今天分享的是人形机器人系列深度研究报告:《2023人形机器人行业海外科技研究:从谷歌看机器人大模型进展》。
(报告出品方:华鑫证券)
报告共计:26页


大模型是人形机器人的必备要素
长期来看,人形机器人的最大优势在于通用性:
人形机器人的特点在于泛化能力。如果只为解决单一或少数场景的应用,则特定专用机器人足以满足要求(如酒店服务机器人,扫地机器人等,从第一性原理来说,机器人之所以拟人,其根本目的在于完成多样化的任务一一能爬楼梯,能按电梯能提重物等完成所有人类所需的各种任务
通用性的实现依赖大模型的应用 (体现在感知与识别) :
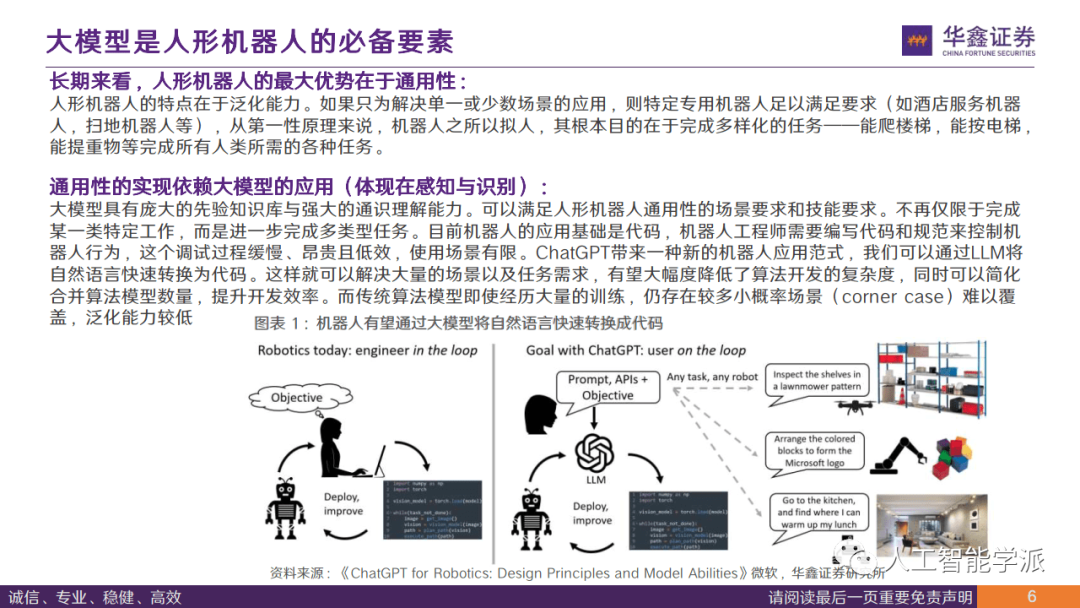
大模型具有庞大的先验知识库与强大的通识理解能力。可以满足人形机器人通用性的场景要求和技能要求。不再仅限于完成某一类特定工作,而是进一步完成多类型任务。目前机器人的应用基础是代码,机器人工程师需要编写代码和规范来控制机器人行为,这个调试过程缓慢、昂贵且低效,使用场景有限。ChatGPT带来一种新的机器人应用范式,我们可以通过LLM将自然语言快速转换为代码。这样就可以解决大量的场景以及任务需求,有望大幅度降低了算法开发的复杂度,同时可以简化合并算法模型数量,提升开发效率。而传统算法模型即使经历大量的训练,仍存在较多小概率场景(corner case) 难以零盖,泛化能力较低。
大模型是人形机器人的必备要素
人形机器人大模型所需的视频数据足够充足 (体现在后续的动作):
深度学习的本质是模仿,可以用大量的人类视频来进行预训练/模仿学习,之后再通过标注用Reinforcement Learning进行微调。机器人做成人形也是为大模型在机器人上的发展铺垫。
思维链条:
思维链(Chain of Thought,CoT)是一种思维工具,通过逐步延伸和拓展一个主要想法,帮助人们进行更深层次的思考,并得出更复杂、更全面的结论。在机器人大模型上,思维链可以帮助机器人拆分与分解一件事件如何完成,增加了先解码出计划的步骤,再解码需要完成任务需要输出的动作,在需要语义推理任务上效果更好。
在谷歌7月发布展示的具身大模型中RT-2中,机器人展示了类似视觉语言模型 (VLM) 的思维链,如: 选出与其他物品不同的物品:告诉机器人很困,让机器人拿饮料,机器人会拿红牛:让机器人完成锤钉子任务,但桌子上只有耳机线、石头、纸,使用思维链后机器人会拿石头等。


SayCan:谷歌机器人大模型的开端,连接LLM与具身智能
• 2022 年4月,谷歌推出 Say-can 模型。将任务拆分成两个部分,先是 “Say”,模型通过与谷歌的大语言模型结合, 把获得的任务进行分解,找到最适合当前行动;之后是“Can”,模型计算出当前机器人能够成功执行这一任务的概率。 机器人通过将二者结合起来,进行动作。例子:对机器人说“我的饮料撒了,你能帮助我吗”机器人会首先通过语言模型 进行任务规划,这时可能最合理的方式是找到一个清洁工、找到一个吸尘器,找一块海绵自己擦等。然后机器人会通过价 值函数计算出作为机器人,找到海绵自己擦是最佳方案。之后,机器人就会选择寻找海绵的动作。
• 亮点:首次引入大语言模型帮助理解任务,选择合适的任务规划。
• 不足:机器人的动作仍然是预设好的,因此只能完成特定任务。底层技能通用性和泛用性较差。只能输出高级指令。

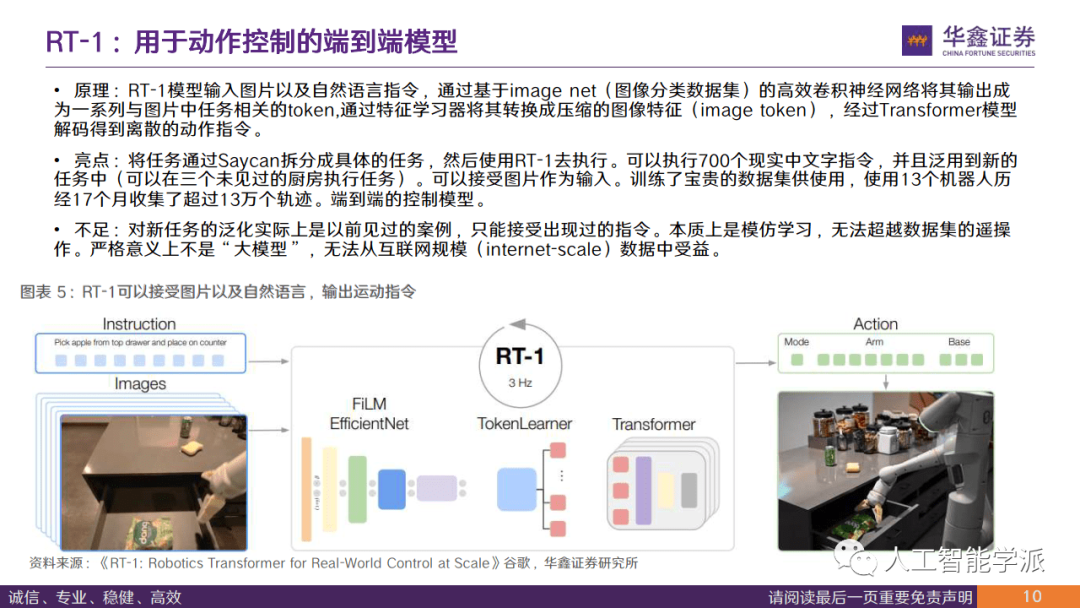
RT-1:用于动作控制的端到端模型
• 原理:RT-1模型输入图片以及自然语言指令,通过基于image net(图像分类数据集)的高效卷积神经网络将其输出成 为一系列与图片中任务相关的token,通过特征学习器将其转换成压缩的图像特征(image token),经过Transformer模型 解码得到离散的动作指令。
• 亮点:将任务通过Saycan拆分成具体的任务,然后使用RT-1去执行。可以执行700个现实中文字指令,并且泛用到新的 任务中(可以在三个未见过的厨房执行任务)。可以接受图片作为输入。训练了宝贵的数据集供使用,使用13个机器人历 经17个月收集了超过13万个轨迹。端到端的控制模型。
• 不足:对新任务的泛化实际上是以前见过的案例,只能接受出现过的指令。本质上是模仿学习,无法超越数据集的遥操 作。严格意义上不是“大模型”,无法从互联网规模(internet-scale)数据中受益。
PaLM-E:多模态视觉语言具身大模型(VLM)
• 原理:由谷歌大语言模型PaLM与拥有220亿个参数的最大视觉模型ViT-22B结合而成,输入连续的视觉、状态、文字之 后,在已经预训练的大语言模型PaLM基础上进行端到端训练,用于多个具体任务,包括顺序机器人操作规划、视觉问题解 答和图像视频字幕描述。最终输出文本形式的高级任务指令(可以是问题的答案,也可以是PaLM-E以文本形式生成的一系 列决策,这些决策应由机器人执行)。
• 亮点:让机器人能够接收持续的多模态的输入(包括文本,图片,状态以及其他传感器模态),连续信息以类似于语言 标记的方式注入到语言模型中,并具有一定的推理能力。参数量级有明显提升,5620亿的参数模型。
• 不足:本质为大语言模型,对于动作的完成和指导较弱。只解决机器人的高级别指令,没有更基础层级的具体运动控制 相关指令。

RT-2:控制机器人的视觉 - 语言 - 动作(VLA)大模型
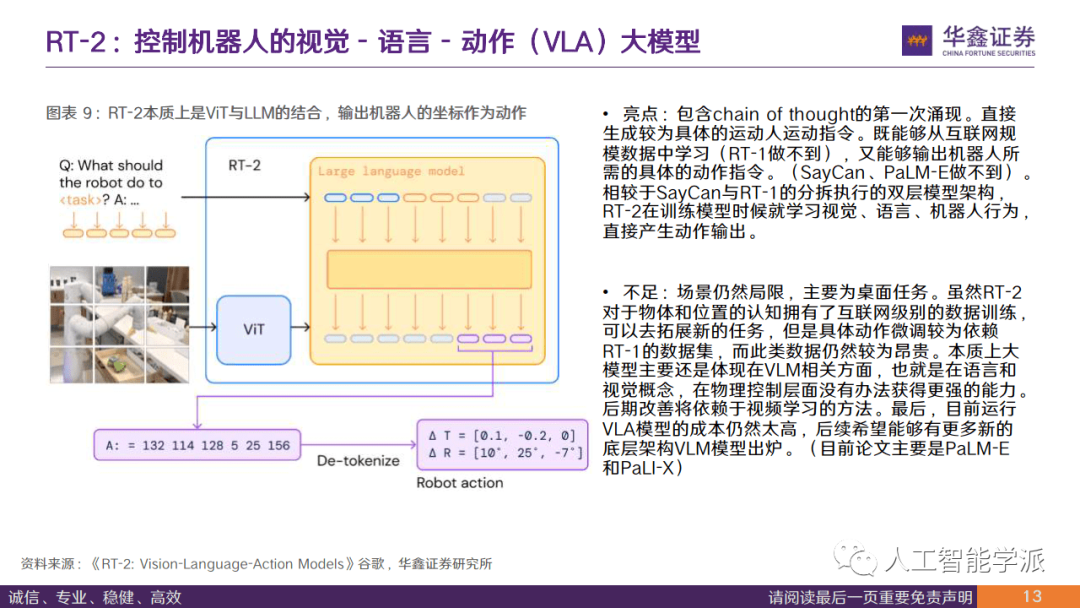
• 原理:机器人数据仍然稀缺的背景下,收集到海量机器人数据难度太大。因此谷歌RT-2抛弃了RT-1从头训练 Transformer模型的方式,而是直接采用已有的视觉语言模型(VLM)作为主模型,再使用更适合机器人任务的方法对其进行微调(结合RT-1的视觉/语言/机器人动作数据集与互联网级别数据共同微调co-fine-tuning),最终输出机器人行为字符串。
• 在这种训练方式下,机器人模型拥有一个已经预训练好的VLM模型,可以理解成一个互联网数据级别的常识系统,能够 识别物体、了解物体。而在后续的微调阶段,再加入机器人实际抓取物体的数据集。
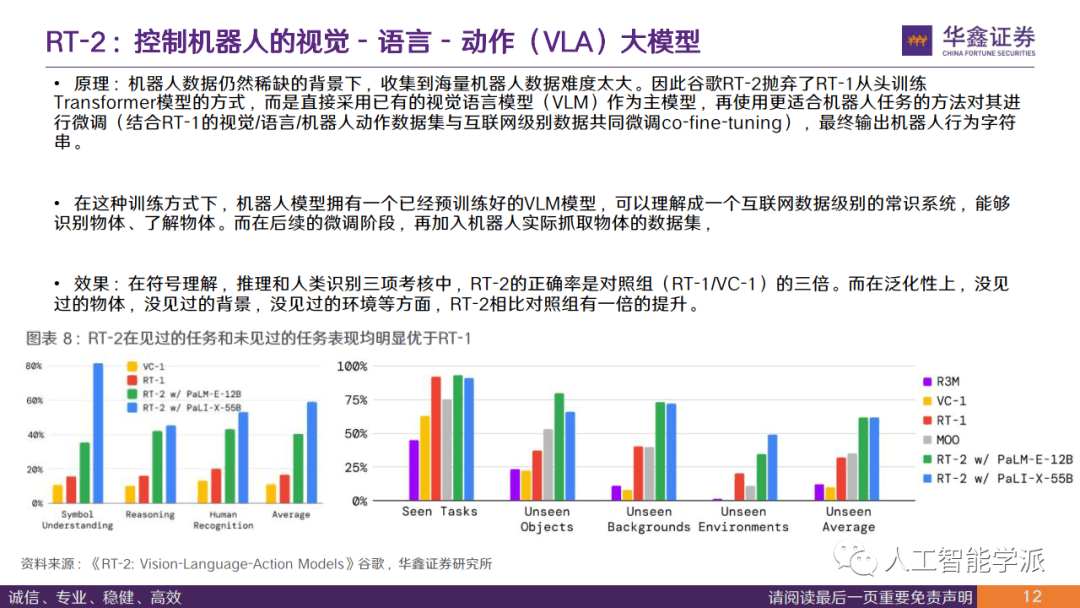
• 效果:在符号理解,推理和人类识别三项考核中,RT-2的正确率是对照组(RT-1/VC-1)的三倍。而在泛化性上,没见 过的物体,没见过的背景,没见过的环境等方面,RT-2相比对照组有一倍的提升。
• 亮点:包含chain of thought的第一次涌现。直接 生成较为具体的运动人运动指令。既能够从互联网规 模数据中学习(RT-1做不到),又能够输出机器人所 需的具体的动作指令。(SayCan、PaLM-E做不到)。 相较于SayCan与RT-1的分拆执行的双层模型架构, RT-2在训练模型时候就学习视觉、语言、机器人行为, 直接产生动作输出。
• 不足:场景仍然局限,主要为桌面任务。虽然RT-2 对于物体和位置的认知拥有了互联网级别的数据训练, 可以去拓展新的任务,但是具体动作微调较为依赖 RT-1的数据集,而此类数据仍然较为昂贵。本质上大 模型主要还是体现在VLM相关方面,也就是在语言和 视觉概念,在物理控制层面没有办法获得更强的能力。 后期改善将依赖于视频学习的方法。最后,目前运行 VLA模型的成本仍然太高,后续希望能够有更多新的 底层架构VLM模型出炉。(目前论文主要是PaLM-E 和PaLI-X)
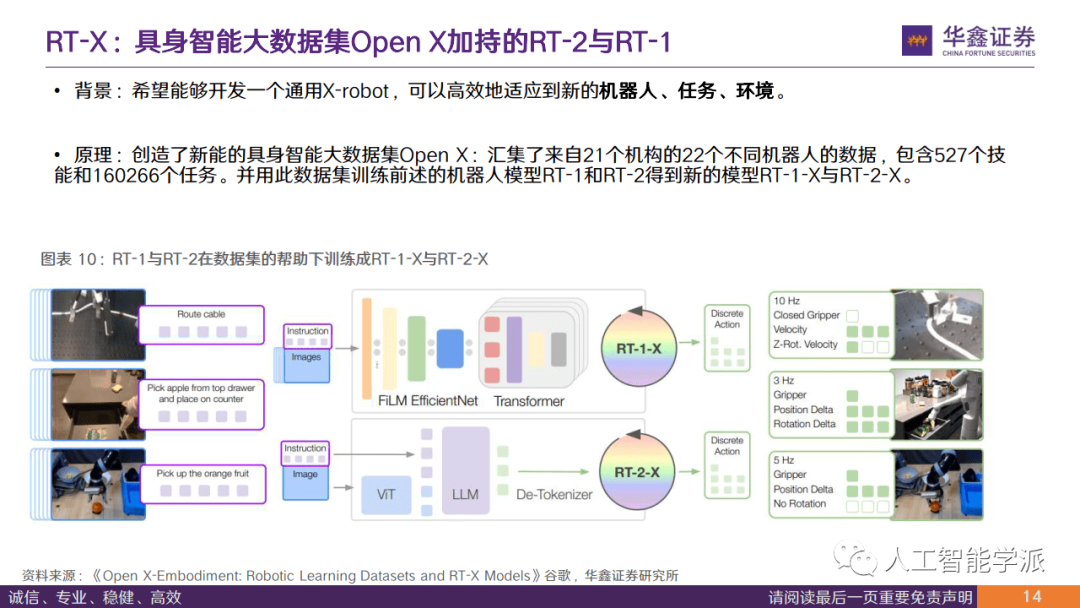
RT-X:具身智能大数据集Open X加持的RT-2与RT-1
• 背景:希望能够开发一个通用X-robot,可以高效地适应到新的机器人、任务、环境。
• 原理:创造了新能的具身智能大数据集Open X:汇集了来自21个机构的22个不同机器人的数据,包含527个技 能和160266个任务。并用此数据集训练前述的机器人模型RT-1和RT-2得到新的模型RT-1-X与RT-2-X。
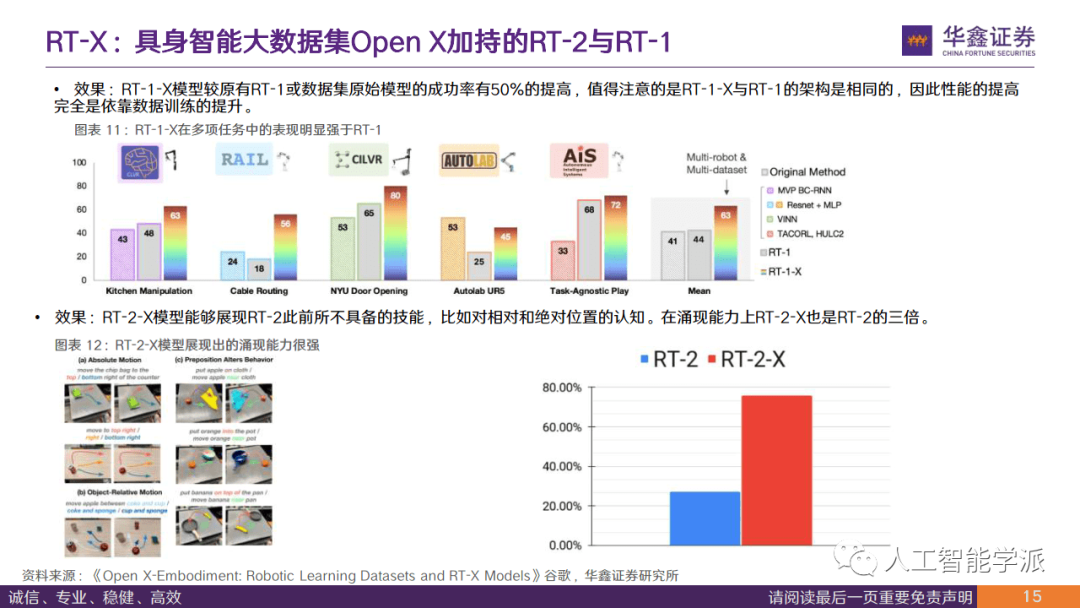
• 效果:RT-1-X模型较原有RT-1或数据集原始模型的成功率有50%的提高,值得注意的是RT-1-X与RT-1的架构是相同的,因此性能的提高 完全是依靠数据训练的提升。 RT-2-X模型能够展现RT-2此前所不具备的技能,比如对相对和绝对位置的认知。在涌现能力上RT-2-X也是RT-2的三倍。