目录
一:爬虫基础
二:安装html解析的python工具
三:爬取网页图片
一:爬虫基础
爬虫基本过程:
1.请求标头 headers
2.创建一个会话 requests.Session
3.确定请求的路径
4.根据路径获取网页资源(HTML文件)
5.解析html文件BeautifulSoup div a 标签 获取对应的图片
6.建立网络连接进行下载 创建出下载的图片
了解基本HTML结构
保存带有图片的网页
查找带有data-imgurl属性的标签获取url
<html><head></head><body></body>
</html>头:引用资源
体:包含一切标签
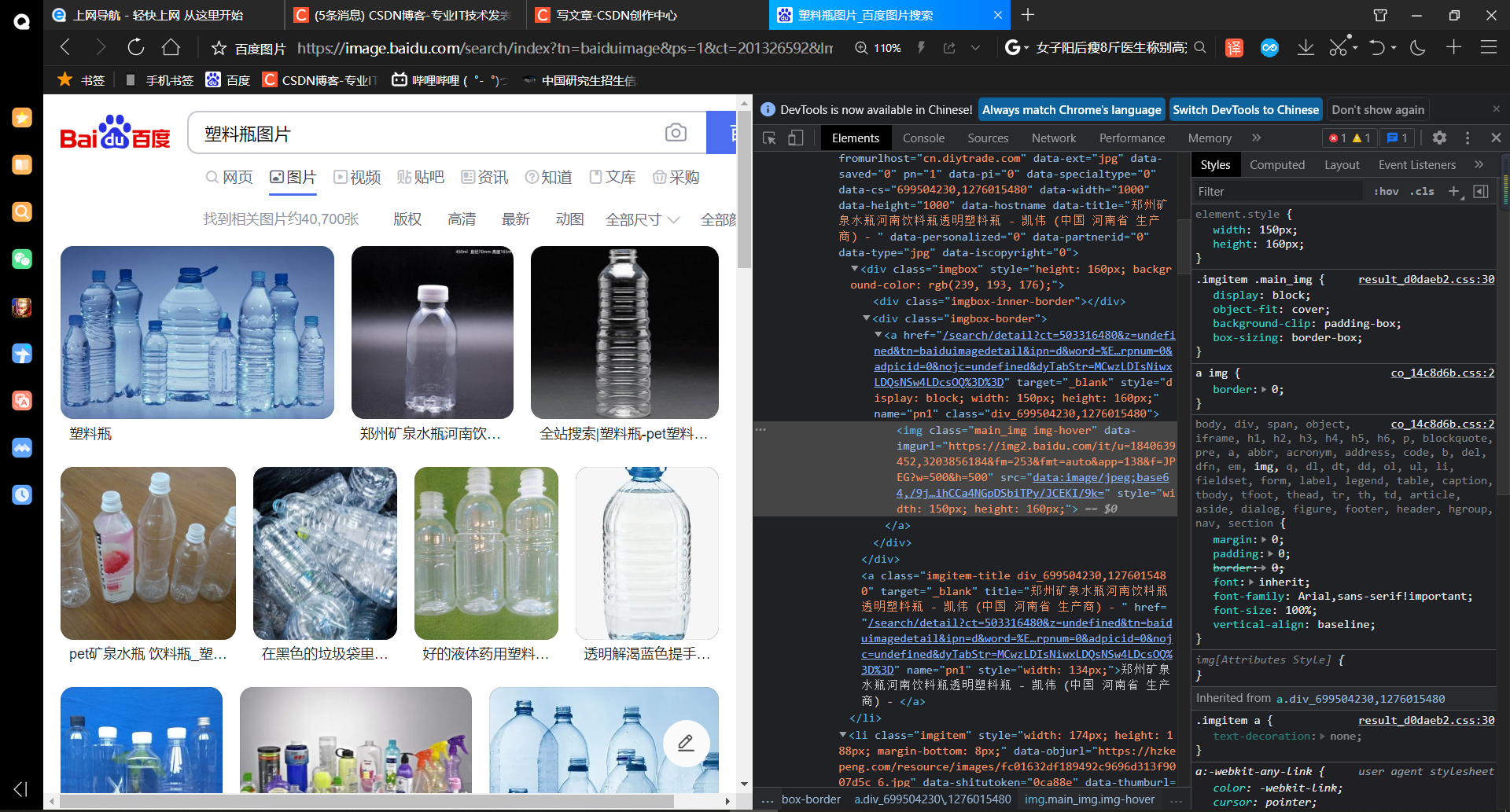
可以 F12 或者 ctrl+shift+i 打开控制台,查看网页代码,获取自己想要的信息



二:安装html解析的python工具
具体可以参考下面的这篇文章:
https://blog.csdn.net/m0_56051805/article/details/128407402
三:爬取网页图片
以爬取百度网页图片为例,大致实现如下
根据地址查找对应图片的信息:
# 根据地址去查找 对应的图片的信息
def Find(url, A):global List # 保存信息的列表print('正在检测图片总数,请稍等.....')t = 0i = 1s = 0while t < 1000:# 时间戳 不简单刷新访问网址Url = url + str(t)try:# get获取数据Result = A.get(Url, timeout=7, allow_redirects=False)except BaseException:t = t + 60continueelse:# 拿到网站的数据result = Result.text# 找到图片urlpic_url = re.findall('"objURL":"(.*?)",', result, re.S)# 图片总数s += len(pic_url)if len(pic_url) == 0:breakelse:List.append(pic_url)t = t + 60return s记录下相关的数据信息:
# 记录相关数据
def recommend(url):Re = []try:html = requests.get(url, allow_redirects=False)except error.HTTPError as e:returnelse:html.encoding = 'utf-8'# html文件解析bsObj = BeautifulSoup(html.text, 'html.parser')div = bsObj.find('div', id='topRS')if div is not None:listA = div.findAll('a')for i in listA:if i is not None:Re.append(i.get_text())return Re对相应网页的图片进行下载:
# 下载图片
def dowmloadPicture(html, keyword):global num# 找到图片urlpic_url = re.findall('"objURL":"(.*?)",', html, re.S)print('找到关键词:' + keyword + '的图片,开始下载图片....')for each in pic_url:print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))try:if each is not None:pic = requests.get(each, timeout=7)else:continueexcept BaseException:print('错误,当前图片无法下载')continueelse:string = file + r'\\' + str(num) + '.jpg'fp = open(string, 'wb')fp.write(pic.content)fp.close()num += 1if num >= numPicture:return伪装成浏览器向网页提取服务:
if __name__ == '__main__': # 主函数入口# 模拟浏览器 请求数据 伪装成浏览器向网页提取服务headers = {'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0','Upgrade-Insecure-Requests': '1'}# 创建一个请求的会话A = requests.Session()# 设置头部信息A.headers = headersword = input("输入要搜索的关键词:")# 拼接路径url = 'https://image.baidu.com/search/flip?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs1&word=' + word# 根据路径去查找total = Find(url, A)# 记录相关推荐图片Recommend = recommend(url)print('经过检测%s类图片共有%d张' % (word, total))numPicture = int(input('输入要下载的数量'))file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')y = os.path.exists(file)if y == 1:print('该文件已存在,请重新输入')file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')os.mkdir(file)else:os.mkdir(file)t = 0tmp = urlwhile t < numPicture:try:url = tmp + str(t)result = requests.get(url, timeout=10)print(url)except error.HTTPError as e:print('网络错误,请调整网络后重试')t = t + 60else:dowmloadPicture(result.text, word)t = t + 60
测试过程如下
1 输入要搜索的图片,可以检索网页图片的数量

2 输入自己想要下载的图片数量,同时创建一个存储下载图片的文件夹

3 等待下载完即可

4 到新创建的文件夹下可以查看到,网页上获取到的图片已经下载


文章学习自: 学术菜鸟小晨 博主的文章
百度,搜狗,360网络爬图
完整源码分享如下
import re
import requests
from urllib import error
from bs4 import BeautifulSoup
import osnum = 0
numPicture = 0
file = ''
List = []# 根据地址去查找 对应的图片的信息
def Find(url, A):global List # 保存信息的列表print('正在检测图片总数,请稍等.....')t = 0i = 1s = 0while t < 1000:# 时间戳 不简单刷新访问网址Url = url + str(t)try:# get获取数据Result = A.get(Url, timeout=7, allow_redirects=False)except BaseException:t = t + 60continueelse:# 拿到网站的数据result = Result.text# 找到图片urlpic_url = re.findall('"objURL":"(.*?)",', result, re.S)# 图片总数s += len(pic_url)if len(pic_url) == 0:breakelse:List.append(pic_url)t = t + 60return s# 记录相关数据
def recommend(url):Re = []try:html = requests.get(url, allow_redirects=False)except error.HTTPError as e:returnelse:html.encoding = 'utf-8'# html文件解析bsObj = BeautifulSoup(html.text, 'html.parser')div = bsObj.find('div', id='topRS')if div is not None:listA = div.findAll('a')for i in listA:if i is not None:Re.append(i.get_text())return Re# 下载图片
def dowmloadPicture(html, keyword):global num# 找到图片urlpic_url = re.findall('"objURL":"(.*?)",', html, re.S)print('找到关键词:' + keyword + '的图片,开始下载图片....')for each in pic_url:print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))try:if each is not None:pic = requests.get(each, timeout=7)else:continueexcept BaseException:print('错误,当前图片无法下载')continueelse:string = file + r'\\' + str(num) + '.jpg'fp = open(string, 'wb')fp.write(pic.content)fp.close()num += 1if num >= numPicture:returnif __name__ == '__main__': # 主函数入口# 模拟浏览器 请求数据 伪装成浏览器向网页提取服务headers = {'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0','Upgrade-Insecure-Requests': '1'}# 创建一个请求的会话A = requests.Session()# 设置头部信息A.headers = headersword = input("输入要搜索的关键词:")# 拼接路径url = 'https://image.baidu.com/search/flip?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs1&word=' + word# 根据路径去查找total = Find(url, A)# 记录相关推荐图片Recommend = recommend(url)print('经过检测%s类图片共有%d张' % (word, total))numPicture = int(input('输入要下载的数量'))file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')y = os.path.exists(file)if y == 1:print('该文件已存在,请重新输入')file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')os.mkdir(file)else:os.mkdir(file)t = 0tmp = urlwhile t < numPicture:try:url = tmp + str(t)result = requests.get(url, timeout=10)print(url)except error.HTTPError as e:print('网络错误,请调整网络后重试')t = t + 60else:dowmloadPicture(result.text, word)t = t + 60


![[Python程序打包: 使用PyInstaller制作单文件exe以及打包GUI程序详解]](https://img-blog.csdnimg.cn/44a82c678d4f4444b617005e86de3e91.png)