文章目录
- 数据准备阶段
- KNN预测的过程
- 1.计算新样本与已知样本点的距离
- 2.按照举例排序
- 3.确定k值
- 4.距离最近的k个点投票
- scikit-learn中的KNN算法
数据准备阶段
import matplotlib.pyplot as plt
import numpy as np
# 样本特征
data_X = [[0.5, 2],[1.8, 3],[3.9, 1],[4.7, 4],[6.2, 6],[7.5, 5],[8.3, 3.5],[9.1, 7],[9.8, 4.5]
]# 样本标记
data_y = [0, 0, 0, 1, 1, 1, 1, 1, 1]
X_train = np.array(data_X)
y_train = np.array(data_y)
X_train
array([[0.5, 2. ],[1.8, 3. ],[3.9, 1. ],[4.7, 4. ],[6.2, 6. ],[7.5, 5. ],[8.3, 3.5],[9.1, 7. ],[9.8, 4.5]])
y_train
array([0, 0, 0, 1, 1, 1, 1, 1, 1])
选出样本标记为0的样本特征
y_train == 0
array([ True, True, True, False, False, False, False, False, False])
X_train[y_train==0]
array([[0.5, 2. ],[1.8, 3. ],[3.9, 1. ]])
X_train[y_train==0, 0]
array([0.5, 1.8, 3.9])
X_train[y_train==0, 1]
array([2., 3., 1.])
X_train[y_train==1, 0].shape
(6,)
X_train[y_train==1, 1].shape
(6,)
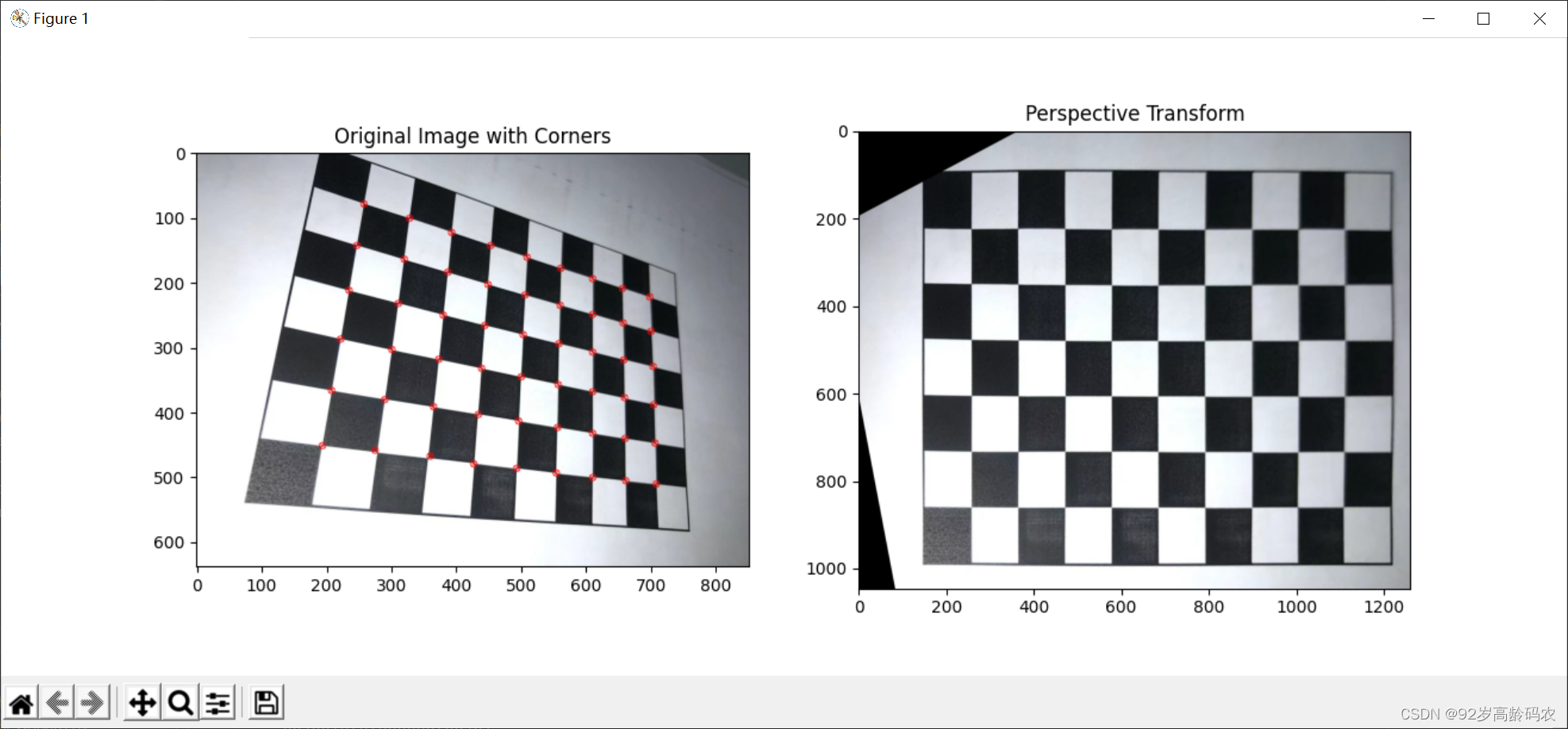
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='red', marker='x')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color='black', marker='o')
plt.show()
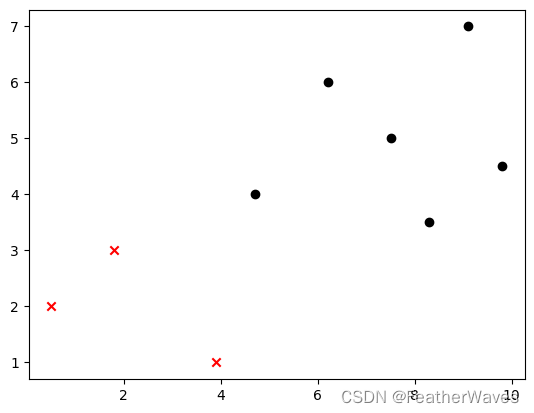
增加新的样本点
data_new = np.array([4, 5])
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='red', marker='x')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1],color='black', marker='o')
plt.scatter(data_new[0], data_new[1], color='b', marker='^')
plt.show()
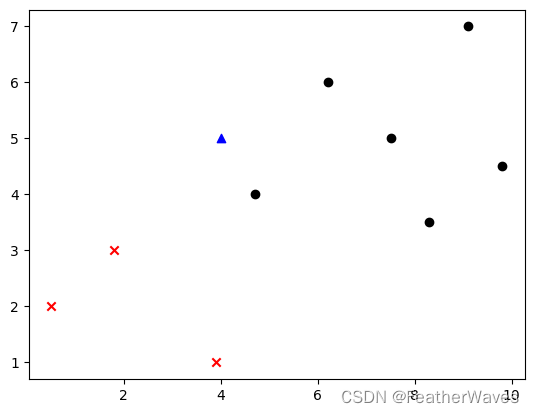
KNN预测的过程
1.计算新样本与已知样本点的距离
for data in X_train:print(np.sqrt(np.sum((data - data_new) ** 2)))
4.6097722286464435 2.973213749463701 4.001249804748512 1.2206555615733703 2.4166091947189146 3.5 4.5541190146942805 5.478138369920935 5.821511831131154
distances = [np.sqrt(np.sum((data - data_new) ** 2)) for data in X_train]
distances
[4.6097722286464435,2.973213749463701,4.001249804748512,1.2206555615733703,2.4166091947189146,3.5,4.5541190146942805,5.478138369920935,5.821511831131154]
2.按照举例排序
np.sort(distances)
array([1.22065556, 2.41660919, 2.97321375, 3.5 , 4.0012498 ,4.55411901, 4.60977223, 5.47813837, 5.82151183])
sort_index = np.argsort(distances)
sort_index
array([3, 4, 1, 5, 2, 6, 0, 7, 8], dtype=int64)
3.确定k值
k = 5
4.距离最近的k个点投票
first_k = [y_train[i] for i in sort_index[:k]]
first_k
[1, 1, 0, 1, 0]
from collections import Counter
Counter(first_k)
Counter({1: 3, 0: 2})
Counter(first_k).most_common()
[(1, 3), (0, 2)]
Counter(first_k).most_common(1)
[(1, 3)]
predict_y = Counter(first_k).most_common(1)[0][0]
predict_y
1
得到结果为1,KNN判断新加入的点data_y的标记应该为1,从图中也可以看到,新加入的点更靠近标记为1的点群。
scikit-learn中的KNN算法
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=5)
kNN_classifier.fit(X_train, y_train)
data_new.reshape(1, -1)
array([[4, 5]])
predict_y = kNN_classifier.predict(data_new.reshape(1, -1))
predict_y
array([1])
与手写KNN得到的结果相同,皆判断为1。