance的区别是什么?![]() https://www.zhihu.com/question/607447662扩散模型引导生成的三种做法:1.classifier guidance,显式分类器引导生成;2.classifier-free guidance隐式无分类器引导生成;3.clip计算跨模态间的损失引导生成。其中第1种和第2种可以描述为:1.classifier guidance是无条件输入+classifier指导;2.classifier-free guidance是条件输入+无条件输入。
https://www.zhihu.com/question/607447662扩散模型引导生成的三种做法:1.classifier guidance,显式分类器引导生成;2.classifier-free guidance隐式无分类器引导生成;3.clip计算跨模态间的损失引导生成。其中第1种和第2种可以描述为:1.classifier guidance是无条件输入+classifier指导;2.classifier-free guidance是条件输入+无条件输入。
1.classifier guidance 显式分类器引导生成
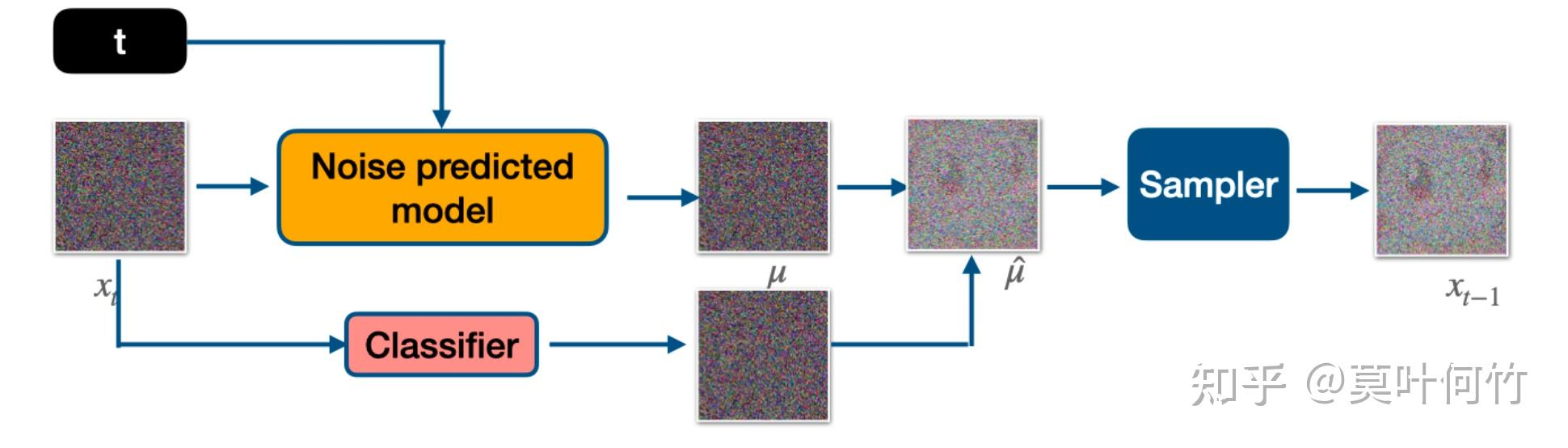
也叫事后修改,即给定一个训练好的无条件diffusion模型,再进行条件控制输出。扩散模型的前向扩散过程和后向去噪过程都可以用一个随机微分方程表示,其中后向去噪时,可以通过一个神经网络来拟合当前输入关于原数据分布的梯度,来将一个先验分布(如高斯分布)里采样出的点逐渐推进到数据分布里。后向生成可以看成是一个马尔科夫蒙特卡洛采样过程,其中每一步的转移方程都是沿着往数据分布的梯度方向迈进,且该方向由神经网络的输出来拟合。DDPM里扩散网络预测的噪声实际上是往数据分布的转移梯度。

生成符合原数据分布的点,可以通过逐步往该网络的预测梯度方向行走来获得最终数据点。但是这样的无条件生成是无法做到条件生成的,2021年openai在diffusion models beat gans on image synthesis中提出classifier guidance,使得扩散模型能够按类别生成。将条件生成对输入的对数梯度用贝叶斯拆解一下:

想要获得数据分布里在条件约束下的数据点时,实际只要在往数据方向的梯度方向上再额外添加一个分类器的梯度方向即可。classifier guidance需要训练噪声数据版本的classifier网络,推理是每一步都需要额外计算classifier的梯度。

多了y关于x的梯度,这个就是classifier guidance。其中logp(y|x)是classifier。

在DDIM中,噪声估计加上分类器引导的梯度。可以把stable diffusion的预训练模型拿来用,text设置为空,根据它训练一个classifier,实现类别指导生成。
2.classifier-free guidance
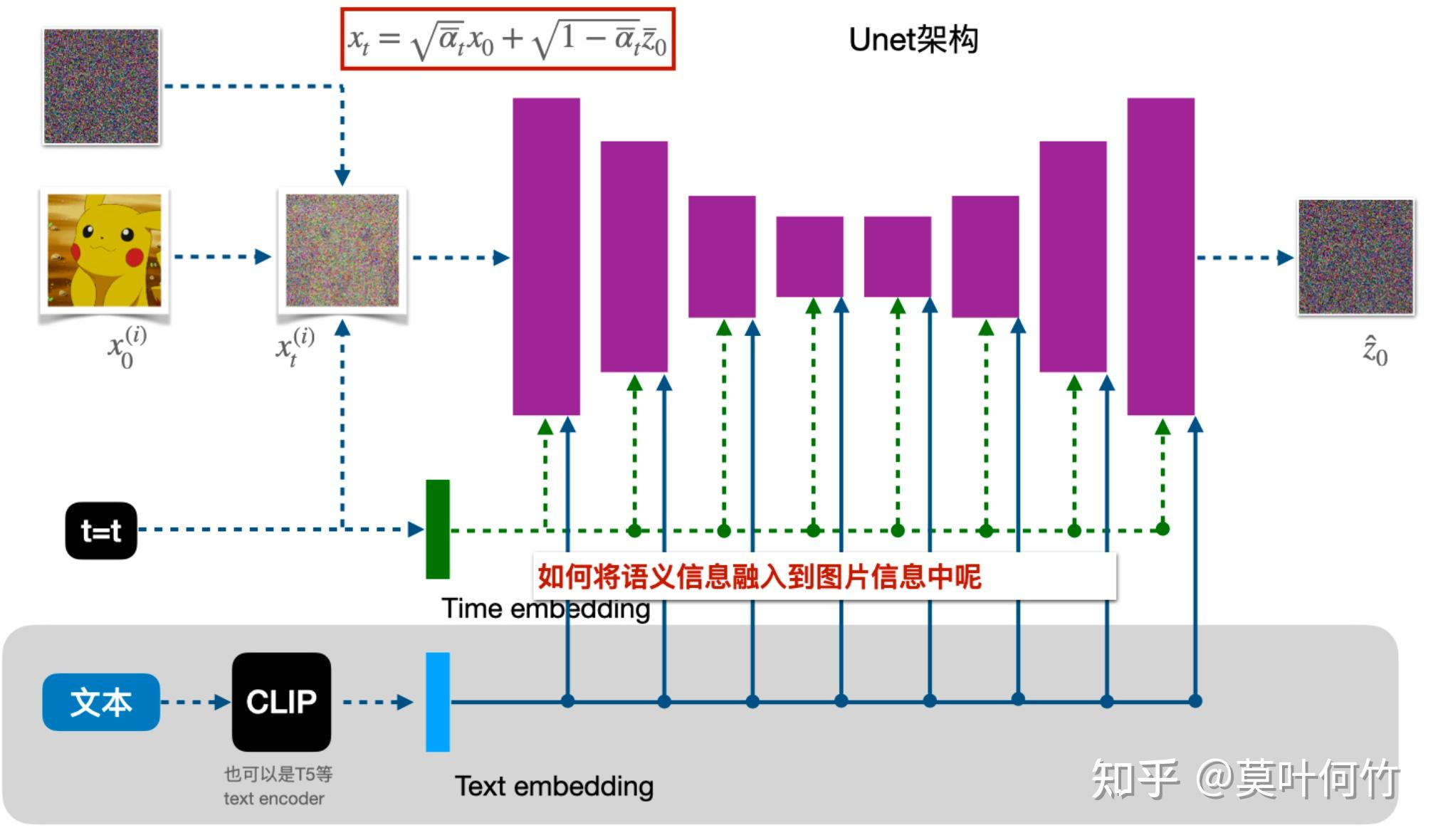
也叫事前修改,即直接将条件y加入到训练过程中。classifier guidance使用显式的分类器有几个问题:1.需要额外训练一个噪声版本的图像分类器;2.该分类器的质量会影响类别生成的效果;3.通过梯度更新图像会导致对抗攻击效应,生成图像可能会通过人眼不可察觉的细节欺骗分类器,实际上并没有按条件生成。谷歌2022年提出classifier-free guidance,可以通过调节引导权重,控制生成图像的逼真性和多样性的平衡,dalle2、imagen、glide和stable dffusion等都是以classifier-free guidance为基础进行训练和推理。classifier-free guidance是通过一个隐式分类器来替代显式分类器,而无需直接计算显式分类器及其梯度。分类器的梯度可以用条件生成概率和无条件生成概率表示:

新的生成过程不再依赖显式的classifier,训练时,classifier-free guidance需要训练两个模型,一个是无条件生成模型(DDPM),一个是条件生成模型,这两个模型可以用一个模型表示,训练时只需要在无条件生成时将条件向量置为零即可。推理时,最终结果可以由条件生成和无条件生成的线性外推获得,生成效果可以由引导系数调节,控制样本生成的逼真性和多样性。
classifier-free guidance一方面大大减轻了条件生成的训练代价,无需训练额外的分类器,只需要在训练时进行随机drop out condition来同时训练两个目标,另一方面,这样的条件生成并不是以一个类似于对抗攻击的方式进行。上面的采样式子,实际上是另个梯度的差值所形成的。在训练时同时算了e(xt,t,y)和e(xt,t),然后计算差值就到了加条件的目的。
在stable-diffusion-webui中,negative prompt实际上就用了无分类器引导的公式,将无条件生成转成不想要的提示的条件生成。
既然网络可以接受条件输入,输出不就自然是根据条件引导生成的结果,为什么还要用无条件的结果?并不是在生成网络加个条件输入就是条件生成,条件生成可理解为条件概率问题,cfg是根据隐分类器推导成线性外插的形式。classifier-guidance是每一步要训练一个分类器引导;classifier-free guidance不用训练分类器,只要在训练条件生成模型时,给一个空条件,然后使用真实条件引导+空条件引导来更好的控制条件生成。
stable diffusion在训练过程中,采用classifier-free guidance,就是在训练条件扩散模型的同时也训练一个无条件扩散模型,同时在采样阶段将条件控制下预测的噪声和无条件控制下的预测噪声组合在一起来确定最终的噪声。
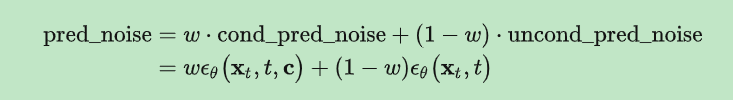
这里w是guidance scale,当w越大时,condition起的作用越大,即生成的图像和输入文本一致,cfg实现很简单,在训练过程中,只需要以一定概率(比如10%)随机drop掉text即可,我们可以将text置为空字符串。
3.clip损失引导生成
通过使扩散生成的图像和目标文本的多模态clip损失尽可能小来达到目的。