1 K8S 简介
K8S是Kubernetes的简称,是一个开源的容器编排平台,用于自动部署、扩展和管理“容器化(containerized)应用程序”的系统。它可以跨多个主机聚集在一起,控制和自动化应用的部署与更新。
K8S 架构
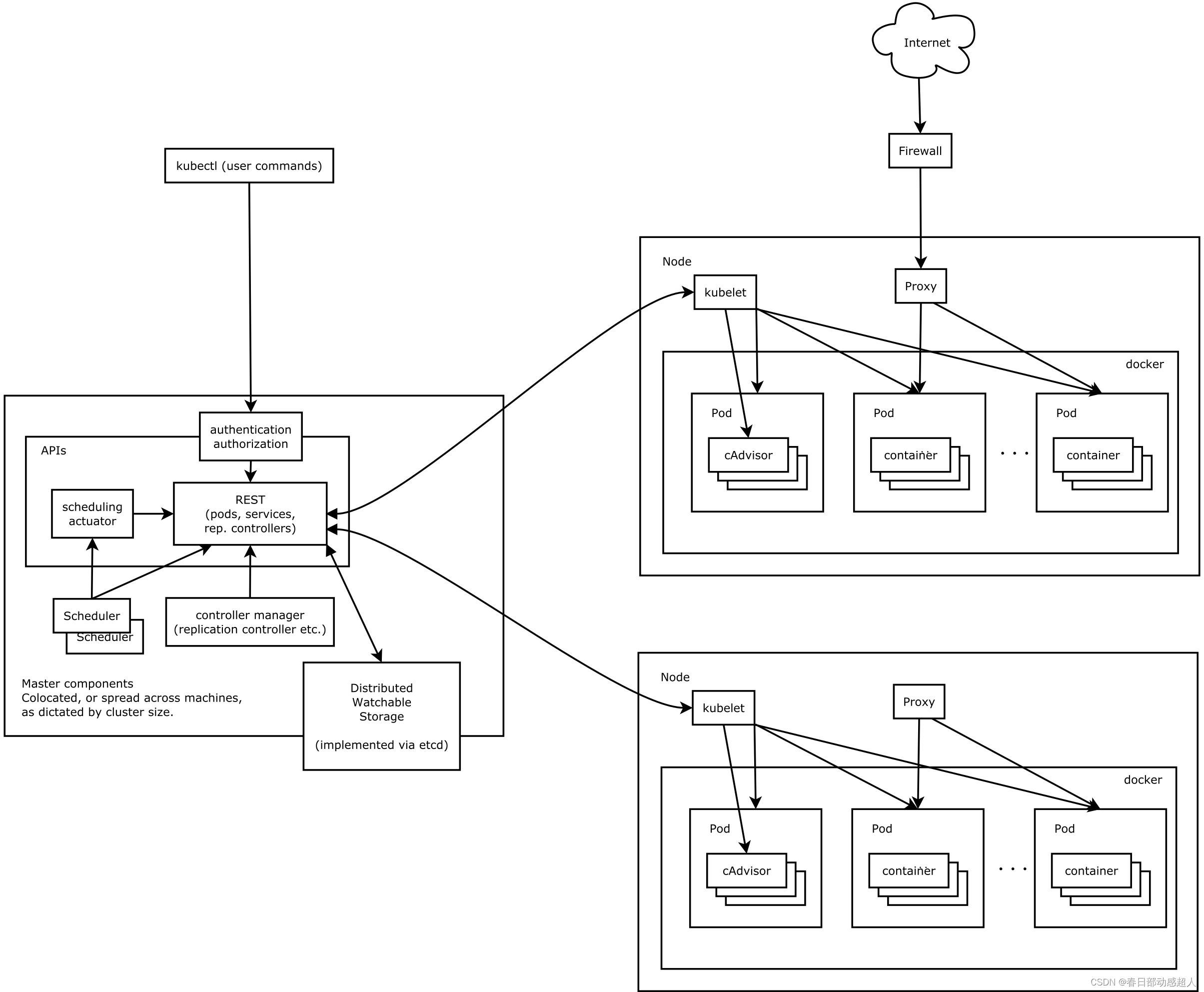
Kubernetes 主要由以下几个核心组件组成:
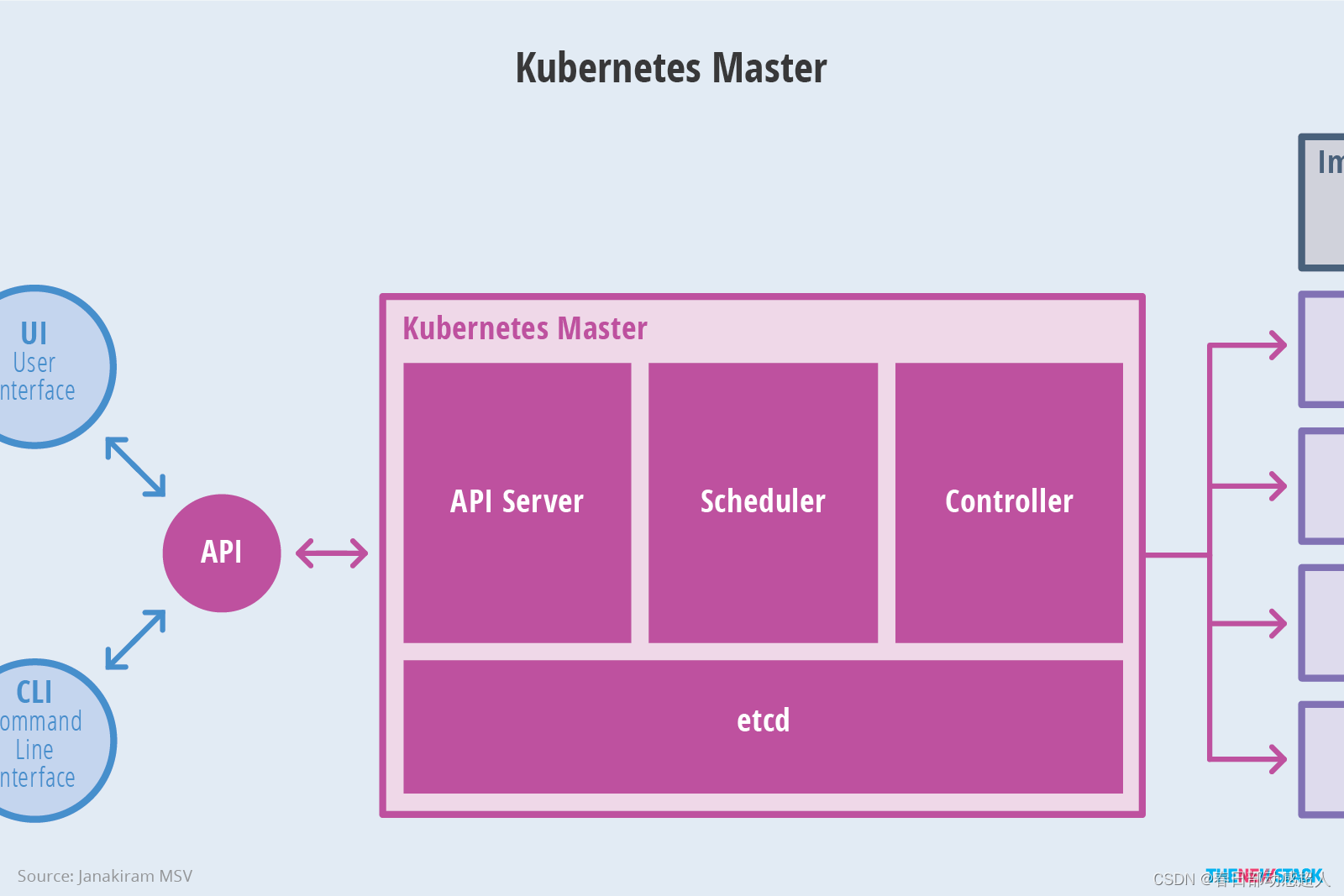
- etcd 保存了整个集群的状态;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
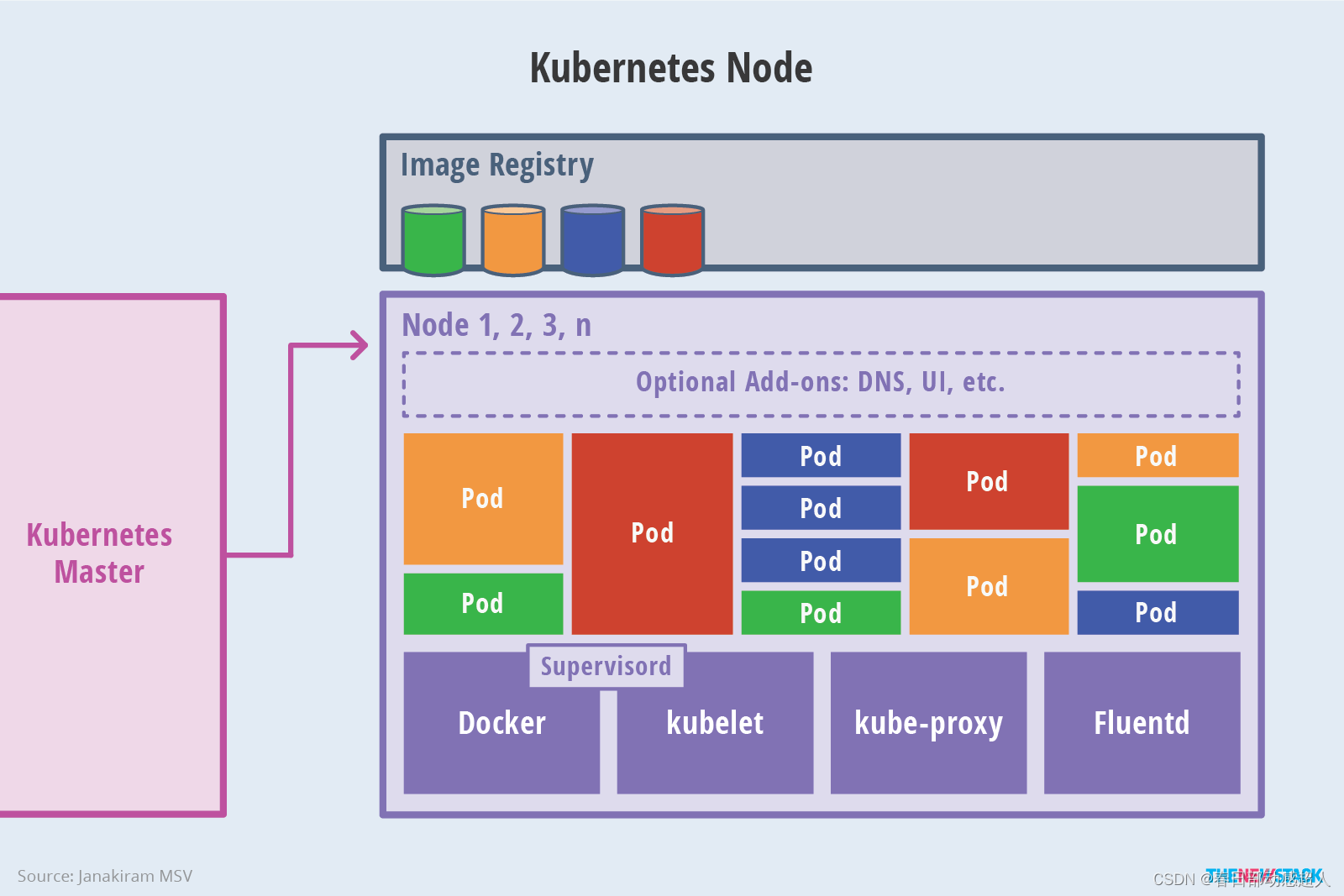
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的插件,其中有的已经成为 CNCF 中的托管项目:
-
CoreDNS 负责为整个集群提供 DNS 服务
-
Ingress Controller 为服务提供外网入口
-
Prometheus 提供资源监控
-
Dashboard 提供 GUI
-
Federation 提供跨可用区的集群
整体架构
下图清晰表明了 Kubernetes 的架构设计以及组件之间的通信协议。
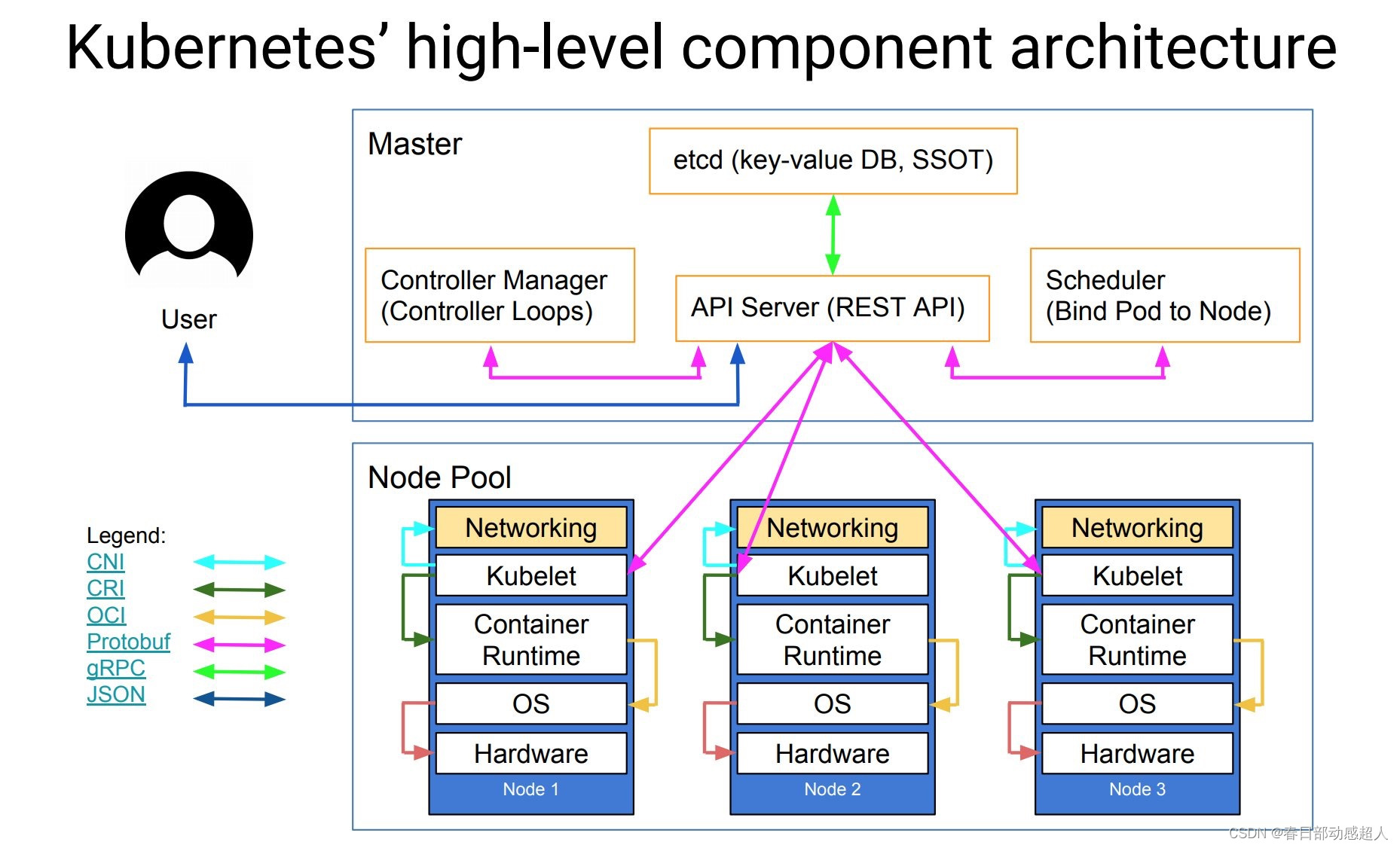
下面是更抽象的一个视图:
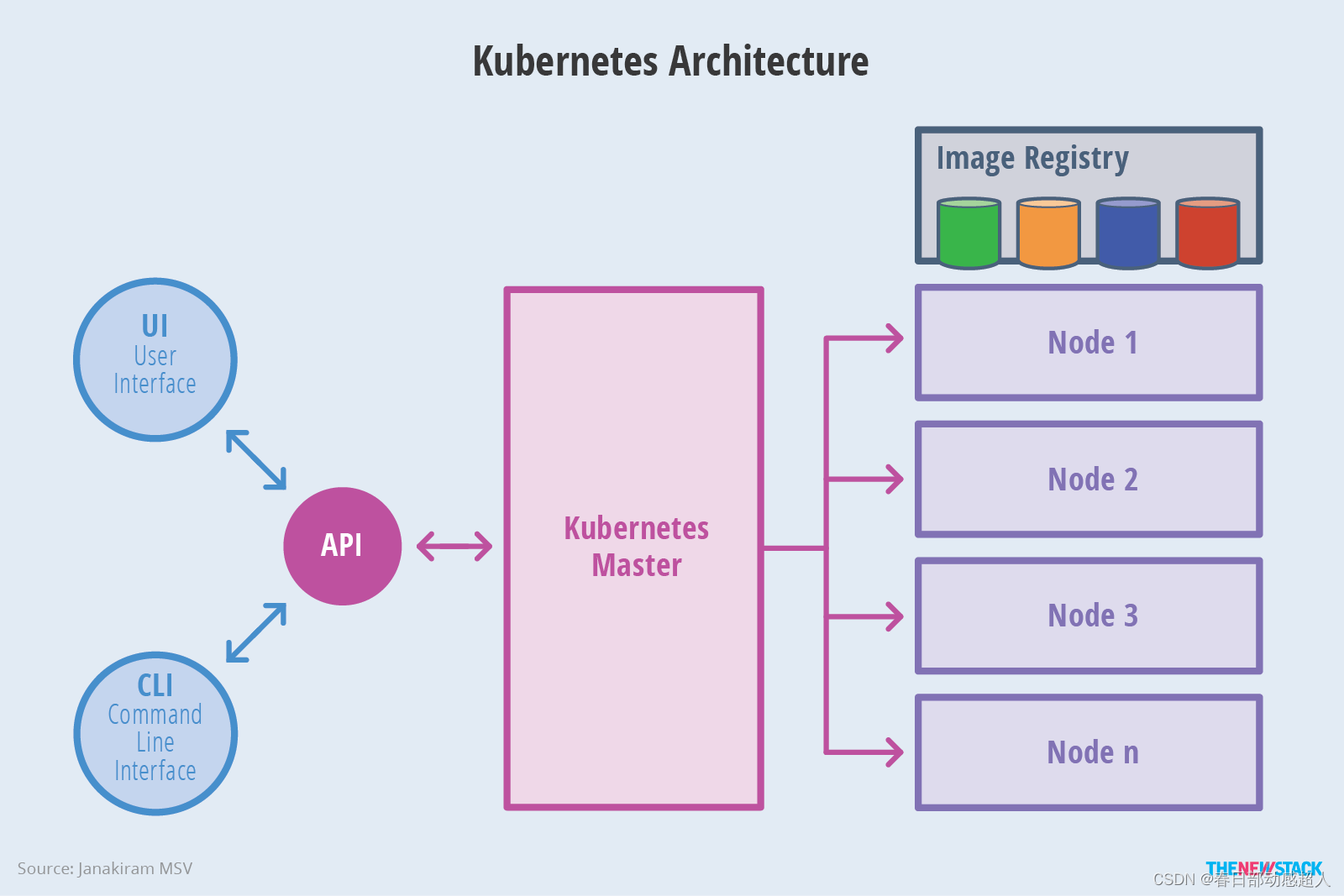
Master架构
Node架构
分层架构
Kubernetes 设计理念和功能其实就是一个类似 Linux 的分层架构,如下图所示。
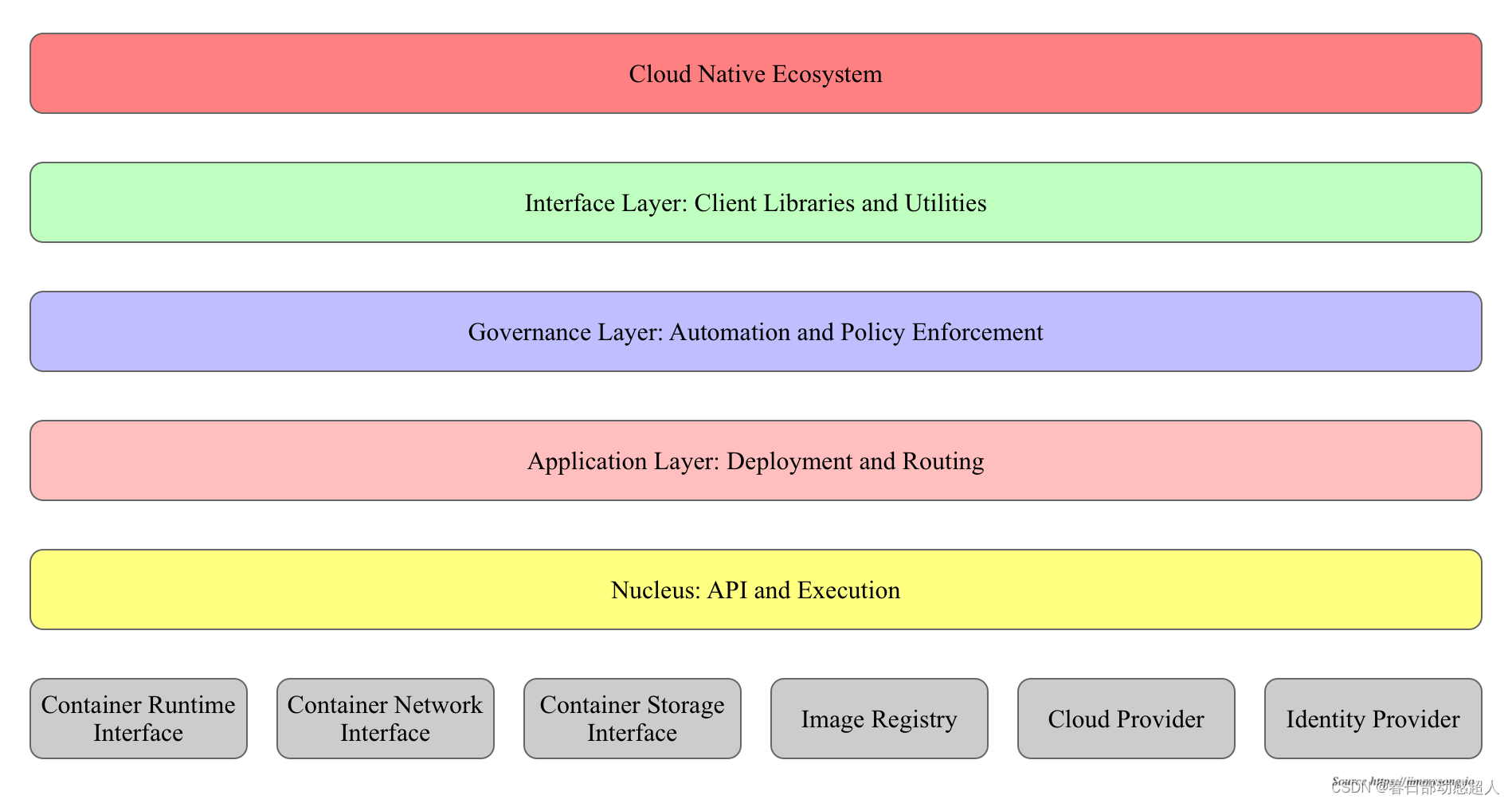
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)、Service Mesh(部分位于应用层)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)、Service Mesh(部分位于管理层)
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes 外部:日志、监控、配置管理、CI/CD、Workflow、FaaS、OTS 应用、ChatOps、GitOps、SecOps 等
- Kubernetes 内部:CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等
2 CPU架构
ARM64和x86是指基于不同架构的处理器。
ARM64是指基于ARM架构的64位处理器,而ARM是指基于ARM架构的32位处理器。ARM架构广泛应用于手机和移动设备领域,具有低成本、高性能、低电耗的特点。
x86则是指基于x86架构的处理器,它可以是32位或64位处理器架构,具体取决于处理器型号。x86架构广泛应用于传统的PC和服务器领域。
因为ARM64与x86是不同的CPU架构,两者的指令集不同,因此在部署时,需要考虑具体适配的软件安装包。
本文将基于arm64架构的国产操作系统统信UOS为例,说明K8S部署流程,仅供参考。
3 环境信息
| 环境 | 版本 | 说明 |
|---|---|---|
| 操作系统 | UnionTech OS Server 20 | |
| CPU架构 | aarch64 | |
| docker | 17.09.0-ce | OS/Arch: linux/arm64 |
| K8S | 1.20.11 | OS/Arch: linux/arm64 |
| rancher | v2.5.16-linux-arm64 | OS/Arch: linux/arm64 |
4 部署Docker
如果当前环境已经部署完arm64的docker,请忽略此章节。
下面的操作,需要在规划K8S的所有机器上执行。
4.1 环境准备
4.1.1 磁盘挂载
如果磁盘已经挂载,则省略该步骤。
docker推荐使用 xfs 磁盘格式。
磁盘挂载
$ mkfs.xfs -f /dev/vdb
$ mkdir /demo
$ mount /dev/vdb /demo
查看磁盘id
$ blkid
永久挂载
$ echo "UUID=94be2fa7-93aa-47a4-b661-45963b28fbb4 /demo xfs defaults 0 0" >> /etc/fstab
$ mount -a
备注:这里磁盘格式化仅做参考,具体的磁盘格式化以及挂载,请自行参考其他文档。目的就是:挂载xfs格式的磁盘到指定目录下(比如 /demo)
4.1.2 docker 根目录
磁盘挂载路径为/var/lib/docker时可忽略此步
磁盘挂载路径为其他路径时,通过mount --bind方式挂载目录
1 创建挂载目录
$ mkdir -p /demo/data/docker
2 将/demo/data/docker映射到/var/lib/docker
$ mount --bind /demo/data/docker /var/lib/docker
3 设置永久生效
$ echo "/demo/data/docker /var/lib/docker none bind 0 0" >> /etc/fstab
4 挂载
$ mount -a
4.2 下载Docker安装包并且解压
进入 /demo/data/ 目录下,下载 aarch64的docker安装包
执行如下命令:
# wget https://download.docker.com/linux/static/stable/aarch64/docker-17.09.0-ce.tgz

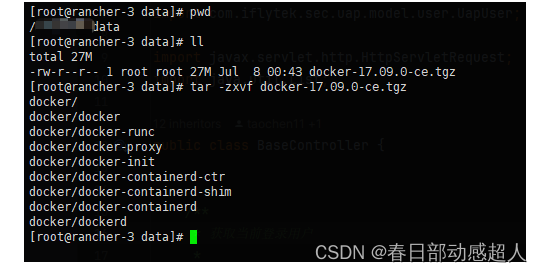
下载完成后,在当前目录进行解压操作:
$ tar -zxvf docker-17.09.0-ce.tgz
4.3 复制文件
在 /demo/data 目录下执行如下命令:
$ cp docker/* /usr/bin/
4.4 创建containerd的service文件
执行如下命令:
$ touch /etc/systemd/system/docker.service
# 给予可执行权限
$ chmod +x /etc/systemd/system/docker.service
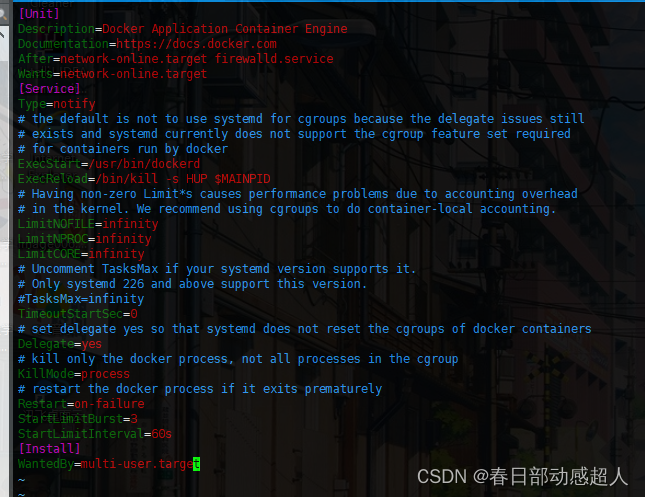
编辑docker.service文件,添加下面的内容:
$ vim /etc/systemd/system/docker.service
内容如下:
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
4.5 启动docker
重新加载配置文件
$ systemctl daemon-reload
启动docker
$ systemctl start docker
设置 docker 开机启动
$ systemctl enable docker.service
5 部署K8S
5.1 关闭selinux
selinux 是一个 Linux 内核模块,同时也是 Linux 的一个安全子系统。
SELinux 的主要作用是最大限度地减小系统中的安全风险,提高系统的安全性。
这个重要的安全工具由美国国家安全局开发,并且已经被集成到了主流的 Linux 2.6 及以上版本的内核中。
#临时关闭
$ setenforce 0
#永久关闭 SELINUX=disabled
$ vim /etc/sysconfig/selinux

5.2 关闭swap分区
Swap分区,也被称为交换分区或虚拟内存,是Linux系统中用于当物理内存不足时,将部分硬盘空间虚拟成内存使用的系统机制。它的作用在于释放物理内存中的一部分空间,以供当前运行的程序使用。当系统的物理内存不够用的时候,将其中一些暂时不需要的数据交换到交换空间。
but 有利有弊:
在安装Kubernetes(K8S)时,建议关闭swap分区。因为K8S的各个组件和容器都需要足够的内存来运行,而Swap的使用可能导致性能下降,甚至是应用程序的奔溃。如果系统内存不足,Kubernetes会将一部分数据交换到swap分区,而这可能会降低系统的性能,甚至导致Pod异常终止。
此外,对于一些集群,它们的swap位于机械硬盘阵列上,大量动用swap基本可以等同于死机,你甚至连root都登录不上,不用提杀掉问题进程了。往往结局就是硬重启。
然而,在关闭swap分区之前,需要确保系统的内存容量足够满足所有Pod的内存需求,以及不会因为关闭swap分区而导致系统崩溃或出现其他问题。因此,如果系统内存充足或者有额外的物理内存可供使用,建议保留swap分区。
#临时关闭
swapoff -a
#永久关闭 注释 swap 行
vim /etc/fstab
5.3 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
5.4 网络配置 iptables
Linux桥接功能是一种虚拟交换机,它是用纯软件实现的,具有和物理交换机相同的功能,例如二层交换,MAC地址学习等。它是一个软件层面的网络设备,用于在Linux系统中创建和管理网络桥接。
网桥的主要作用是将多个物理或虚拟网络接口连接在一起,以创建一个共享相同网络段的网络。而将网络接口连接起来的结果就是,一个网络接口接收到网络数据包后,会复制到其他网络接口中。
此外,如果你想把虚拟机当做一台完全独立的计算机看待,并且允许它和其他终端一样的进行网络通信,那么桥接模式通常是虚拟机访问网络的最简单途径。同时,bridge技术还可以把一个linux设备上的两块网卡桥接在一起,对外表现为一个大的网卡接口,比如你有两台设备,但是又没有路由器,那么把他们桥接在一起,可以共享其中一台的网络,这样两台都可以上网。
在Kubernetes(K8S)中,打开桥接功能的主要目的是为了解决网络通信问题。首先,每个Pod的网卡都是veth设备,veth pair的另一端连上宿主机上的网桥。由于网桥是虚拟的二层设备,同节点的Pod之间通信直接走二层转发,跨节点通信才会经过宿主机eth0。
其次,如果需要在K8S集群内部署一个VPN,需要采用桥接VPN+静态路由的双重策略,才能实现互相都可以直接使用IP进行访问。此外,开发人员在进行微服务开发的时候需要通过服务发现进行Pod级服务的直接访问,现在的K8S网络没办法做到直接访问pod或者service的ip。这时,可以通过Bridge to Kubernetes功能将应用程序的所有出站流量路由回Kubernetes群集。
总的来说,K8S打开桥接功能主要是为了优化网络通信,提高服务发现的效率和灵活性,以及实现不同网络间的无缝连接。
net.bridge.bridge-nf-call-iptables是一个 Linux 内核参数,用于控制桥接设备是否调用iptables进行网络过滤。当设置为 1 时,表示启用iptables;当设置为 0 时,表示禁用iptables。这个参数通常在/etc/sysctl.conf文件中进行配置。
net.bridge.bridge-nf-call-ip6tables=1是一个 Linux 内核参数,用于控制桥接设备是否调用ip6tables进行网络过滤。当设置为 1 时,表示启用ip6tables;当设置为 0 时,表示禁用ip6tables。这个参数通常在/etc/sysctl.conf文件中进行配置。
net.ipv4.ip_forward=1是一个 Linux 内核参数,用于控制 IPv4 数据包转发功能是否开启。当设置为 1 时,表示启用 IPv4 数据包转发;当设置为 0 时,表示禁用 IPv4 数据包转发。这个参数通常在/etc/sysctl.conf文件中进行配置。
m.swappiness=0是一个 Linux 内核参数,用于控制虚拟机(VM)的交换空间使用情况。当设置为 0 时,表示禁用交换空间;当设置为 100 时,表示启用交换空间并尽可能使用它。这个参数通常在/etc/sysctl.conf文件中进行配置。
对iptables内部的nf-call需要打开的内生的桥接功能
$ touch /etc/sysctl.d/k8s.conf
$ vim /etc/sysctl.d/k8s.conf
修改如下内容:
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
修改完成后执行:
$ modprobe br_netfilter
$ sysctl -p /etc/sysctl.d/k8s.conf
5.5 配置kubernetes源
yum源是一个在Linux下的软件包管理器,它能够从指定的服务器自动下载RPM包并完成安装,同时可以自动处理软件包之间的依赖关系。
根据存储位置的不同,yum源可以被分为本地yum源和网络yum源两种类型。本地yum源是指yum仓库在本地,通常是本地的镜像文件;而网络yum源则是指yum仓库在远程,也就是说我们需要联网才能使用。
yum.repos.d目录是Linux系统中存放yum源配置文件的默认位置。在该目录下,每个子目录都代表一个yum源,子目录的名称通常以.repo结尾。在
/etc/yum.repos.d/目录下,系统会默认存在一些yum源配置文件,例如 CentOS 官方源、epel源等。同时,用户也可以自己创建新的yum源配置文件并放置在该目录下,以便安装其他软件包或更新系统时使用。需要注意的是,当修改了
yum.repos.d目录下的任何一个配置文件后,都需要运行yum clean all命令清除缓存,否则新添加的软件包可能无法被正确识别和安装。
创建/etc/yum.repos.d/kubernetes.repo文件
$ touch /etc/yum.repos.d/kubernetes.repo
编辑:
$ vim /etc/yum.repos.d/kubernetes.repo
添加如下内容:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-aarch64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
#清除缓存
yum clean all
#把服务器的包信息下载到本地电脑缓存起来,makecache建立一个缓存
yum makecache
5.6 安装kubelet kubeadm kubectl
kubelet:运行在K8S cluster所有节点上,负责启动POD和容器
kubeadm:用于初始化K8S集群
kubectl:kubectl是kubenetes命令行工具,通过kubectl可以部署和管理应用,查看各种资源,创建,删除和更新组件
当不指定具体版本时,将下载当前yum源对应的最新版本
$ yum install -y kubelet kubeadm kubectl
也可以指定版本,建议指定如下版本
#安装指定版本的kubelet,kubeadm,kubectl
$ yum install -y kubelet-1.20.11 kubeadm-1.20.11 kubectl-1.20.11
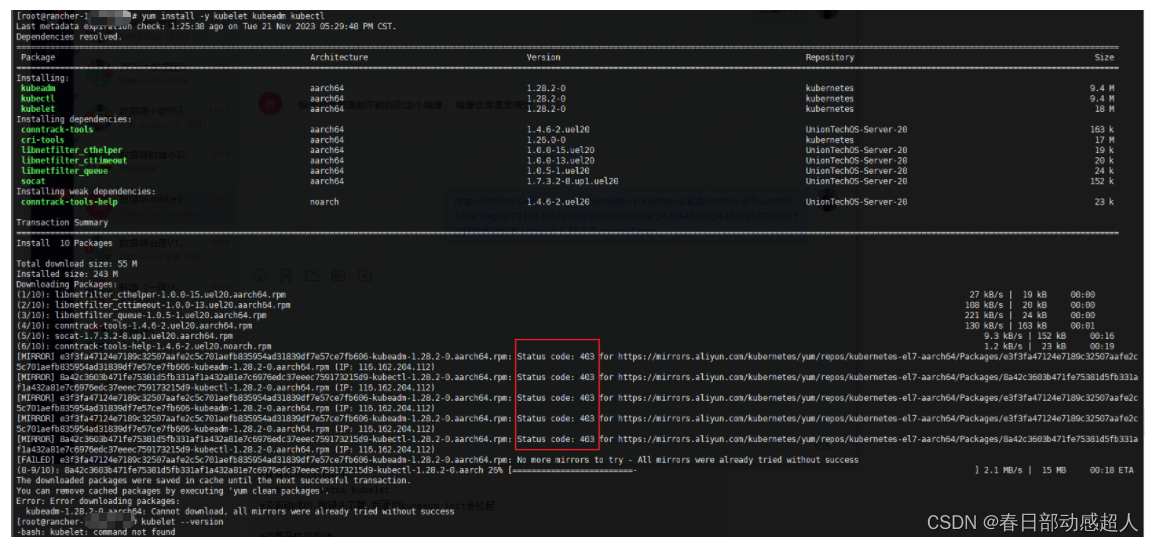
安装时如果出现 403,解决方案是多尝试几次。
安装完成后,查看K8S版本
#查看kubelet版本
$ kubelet --version
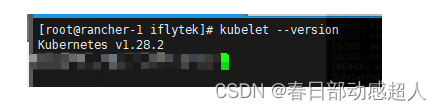
查看kubeadm版本
$ kubeadm version

5.7 启动kubelet并设置开机启动服务
Systemctl是Systemd的主命令,主要用于管理系统和服务。Systemd是Linux系统最新的初始化系统,也就是init,它的主要作用是提高系统的启动速度,尽可能启动较少的进程,并让更多的进程并发启动。
daemon-reload是一个systemd命令,它的主要功能是重新加载systemd的守护进程。当服务文件(service file)发生变化时,可以使用此命令来使这些变化立即生效,而无需重启整个系统。例如,如果你新安装了一个服务,并且这个服务被systemd管理,那么为了让新服务的配置文件生效,你需要运行
systemctl daemon-reload命令。此外,如果服务的程序配置文件发生了变化,也需要重新加载以使新的配置生效。需要注意的是,使用此命令需要管理员权限,通常可以通过在命令前添加
sudo来获取。例如:sudo systemctl daemon-reload。
重新加载配置文件
$ systemctl daemon-reload
启动kubelet
$ systemctl start kubelet
查看kubelet启动状态
$ systemctl status kubelet
没启动成功,报错先不管,后面的kubeadm init会拉起

设置开机自启动
$ systemctl enable kubelet

查看kubelet开机启动状态 enabled:开启, disabled:关闭
$ systemctl is-enabled kubelet

查看日志
journalctl -xefu是一个常用的命令,用于查看系统日志并显示错误信息。其中,各个选项的含义如下:
-x: 显示系统启动后的所有日志,包括正常和错误日志。-e: 只显示最近的错误日志。-f: 实时刷新日志输出,即当有新的日志产生时,会立即显示在屏幕上。-u: 显示内核日志。通过运行这个命令,可以快速定位系统中的问题,并了解系统的运行状态。例如,如果系统出现了崩溃或异常情况,可以使用此命令来查找相关的错误日志,以帮助解决问题。
$ journalctl -xefu kubelet
arm64环境,到此步后,先看看 FAQ中的问题4.
5.8 初始化K8S集群Master
注意,此操作只在规划的Master服务器上执行
#执行初始化命令
kubeadm init --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address=172.31.186.36 --kubernetes-version=v1.20.11 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
可能比较耗时,请耐心等待
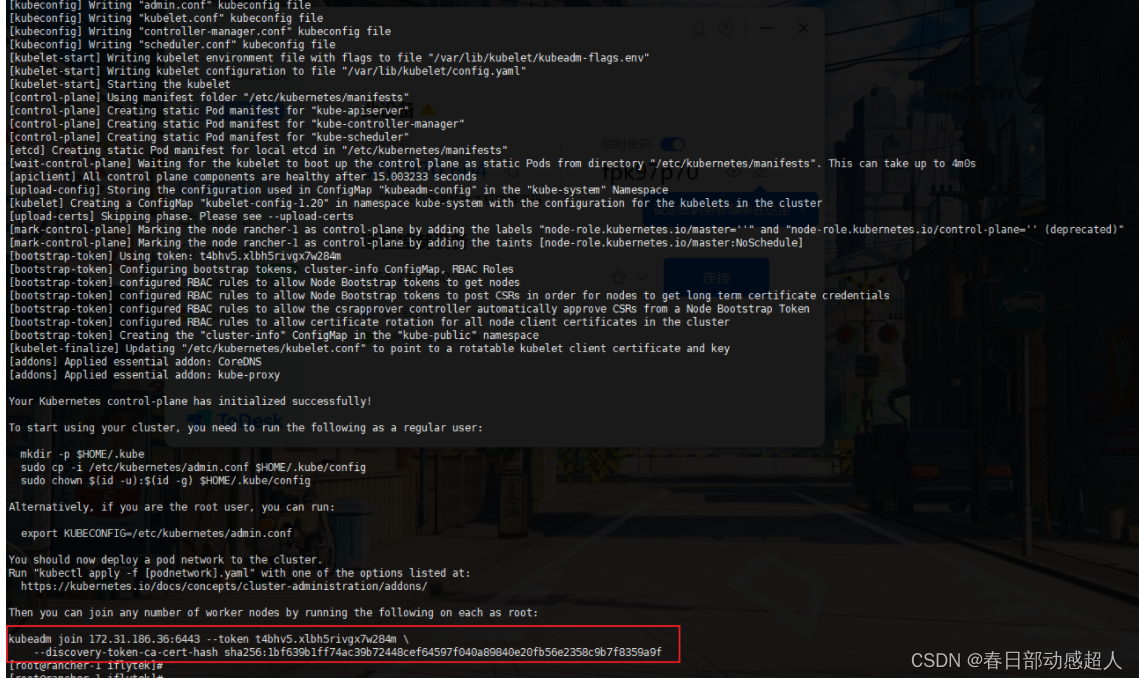
待初始化完成后,需要按照提示,执行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
这里需要注意,要将最后一个命令复制出来并且保存,用于后续添加节点使用:
kubeadm join 172.31.186.36:6443 --token t4bhv5.xlbh5rivgx7w284m \--discovery-token-ca-cert-hash sha256:1bf639b1ff74ac39b72448cef64597f040a89840e20fb56e2358c9b7f8359a9f
查看K8S集群节点
$ kubectl get node

NAME STATUS ROLES AGE VERSION
rancher-1 NotReady control-plane,master 13h v1.20.11
这里会发现状态是 NotReady ,是因为没有安装网络插件。
查看kubelet的日志
$ journalctl -xef -u kubelet -n 20
5.9 安装flannel网络插件
创建文件夹
$ mkdir -p /demo/package_k8s/flannel
$ cd /demo/package_k8s/flannel
在/demo/package_k8s/flannel目录,下载文件
curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
因为网络原因,可能比较耗时,如果下载失败了,请耐心的多尝试几次。
kube-flannel.yml里需要下载镜像,我这里提前先下载
$ docker pull quay.io/coreos/flannel:v0.14.0-rc1
创建flannel网络插件
$ kubectl apply -f kube-flannel.yml
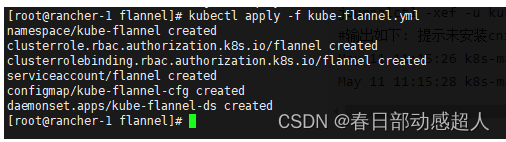
5.10 集群添加节点
在其他节点上执行5.1、5.2、5.3、5.4、5.5、5.6、5.7、5.9
执行完后,在除Master之外的节点执行 5.8 生产的命令:
kubeadm join 172.31.186.36:6443 --token t4bhv5.xlbh5rivgx7w284m \--discovery-token-ca-cert-hash sha256:1bf639b1ff74ac39b72448cef64597f040a89840e20fb56e2358c9b7f8359a9f

在master节点执行:
$ kubectl get node
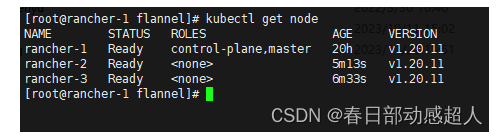
6 部署rancher
Rancher是一个企业级容器管理平台,可以帮助组织在生产环境中轻松快捷的部署和管理容器。Rancher支持多种云和本地生态系统,提供一键部署、多种编排调度工具、多租户、多种基础架构等功能,适用于混合云、多环境、多资源池、DevOps流水等场景 。
-
如果不需要用rancher来管理K8S集群,请忽略此章节。
-
如果当前环境已经部署完arm64的rancher,请忽略此章节。
部署rancher前,请保证arm64架构的docker已经部署成功
6.1 pull 镜像
rancher需要pull第三方镜像,为了节省时间,我们可以提前下载好rancher相关的镜像
这里的 docker中央仓库地址 只是举例,请根据实际情况填写 dockerpull 的镜像地址
执行如下pull:
docker pull docker中央仓库地址/fleet-agent:v0.3.10-security1
docker pull docker中央仓库地址/rancher-agent:v2.5.16
docker pull docker中央仓库地址/rancher:v2.5.16-linux-arm64
docker pull docker中央仓库地址/hyperkube:v1.20.15-rancher2
docker pull docker中央仓库地址/nginx-ingress-controller:nginx-1.2.1-rancher1
docker pull docker中央仓库地址/rke-tools:v0.1.80
docker pull docker中央仓库地址/mirrored-coreos-flannel:v0.15.1
docker pull docker中央仓库地址/mirrored-ingress-nginx-kube-webhook-certgen:v1.1.1
docker pull docker中央仓库地址/hyperkube:v1.20.11-rancher1
docker pull docker中央仓库地址/mirrored-pause:3.6
docker pull docker中央仓库地址/rke-tools:v0.1.78
docker pull docker中央仓库地址/mirrored-metrics-server:v0.5.0
docker pull docker中央仓库地址/nginx-ingress-controller:nginx-0.43.0-rancher3
docker pull docker中央仓库地址/mirrored-coreos-etcd:v3.4.15-rancher1
docker pull docker中央仓库地址/mirrored-coredns-coredns:1.8.0
docker pull docker中央仓库地址/mirrored-cluster-proportional-autoscaler:1.8.1
docker pull docker中央仓库地址/flannel-cni:v0.3.0-rancher6
docker pull docker中央仓库地址/kube-api-auth:v0.1.4
docker pull docker中央仓库地址/mirrored-pause:3.2
注意:执行到docker pull docker中央仓库地址/mirrored-pause:3.2时,可能需要手动按一下回车键。
6.2 启动rancher
这里会先从仓库拉取rancher的镜像,根据网络环境,可能耗时较久,请等待。
docker run -d --privileged --restart=unless-stopped -p 8080:80 -p 8445:443 \
-v /demo/data/rancher/rancher:/var/lib/rancher \
-v /demo/data/rancher/auditlog:/var/log/auditlog \
--name rancher rancher/rancher:v2.5.16-linux-arm64
稍等片刻,浏览器输入:https://ip:8445/g/clusters
部署完rancher后,第一次打开页面,需要进行免密设置
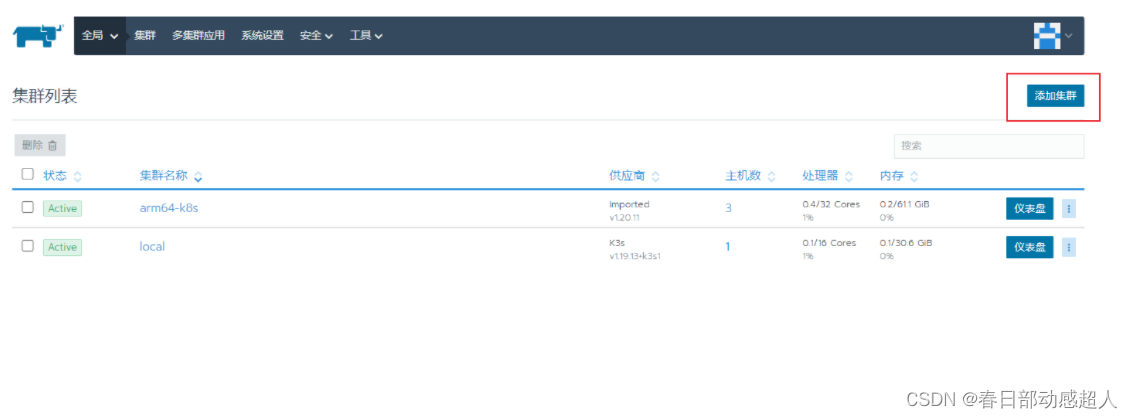
6.3 导入K8S集群
进入rancher页面,点击右上角的 “添加集群” 操作
然后选择 “导入”
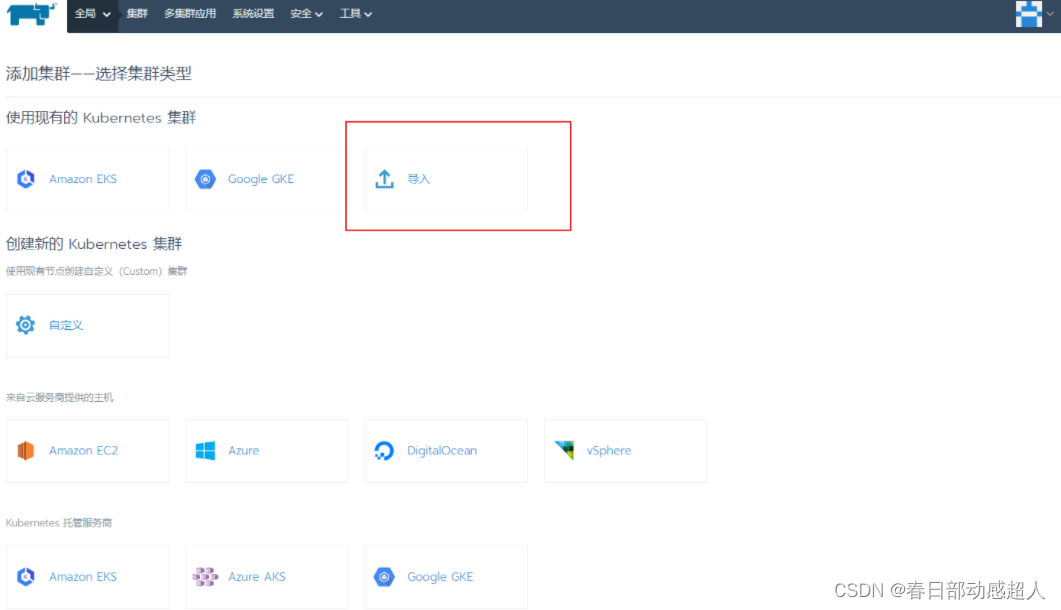
填写K8S集群名称
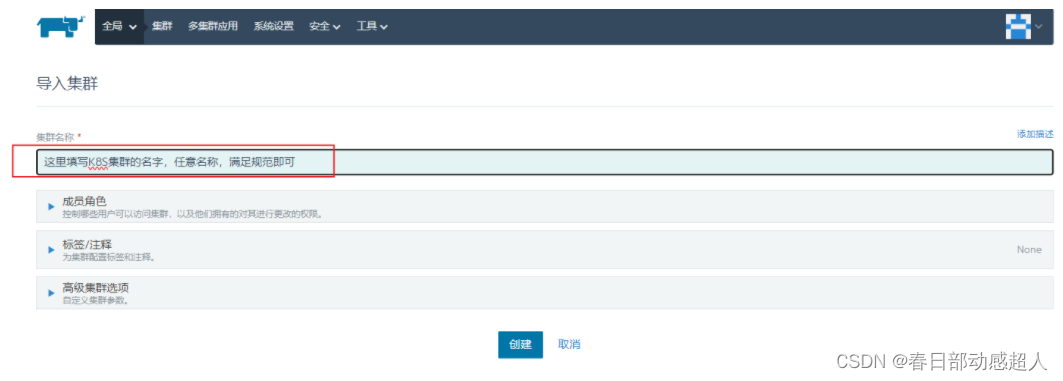
点击 “创建” 按钮后,会出现三个命令行,将第一个命令行的 [USER_ACCOUNT]替换为 admin。
依次在K8S Master机器上执行下面三个命令行。
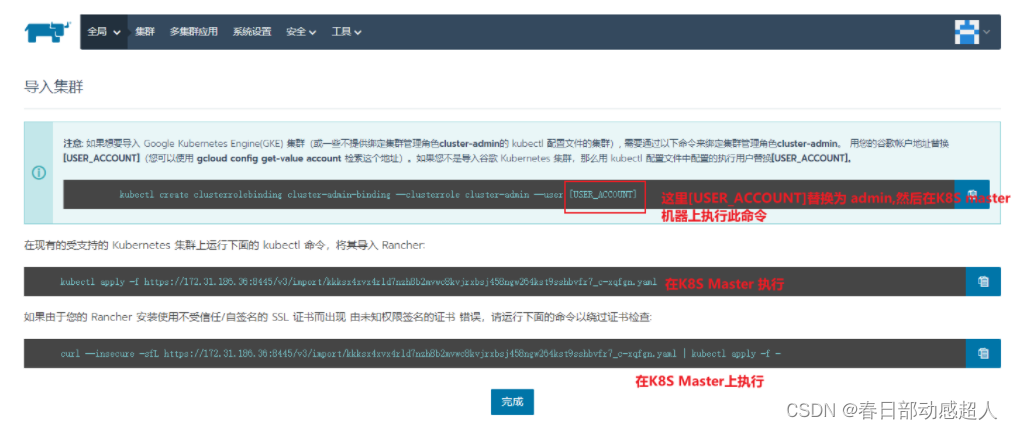
执行命令1
在K8S master机器上执行:
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user admin
执行命令2
$ kubectl apply -f https://172.31.186.36:8445/v3/import/kkksx4xvx4rld7nzh8b2mvwc8kvjrxbsj458ngw264kst9sshbvfr7_c-xqfgn.yaml
如果执行命令2时,x509错误,则可以通过将对应的yaml文件下载到服务器本地,然后执行apply
下载yaml文件
$ wget https://172.31.186.36:8445/v3/import/6w5jzw4wtc7pg7h8cjbhcnj4ptbhgkdrrsc8ftjgkhqkvm2qc557tv_c-9g9rs.yaml --no-check-certificate
执行安装:
$ kubectl apply -f 6w5jzw4wtc7pg7h8cjbhcnj4ptbhgkdrrsc8ftjgkhqkvm2qc557tv_c-9g9rs.yaml
执行命令3
执行复制忽略证书检查命令:
curl --insecure -sfL https://172.31.186.36:8445/v3/import/7d64lpx6gpl8mdz4tz9nzk6r2wb684fls7fs728ns2sbzvzfdw55j4_c-llx8j.yaml | kubectl apply -f -
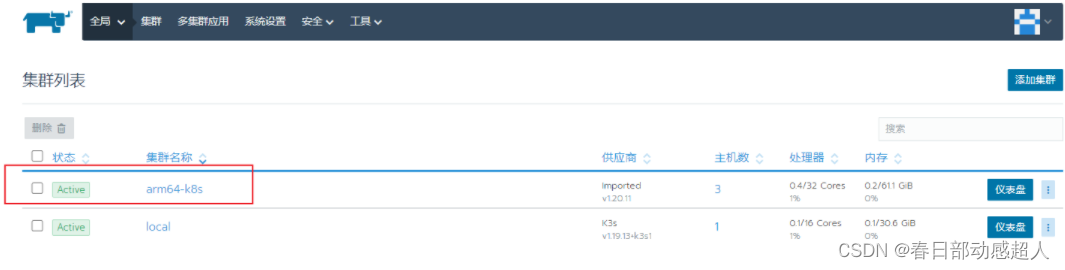
稍等片刻,如果一切顺利,则可看到如下:
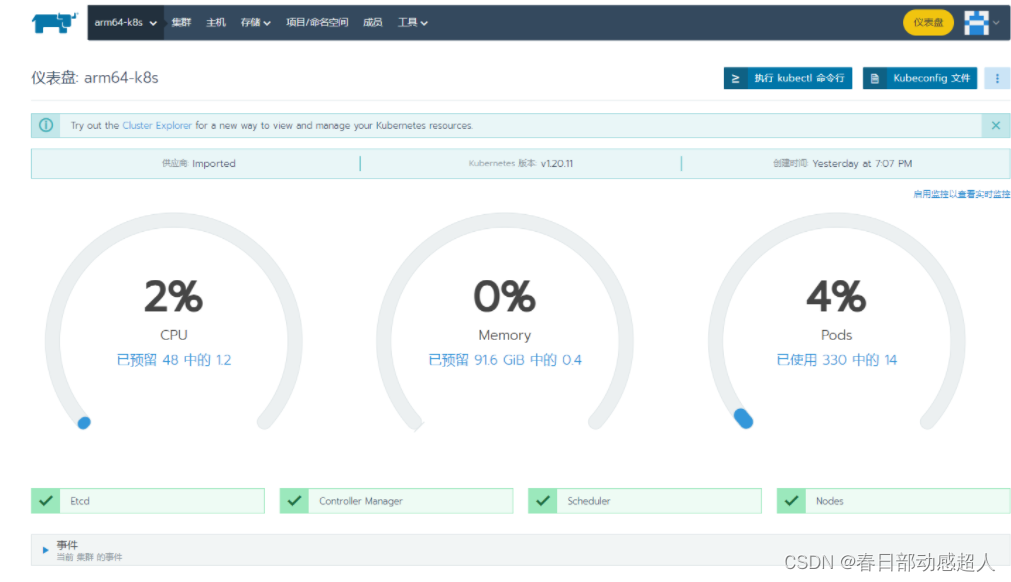
FAQ
1 问题:节点状态为NotReady
如果安装了flannel网络插件后,查看节点状态,仍然是 NotReady
且日志显示 failed to find plugin “portmap” in path [/opt/cni/bin]

查看日志
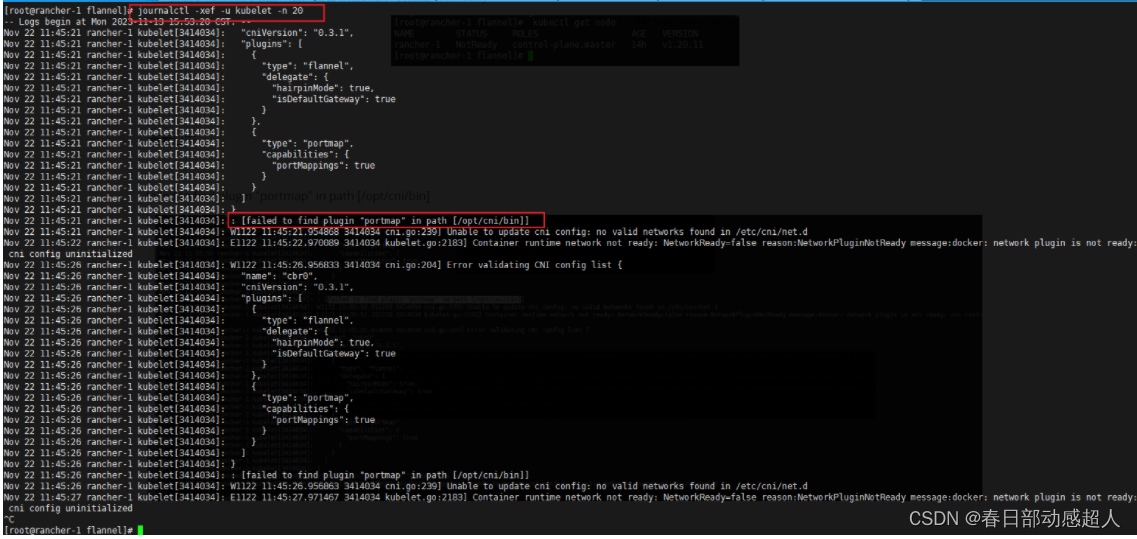
解决方案:
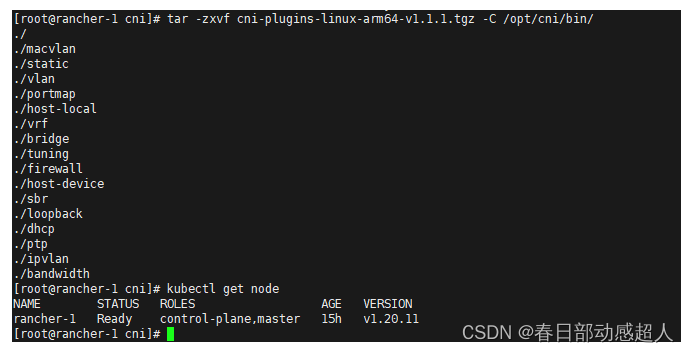
下载 cni-plugins-linux-arm64-v1.1.1.tgz 包,然后解压,将其中的文件copy到 /opt/cni/bin/ 目录下即可
tar -zxvf cni-plugins-linux-arm64-v1.1.1.tgz -C /opt/cni/bin
2 问题:在非master节点执行 kubectl get node

kubectl命令需要使用kubernetes-admin来运行,需要admin.conf文件(conf文件是通过“ kubeadmin init”命令在主节点/etc/kubernetes 中创建),但是从节点没有conf文件,也没有设置 KUBECONFIG =/root/admin.conf环境变量,所以需要复制conf文件到从节点,并设置环境变量就OK了。
其实这个问题也没必要解决,不影响。
3 问题:rancher面板中 Controller Manager与 Scheduler不健康
如果rancher面板中 Controller Manager与 Scheduler不健康
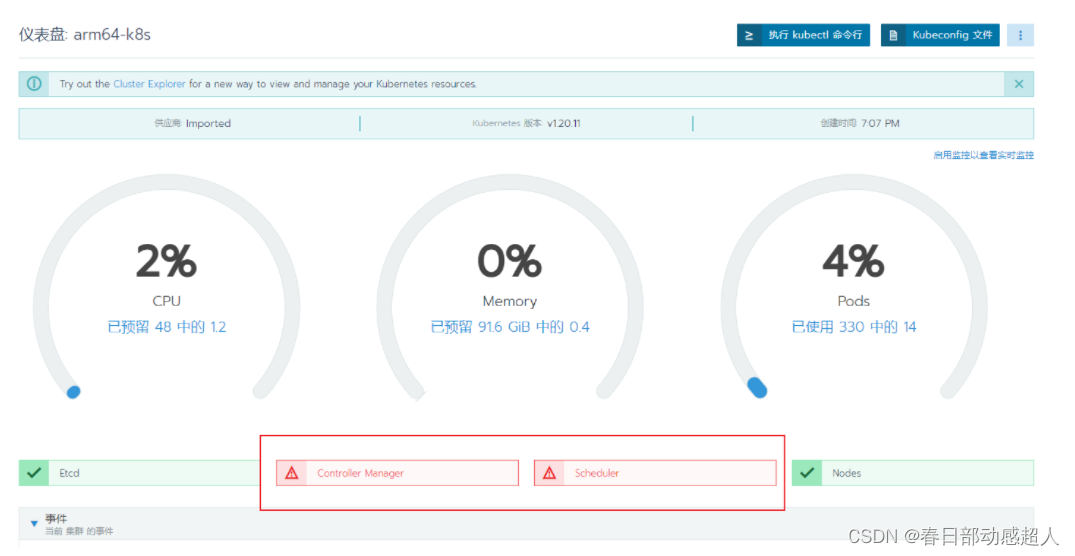
登录到master server机器,修改如下文件:
- /etc/kubernetes/manifests/kube-controller-manager.yaml
- /etc/kubernetes/manifests/kube-scheduler.yaml
两个文件中删除 --port=0 配置项
然后重启kubelete
$ service kubelet restart
稍等片刻,如果一切顺利,Controller Manager与 Scheduler将恢复健康。
4 问题:failed to find plugin “portmap” in path [/opt/cni/bin]
如果kubelet服务异常,且日志里有如下报错:
failed to find plugin "portmap" in path [/opt/cni/bin]
大概率是/opt/cni/bin目录下没有对应的 portmap 插件
解决方案:
1、下载 cni-plugins-linux-arm64-v1.1.1.tgz 插件
$ wget https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-arm64-v1.1.1.tgz
2、解压 cni-plugins-linux-arm64-v1.1.1.tgz 插件,并且复制到 /opt/cni/bin/
$ tar -zxvf cni-plugins-linux-arm64-v1.1.1.tgz -C /opt/cni/bin/
/opt/cni/bin是一个目录路径,通常用于存放网络连接插件(CNI)的可执行文件。CNI是容器网络接口(Container Network Interface)的缩写,它提供了一种标准化的方式来定义和实现容器运行时的网络连接。在Kubernetes等容器编排系统中,每个节点上的CNI插件负责为在该节点上运行的容器创建、配置和管理网络连接。这些插件可以提供不同的网络解决方案,例如桥接、路由、隧道等。
具体来说,
/opt/cni/bin目录通常包含以下内容:
ip: IP地址管理工具,用于分配IP地址给容器。bridge: 桥接网络插件,用于在主机上创建一个虚拟网络桥接,并将容器连接到该桥接上。flannel: Flannel是一种覆盖网络(Overlay Network)解决方案,用于在主机之间建立虚拟网络连接。weave: Weave是一种基于IPv6的覆盖网络解决方案,用于在主机之间自动创建虚拟网络连接。calico: Calico是一种高性能的容器网络解决方案,支持多种网络模型和策略。请注意,具体的CNI插件可能因系统和部署环境而异。以上列出的插件只是一些常见的示例。
附录 K8S 运维技术点简介
删除POD
要删除 Kubernetes(K8S)中的 Pod,可以使用 kubectl delete pod 命令。下面是删除 Pod 的一般格式:
# kubectl delete pod <pod-name> [-n=<namespace>]
$ kubectl delete pod coredns-7f89b7bc75-46tlx -n kube-system
按照创建时间升序查看POD
要按照创建时间升序查看 Kubernetes(K8S)中的 Pod,可以使用 kubectl get pods --sort-by=.metadata.creationTimestamp 命令。
$ kubectl get pods -A --sort-by=.metadata.creationTimestamp