一、说明
文本摘要是一种自然语言处理技术,允许用户将大量文本总结为小块,而不会丢失任何重要信息。本文介绍NLP中使用Gensim和Sumy实现文本摘要的步骤。
二、为什么要总结文本?
互联网包含大量信息,而且每秒都在增加。文本摘要可以通过提供长文本的简单、非正式的摘要来提供帮助。除了摘要之外,它还可以让用户快速准确地识别段落或文章的基本内容。
总结文本有很多正当理由,包括:
- 减少阅读时间
- 提高生产力
- 不错过重要事实
- 使文本轮廓更容易
文本摘要有两种主要方法:提取式和抽象式。
2.1 抽取文本摘要
此方法通过从原始文本中选择最常用的短语和句子来创建摘要。最重要的单词和句子以及与该主题相关的信息最多的单词和句子被优先考虑。
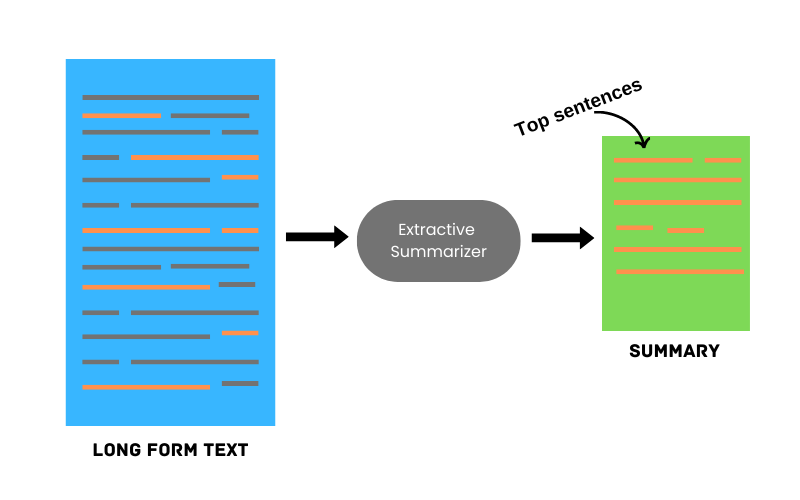
使用提取摘要器的示例:
长文本:Python 是一种高级、解释性、交互式、面向对象的脚本语言。对于初级程序员来说,Python 是一门很棒的语言。
摘 要:Python 是一种高级的、解释性的、交互式的、面向对象的脚本语言。
2.2 抽象文本摘要
抽象摘要方法涉及生成传达源文档含义的全新短语和句子。它利用算法和数学以更短的形式创建原始文本的表示。
让我们用一个简单的例子来理解抽象总结器:
长文本:Python 是一种高级、解释性、交互式、面向对象的脚本语言。对于初级程序员来说,Python 是一门很棒的语言。
摘要:Python 是一种高级脚本语言,对于初级程序员很有帮助。
这两种技术都有各自的用途。对于第一个,人们可以通过从源中挑选最热门的单词来创建简短的摘要。另一方面,第二种方法可以通过添加自己的文字来完全改变摘要,从而使原始消息不会消失。让我们看看如何用 Python 构建这些!
三、构建一个提取文本摘要器
NLTK(自然语言处理工具包)是一个 Python 库,提供了一组可用于构建文本摘要的工具。
我们将使用Python 编程维基百科页面内容作为示例。让我们编写一个简单的函数来使用requests和 BeautifulSoup从互联网页中抓取数据:
from bs4 import BeautifulSoup
import requestsdef scrape_con(url):res = requests.get(url)soup = BeautifulSoup(res.text,'html.parser') content = soup.findAll("p")data = ""for text in content:data +=text.textreturn datascrape_con('https://en.wikipedia.org/wiki/Python_(programming_language)')文本摘要的第一步是清理文本。我们将执行一些基本的文本清理,例如将文本转换为小写、删除标点符号等。您可以从我之前关于心跳的文章中阅读有关文本清理的更多信息。
import re
def clean_data(data):text = re.sub(r"\[[0-9]*\]"," ",data)text = text.lower()text = re.sub(r'\s+'," ",text)text = re.sub(r","," ",text)return text
cleaned_data = clean_data(raw_data)清理数据后,下一步将是创建单词和句子标记并计算每个标记的频率。
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk.tokenize import sent_tokenize,word_tokenizesent_tokens = sent_tokenize(cleaned_data)
word_tokens = word_tokenize(cleaned_data)
word_frequency = {}
stopwords = set(stopwords.words("english"))for word in word_tokens:if word not in stopwords:if word not in word_frequency.keys():word_frequency[word]=1else:word_frequency[word] +=1
for word in word_frequency.keys():word_frequency[word] = (word_frequency[word]/maximum_frequency)现在,我们将借助词典生成句子分数word_frequency。
sentences_score = {}
for sentence in sent_tokens:for word in word_tokenize(sentence):if word in word_frequency.keys():if (len(sentence.split(" "))) <30:if sentence not in sentences_score.keys():sentences_score[sentence] = word_frequency[word]else:sentences_score[sentence] += word_frequency[word] 最后,我们使用该heapq库提取前n个句子并将它们包含在最终摘要中。n是用户定义的数字,在下面的示例中我们将其设置为 3。
def get_key(val): for key, value in sentences_score.items(): if val == value: return key
key = get_key(max(sentences_score.values()))
summary = heapq.nlargest(n,sentences_score,key=sentences_score.get) ## n=3
print(" ".join(summary))python 的名字源自英国喜剧团体 monty python,Python 的创建者 Guido van rossum 在开发该语言时很喜欢这个团体。python 3.10 弃用了 wstr (将在 python 3.12 中删除;意味着届时需要修改 python 扩展)并向该语言添加模式匹配。
还有其他库以更自动化的方式提供相同的解决方案。我们将在下面探讨它们。
隔离困难的数据样本?彗星可以做到这一点。通过我们的 PetCam 场景了解更多信息并发现彗星文物。
3.1.Gensim
Gensim 是一个开源库,用于无监督主题建模、文档索引、相似性检索和其他自然语言处理功能,使用现代统计机器学习,如维基百科所述。
Gensim 有一个summarize带有内置提取文本摘要器的类。让我们使用维基百科中的相同网页并使用gensim摘要器对其进行总结。
import gensim
import re
from gensim.summarization.summarizer import summarize
import requests
from bs4 import BeautifulSoupurl = 'https://en.wikipedia.org/wiki/Python_(programming_language)'res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')extracted_rows_content = []
for i in range(len(soup.select('p'))):row_text = soup.select('p')[i].getText().strip()extracted_rows_content.append(row_text)
raw_data = " ".join(extracted_rows_content)import re
def clean_data(data):text = re.sub(r"\[[0-9]*\]"," ",data)text = text.lower()text = re.sub(r'\s+'," ",text)text = re.sub(r","," ",text)return text
cleaned_article_content = clean_data(raw_data)summary = summarize(cleaned_article_content, ratio = 0.01)
summary = re.sub('\[[^\]]*\]','',summary)
print(summary)标准库的部分内容由规范涵盖 - 例如 Web 服务器网关接口 (wsgi) 实现 wsgiref 遵循 pep 333 - 但大多数是由其代码内部文档和测试套件指定的。
3.2. Sumy
Sumy 是一个用于从 HTML 页面或纯文本中提取摘要的 Python 库。它使用多种算法来准备摘要。例如,我们正在使用 LexRank 算法,其主要思想是,如果一个句子与许多其他句子非常相似,那么它很可能是包含在摘要中的重要句子。
import sumy
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizerimport requests
from bs4 import BeautifulSoupurl = 'https://en.wikipedia.org/wiki/Python_(programming_language)'res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')articles = []
for i in range(len(soup.select('p'))):article = soup.select('p')[i].getText().strip()articles.append(article)
raw_data = " ".join(articles)import re
def clean_data(data):text = re.sub(r"\[[0-9]*\]"," ",data)text = text.lower()text = re.sub(r'\s+'," ",text)text = re.sub(r","," ",text)return text
cleaned_article_content = clean_data(raw_data)# For Strings
parser = PlaintextParser.from_string(cleaned_article_content,Tokenizer("english"))summarizer = LexRankSummarizer()
#Summarize the document with 2 sentences
summary = summarizer(parser.document, 2)for sentence in summary:print(sentence) 除了 LexRank 之外,Sumy 还有其他汇总方法,如Luhn、TextRank、SumBasic和LSA。潜在语义分析(LSA)是近年来最常用的方法。该方法能够识别文本中的同义词以及文档中未明确写入的主题。LsaSummarizer您可以通过从类导入来使用它sumy.summarizers.lsa。
四、结论
文本摘要可以通过简短的摘要表示主要事实来减少文章的阅读时间。提取和抽象方法都可以使用不同的方法来做到这一点。这完全取决于您的用例以及您需要哪种方法。当然,在某些情况下,提取摘要器无法在摘要中包含最上面的句子,而抽象摘要器会生成完全不同的摘要。最后,它们都只是需要一定程度的人类评估的算法。
五、推荐读物
1. Abstractive Text Summarization Using Python [Kaggle Notebook] 2. An approach to abstractive text summarization [IEEE Research Papaer] 3. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond [cornell university (arxiv)] 4. Using Latent Semantic Analysis in Text Summarization and Summary Evaluation [By Josef Steinberger and Karel Ježek]5. 使用 Python 和 NLTK 进行文本摘要 |由 Abhay Parashar |心跳 (comet.ml)