模型剪枝是一种常见的模型压缩技术,它可以通过去除模型中不必要的参数和结构来减小模型的大小和计算量,从而提高模型的效率和速度。在 PyTorch 中,我们可以使用一些库和工具来实现模型剪枝。
pytorch实现剪枝的思路是生成一个掩码,然后同时保存原参数、mask、新参数,如下图:
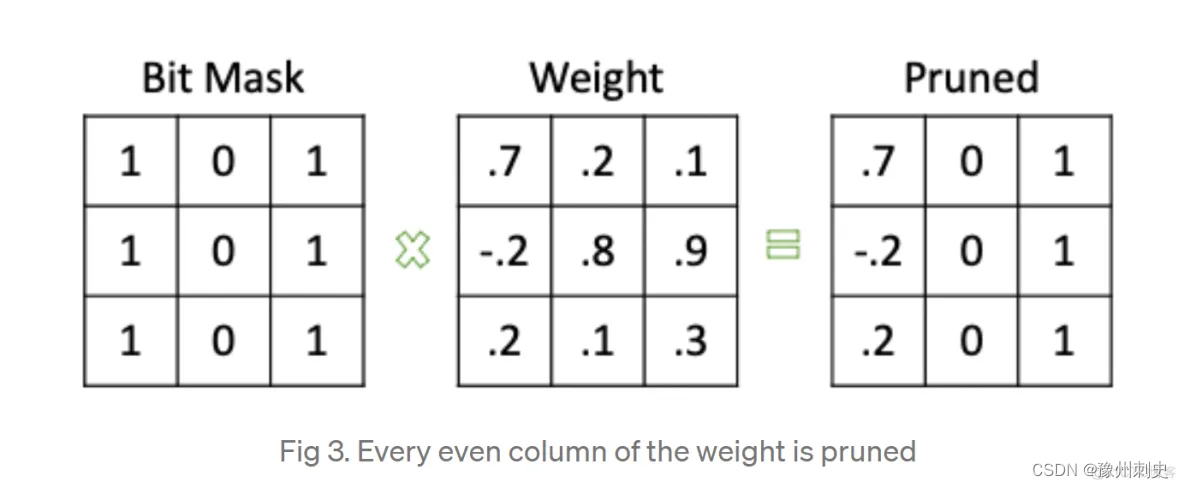
Pytorch实现模型剪枝的基本步骤
-
加载模型:我们首先需要加载一个已经训练好的模型,可以使用 PyTorch 提供的模型库或者自己训练的模型。
-
定义剪枝方法:我们需要定义一种剪枝方法,来决定哪些参数和结构需要被剪枝。
-
执行剪枝操作:我们需要执行剪枝操作,将不必要的参数和结构从模型中去除。
-
保存剪枝后的模型:我们需要将剪枝后的模型保存下来,以便后续使用。
pytorch 剪枝分为 局部剪枝、全局剪枝、自定义剪枝;
局部剪枝
局部剪枝是指在什么网络的单个层或局部范围内进行剪枝。
Pytorch中与剪枝有关的接口封装在torch.nn.utils.prune中。下面开始演示三种剪枝在LeNet网络中的应用效果,首先给出LeNet网络结构。
加载模型
import torch
from torch import nnclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸self.conv1 = nn.Conv2d(1, 6, 3)self.conv2 = nn.Conv2d(6, 16, 3)self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))x = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, int(x.nelement() / x.shape[0]))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
model = LeNet().to(device=device)
局部剪枝实验,假定对模型的第一个卷积层中的权重进行剪枝
# 打印输出剪枝前的参数
module = model.conv1
print(list(module.named_parameters()))
print(list(module.buffers()))
print(module.weight)
运行结果
[('weight', Parameter containing:
tensor([[[[ 0.1158, -0.0091, -0.2742],[-0.1132, 0.1059, -0.0381],[ 0.0430, -0.1634, -0.1345]]],...[[[-0.0226, 0.2091, -0.1479],[ 0.2302, -0.0988, 0.2117],[-0.2000, -0.2531, 0.2770]]]], device='cuda:0', requires_grad=True)), ('bias', Parameter containing:
tensor([ 0.2658, 0.2096, -0.2639, -0.3063, -0.1453, 0.1201], device='cuda:0',requires_grad=True))]
[]
Parameter containing:
tensor([[[[ 0.1158, -0.0091, -0.2742],[-0.1132, 0.1059, -0.0381],[ 0.0430, -0.1634, -0.1345]]],...[[[-0.0226, 0.2091, -0.1479],[ 0.2302, -0.0988, 0.2117],[-0.2000, -0.2531, 0.2770]]]], device='cuda:0', requires_grad=True)
定义剪枝+执行剪枝
# 修剪是从 模块 中 删除 参数(如 weight),并用 weight_orig 保存该参数
# random_unstructured 是一种裁剪技术,随机非结构化裁剪
# 第一个参数:modeul,代表要进行剪枝的特定模型,之前我们已经制定了module=module.conv1,说明这里要对第一个卷积层执行剪枝
# 第二个参数:name,指定要对选中模块中的那些参数执行剪枝,这里设定为name='weight',意味着对连接网络的weight剪枝,而不死bias剪枝
# 第三个参数:amount,指定要对模型中的多大比例的参数执行剪枝,amount是一个介于0.0~1.0的float数值,或者一个正整数指定裁剪多少条连接边。
prune.random_unstructured(module, name="weight", amount=0.3) # weight bias
print(list(module.named_parameters()))
# 通过修剪技术会创建一个mask命名为 weight_mask 的模块缓冲区
print(list(module.named_buffers()))# 经过裁剪操作后的模型,原始的参数存放在了weight-orig中,
# 对应的剪枝矩阵存放在weight-mask中,而将weight-mask视作掩码张量
# 再和weight-orig相乘的结果就存放在了weight中
print(module.weight)
print(module.bias)
运行结果
[('bias', Parameter containing:
tensor([ 0.1303, 0.1208, -0.0989, -0.0611, -0.1103, -0.2433], device='cuda:0',requires_grad=True)), ('weight_orig', Parameter containing:
tensor([[[[-1.1443e-01, 3.2276e-01, -2.4664e-02],[ 4.6659e-02, 1.8311e-01, 6.6681e-02],[-2.5493e-01, -1.1471e-01, 2.8336e-01]]],...[[[ 1.4041e-01, 2.0963e-02, 2.2884e-01],[ 3.5870e-02, 7.5861e-02, 8.4728e-02],[ 4.1965e-02, -1.2838e-01, 8.8462e-02]]]], device='cuda:0',requires_grad=True))]
[('weight_mask', tensor([[[[1., 0., 0.],[1., 0., 0.],[0., 0., 0.]]],...[[[1., 0., 0.],[1., 0., 1.],[0., 1., 0.]]]], device='cuda:0'))]
tensor([[[[-1.1443e-01, 0.0000e+00, -0.0000e+00],[ 4.6659e-02, 0.0000e+00, 0.0000e+00],[-0.0000e+00, -0.0000e+00, 0.0000e+00]]],...[[[ 1.4041e-01, 0.0000e+00, 0.0000e+00],[ 3.5870e-02, 0.0000e+00, 8.4728e-02],[ 0.0000e+00, -1.2838e-01, 0.0000e+00]]]], device='cuda:0',grad_fn=<MulBackward0>)
Parameter containing:
tensor([ 0.1303, 0.1208, -0.0989, -0.0611, -0.1103, -0.2433], device='cuda:0',requires_grad=True)
保存剪枝后的模型
# 保存剪枝后的模型
torch.save(model.state_dict(), 'pruned_model.pth')
模型经历剪枝以后,原始的权重矩阵weight参数不见了,变成了weight_orig。并且剪枝前打印为空的列表module.name_buffers(),此时拥有了一个weight_mask参数。经过剪枝操作后的模型,原始的参数存放在了weight_orig中,对应的剪枝矩阵存在weight_mask中,而将weight_mask视作掩码张量,再和weight_orig相乘的结果就存在了weight中。
Q1:打印经过剪枝处理的 weight 参数。这个 weight 实际上是原始的 weight_orig 和 weight_mask 的元素乘积,其中被剪枝的权重会被设置为0。这个weight不是剪枝了嘛?为什么还能打印出来?
答:在Pytorch的剪枝过程中,当我们说剪枝一个权重的参数时,并不是真的从网络中移除这些参数,而是通过一个掩码来“禁用”它们。这是通过将某些权重的值设为0来实现的,从而在网络的前向传播中这些权重不会有任何作用,这种方法允许我们在保留原始权重信息的同时,实现剪枝的效果。
在 PyTorch 的剪枝过程中,当我们说“剪枝”一个权重参数时,并不是真的从网络中移除这些权重,而是通过应用一个掩码来“禁用”它们,为什么禁用就可以达到模型压缩的目的?为什么剪枝完,执行print(list(module.named_parameters())),没有显示weight属性,但是执行print(module.weight)时,weight依然存在?
- 为什么“禁用”权重可以达到模型压缩的目的?
虽然剪枝后的权重仍然占据内存空间,但在实际计算中,值为0的权重不会对前向传播产生任何影响。这意味着在计算层面可以忽略这些权重,从而减少计算量。 - 为什么 print(list(module.named_parameters())) 没有显示 weight 属性,但执行 print(module.weight) 时 weight 依然存在?
-
修改参数列表:当执行剪枝操作时,PyTorch 会修改模块的参数列表。原始的 weight 参数被重命名为 weight_orig,并且创建了一个新的名为 weight_mask 的缓冲区。原始的 weight 参数(现在是 weight_orig)和 weight_mask 通过一个钩子(hook)相结合,生成了新的 weight 属性。
-
动态权重生成:在调用 module.weight 时,由于剪枝过程中添加的前向钩子,weight 参数是动态生成的,它是 weight_orig 和 weight_mask 的元素乘积。因此,尽管 weight 在 named_parameters 列表中看起来已经不存在,但它实际上是在运行时动态生成的。
-
参数与属性的区别:在 PyTorch 中,模块的参数(可通过 named_parameters 访问)和模块的属性(如直接通过 module.weight 访问)是不同的。module.weight 被视为一个可访问的属性,但由于剪枝过程的内部处理,它可能不再直接列在模块的参数列表中。
-
既然原始的 weight 参数被重命名为 weight_orig,那参数是不是并没有发生变化,又怎么能达到剪枝的效果呢?
原始的 weight 参数在剪枝过程中被重命名为 weight_orig,并且保持不变。剪枝的效果是通过以下几个关键步骤实现的:
- 掩码(Mask)创建:
- 在剪枝过程中,PyTorch 创建了一个掩码(weight_mask),它是一个与 weight 形状相同的二进制张量(由0和1组成)。
- 在这个掩码中,1表示相应的权重保持不变,而0表示相应的权重被“剪枝”(实际上是被禁用)。
- 动态权重更新:
- 尽管 weight_orig 保持不变,但是模块的 weight 属性被动态更新为 weight_orig 和 weight_mask 的元素乘积。
- 这意味着,在模型的前向传播过程中,实际使用的 weight 是被掩码修改过的。在这个新的 weight 中,被剪枝的权重(在 weight_mask 中对应0的位置)的值为0,而其他位置的权重保持原始值。
- 前向传播的影响:
- 当模型进行前向传播时,使用的是被掩码修改过的 weight。因此,尽管原始的 weight 参数(现在是 weight_orig)没有变化,模型实际上使用的权重已经被剪枝修改了。
- 剪枝过程实际上通过使某些权重值为0,从而在模型的计算过程中禁用了这些权重。
- 模型复杂度的降低:
- 通过这种方式,模型的复杂度在实际运行时降低了,因为一部分权重不再对输出产生影响。
- 这可以提高计算效率,并且在某些情况下,可以通过专门的硬件和软件优化来利用权重的这种稀疏性。
综上所述,虽然原始的 weight 参数作为 weight_orig 保留下来,但是实际上模型使用的是被掩码修改过的权重,这就是剪枝效果的实现方式。这种方法的一个优势是可以在不永久性地移除权重的情况下,测试和评估剪枝的影响,甚至可以在必要时撤销剪枝操作。