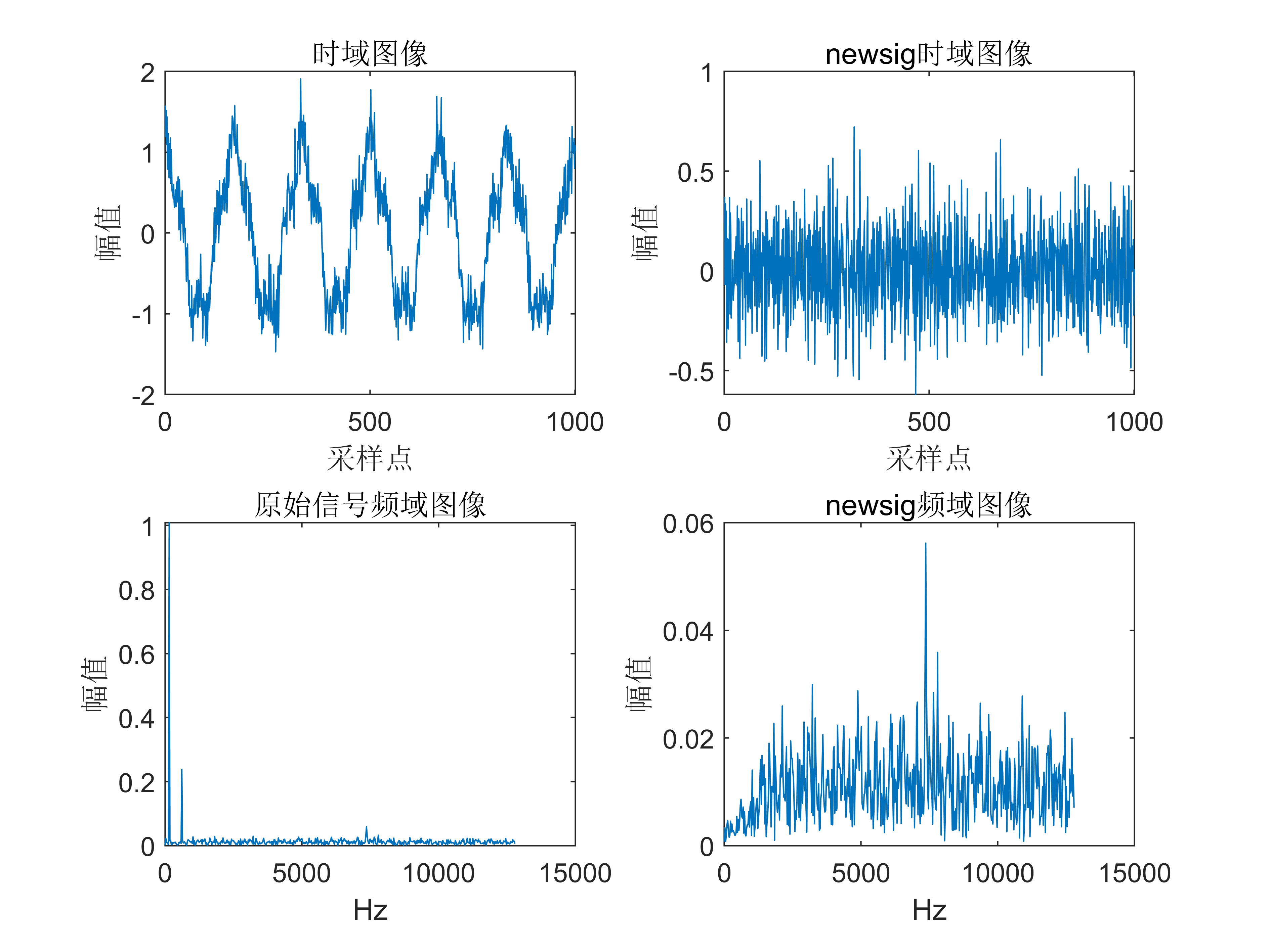
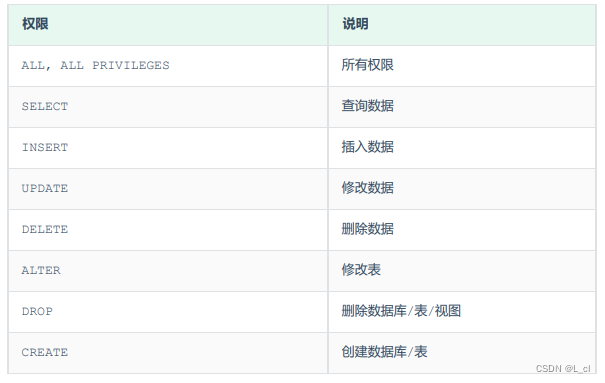
在HotSpot 虚拟机里,对象在堆内存中的存储布局可以划分为三个部分:对象头( Header )、实例数据(Instance Data )和对齐填充( Padding )。
对象头
Mark Word(标记字段)
包含一些用于垃圾回收和同步的标志位,例如对象是否被锁定、对象的哈希码、分代收集信息(新老代)等。
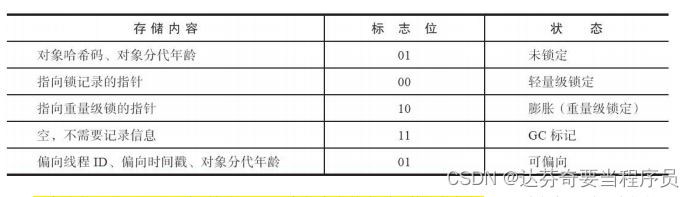
例如在32位的HotSpot虚拟机中,如对象未被同步锁锁定的状态下,Mark Word的32个比特存储空间中的25个比特用于存储对象哈希码,4个比特用于存储对象分代年龄,2个比特用于存储锁标志位,1个比特固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如表所示。
类型指针(Class Pointer)
指向对象的类元数据,用于确定对象的类型信息。这个指针帮助 JVM 确定对象是哪个类的实例。
数组长度(Array Length)
仅对数组对象有效,用于存储数组的长度。因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小。
实例数据(Instance Data)
是对象真正存储的有效信息,对象的字段值存储在这部分。字段的数量和类型取决于对象所属的类。实际数据可以包含以下内容:
-
对象引用: 如果一个字段是对象引用,实际数据部分会存储指向另一个对象的引用。
-
基本数据类型: 如果一个字段是基本数据类型(如 int、float、double 等),实际数据部分会存储相应的数值。
对齐填充(Padding)
由于 JVM 对象的内存布局要求是按照字节对齐的,因此可能存在一些填充数据以保证对象的大小是某个特定字节数的整数倍。


![pat实现基于邻接表表示的深度优先遍历[含非递归写法]](https://img-blog.csdnimg.cn/004ff64480ac40109da2d759e8ad8e5d.png)