算法:
这道题适合用迭代法,层序遍历:按层遍历,每次把每层最左边的值保存、更新到result里面。
看看Java怎么实现层序遍历的(用队列):
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {//定义全局变量result// public List<List<Integer>> result = new ArrayList<List<Integer>>();public List<List<Integer>> result = new ArrayList<List<Integer>>();public List<List<Integer>> levelOrder(TreeNode root) {chek(root);return result;}public void chek(TreeNode node) {if (node == null) return;Queue<TreeNode> que = new LinkedList<TreeNode>();//在 Java 中,当调用类的构造函数时,使用括号可以传递参数或指定初始化的大小。如果没有传递参数,则会使用默认的构造函数。//虽然在这种情况下使用括号是可选的,但建议使用括号,以提高代码的可读性和一致性。此外,如果将来需要在构造函数中传递参数或指定初始化大小,添加括号将更加方便。//把node加入queque.offer(node);while(!que.isEmpty()){//itemlist用来存储每一层的节点List<Integer> itemlist = new ArrayList<Integer>();//len表示每一层的节点数量int len = que.size();while (len>0){TreeNode tempt = que.poll();itemlist.add(tempt.val);if (tempt.left != null) que.offer(tempt.left);if (tempt.right != null) que.offer(tempt.right);len--;}result.add(itemlist);}}
}注意:
Java里面有全局变量:
即所有函数都可以用的变量,比如result
写函数还有定义变量时,要拼写正确并区分大小写:
比如isEmpty,ArrayList等
Java定义变量:
<数据类型> <变量名> = <初始值>;
- `
<数据类型>`:表示变量的数据类型,例如`int`、`double`、`String`等。 - `
<变量名>`:表示变量的名称,由字母、数字和下划线组成,不能以数字开头,且不能使用Java的关键字作为变量名。 - `
<初始值>`:表示变量的初始值,可以是一个具体的数值、表达式或者其他变量的值。如果不需要初始值,可以将其省略。
比如:List<Integer> itemList = new ArrayList<Integer>();
其中`List<Integer>`表示列表的数据类型(整数类型的列表),`itemList`是变量的名称,`new ArrayList<Integer>()`是初始值,创建了一个`ArrayList`类型的对象,并将其赋值给`itemList`变量。
ArrayList和LinkedList的区别:
ArrayList:
- 内部实现:`
ArrayList`是基于数组的实现。它使用动态数组来存储元素,并可以根据需要自动调整容量。当元素数量超过当前容量时,`ArrayList`会自动增加容量,以便能够容纳更多的元素。 - 随机访问:由于`
ArrayList`基于数组,因此支持快速的随机访问。可以通过索引直接访问元素,时间复杂度为O(1)。 - 插入和删除:在中间位置插入或删除元素时,需要将后续元素进行移动,因此时间复杂度为O(n)。但在末尾进行插入和删除操作时,时间复杂度为O(1)。
- 内存占用:由于`
ArrayList`使用连续的内存块来存储元素,因此在存储大量元素时,可能会导致内存碎片问题。
LinkedList:
- 内部实现:`
LinkedList`是基于链表的实现。它使用双向链表来存储元素,每个节点包含对前一个节点和后一个节点的引用。 - 随机访问:由于`
LinkedList`是基于链表的,因此不支持快速的随机访问。要访问特定索引的元素,需要从头节点或尾节点开始遍历链表,时间复杂度为O(n)。 - 插入和删除:在中间位置插入或删除元素时,只需要修改节点的引用,时间复杂度为O(1)。但在末尾进行插入和删除操作时,需要先遍历到末尾节点,时间复杂度为O(n)。
- 内存占用:由于`
LinkedList`使用链表存储元素,每个节点需要额外的内存空间来保存前后节点的引用,因此在存储大量元素时,可能会占用更多的内存。
add和offer的区别:
在 Java 中,`add` 和 `offer` 是用于向队列(Queue)添加元素的方法,它们有一些区别:
-
返回值:`
add` 方法在成功添加元素后会返回 `true`,如果无法添加元素(例如队列已满),则会抛出异常(`IllegalStateException` 或其子类)。而 `offer` 方法在成功添加元素后会返回 `true`,如果无法添加元素(例如队列已满),则会返回 `false`。 -
异常处理:`
add` 方法在无法添加元素时会抛出异常,而 `offer` 方法在无法添加元素时则会返回 `false`,不会抛出异常。这使得在使用 `offer` 方法时,可以通过返回值来判断元素是否成功添加,而无需使用异常处理机制。 -
接口支持:`
add` 方法定义在 `Collection` 接口中,而 `offer` 方法定义在 `Queue` 接口中。由于 `Queue` 是 `Collection` 的子接口,所以所有实现了 `Queue` 接口的类都会包含 `offer` 方法。而 `add` 方法在一些特定的队列实现中可能没有定义。
总的来说,`add` 和 `offer` 方法在添加元素时的行为基本相同,但在处理无法添加元素的情况时有所不同。如果需要处理无法添加元素的情况,可以使用 `offer` 方法并根据返回值进行判断。如果希望抛出异常来处理无法添加元素的情况,可以使用 `add` 方法。
使用层序遍历找树左下角的值:
调试过程:
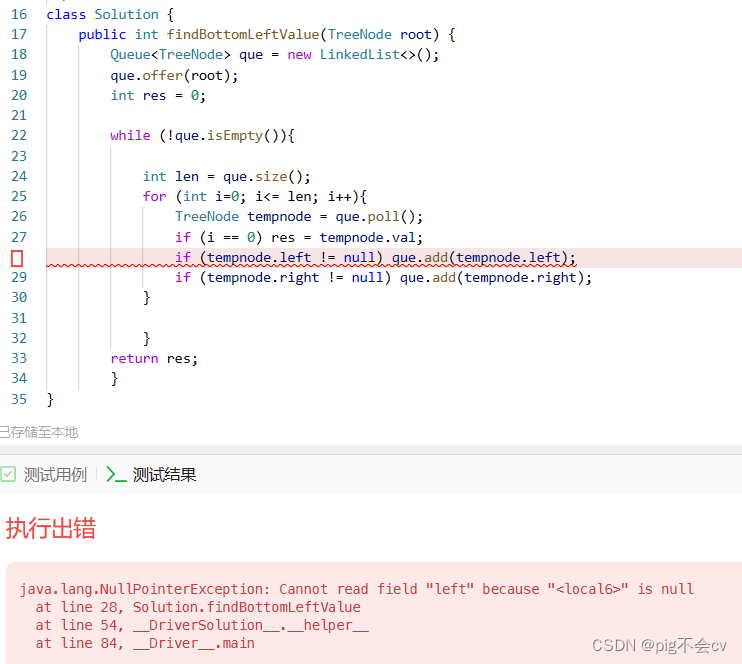
原因:当`i`等于`len`时,表示已经遍历完当前层级的所有节点。此时tempnode就是空节点,没有val。所以要把for循环条件改为i<len
正确代码:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public int findBottomLeftValue(TreeNode root) {Queue<TreeNode> que = new LinkedList<>();que.offer(root);int res = 0;while (!que.isEmpty()){int len = que.size();for (int i=0; i< len; i++){TreeNode tempnode = que.poll();if (i == 0) res = tempnode.val;if (tempnode.left != null) que.add(tempnode.left);if (tempnode.right != null) que.add(tempnode.right);} }return res;}
}
时间空间复杂度
在这段代码中,使用了广度优先搜索(BFS)来遍历二叉树的每一层节点,因此时间复杂度为O(N),其中N是二叉树中的节点数。
空间复杂度方面,使用了一个队列`que`来存储节点,最坏情况下队列的大小可以达到二叉树的最大宽度,因此空间复杂度为O(W),其中W是二叉树的最大宽度。 综上所述,时间复杂度为O(N),空间复杂度为O(W)。

![[C/C++]数据结构 堆的详解](https://img-blog.csdnimg.cn/efd909d783244baa9ae1a031017580fe.jpeg)