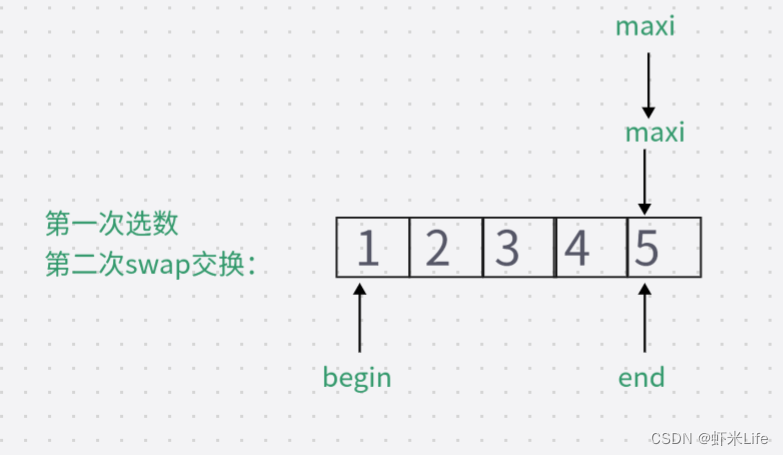
RocketMQ源码深入剖析
6 Broker源码分析
Broker模块涉及到的内容非常多,本课程重点讲解以下技术点:
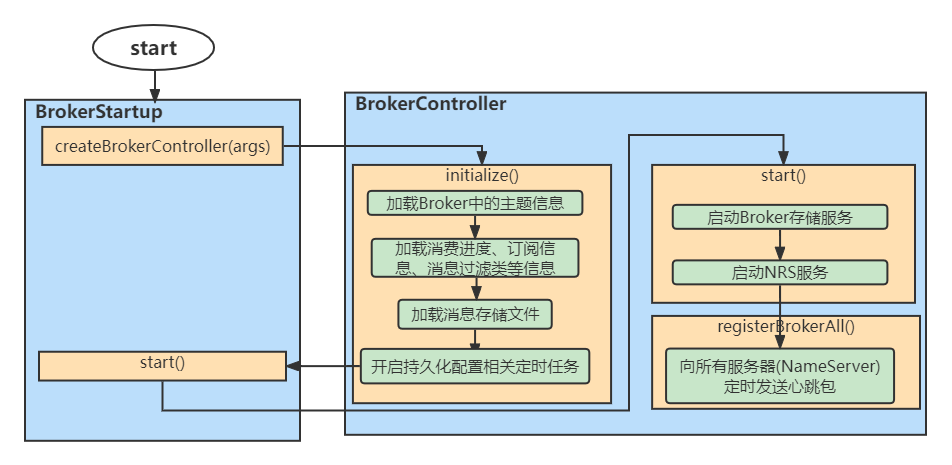
1、Broker启动流程分析
2、消息存储设计
3、消息写入流程
4、亮点分析:NRS与NRC的功能号设计
5、亮点分析:同步双写数倍性能提升的CompletableFuture
6、亮点分析:Commitlog写入时使用可重入锁还是自旋锁?
7、亮点分析:零拷贝技术之MMAP提升文件读写性能
8、亮点分析:堆外内存机制
6.1 Broker启动流程分析
在RocketMQ中Broker的处理是最多的,所以我们先分析Broker的启动流程。核心流程图如下
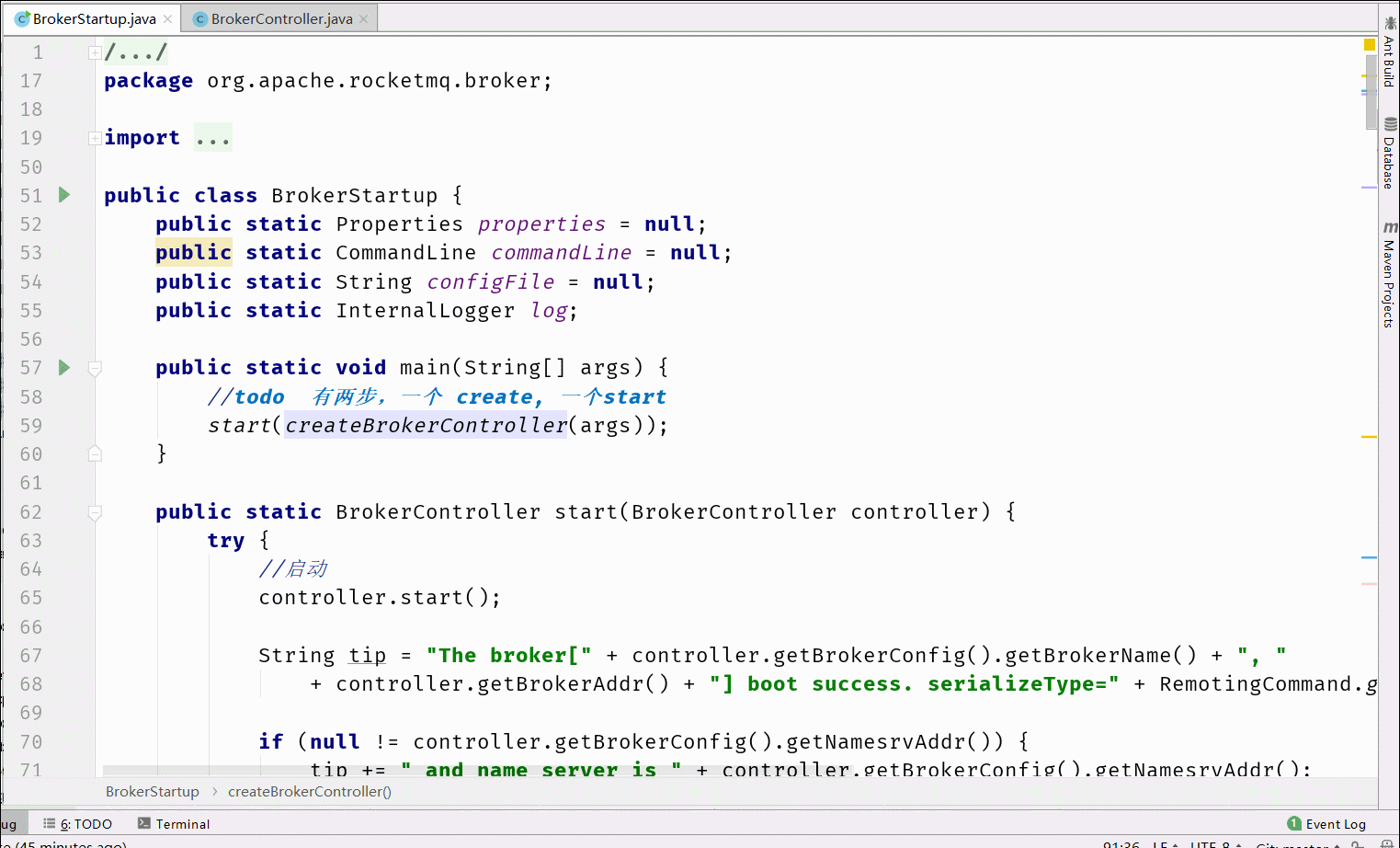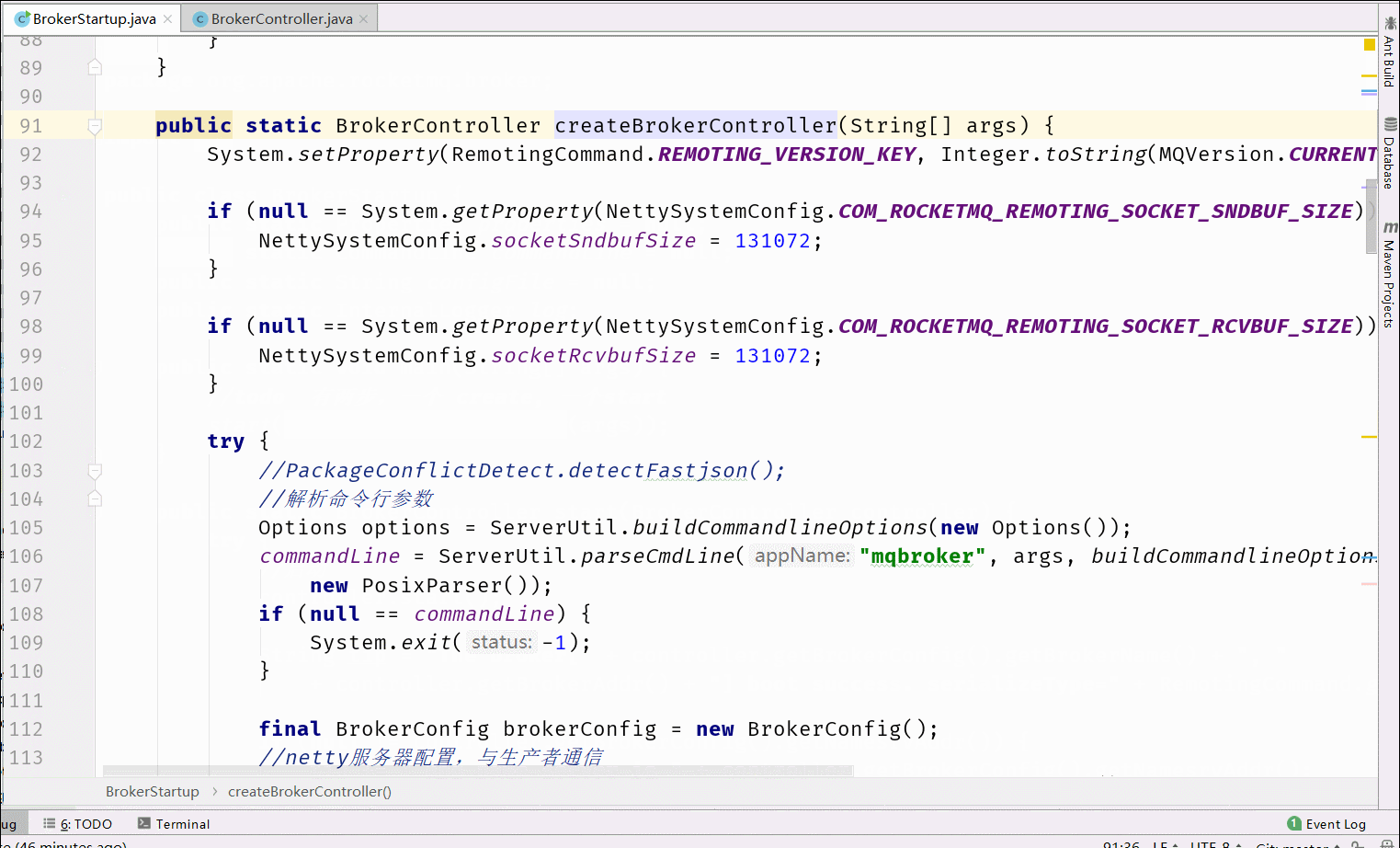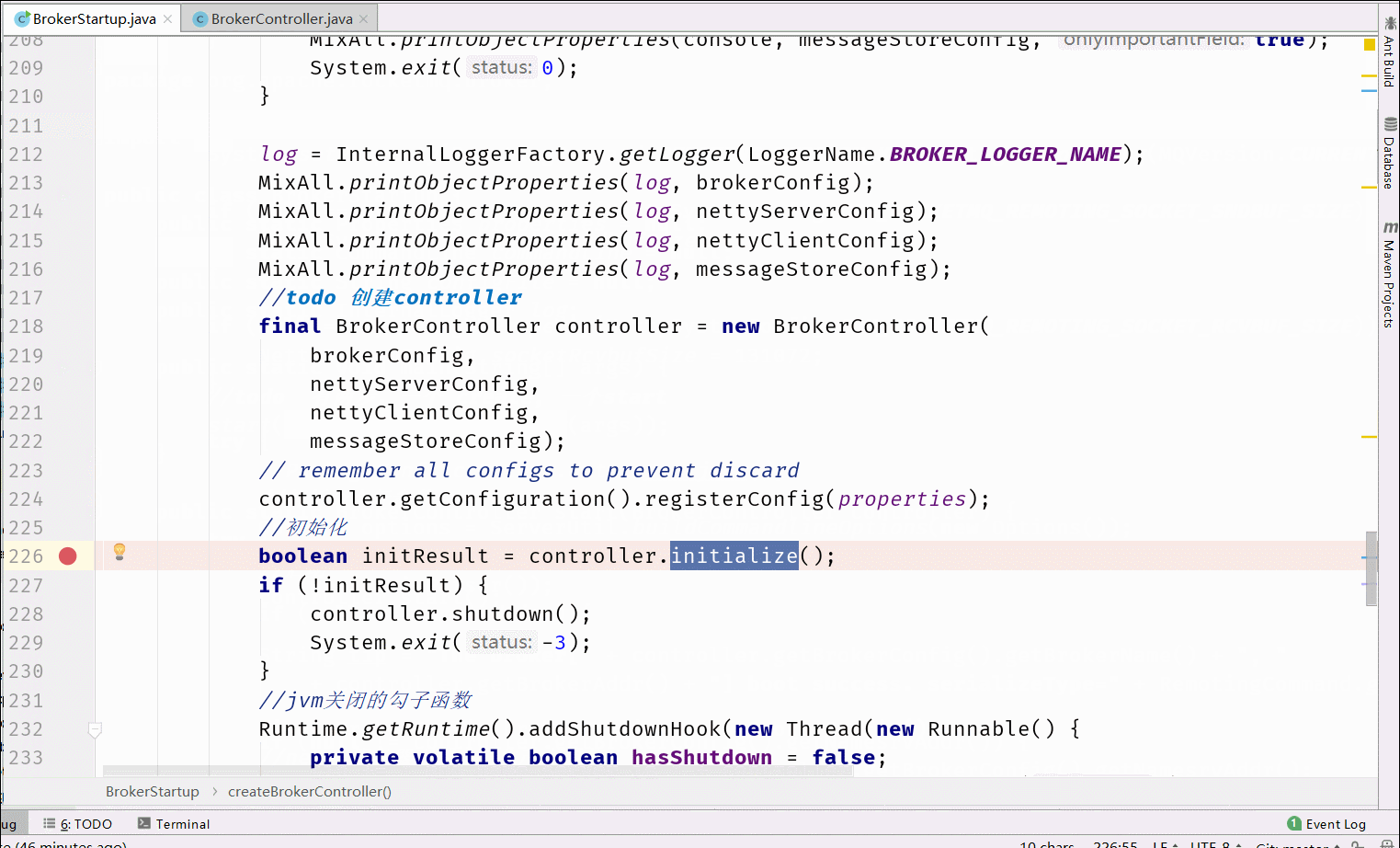
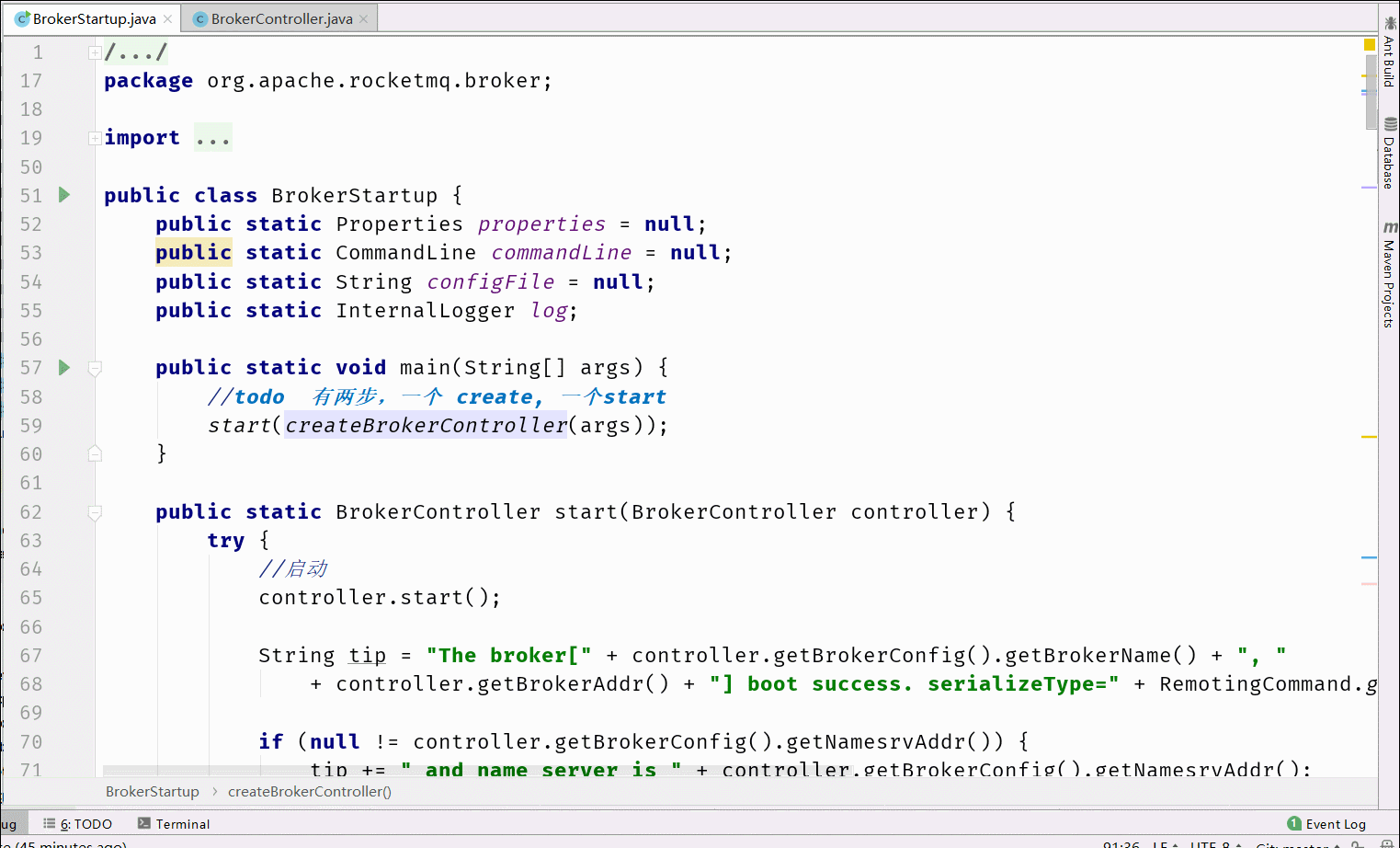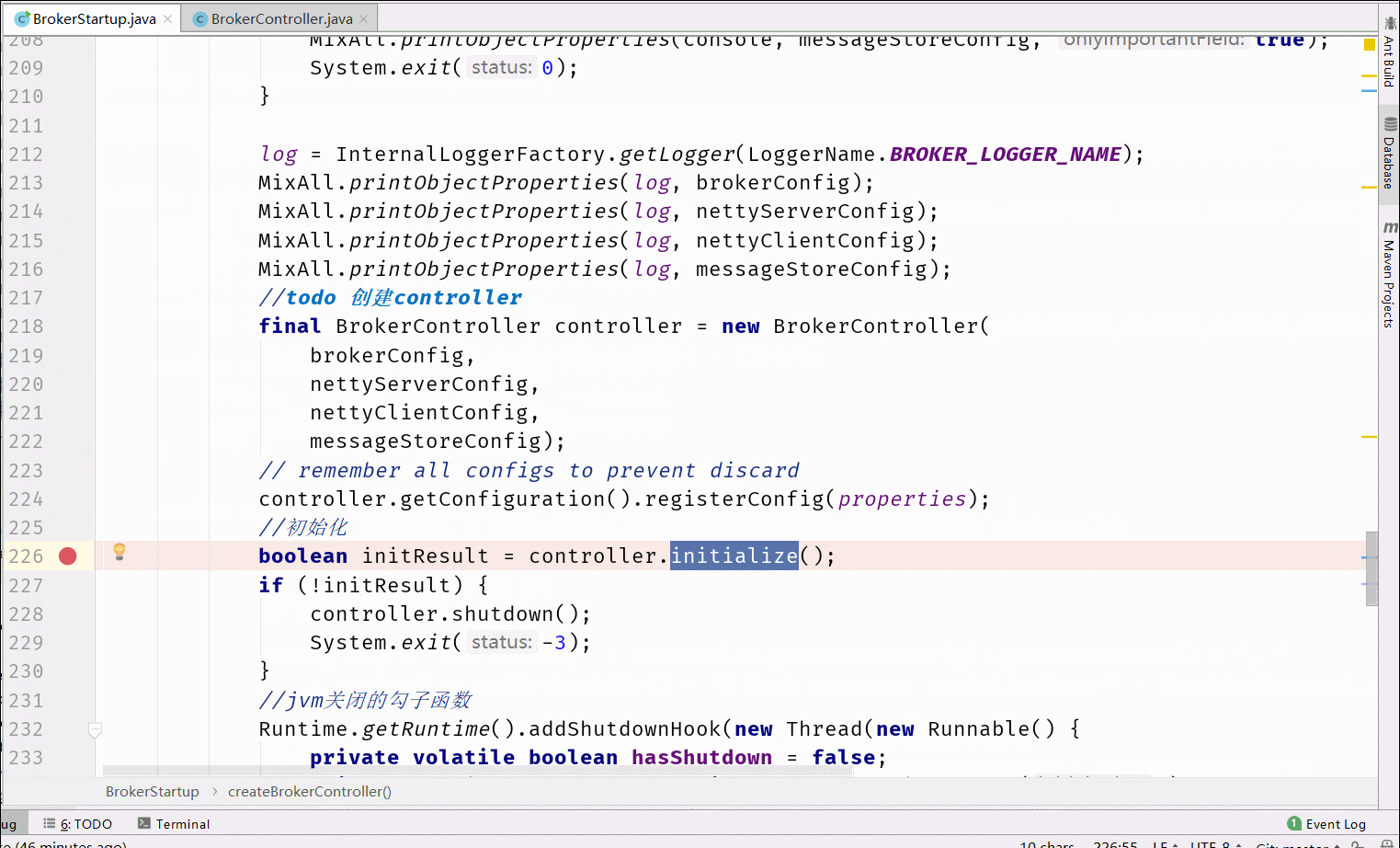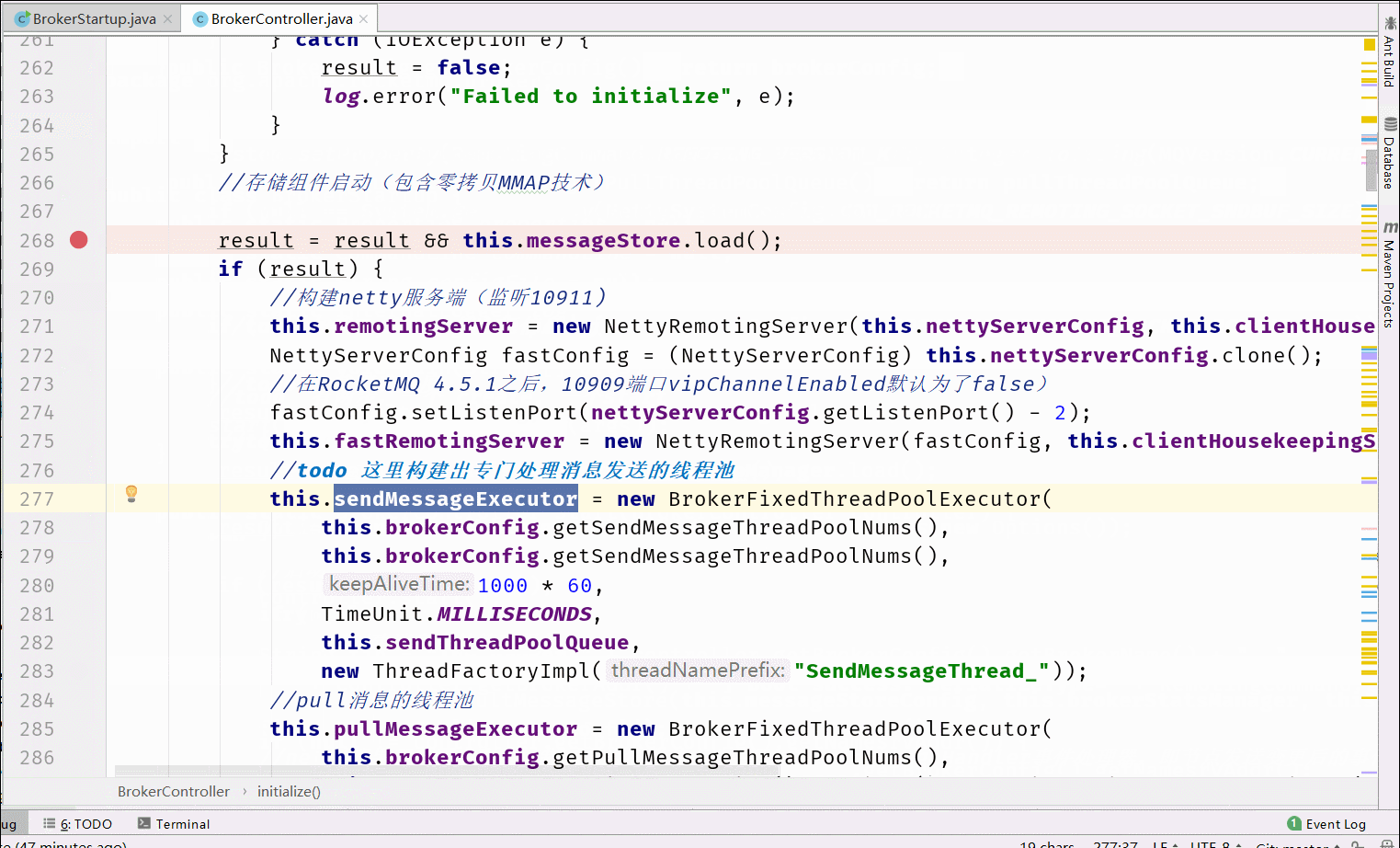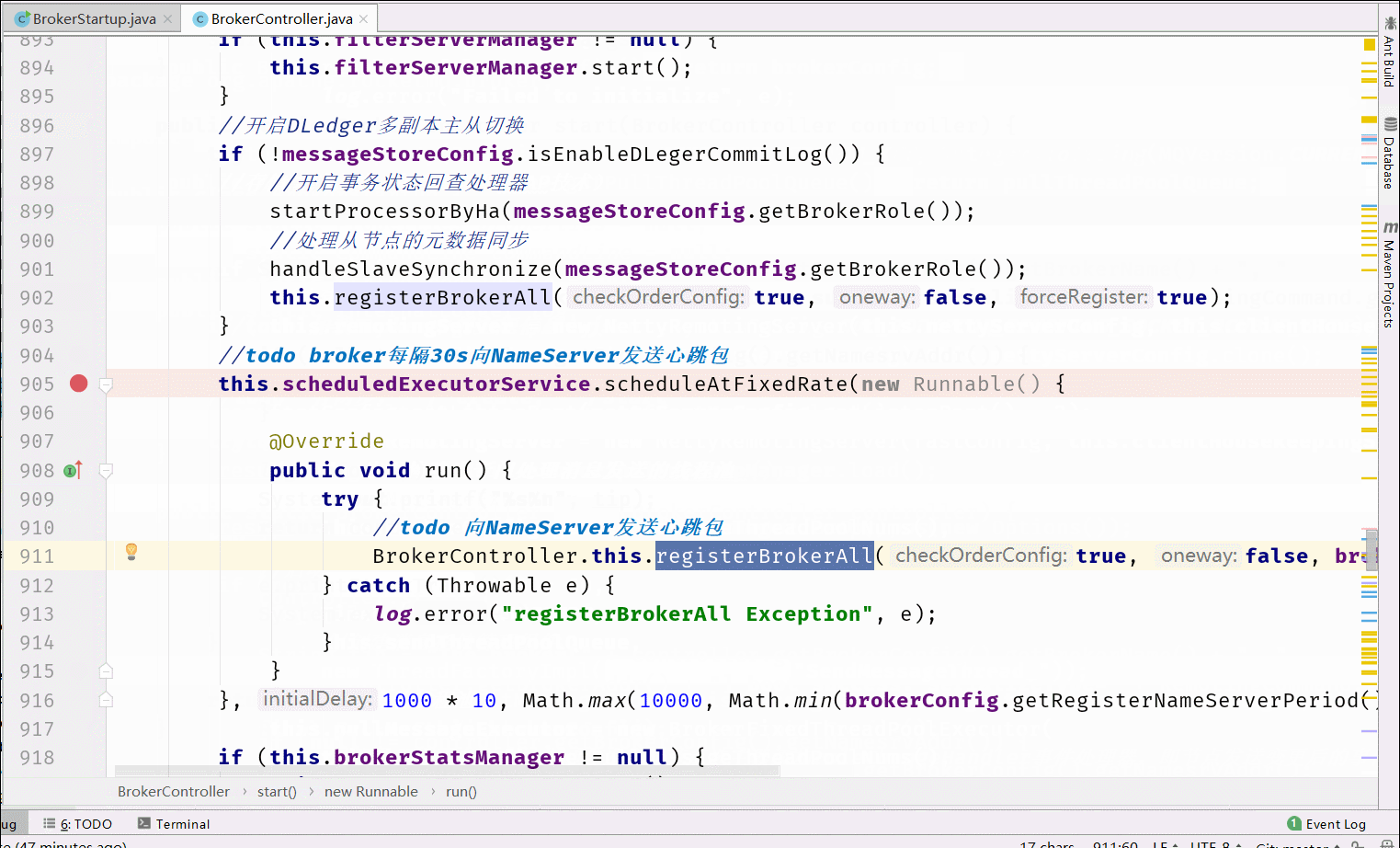
6.2 消息存储设计
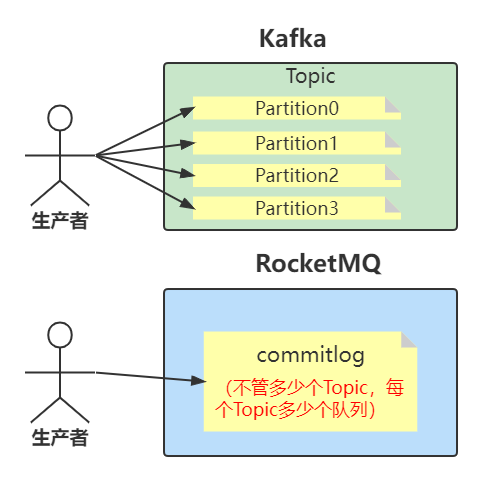
Kafka 中文件的布局是以 Topic/partition ,每一个分区一个物理文件夹,在分区文件级别实现文件顺序写,如果一个Kafka集群中拥有成百上千个主题,每一个主题拥有上百个分区,消息在高并发写入时,其IO操作就会显得零散(消息分散的落盘策略会导致磁盘IO竞争激烈成为瓶颈),其操作相当于随机IO,即 Kafka 在消息写入时的IO性能会随着 topic 、分区数量的增长,其写入性能会先上升,然后下降。而 RocketMQ在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入 commitlog 文件,并不会随着 topic 和 分区数量的增加而影响其顺序性。在消息发送端,消费端共存的场景下,随着Topic数的增加Kafka吞吐量会急剧下降,而RocketMQ则表现稳定。因此Kafka适合Topic和消费端都比较少的业务场景,而RocketMQ更适合多Topic,多消费端的业务场景。
6.3 存储文件设计
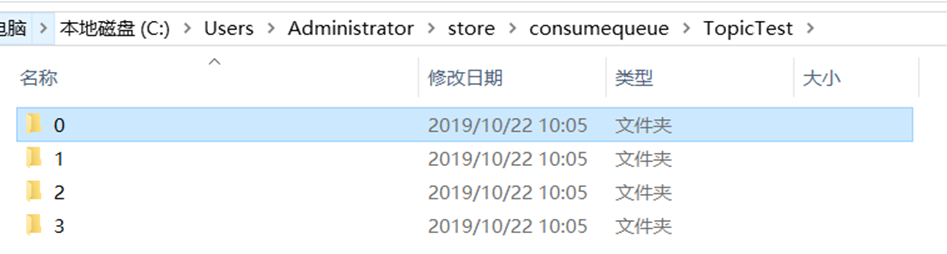
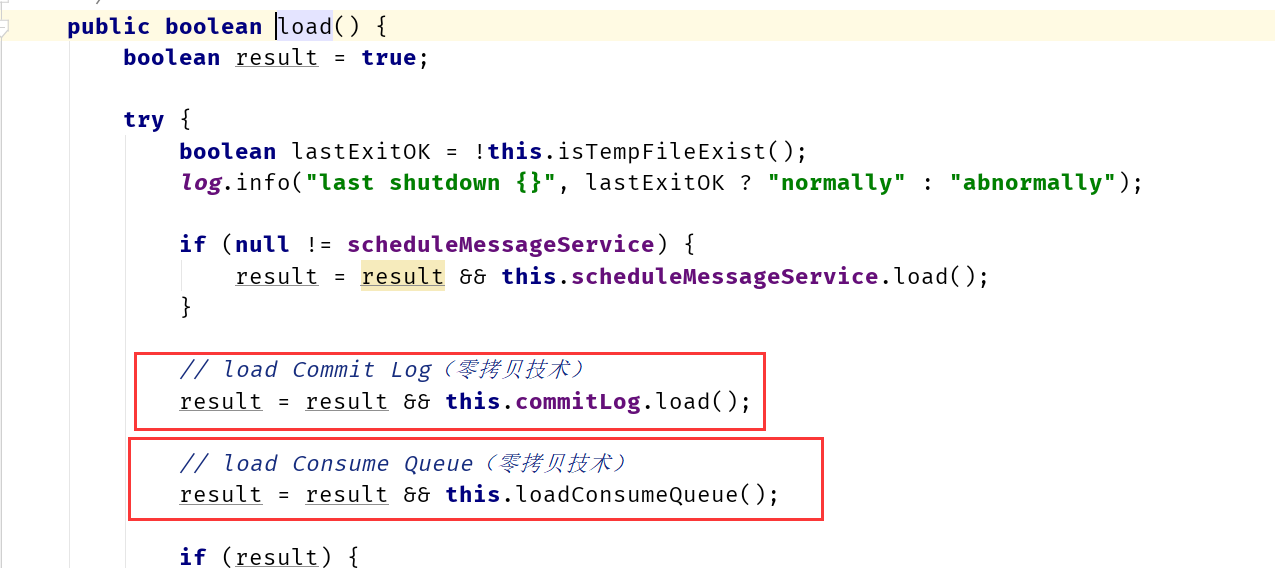
RocketMQ 主要存储的文件包括 Commitlog 文件、 ConsumeQueue 文件、 IndexFile。RocketMQ 将所有主题的消息存储在同一文件,确保消息发送时顺序写文件,尽最大的能力确保消息发送的高性能与高吞吐量。但由于一般的消息中间件是基于消息主题的订阅机制,这样便给按照消息主题检索消息带来了极大的不便。为了提高消息消费的效率, RocketMQ 引入了 ConsumeQueue 消息队列文件,每个消息主题包含多个消息消费队列,每个消息队列有一个消息文件。RocketMQ 还引入了IndexFile 索引文件,其主要设计理念就是为了加速消息的检索性能,可以根据消息的属性快速从 Commitlog 文件中检索消息。整体如下:

1 ) CommitLog :消息存储文件,所有消息主题的消息都存储在 CommitLog 文件中2 ) ConsumeQueue :消息消费队列,消息到达 CommitLog 文件后,将异步转发到消息消费队列,供消息消费者消费3 ) IndexFile :消息索引文件,主要存储消息 Key与Offset 的对应关系
6.3.1消息存储结构
CommitLog 以物理文件的方式存放,每台 Broker 上的 CommitLog 被本机器所有 ConsumeQueue 共享,在CommitLog 中,一个消息的存储长度是不固定的, RocketMQ采取一些机制,尽量向CommitLog 中顺序写 ,但是随机读。commitlog 文件默认大小为lG ,可通过在 broker 置文件中设置 mapedFileSizeCommitLog 属性来改变默认大小。

Commitlog文件存储的逻辑视图如下,每条消息的前面4个字节存储该条消息的总长度。但是一个消息的存储长度是不固定的。

ConsumeQueue
ConsumeQueue 是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个Topic下的每个 Message Queue 都有一个对应的 ConsumeQueue 文件。

ConsumeQueue中存储的是消息条目,为了加速 ConsumeQueue 消息条目的检索速度与节省磁盘空间,每一个 Consumequeue条目不会存储消息的全量信息,消息条目如下:

ConsumeQueue 即为Commitlog 文件的索引文件, 其构建机制是 当消息到达 Commitlog 文件后 由专门的线程产生消息转发任务,从而构建消息消费队列文件(ConsumeQueue )与下文提到的索引文件。存储机制这样设计有以下几个好处:1 ) CommitLog 顺序写 ,可以大大提高写入效率。(实际上,磁盘有时候会比你想象的快很多,有时候也比你想象的慢很多,关键在如何使用,使用得当,磁盘的速度完全可以匹配上网络的数据传输速度。目前的高性能磁盘,顺序写速度可以达到600MB/s ,超过了一般网卡的传输速度,这是磁盘比想象的快的地方 但是磁盘随机写的速度只有大概100KB/s,和顺序写的性能相差 6000 倍!)2 )虽然是随机读,但是利用操作系统的 pagecache 机制,可以批量地从磁盘读取,作为 cache 存到内存中,加速后续的读取速度。同时因为ConsumeQueue中每一条消息的索引是固定长度,所以也能够确保消息消费时的时间复杂度保持在O(1)。3 )为了保证完全的顺序写,需要 ConsumeQueue 这个中间结构 ,因为ConsumeQueue 里只存偏移量信息,所以尺寸是有限的,在实际情况中,大部分的 ConsumeQueue 能够被全部读入内存,所以这个中间结构的操作速度很快,可以认为是内存读取的速度。此外为了保证 CommitLog和ConsumeQueue 的一致性, CommitLog 里存储了 Consume Queues 、Message Key、 Tag 等所有信息,即使 ConsumeQueue 丢失,也可以通过 commitLog 完全恢复出来。
IndexFile
index 存的是索引文件,这个文件用来加快消息查询的速度。消息消费队列 RocketMQ 专门为消息订阅构建的索引文件 ,提高根据主题与消息检索消息的速度 ,使用Hash索引机制,具体是Hash槽与Hash冲突的链表结构

Config
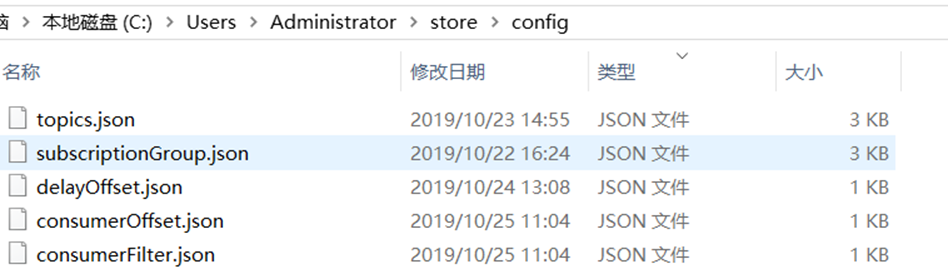
config 文件夹中 存储着Topic和Consumer等相关信息。主题和消费者群组相关的信息就存在在此。topics.json : topic 配置属性subscriptionGroup.json :消息消费组配置信息。delayOffset.json :延时消息队列拉取进度。consumerOffset.json :集群消费模式消息消进度。consumerFilter.json :主题消息过滤信息。
6.3.2 消息存储结构源码对应

6.4 消息写入流程
RocketMQ使用Netty处理网络,broker收到消息写入的请求就会进入SendMessageProcessor类中processRequest方法。
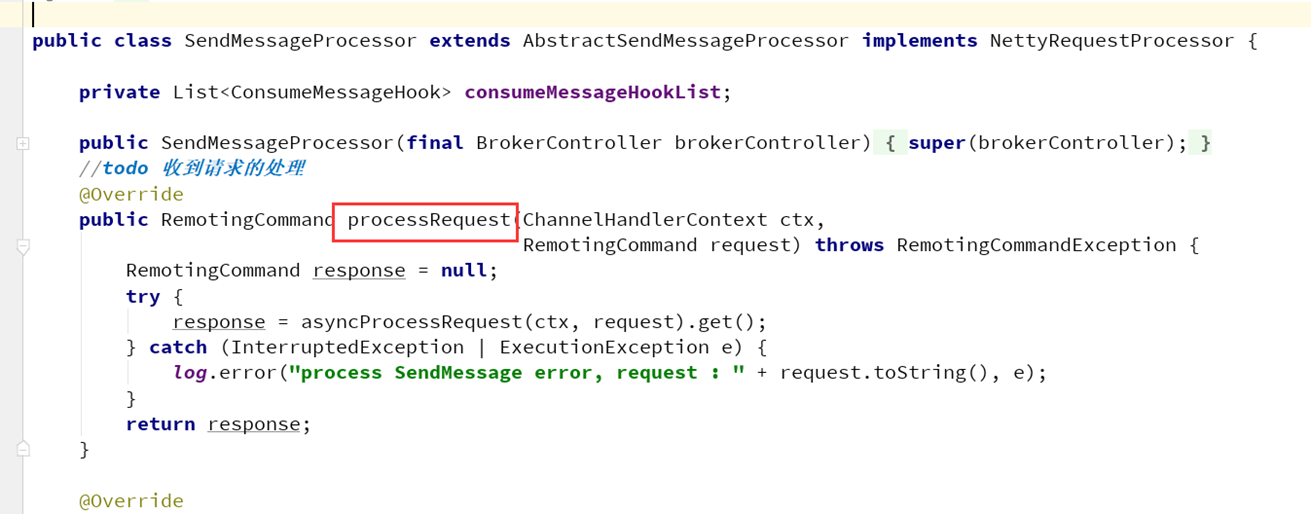
最终进入DefaultMessageStore类中asyncPutMessage方法进行消息的存储

然后消息进入commitlog类中的asyncPutMessage方法进行消息的存储
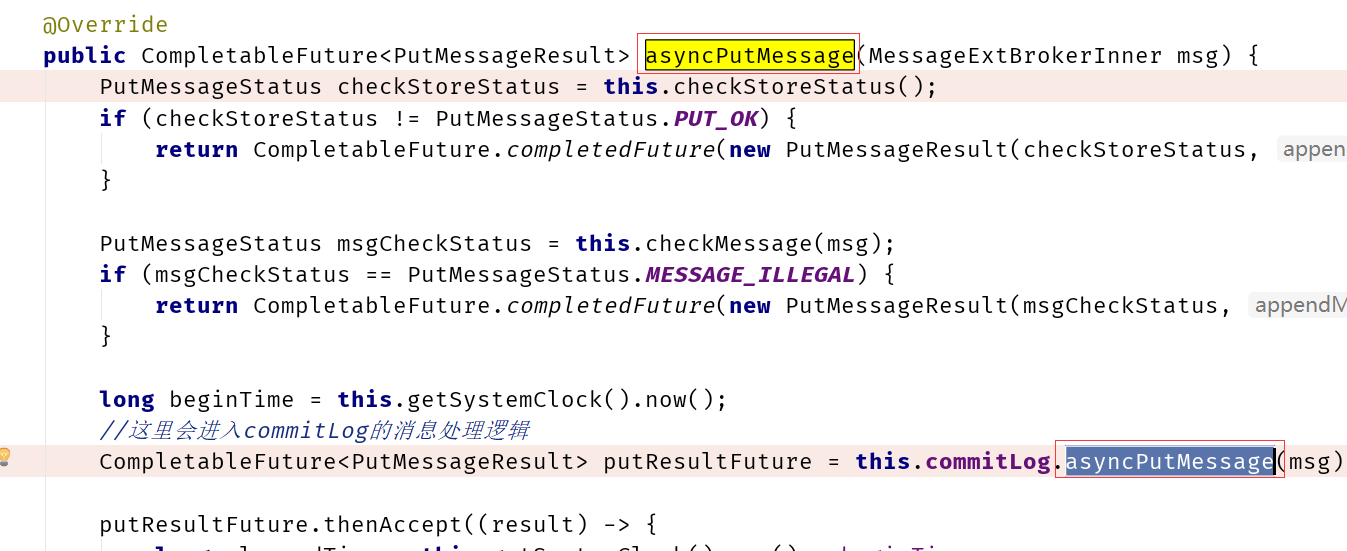
整个存储设计层次非常清晰,大致的层次如下图:
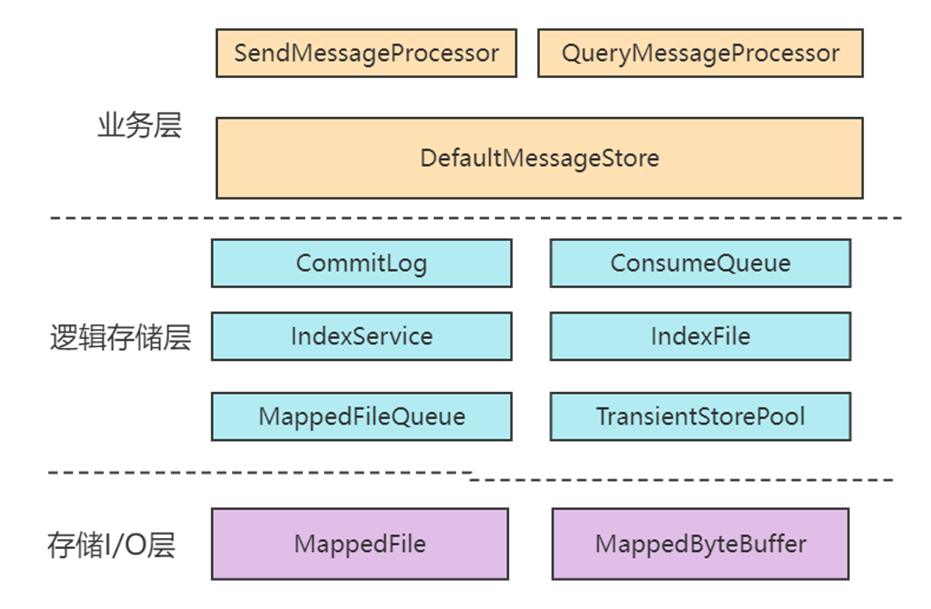
业务层:也可以称之为网络层,就是收到消息之后,一般交给SendMessageProcessor来分配(交给哪个业务来处理)。DefaultMessageStore,这个是存储层最核心的入口。
存储逻辑层:主要负责各种存储的逻辑,里面有很多跟存储同名的类。
存储I/O层:主要负责存储的具体的消息与I/O处理。
6.5 源码分析中亮点
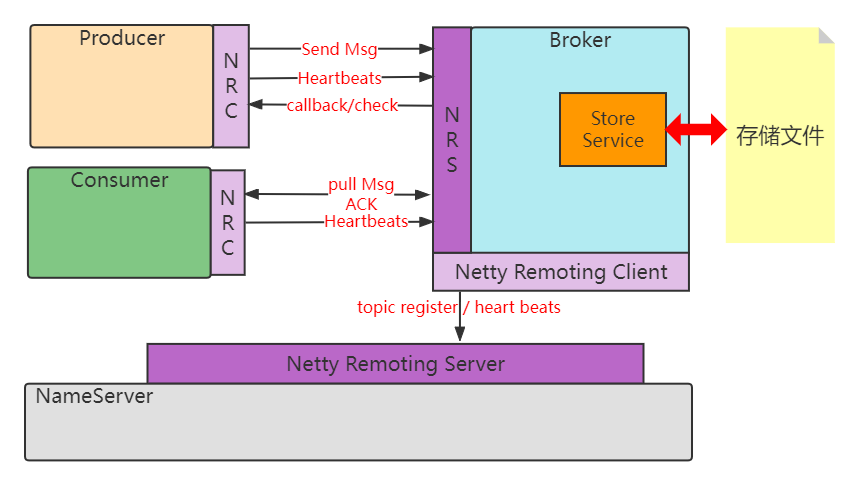
6.5.1 NRS与NRC的功能号设计
RocketMQ的通讯使用的是Netty,作为客户端核心类有两种:RemotingCommand与NettyRemotingClient。
RemotingCommand主要处理消息的组装:包括消息头、消息序列化与反序列化。
NettyRemotingClient主要处理消息的发送:包括同步、异步、单向、注册等操作。
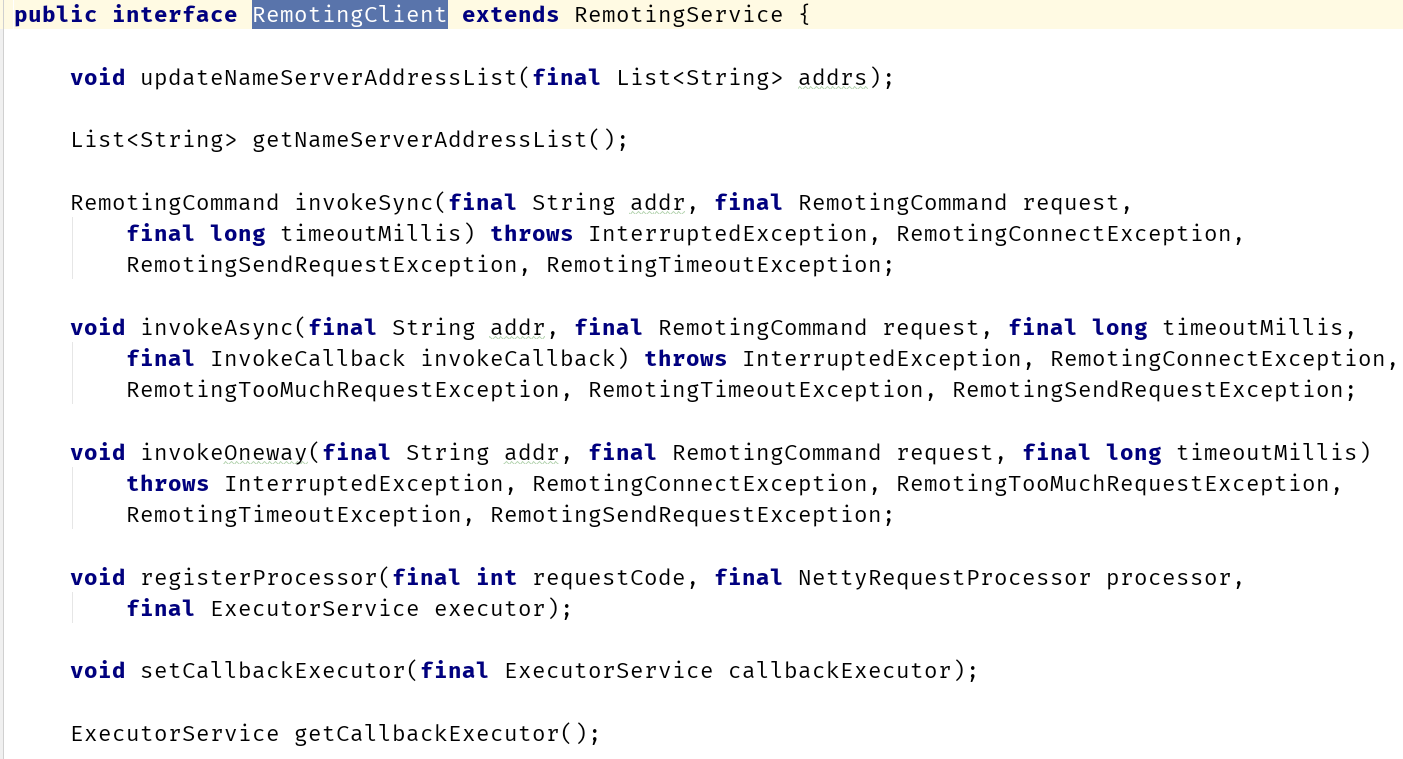
因为RocketMQ消息种类比较众多,所以对于消息的发送,使用了一个类似于功能号的设计。
客户端发送消息时定义一个code,对应一个功能,服务端注册一个业务处理,对应一个code的业务处理。
code对应码表RequestCode类。
例如:从生产者客户端代码,跳入到NRC的代码:NettyRemotingClient
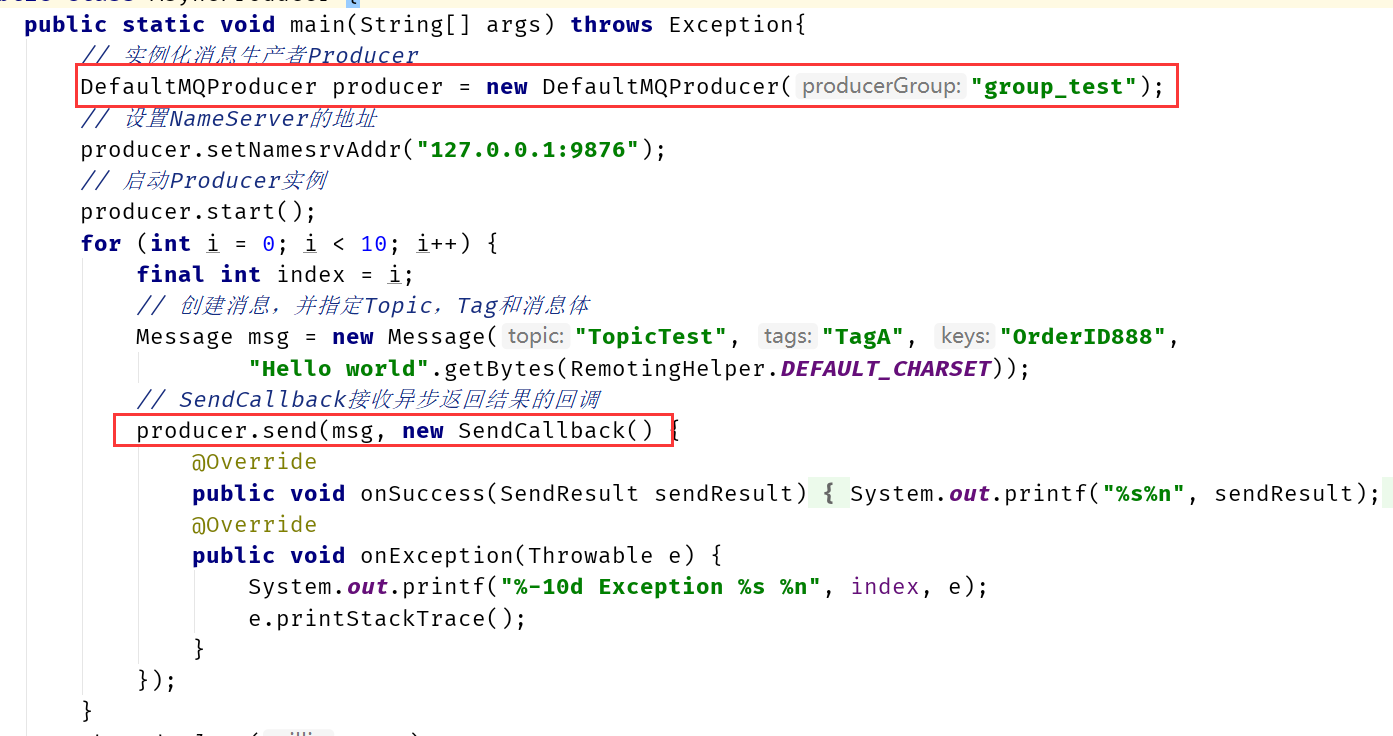
MQClientAPIImpl类中的sendMessage()中
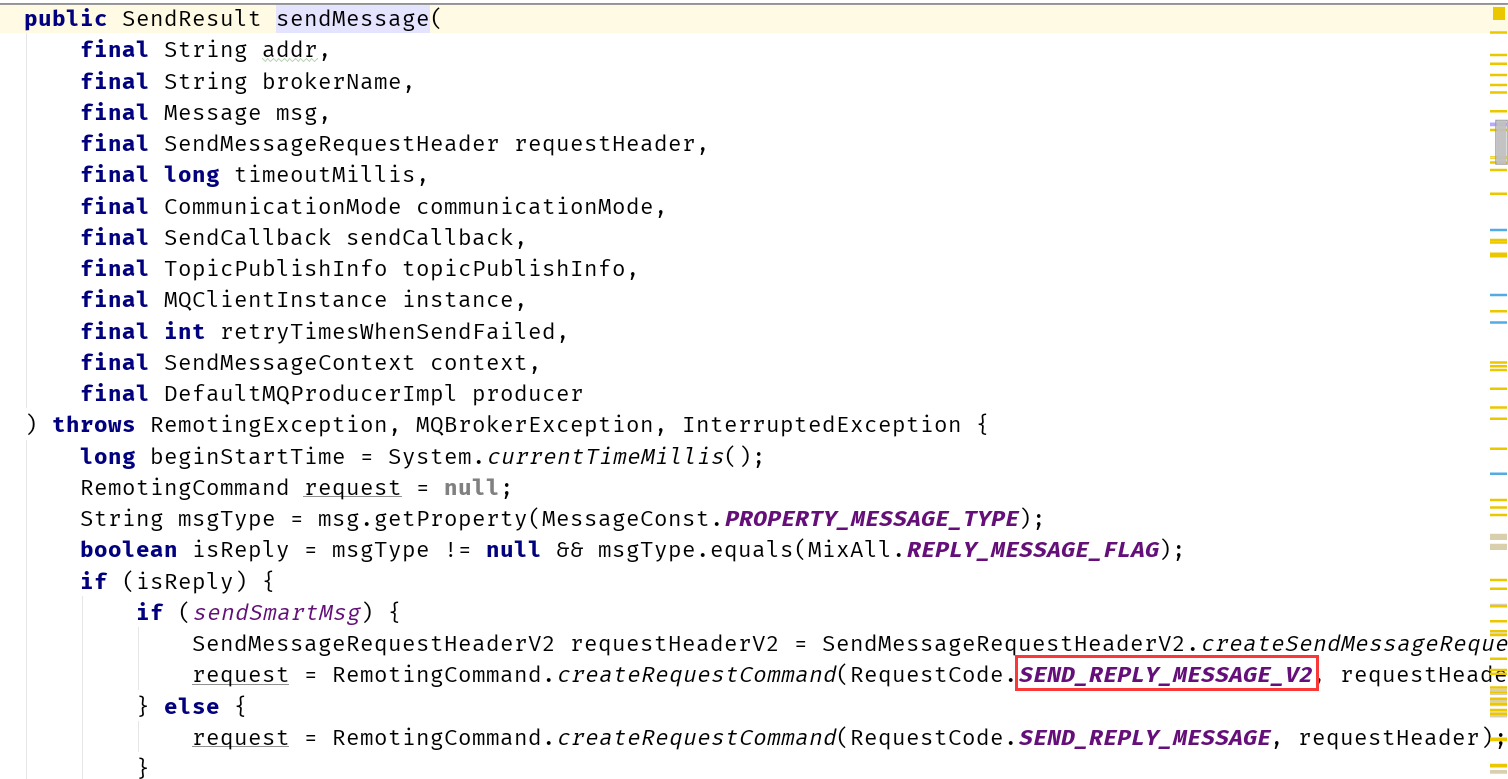
NettyRemotingClient类
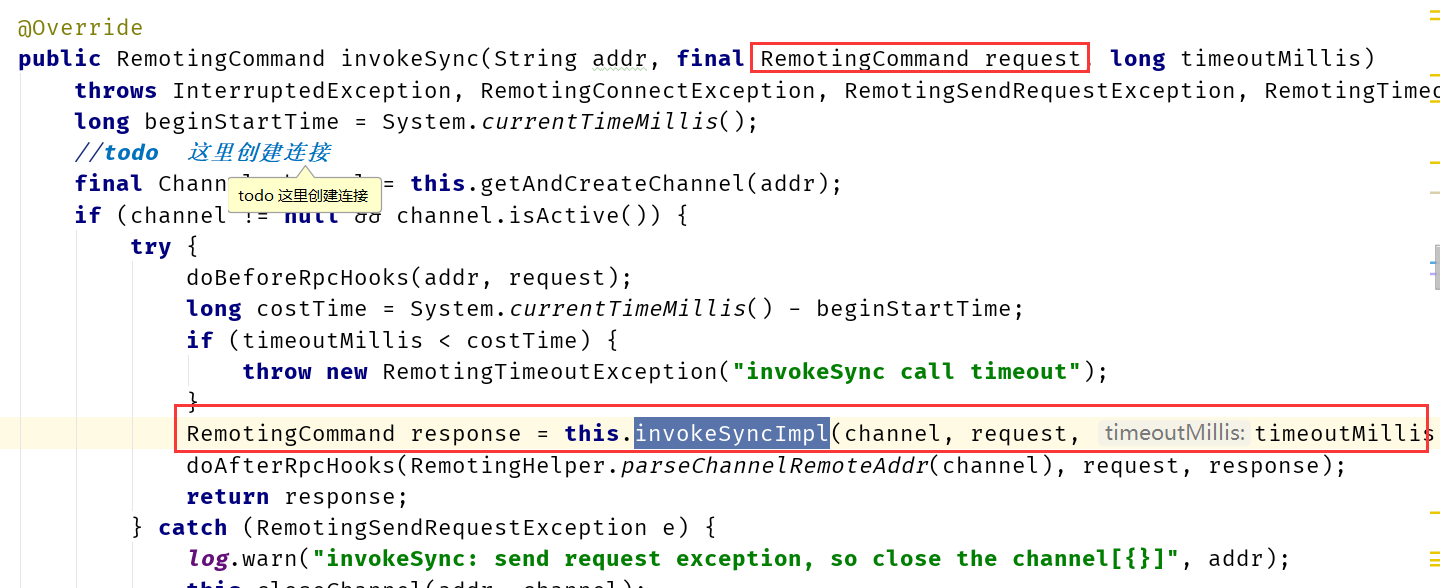
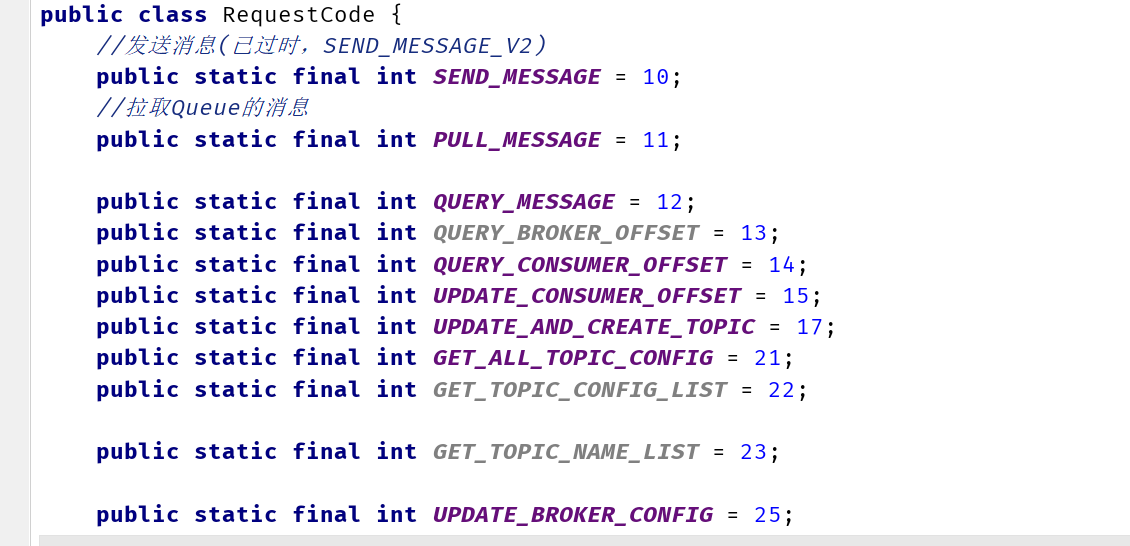 而在NRS中,只需要将服务端需要处理的ExecutorService注册到NRS组件中即可。
而在NRS中,只需要将服务端需要处理的ExecutorService注册到NRS组件中即可。
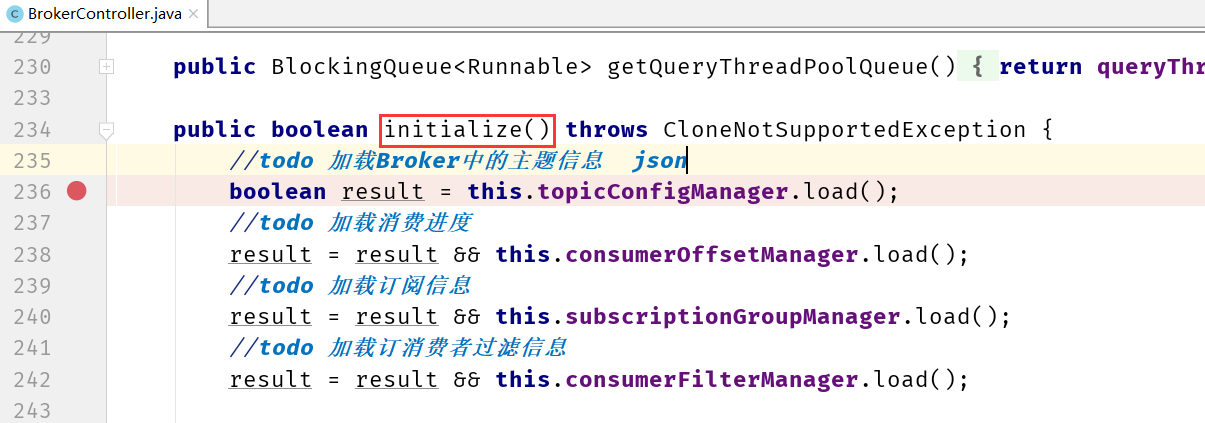
在启动流程中BrokerController类中的initialize()中
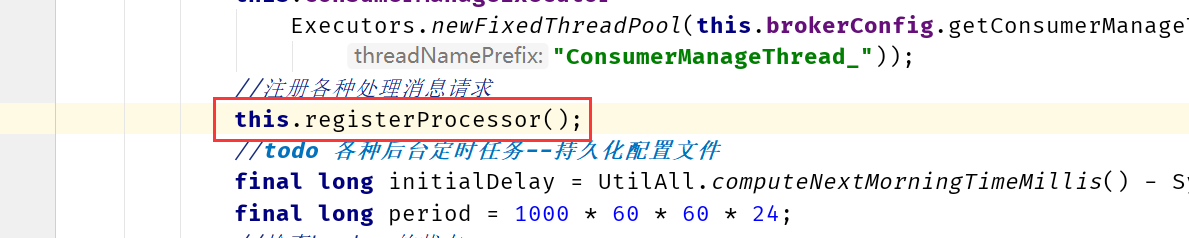
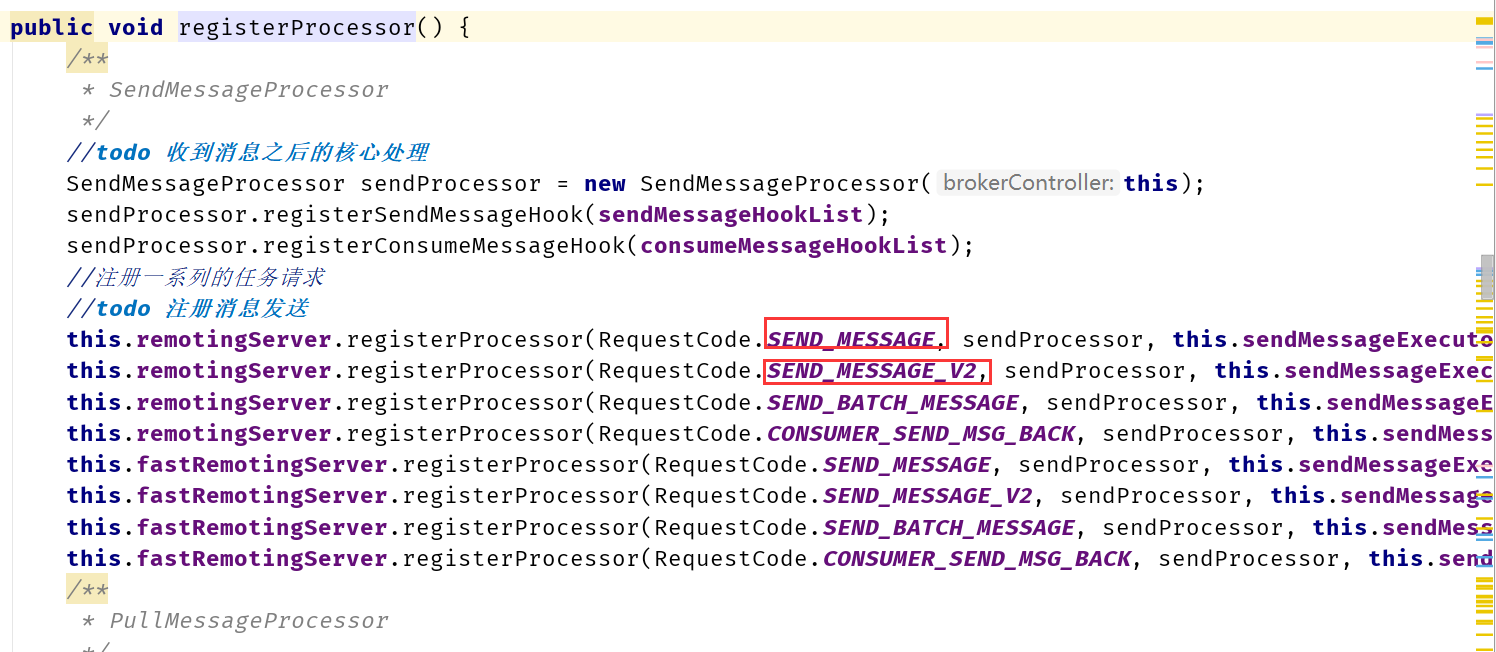
注意:功能号的设计并对客户端和服务端不是一对一的,在服务端往往处理是可以将不同的功能号对应到一个处理的任务中。
6.5.2 同步双写数倍性能提升的CompletableFuture
在RocketMQ4.7.0之后,RocketMQ大量使用Java中的异步编程接口CompletableFuture。尤其是在Broker端进行消息接收处理时。
具体使用及源码见 :马士兵教育官网 - IT职业领路人 (mashibing.com)
比如:DefaultMessageStore类中asyncPutMessage方法
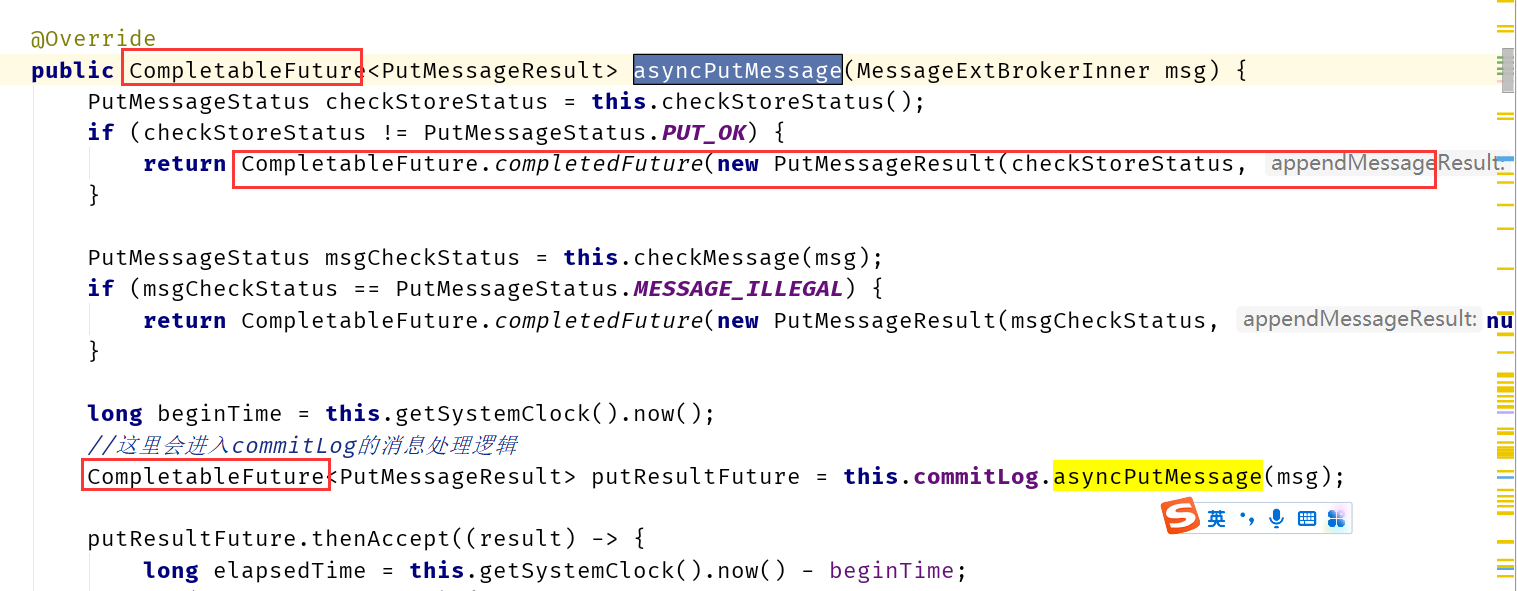

Future接口正是设计模式中Future模式的一种实现:如果一个请求或任务比较耗时,可以将方法调用改为异步,方法立即返回,任务则使用主线程外的其他线程异步执行,主线程继续执行。当需要获取计算结果时,再去获取数据。
在Master-Slave主从架构下,Master 节点与 Slave 节点之间数据同步/复制的方式有同步双写和异步复制两种模式。同步双写是指Master将消息成功落盘后,需要等待Slave节点复制成功(如果有多个Slave,成功复制一个就可以)后,再告诉客户端消息发送成功。
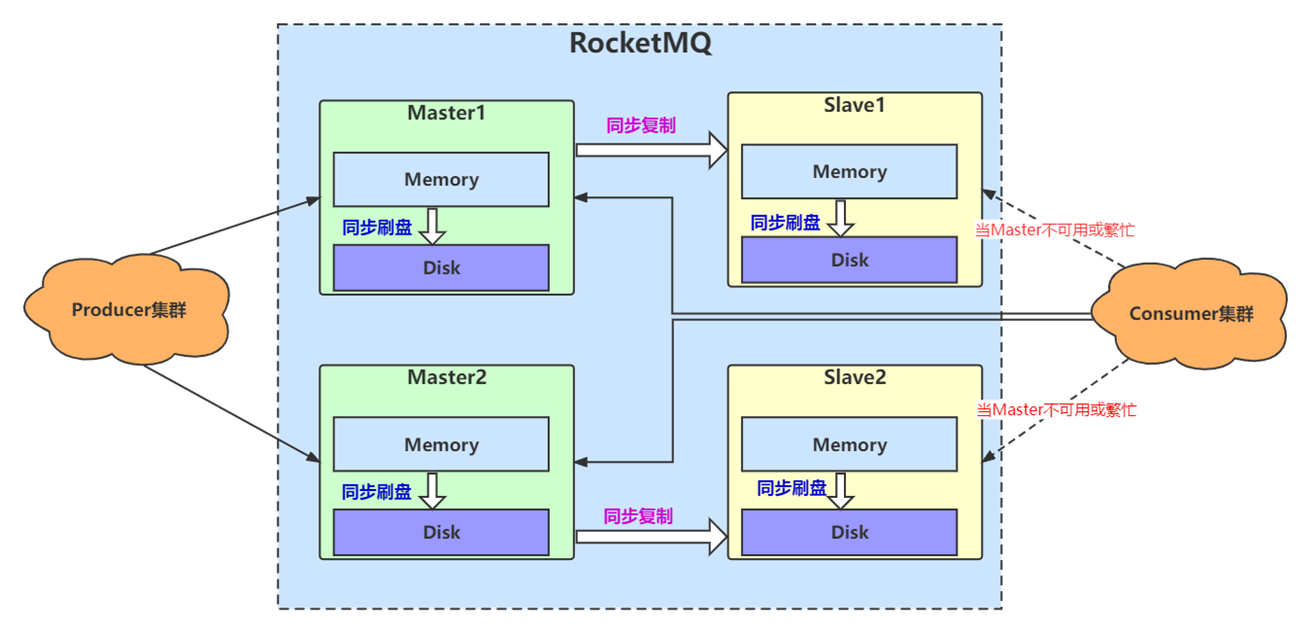
RocketMQ 4.7.0 以后合理使用CompletableFuture对同步双写进行性能优化,使得对消息的处理流式化,大大提高了Broker的接收消息的处理能力。
6.5.3 Commitlog写入时使用可重入锁还是自旋锁?
RocketMQ在写入消息到CommitLog中时,使用了锁机制,即同一时刻只有一个线程可以写CommitLog文件。CommitLog 中使用了两种锁,一个是自旋锁,另一个是重入锁。源码如下:


这里注意lock锁的标准用法是try-finally处理(防止死锁问题)
另外这里锁的类型可以自主配置。
RocketMQ 官方文档优化建议:异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁,调整Broker配置项useReentrantLockWhenPutMessage,默认为false;

同步刷盘时,锁竞争激烈,会有较多的线程处于等待阻塞等待锁的状态,如果采用自旋锁会浪费很多的CPU时间,所以“同步刷盘建议使用重入锁”。
异步刷盘是间隔一定的时间刷一次盘,锁竞争不激烈,不会存在大量阻塞等待锁的线程,偶尔锁等待就自旋等待一下很短的时间,不要进行上下文切换了,所以采用自旋锁更合适。
6.5.4 零拷贝技术之MMAP提升文件读写性能
RocketMQ底层对commitLog、consumeQueue之类的磁盘文件的读写操作都采用了mmap技术。具体到代码里面就是利用JDK里面NIO的MapperByteBuffer的map()函数,来先将磁盘文件(CommitLog文件、consumeQueue文件)映射到内存里来。
假如没有使用mmap技术的时候,使用最传统和基本普通文件进行io操作会产生数据多拷贝问题。比如从磁盘上把数据读取到内核IO缓冲区里面,然后再从内核IO缓冲区中读取到用户进程私有空间里去,然后我们才能拿到这个数据。
MMAP内存映射是在硬盘上文件的位置和应用程序缓冲区(application buffers)进行映射(建立一种一一对应关系),由于mmap()将文件直接映射到用户空间,所以实际文件读取时根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝,不再有文件内容从硬盘拷贝到内核空间的一个缓冲区。
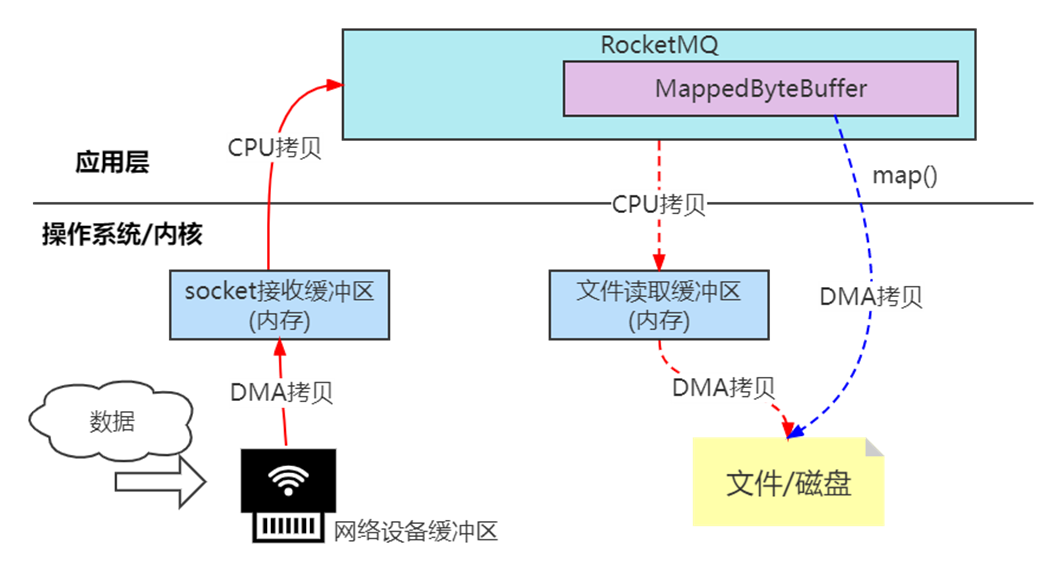
MMAP属于零拷贝技术的一种。
零拷贝(英语: Zero-copy) 技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
mmap技术在地址映射的过程中对文件的大小是有限制的,在1.5G~2G之间,所以,RocketMQ就会把单个的commitLog文件大小控制在1GB,consumeQueue文件大小控制在5.72MB,这样就在读写的时候,方便的进行内存映射了。
Broker启动时MMAP相关源码如下:
MappedFile类的init方法

生产者发送消息时MMAP相关消息写入源码如下:
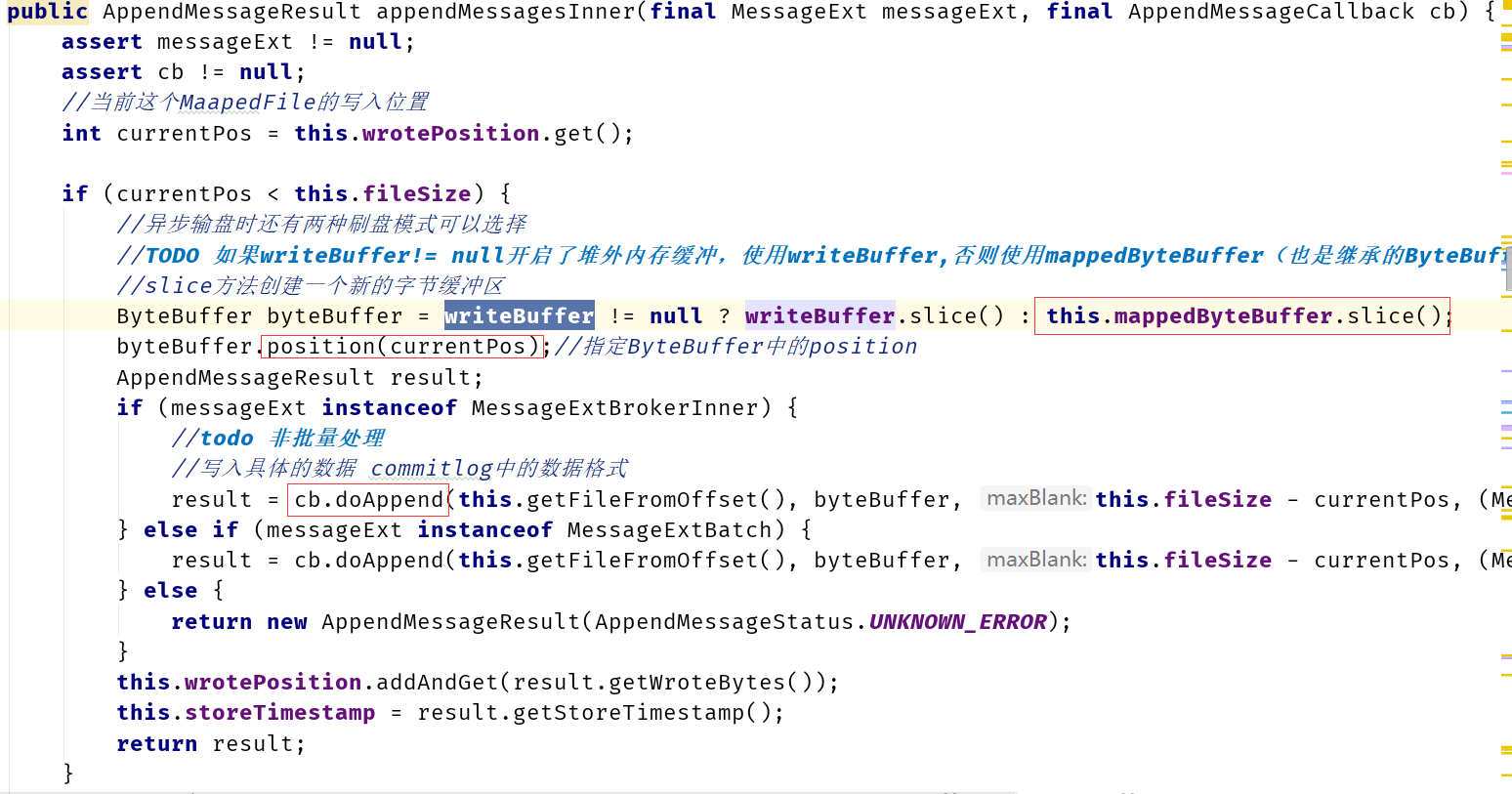
CommitLog类中的doAppend方法:具体进行消息格式的排列:

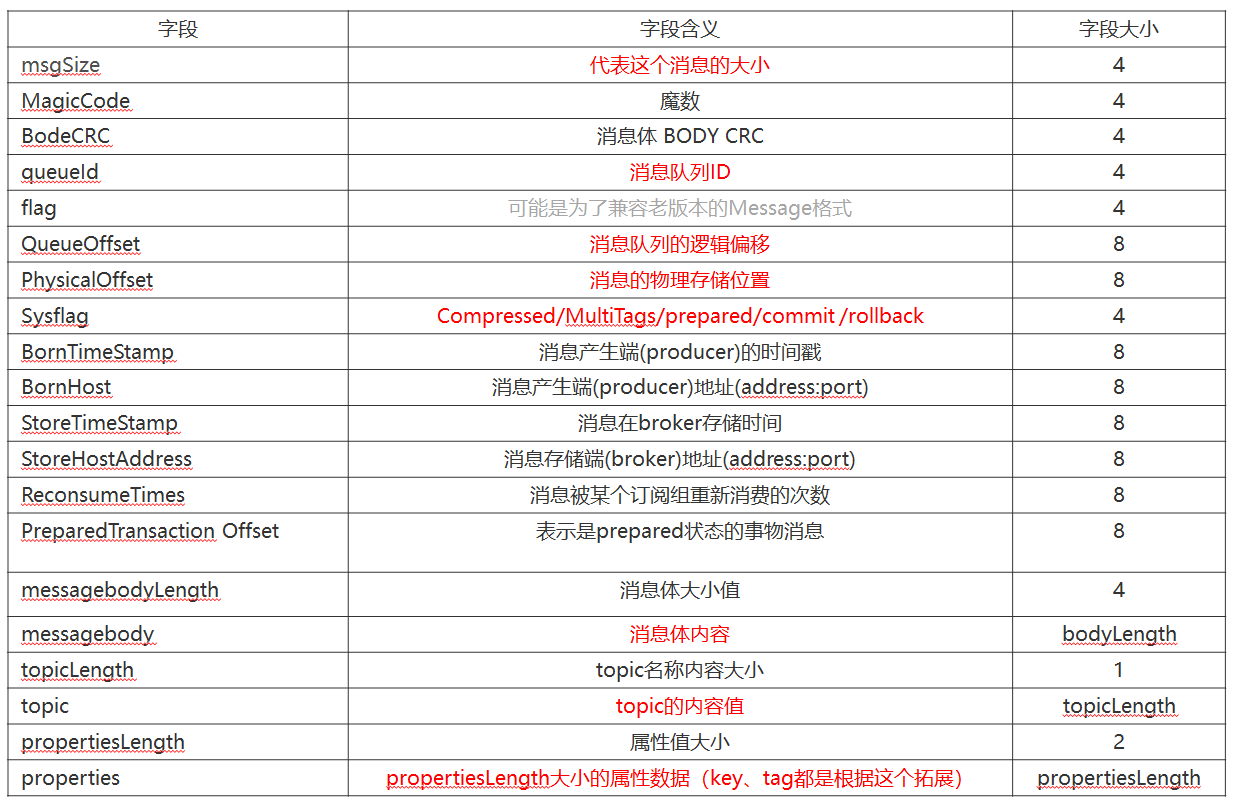
CommitLog之Message格式(可做参考)
6.5.5 堆外内存机制
一般情况下RocketMQ是通过MMAP内存映射,生产时消息写入内存映射文件,然后消费的时候再读。但是RocketMQ还提供了一种机制。堆外内存机制:TransientStorePool,短暂的存储池(堆外内存)。
6.5.5.1 开启条件及限制
开启堆外内存需要修改配置文件broker:transientStorePoolEnable=true
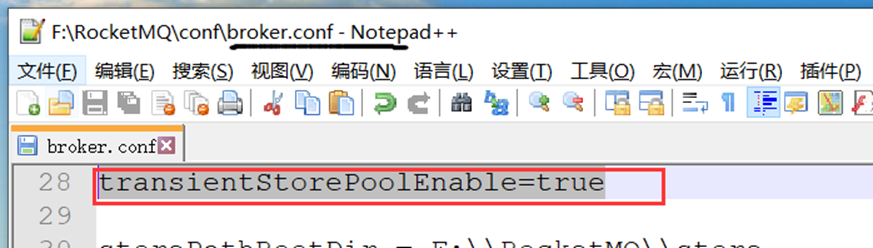
同时如果开启了堆外内存缓冲区的话,集群模式必须是异步刷盘的模式同时该Broker必须为主节点,通过查看源码我们可以可以看到这一限制:
DefaultMessageStore. DefaultMessageStore()


从堆外内存的流程图也可以看出,堆外内存的消息写入明显要多一个步骤,所以堆外内存缓冲区的设置一定要求是异步才行。
6.5.5.2 堆外缓冲区流程
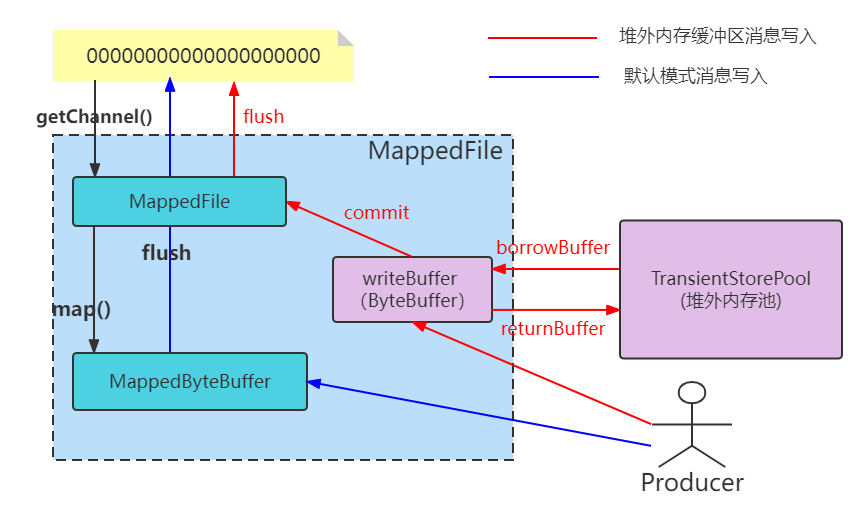
RocketMQ单独创建一个ByteBuffer内存缓存池,用来临时存储数据,数据先写入该内存映射中,然后由commit线程定时将数据从该内存复制到与目标物理文件对应的内存映射中。RocketMQ引入该机制主要的原因是提供一种内存锁定,将当前堆外内存一直锁定在内存中,避免被进程将内存交换到磁盘。同时因为是堆外内存,这么设计可以避免频繁的GC。
6.5.5.3 源码分析
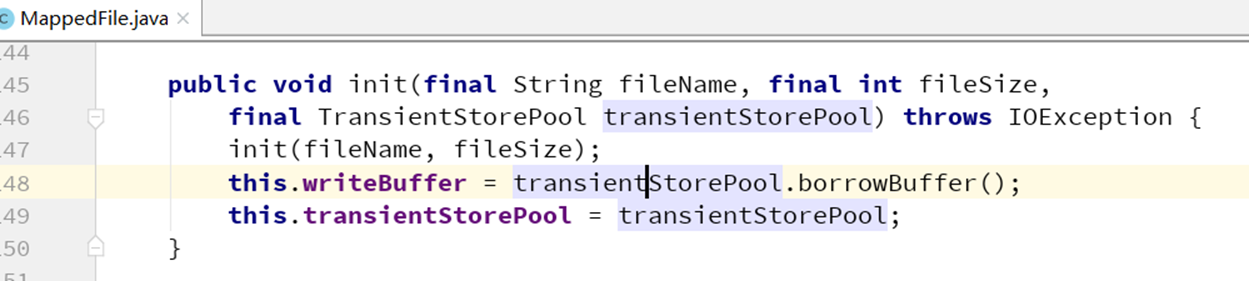
在DefaultMessageStore类中,开启堆外缓冲配置则进行堆外内存池初始化(TransientStorePool)

在创建MappedFile时如果检测到有堆外内存配置。这里就会把堆外内存通过borrowBuffer()赋给writeBuffer
从6.4章节中的消息写入流程继续,消息最终会进入mappedFile中处理。
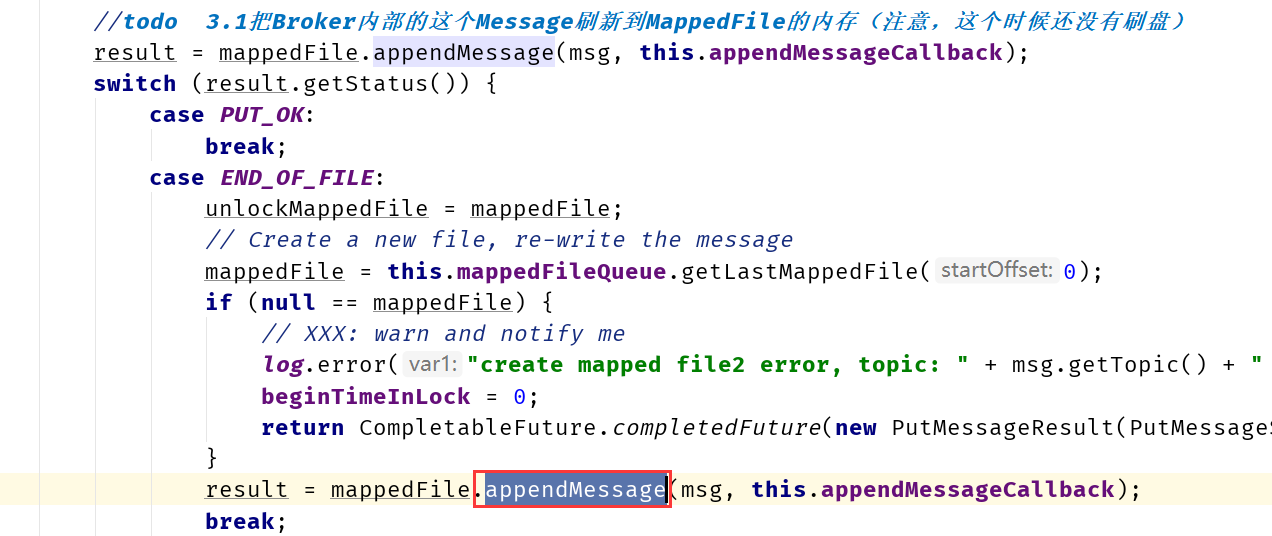
经过几个转跳后,进入appendMessagesInner方法中
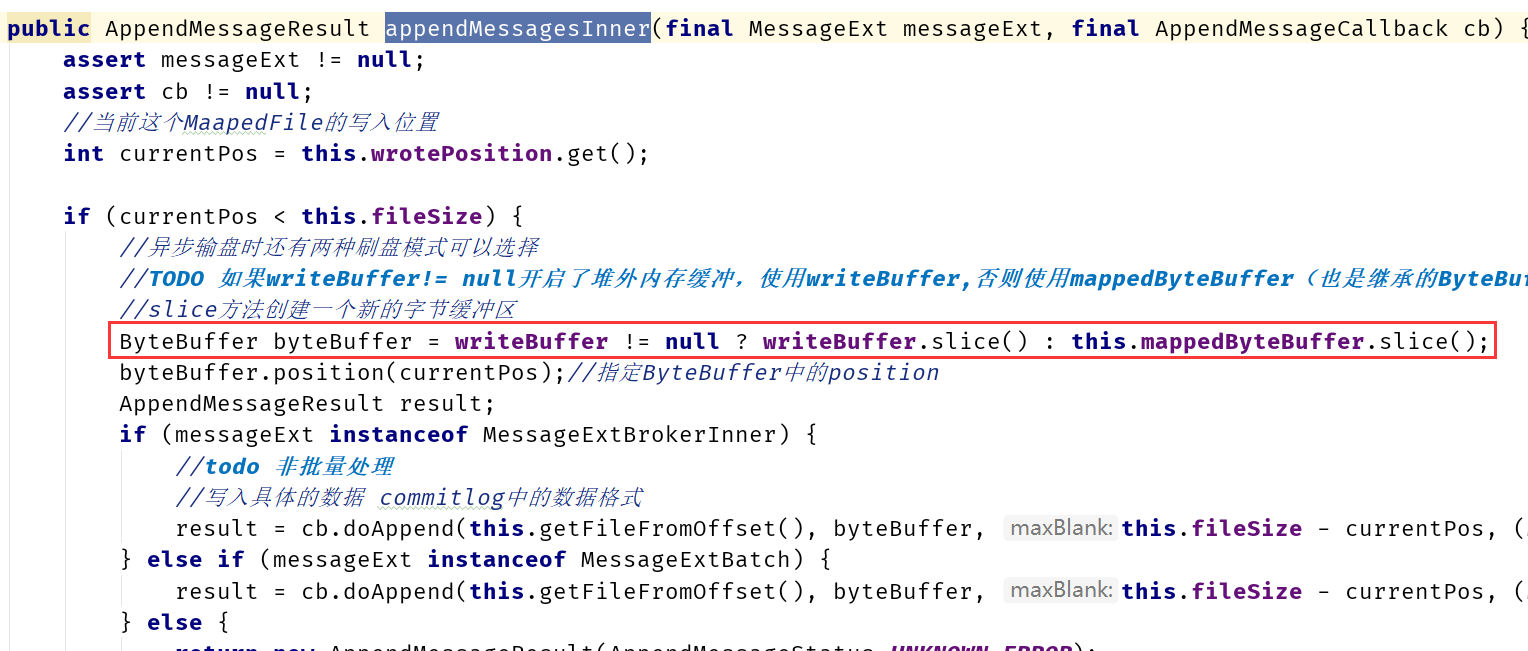
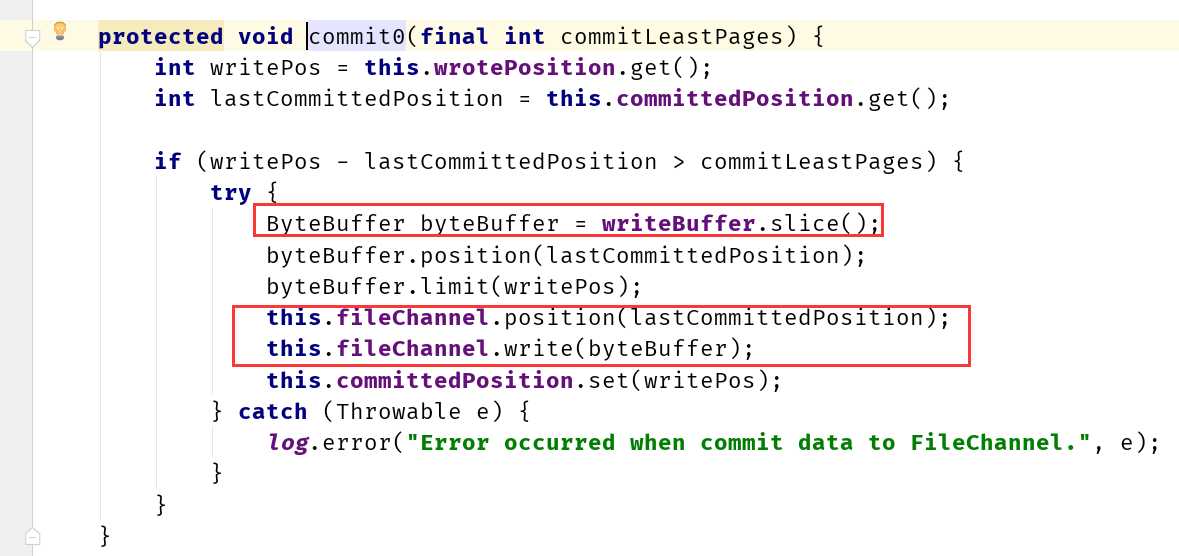
以上就可知如果有堆外内存缓冲区的话,ByteBuffer的来源是不同的。不过这里要注意,如果是堆外内存缓冲区,消息写入到ByteBuffer的话,还只是写入一个临时区域(不像默认模式本身就是mmap映射的内存,直接写入就进入了磁盘和内存的映射),所以,这里还需要一个步骤,就是从临时区域到正式区域。RocketMQ这里使用的是定时任务处理(并且是借用异步刷盘的定时任务来处理)。
这里需要回到CommitLog的构造方法,在CommitLog构造的时候,会选择启动一个定时任务来处理堆外内存
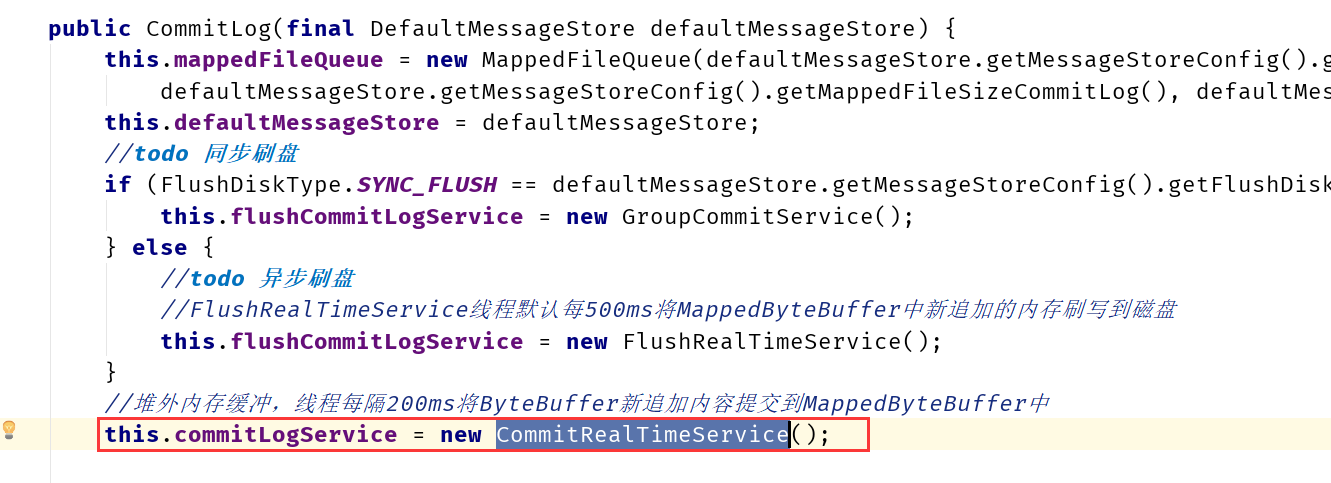

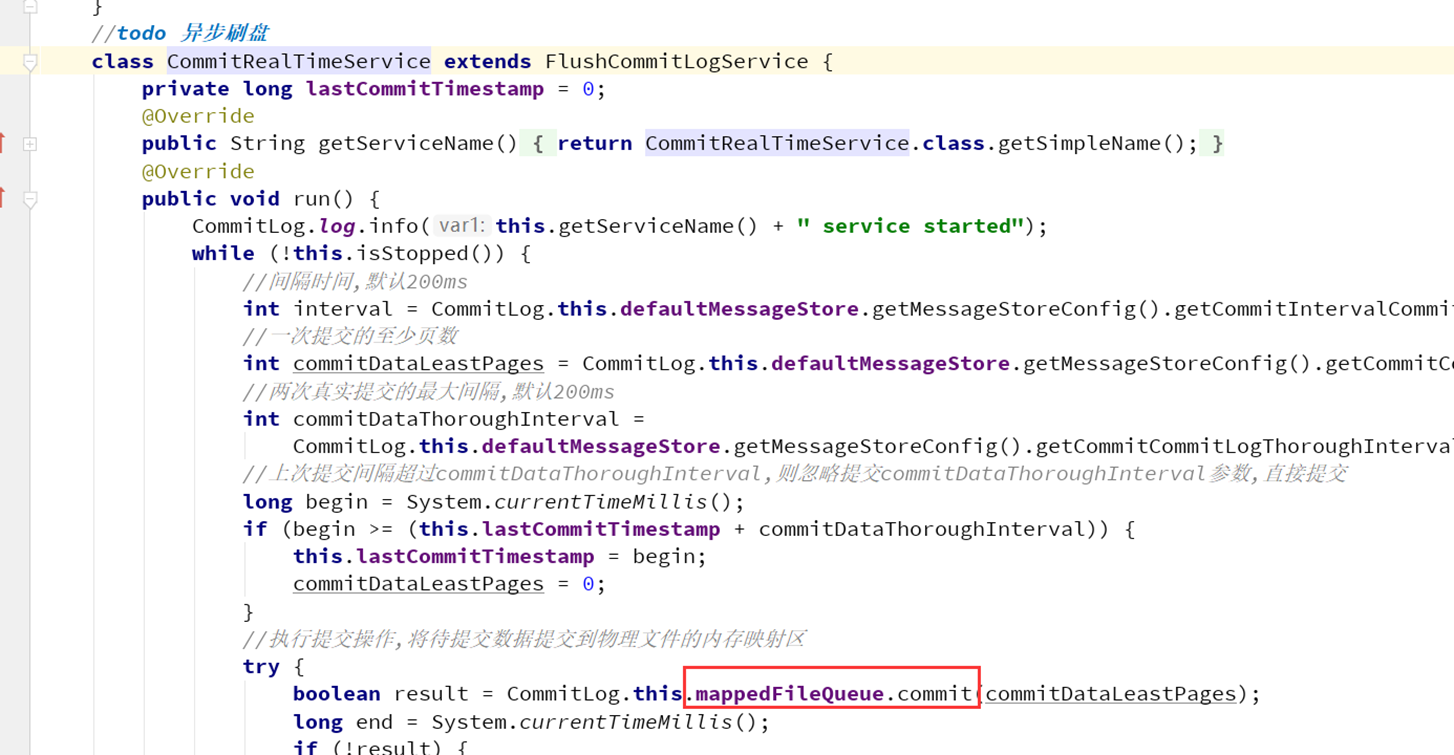
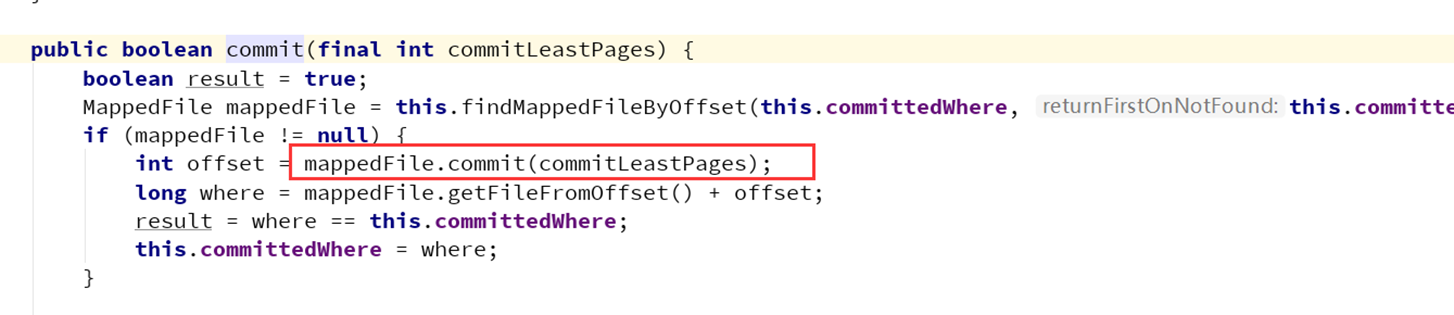
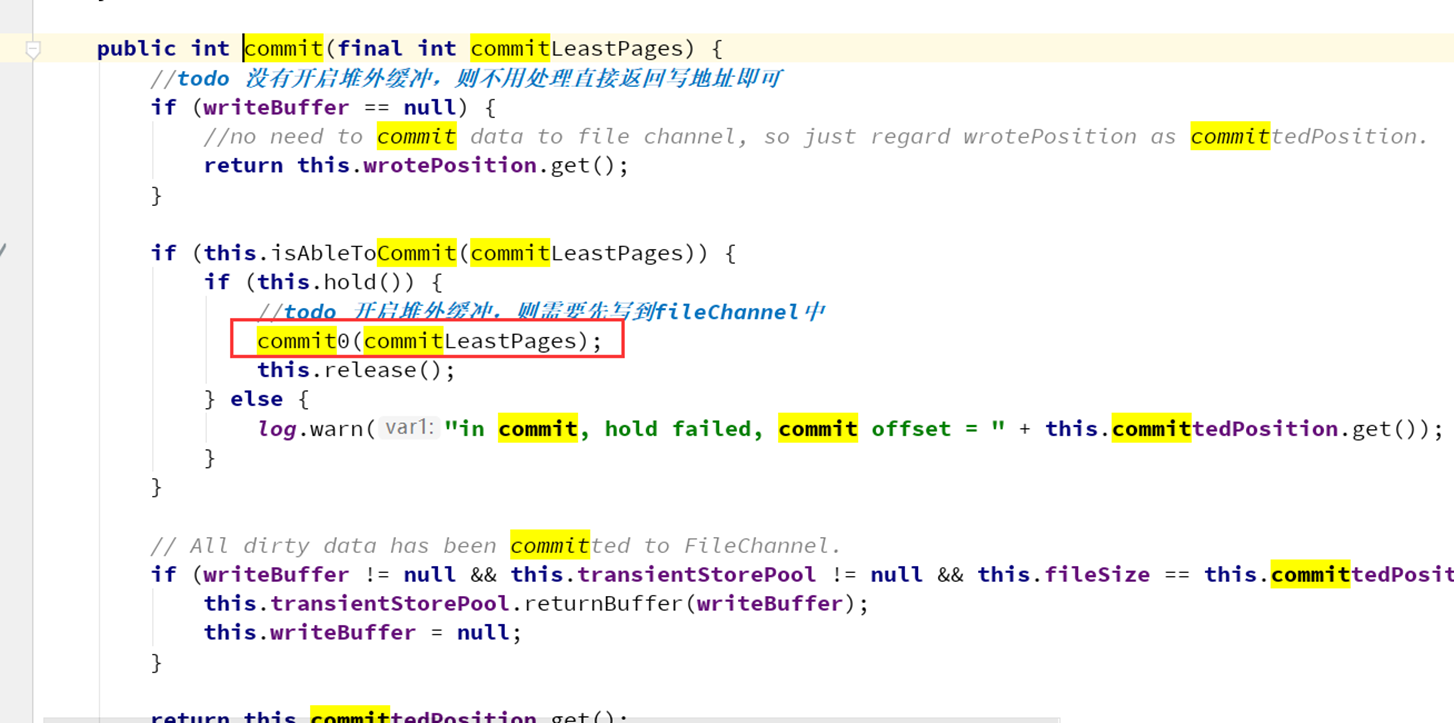
上述跳转比较麻烦,但是记住一个点就是堆外内存的数据写入本质上是分成两个阶段:
一个阶段先写入堆外内存,另外一个阶段通过定时任务再写入文件。
6.5.5.4 堆外内存缓冲的意义
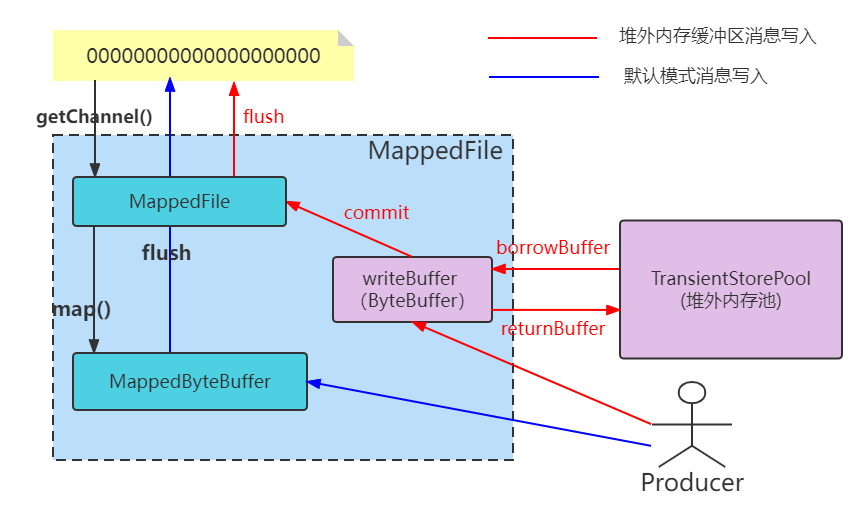
从图中可以发现,默认方式,Mmap+PageCache的方式,读写消息都走的是pageCache(MappedByteBuffer类),这样子读写都在pagecache里面不可避免会有锁的问题,在并发的读写操作情况下,会出现缺页中断降低,内存加锁,污染页的回写(脏页面)。
而如果采用堆外缓冲区,DirectByteBuffer(堆外内存)+PageCache的两层架构方式,这样子可以实现读写消息分离,写入消息时候写到的是DirectByteBuffer——堆外内存中,读消息走的是PageCache(MappedByteBuffer类),带来的好处就是,避免了内存操作的很多容易堵的地方,降低了时延,比如说缺页中断降低,内存加锁,污染页的回写。
所以使用堆外缓冲区的方式相对来说会比较好,但是肯定的是,需要消耗一定的内存,如果服务器内存吃紧就不推荐这种模式,同时的话,堆外缓冲区的话也需要配合异步刷盘才能使用(因为写数据分成了两步,同步刷盘延迟就会比较大)。
![洛谷P1059 [NOIP2006 普及组] 明明的随机数](https://img-blog.csdnimg.cn/c152e8478e4049c3995bbc5766d86843.png)