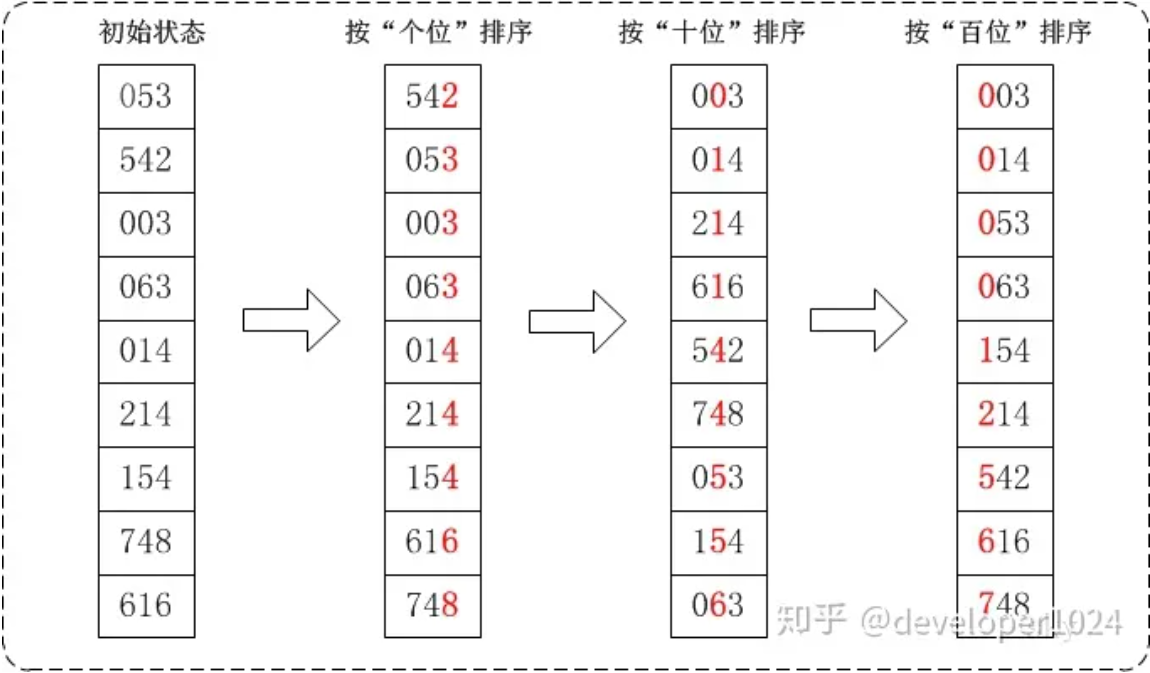
数据中心 incast,广域网拥塞,内存墙都是一类问题。
我接触 incast 很久了,大多是帮忙查问题,也解过几例。
我记得有一次在业务几乎总是(在统计学上,几乎和总是属同义强调) tail latency 很大时,我建议在 sender 方加一个 0~rtt/2 的随机 delay,果然就缓解了。我尝试把这个方案 “永久” 化。
我觉得无论 clos 还是 leaf-spine 都太正则,它们是问题的原因而不是解法,特别在 mapreduce 场景,正则拓扑往往引发全局同步,所有服务器在 10ns 粒度同时发送数据,经过几乎等长的光纤同时到达 tor,剩下的交给 buffer 和时间,这就是 incast。
也因此,我建议插入随机时延。随机几乎是万金油,当你没有办法时,就想想随机。
但何必绕这么个圈子呢?先同步,再打乱?谁说下面的拓扑不合适呢:
我知道 mesh 不该那样,我是故意的。光纤随机长度,汇聚 sw 下直接挂服务器,乱七八糟互联,都是些不负责任的拓扑,但都能缓解 incast,核心在于都引入了随机,至于它带来的混乱问题,就看和 incast 相比孰轻孰重了。
简单计算,信号 10ns 可传输 2m,40Gbps 交换机为例,报文间隔 200ns 即可避免拥塞,服务器只要有 0~20m 随机长度差即可缓解大部分 incast,这很容易。带宽越高,要求随机长度差越小,实施越容易。这只是开始。
站在这视角上升,然后往下看,就看到了 cpu 的内存墙。核越多,内存显得越慢,本质还是拥塞,好像多条流穿越一个瓶颈,受制于带宽。
只要涉及通信,那么 rtt 的开销就必不可少,而 rtt = 处理时延 + 传播时延 + 排队时延。传播时延只能减少距离来降低,cdn,内存离核越来越近,都在干这事。而处理时延受限于自身跟别人无关,一会儿说,排队时延比较有趣,先说它。
信道容量有限,需要通信方同步,同步是对通信信道达成共识的过程,因此排队时延是一种同步时延,通信量随通信方指数增长,而带宽却不能。cdn 卸载了骨干流量,但回源流量还在,前端总线越来越堵,加带宽也没法弥补,干脆处理核独享内存控制器,但只要内存本身还共享,问题就没解决。
回来说处理时延,处理时延也是种同步时延,即通信双方能力的同步,最终对木桶达成共识,效率取决于弱者。像 cpu 和内存,本就是两类东西,几乎可以肯定内存一定不比 cpu 快,否则二者就会反转,你快你算吧,至少能加速存内计算的普及。
综上,无论数据中心,广域网,还是 cpu 和内存,问题都围绕三个 rtt 组分:一方快另一方慢;距离太远;带宽太小而拥塞。解决这些问题的方法也一致:拉近距离,要么独享,要么错开。
L1/L2 cache 和 cdn 一样,但问题也和 cdn 一样,只是被小时延放大了问题尺度。这些都是细枝末节。
周五早上问 chatgpt “能不能随机化服务器光纤长度来缓解 incast”,chatgpt 说能,但不好,教我 “要用拥塞控制,流控和 buffer 来解决问题“,我一看这些就烦,这不都是经理们天天瞎咧咧的吗,瞎 JB 卷,结果这些恰是问题的原因而不是方案,我发了个朋友圈,把 cu 口去了:
问行不行就是行,问好不好就是不好。就算编程的人都知道尽量别动共享变量,避开同步,要异步,要percpu,怎么到了网络这里就开始天天瞎扯拥塞控制而不是异步避免拥塞,同样在处理器访存时那么多核心一起访问内存,内存墙越来越高后瞎折腾 L2/L3 cache 而不是搞独占和错峰,都 TMD 治标不治本且越搞越复杂好吗,一回事的解法也是一回事,三层架构和叶脊都太正则了,这不明显去硬碰同步的吗,路边摊小贩都知道摆一路而不是摆一排,公务员和经理都知道错峰上班,一帮工人一起挤着打卡堵了不是活该?就不能不规定准点上班?谁规定汇聚设备下不能挂服务器了,让你们错开为你们好,总有 SB 瞎怼挑毛病。当然,为了卷绩效的话你说什么都对。
多跟编程的学学,避开共享,避开同步,放之四海而皆准。编程的时候知道,不编就忘了?同步就是峰谷落差太大,集中力量闯大祸。所有人一起跺脚的频率和桥匹配,能把桥振塌,所有流量一起到,能把 buffer 干爆,所有处理核一起 spin,能把板子烧了。
尝试一下如何从根本上解决问题,而不是 “尽可能缩短时间”,后者毕竟只是缓解而不是解决。根本方案就是消除数据通信。这会儿从 cpu 说起。
最初,cpu 是数据面核心,所有数据都要送往 cpu。冯诺依曼存结构,cpu 负责计算,内存负责存储,两者之间必然要通信。于是计算,存储,通信三大件儿,各按自身规律独立发展。但随着单一功能外设(我关注网卡)快速发展,cpu 很快成了慢速设备,更别提内存了。事实上,cpu 大多也是被内存拖累, 访存时间太慢,但无论如何,冯诺依曼结构决定了 cpu 和内存只能共荣辱。
cpu 成了控制面,不再被寄希望于干重活。Linux 内核被认为不是千万并发的方案,而是问题所在,大家想方设法 bypass kernel,bypass cpu,kernel 和 cpu 在高性能网络领域被认为很 low。
事实上,不是 cpu low,高性能网卡毕竟功能相对单一,携带大量 offloading engine,比 cpu 更快处理网络报文理所当然,但当它们遇到甚至 1.6Tbps 时,也会逐渐吃力,你看,它们和 cpu + 内存没有本质区别。
问题不在 cpu,问题在冯诺依曼结构根本上是个网络通信结构,统计复用的带宽同步争抢问题是固有的,再大带宽也挡不住概率性突发。
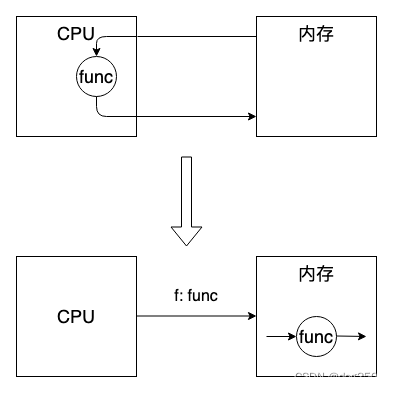
如果倒转视角,把 cpu 当作控制面而不再是 “中央(数据)处理” 器,而以内存为 “中央”,并在内存的存储颗粒间嵌入计算单元(摩尔定律允许这么做),cpu 只负责将 “代码” 发给内存,内存自己进行计算和存储,就打破了冯诺依曼结构,消除了数据通信时对内存带宽的同步争抢:
mapreduce 网络传输也可以这么玩,举一例,不要将片段扇入到一个节点再,一边走一边拼接,走到底也拼完了,以数据本身为中心而不是以数据传输为中心,过交换机的时候一定是一份大数据,而不是多份小数据,只有一条流显然就消除了同步访问,更容易做流控:

无意同步,却全局同步,有意同步,以合作代替争抢,这很辩证。
性能问题就是时间问题,时间问题的根源在等待资源,无论网络传输还是 cpu 内存传输都一样。最终所有问题归根结底就是多路复用问题,而多路复用则分为统计复用和非统计复用(如时分复用),区别在于统计复用会因个体异常拉偏均值,比如 tail latency.
当我们说 “系统性能差” 时,一定是在抱怨时间太久,但真实的 “系统” 性能差一定不针对个体,它一定是全局的。系统性能差几乎一定是资源不足,剩下的就是使用资源的方式了,由于统计复用个体会拉偏整体,“要异步使用资源,而不是同步使用”,也就是本文的主旨。
说一万次了,buffer 不属于系统资源,带宽才是。
浙江温州皮鞋湿,下雨进水不会胖。



![pwn:[NISACTF 2022]ReorPwn?](https://img-blog.csdnimg.cn/e1a07b80e15e4234b4d5979634dc5302.png)