作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
除了HashMap,ArrayList和LinkedList应该是使用最频繁的容器,类似的总结如下:
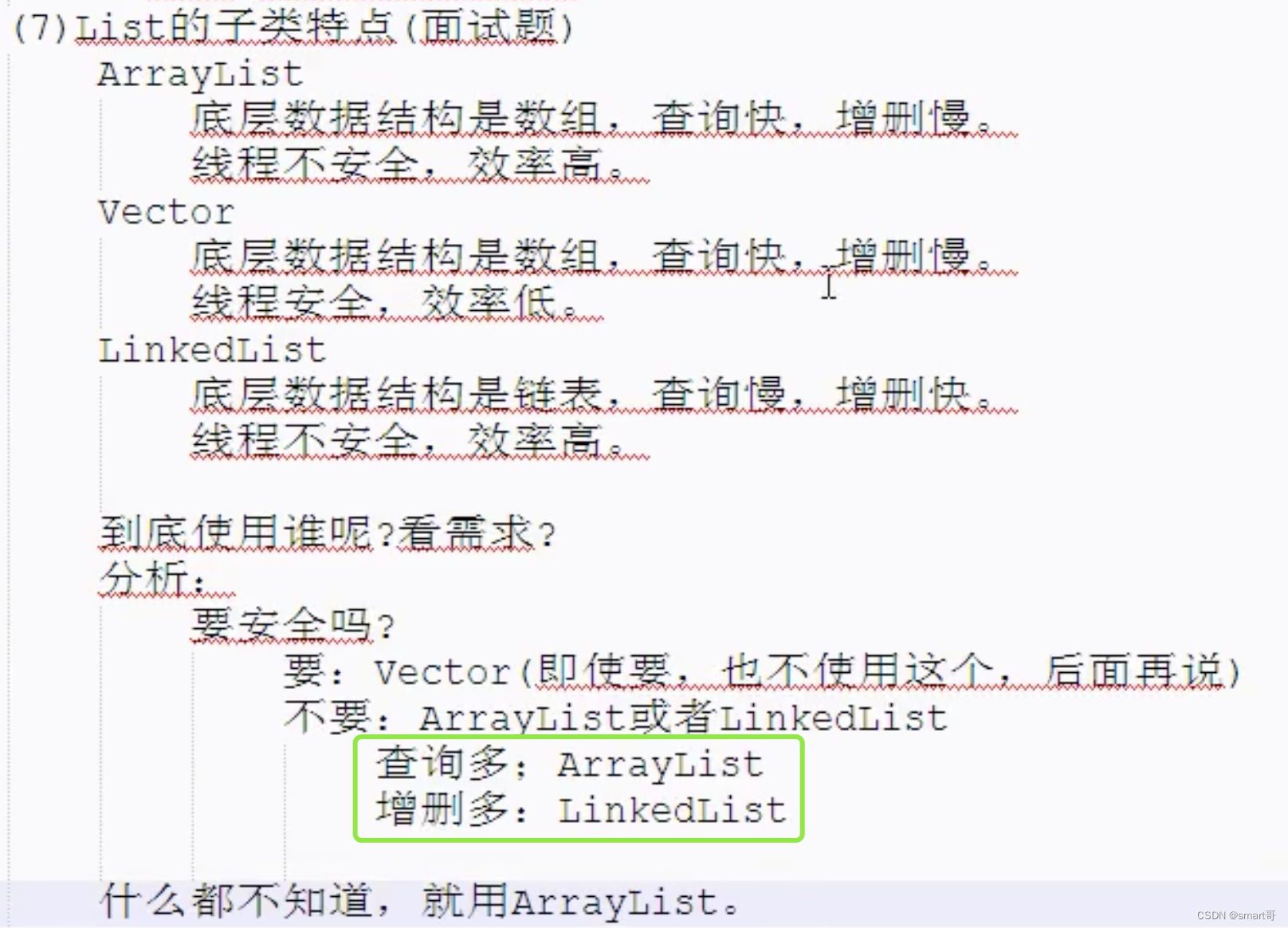
这两句话本身是没错的,但是要看场景。在不了解LinkedList和ArrayList原理的情况下,看到增删操作多就用LinkedList反而会使程序执行效率下降。相对来说,下面那句“什么都不知道,就用ArrayList”反而更适合初学者。
大家之前已经学习过《山寨Stream API》,有没有人感到疑惑,filter()明显属于“增删多”的操作,为什么不用LinkedList?
先卖个关子,后面解释。
要想在合适的场景使用合适的List,必须对它们底层数据结构有所了解。所以接下来我们一起学习数据结构中的两种线性结构:链表、数组。
链表的遍历
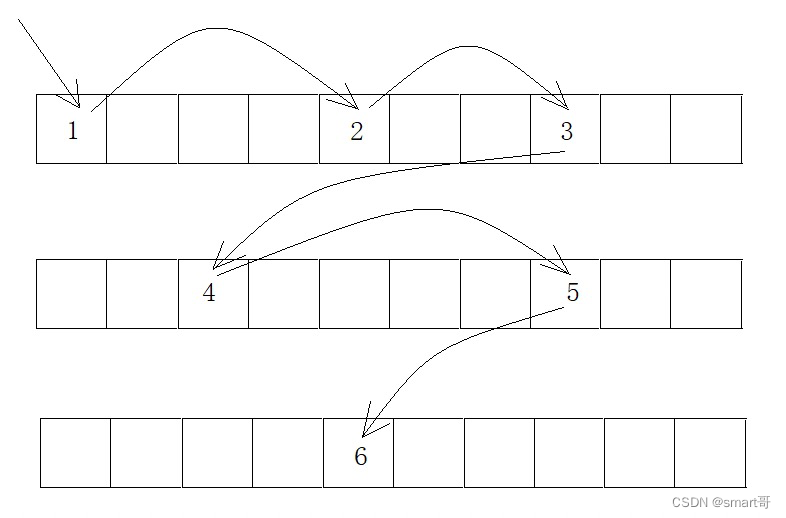
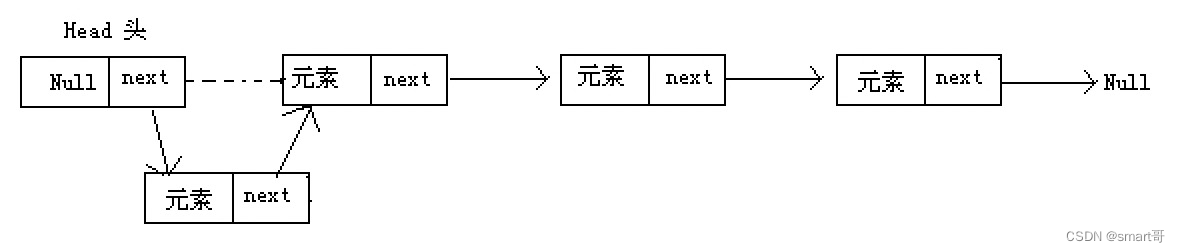
链表的存储空间不是连续的,每个节点会“记住”下一个节点的地址。这样的好处是计算机在为链表结构的容器分配内存空间时可以“见缝插针”,从而更加有效地利用内存。

但相比数组结构来说,由于内存分配是不连续的,上一个节点要找它的下一个节点时,需要根据地址去找。这就导致了链表结构的查询比数组结构要慢。
大家不要看上面的图好像是连续的,实际上可能是这样:
在Java中,LinkedList底层正是链表结构。这里考考大家,链表的遍历对应LinkedList的哪个方法呢?
你以为这叫链表的遍历?
LinkedList<String> list = new LinkedList<>();
for (int i = 0; i < list.size(); i++) {// do something... for example: list.get(i)
}养兔子的大叔:其实上面包含了两层遍历。第一层是外面的for,而list.get(i)本身才是对链表的遍历,get(i)底层会按地址遍历找到第i个元素。
记住这个概念,后面在比较ArrayList和LinkedList的效率时它会出来“捣乱”。
LinkedList#getFirst() (很快)

LinkedList#getLast()(很快)

LinkedList内部会维护头尾节点,所以getFirst()、getLast()都是很快的。
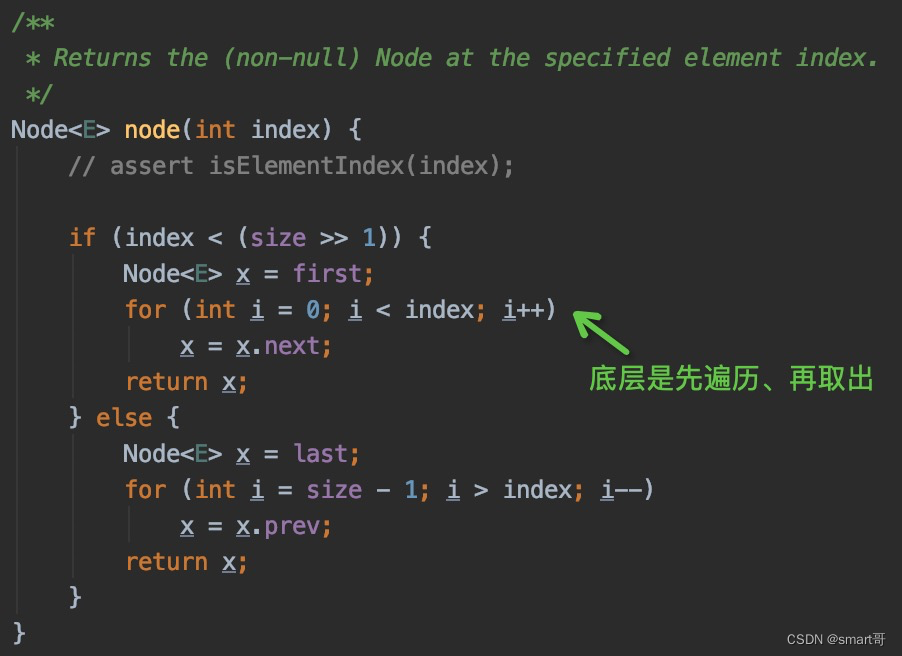
LinkedList#get(index)(较慢,因为要通过node(index)方法遍历到i元素再取出,而链表是不连续的)

链表的插入与删除
链表的插入操作非常方便,只要解开A和B节点的联系,再让它们同时跟C节点重新建立联系即可:
删除同样方便:

但是,大家想一个问题:我想在第i个元素和第i+1个元素之间插入一个新元素。你觉得这个需求包含几个操作?
- 先遍历找到第i个元素(遍历)
- 把第i个元素和第i+1个元素的联系拆开,各自和新元素建立联系(插入)
所以,虽然我们分析问题时都是强调链表结构插入和删除比数组结构快,但理想化的链表节点插入和删除是不存在的,任何基于线性结构的容器,插入和删除的实现必然伴随着遍历。虽然链表对于某个节点的插入和删除确实比数组快,但是遍历相对较吃力,所以实际增删的效率并不能一概而论。
LinkedList#addFirst(e)/addLast(e)(很快)
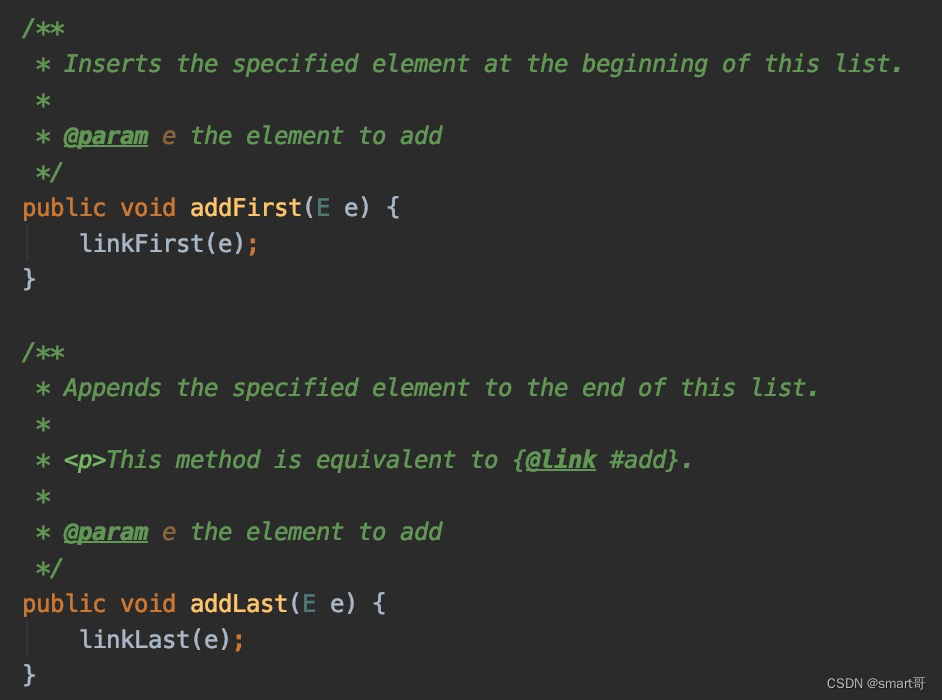

LinkedLis#add(e)(很快,默认从链表尾部插入,此方法与addLast()等效)
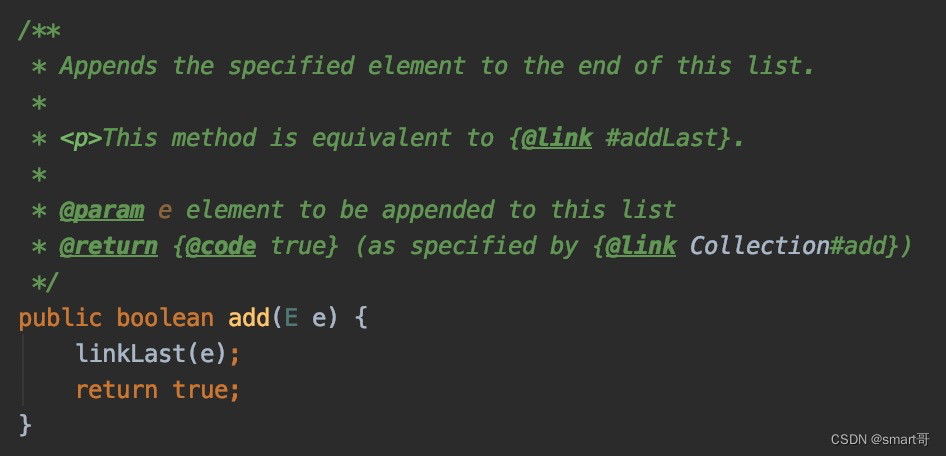
LinkedList#set(i, e)(较慢,先遍历,后替换指定位置的元素为新元素)

LinkedList#add(i, e)(较慢,先遍历,后插入)

LinkedList#removeFirst()/removeLast()(很快)

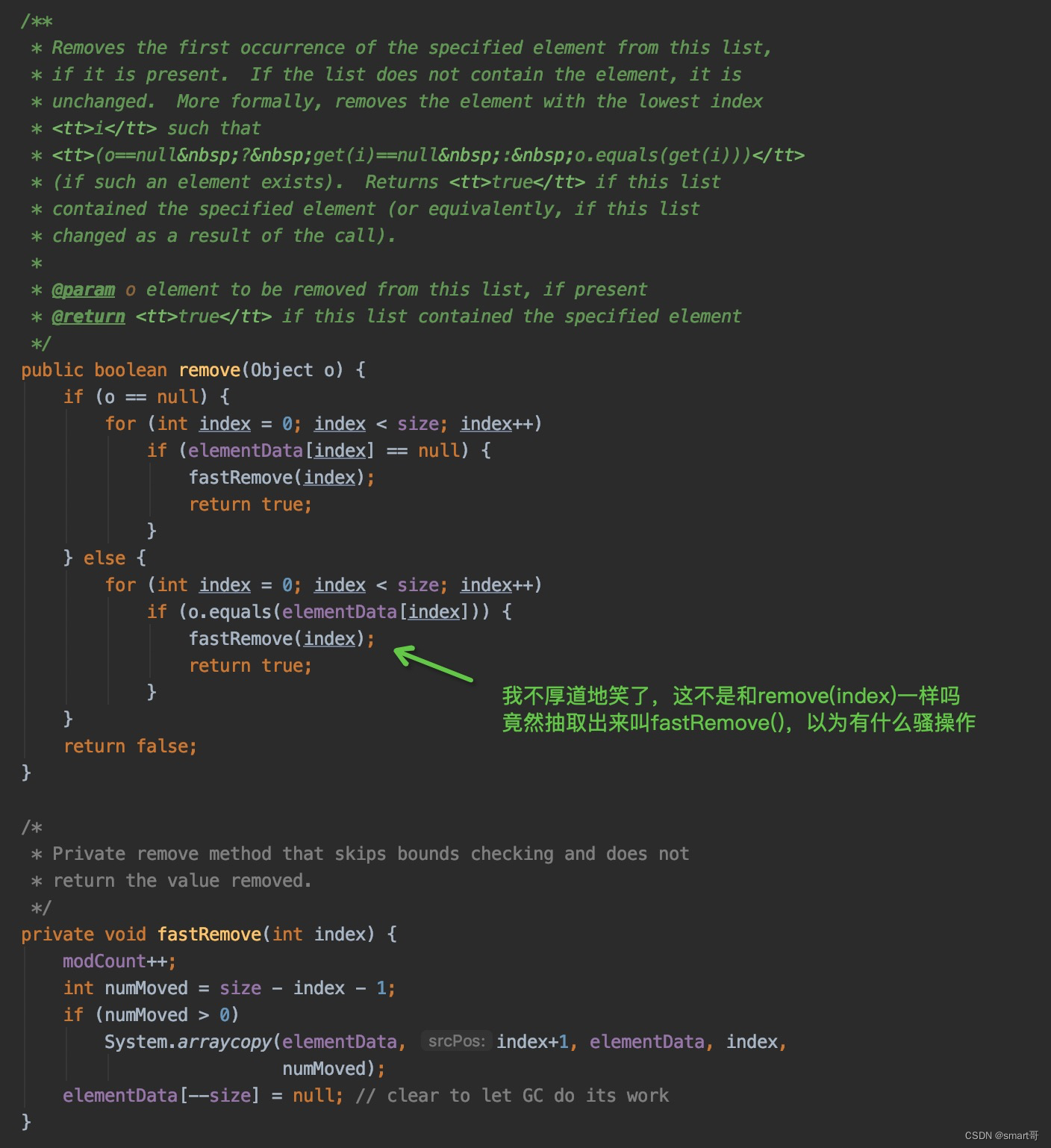
LinkedList#remove()(很快,内部调用removeFirst())
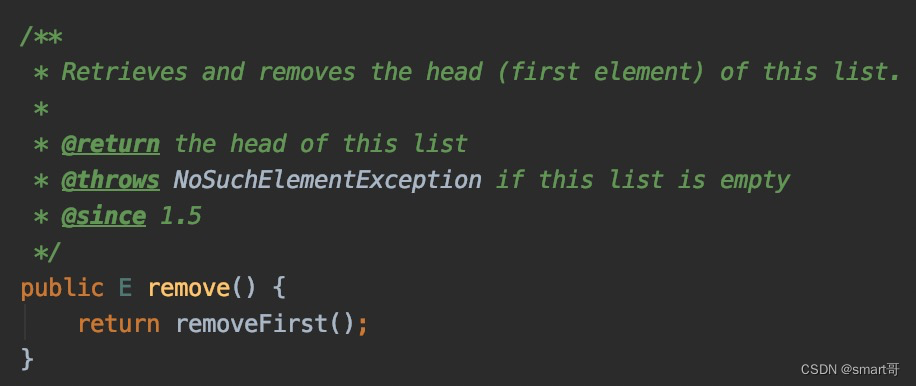
LinkedList#remove(e)/remove(i)(较慢,内部会遍历)
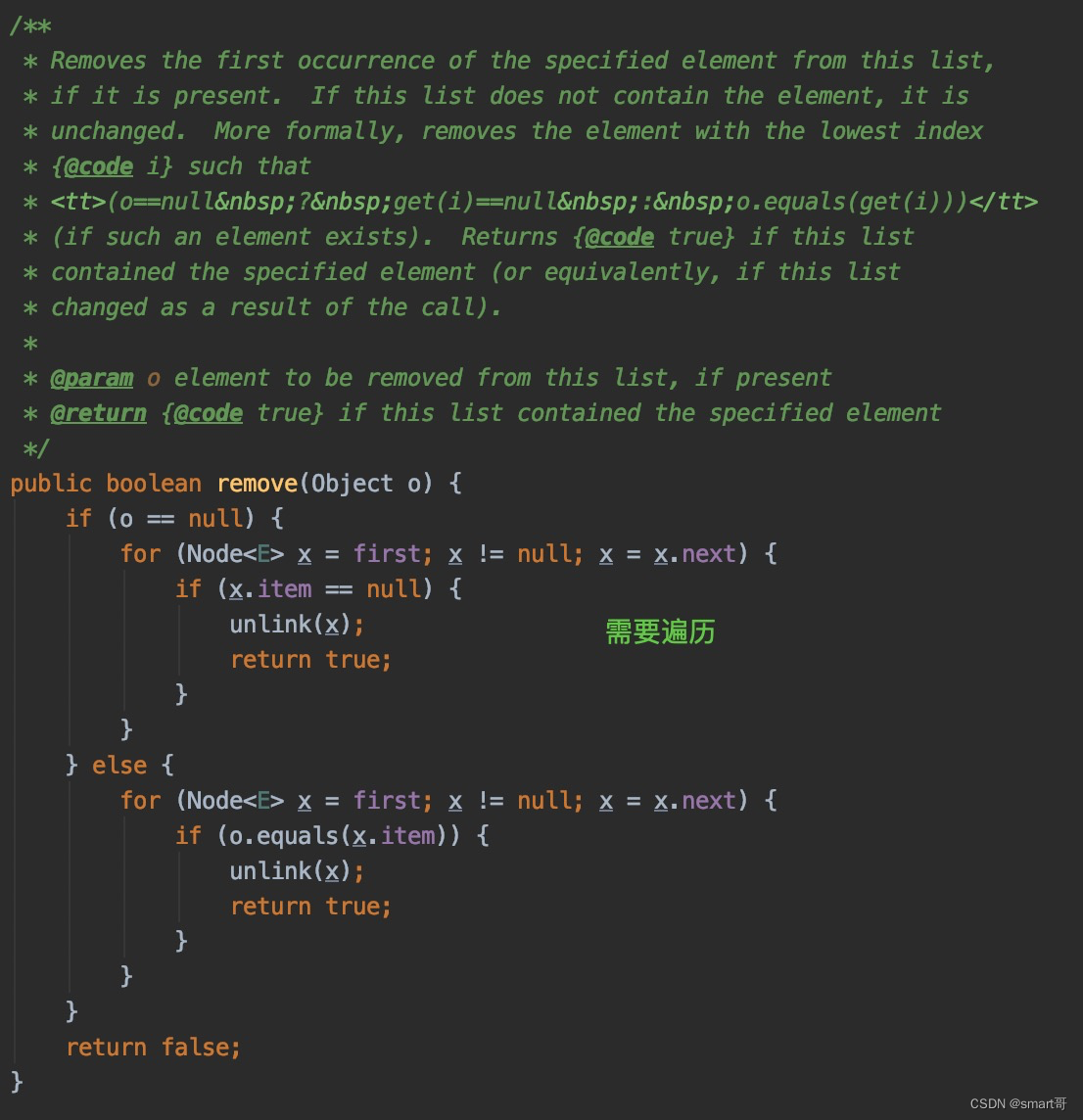

LinkedList小结
- 查询
-
- 尽量使用getFirst()/getLast(),很快,因为内部维护了头尾节点
- 避免使用get(index),内部包含遍历,较慢
- 头尾插入
-
- 尽量使用addFirst(e)/addLast(e)/add(e),都是对头尾节点的操作,很快
- 中间插入/替换
-
- 避免使用set(i, e)和add(i, e),内部需要先遍历再插入/替换
- 删除
-
- 尽量使用removeFirst()/remove()/removeLast(),都是对头尾节点的操作,很快
- 避免使用remove(i)/remove(e),内部包含遍历,较慢
一句话:LinkedList不擅长遍历,但维护了头尾节点,尽量使用带有First/Last的方法,避免使用带索引的方法(带索引意味着需要遍历到该位置)。
数组的遍历
由于数组在结构上要求连续,所以计算机会为它分配连续的一片空间。遍历时不关心具体元素的地址,只要知道起始元素的地址以及目标元素的下标,即可快速找到目标元素。比如,一排房子,我只要知道第一户人家的地址,以及你家在第一户人家从左往右的第几家,那么我找到第一户人家后,往右数第N-1家就找到你家了。所以数组结构的遍历会优于链表结构的遍历,它不需要频繁寻找地址。

ArrayList#get(i):很快
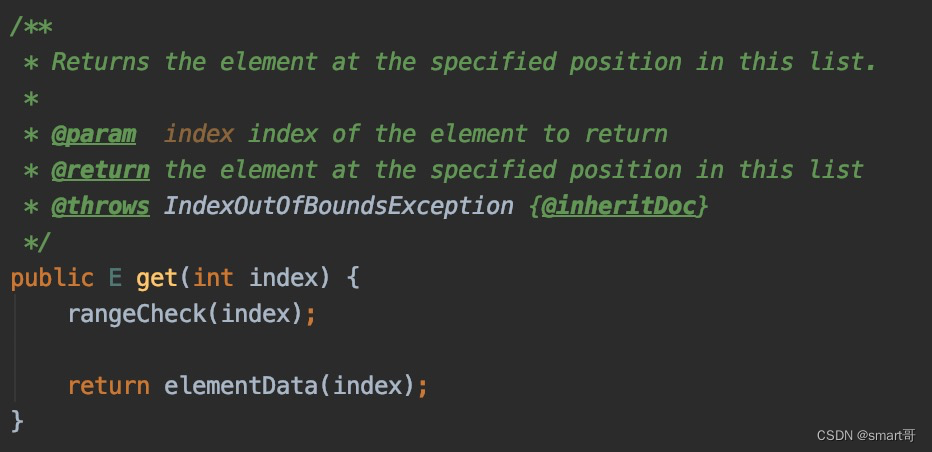
两个细节:
- rangeCheck()与我们最常见的IndexOutOfBoundsException有关
- elementData(index)直接根据数组下标找到元素,由于存储连续,相比LinkedList的遍历要快很多!

数组的插入与删除
要讨论数组的插入和删除,总是离不开数组的拷贝和扩容。
比如我们使用数组时都是这样声明的:
int[] intArr = new int[5];
表示申请长度为5的数组,这意味着数组的长度是固定的。
现在我把数组都填满:
然后让我们考虑两种情况:
- 再插入新元素
- 删除元素
先说插入。在Java中,Array和ArrayList都是数组结构的。Array如果满了,就不能再插入了,否则就会抛“越界异常”。而ArrayList被称为“动态数组”,原因就在于它会自动扩容。
扩容的具体步骤是:
- ArrayList申请新的长度的数组
- 把原数组的元素拷贝到新数组
- 把新元素插入到新数组



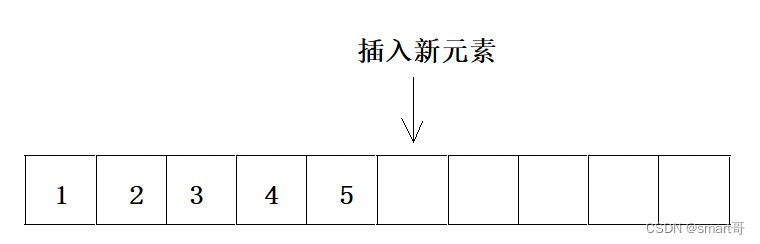
拷贝数组是一件比较耗时的操作,我不知道计算机底层会不会根据实际情况做优化:
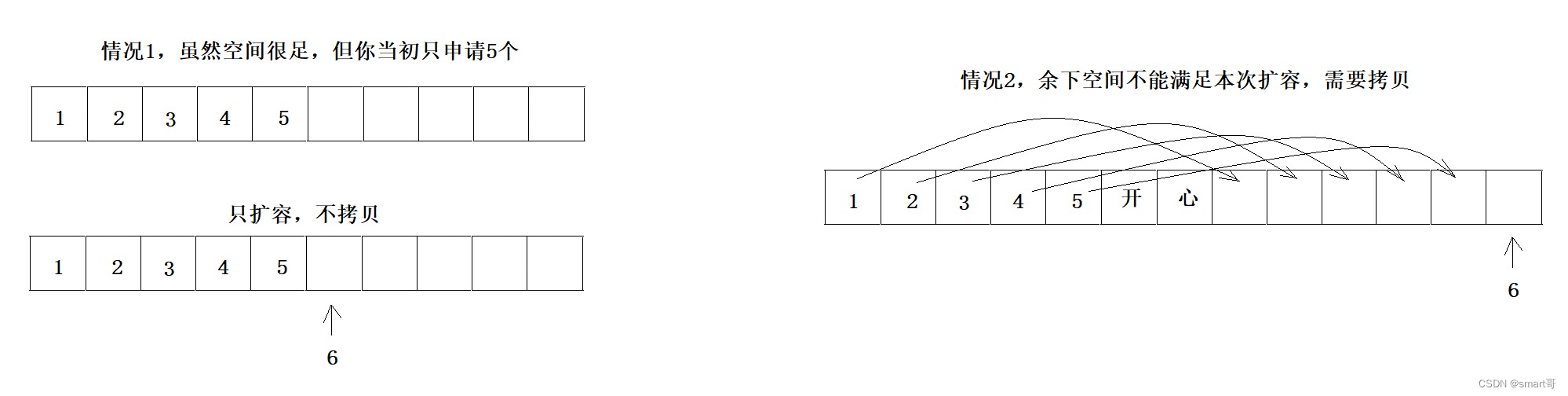
在操作系统层面数组也仅仅是页内保证连续,所以具体有没有以上优化不清楚,仅作为讨论。总之,从ArrayList源码来看,扩容必然伴随元素拷贝,而拷贝是耗时的。大家只需知道这个即可。
而链表其实不存在所谓的长度限制,只需要把新的元素指向原链表的某个(对)元素即可,不涉及拷贝。
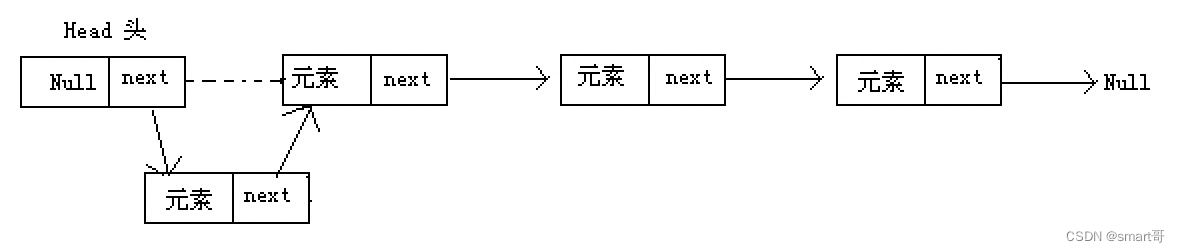


大致介绍数组结构的插入后,我们看看ArrayList相关的插入方法。
- ArrayList#set(index, element):只是替换,不会扩容和拷贝
- ArrayList#add(e):尾部插入,只有当数组满了才扩容
- ArrayList#add(index, element):指定位置插入,不一定扩容,但会触发数组拷贝,尽量避免使用
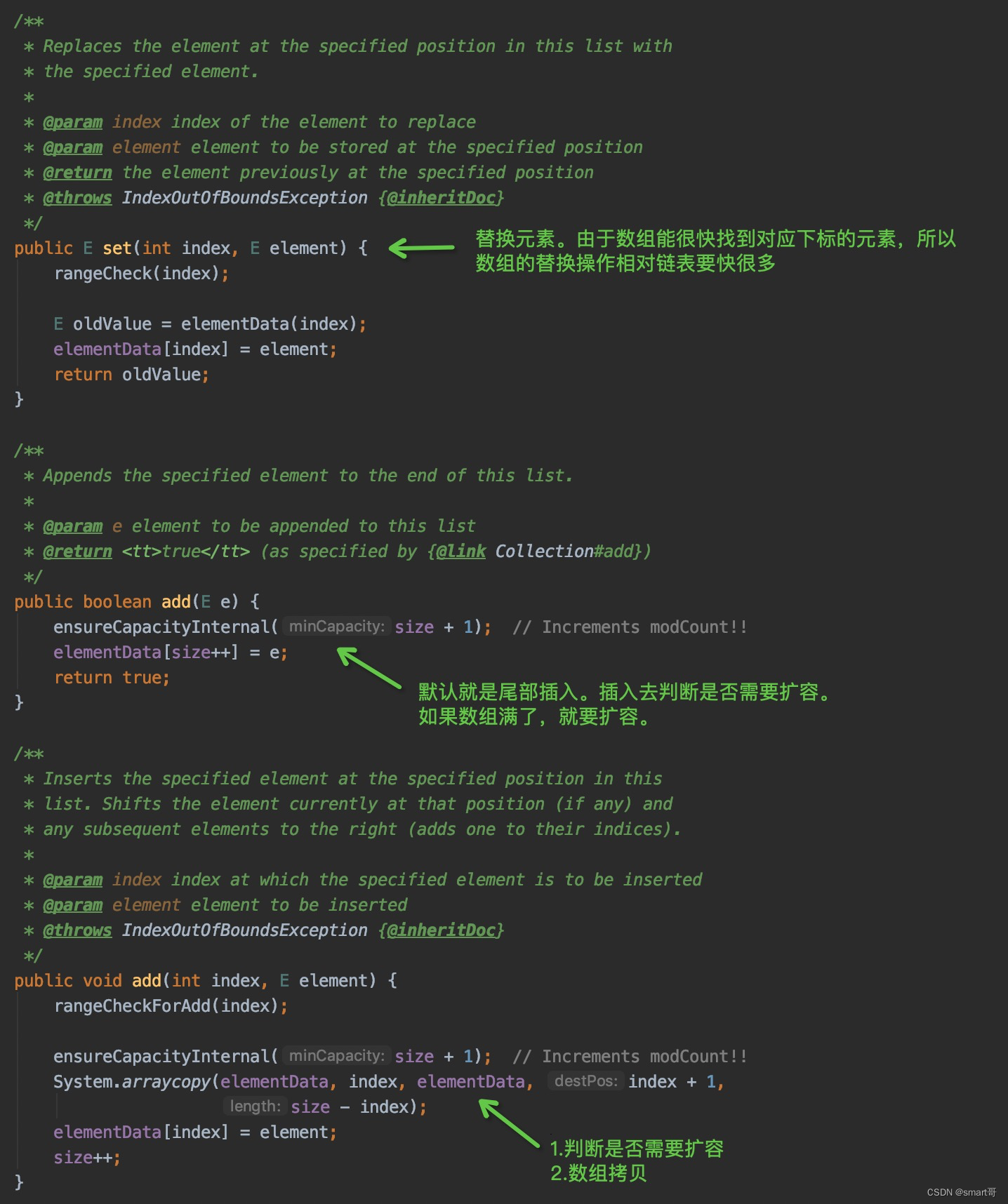
强调几点:
- 数组的元素替换速度比链表的替换快!首先,数组查询比链表快。其次,数组元素直接赋值覆盖完成替换,而链表要先解开地址引用
- add(int index, E element)不一定会触发扩容,但几乎一定会发生拷贝
- 数组的中间插入只会移动部分元素,而头插入会移动所有元素。大家看看上面的System.arracopy(),当我们尾部插入时,index=size,所以length参数就是0,无需移动任何元素
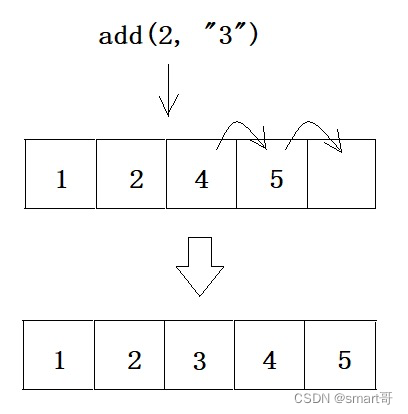
接下来讨论数组的删除。
如果有人告诉你,数组的删除同样可能需要拷贝元素,你会不会很诧异?元素太多存不下,所以要扩容并拷贝元素,这很好理解,但是为什么删除也要拷贝元素??
这和数组的定义有关:空间连续。
你以为数组删除是这样的:
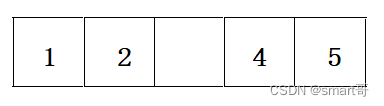
但是注意,new int[5]其实数组是有默认值0的。你根本无法把数组某个元素设为null,默认值就是0。你想清除原有元素可千万别用 arr[i] = 0,那样别人会以为arr[i]的值就是0。所以,我们这里讨论的删除是确确实实的把数组“截短”。由于数组要保证空间连续,所以会重新拷贝元素,把两边的数据合并:
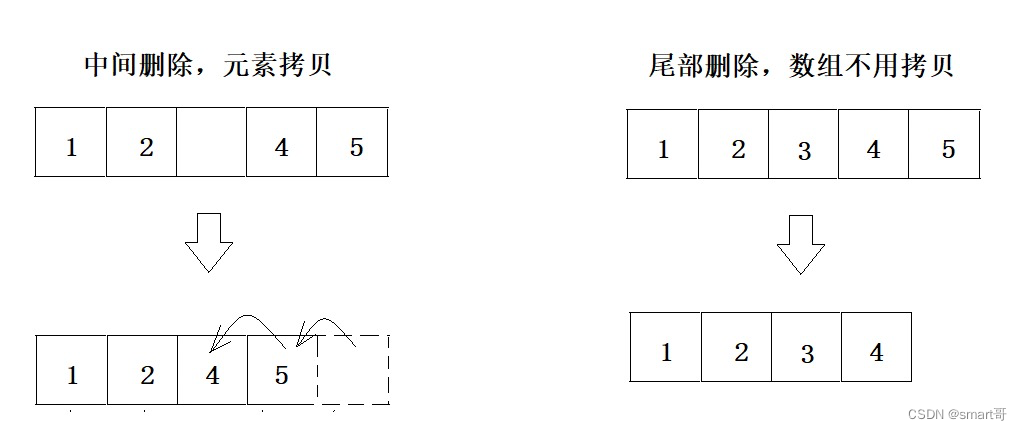
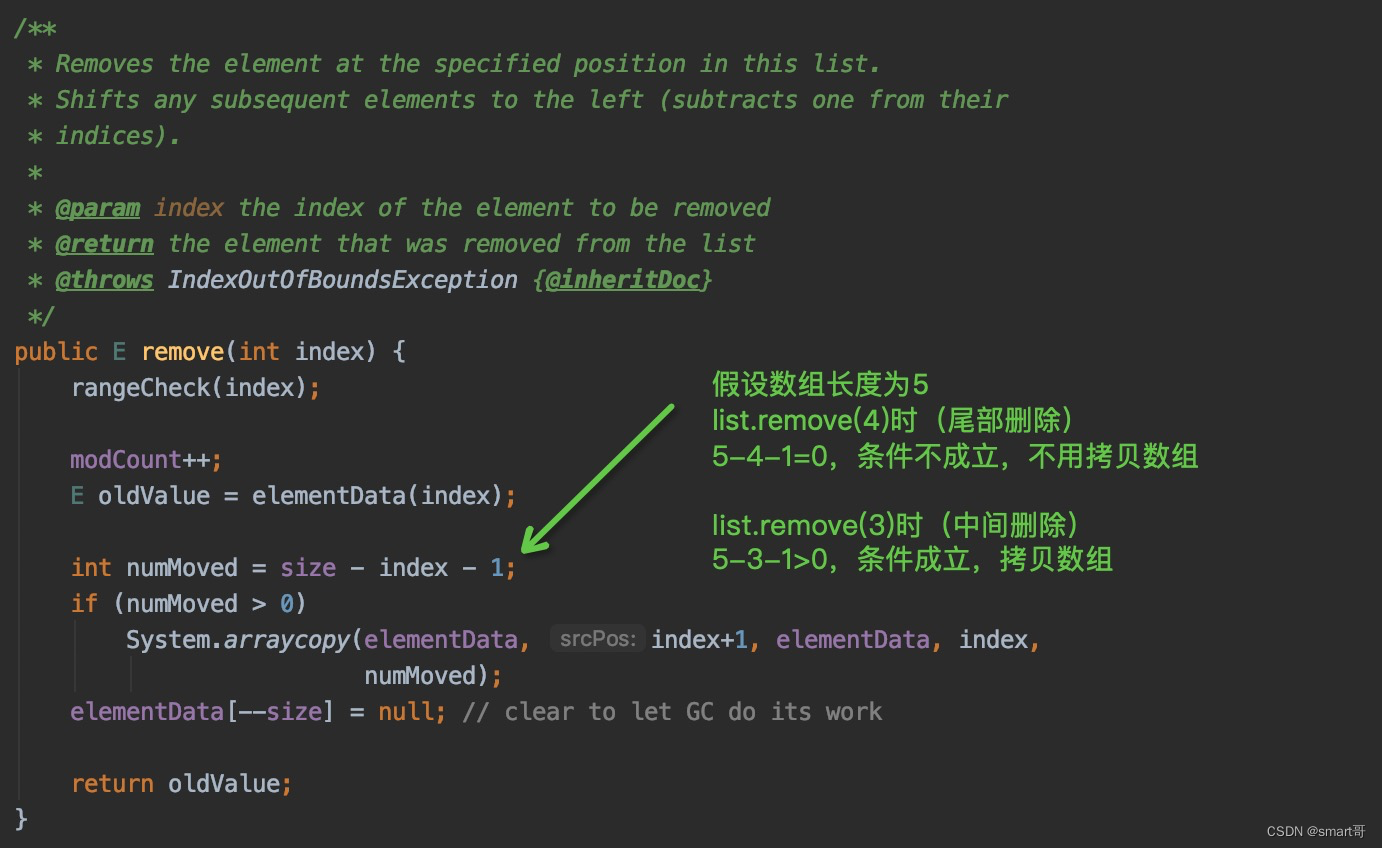
ArrayList#remove(index)/remove(element):极有可能拷贝数组,除非尾部删除
ArrayList小结
- 查询
-
- 随便用,只有一个get(index),根据下标查询,很快
- 插入
-
- 尽量使用add(element),避免使用add(index, element),中间插入一定触发数组拷贝,较大概率触发扩容,扩容和拷贝不一定同时进行。是否取决于元素数量,而是否拷贝取决于本次插入位置,尾部插入无需拷贝
- 替换
-
- set(index, element),很快
- 删除
-
- 推荐循环删除时使用逆序遍历,这样可以从尾部删除,不会触发数组拷贝,禁止从头部删除
讲完了理论,接下来让我们写点代码验证下。
LinkedList VS ArrayList
纯粹的增删改是不存在的,必然伴随着遍历,这也是实际开发的常态,所以demo都会按照实际开发的习惯编写。
时间仅供对位比较,不要错位比较。比如,不要把查询和插入的时间拿来比,因为我有时查询里会打印数据,且查询只查了1w条,而插入可能是100w条。
查询比较
直接跑demo
@Test
public void testForEachInLinkedList() {// 准备10000条数据,不要问我为啥用String.valueOf(),当初不小心这样写的,不改了List<String> list = new LinkedList<>();for (int i = 0; i < 10000; i++) {list.add(String.valueOf(i));}long start = System.currentTimeMillis();// 测试普通for的查询效率for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}System.out.println("普通for耗时:"+(System.currentTimeMillis()-start));// 推荐增强for,内部有优化
// for (String s : list) {
// System.out.println(s);
// }
// System.out.println("增强for耗时:"+(System.currentTimeMillis()-start));
}
LinkedList要靠地址找到下一个节点,速度较慢,而LinkedList#get(i)操作会触发内部的遍历,应该尽量避免使用。所以,对于LinkedList而言,无特殊情况都推荐使用增强for。
ArrayList使用增强for和普通for虽然差距不大,但还是建议使用增强for,除非你需要用到index。
@Test
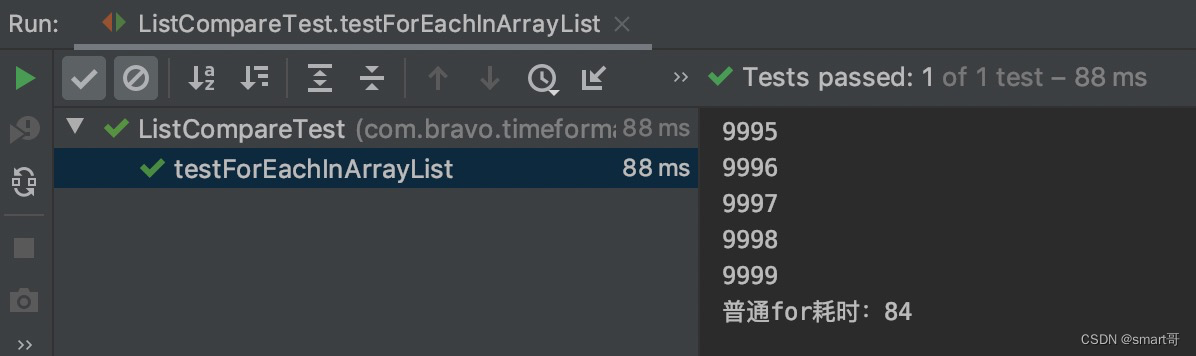
public void testForEachInArrayList() {List<String> list = new ArrayList<>();// 插入10000条数据for (int i = 0; i < 10000; i++) {list.add(String.valueOf(i));}long start = System.currentTimeMillis();// ArrayList推荐使用普通for
// for (int i = 0; i < list.size(); i++) {
// System.out.println(list.get(i));
// }
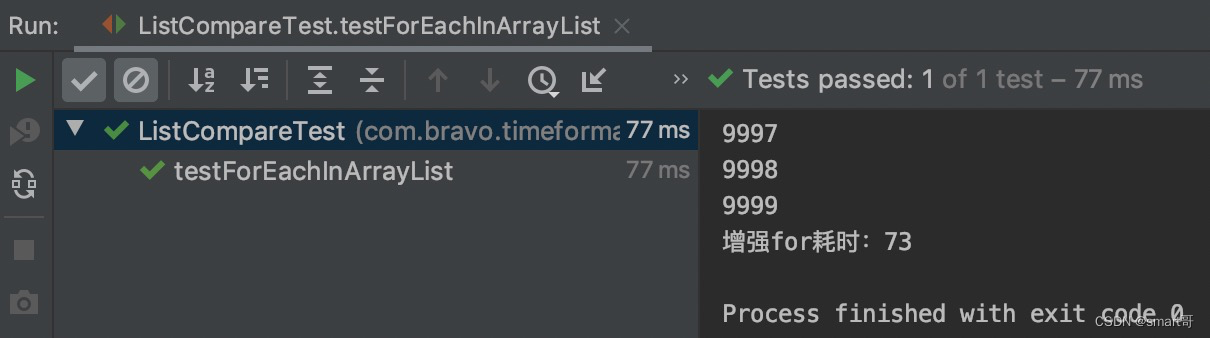
// System.out.println("普通for耗时:"+(System.currentTimeMillis()-start));// 增强forfor (String s : list) {System.out.println(s);}System.out.println("增强for耗时:"+(System.currentTimeMillis()-start));
}
LinkedList 增强for多次查询结果:
87 109 114 82 85...
ArrayList 增强for多次查询结果:
74 142 118 78 90...
结论:都用增强for差不多
LinkedList使用普通for+get(i)会很慢,但使用增强for后得到显著提升,ArrayList普通for和增强for差不多。
整体来说,都用增强for的情况下,ArrayList和LinkedList查询效率差不多。
我的数据量太少了,大家自己测
插入比较
尾部插入:ArrayList胜
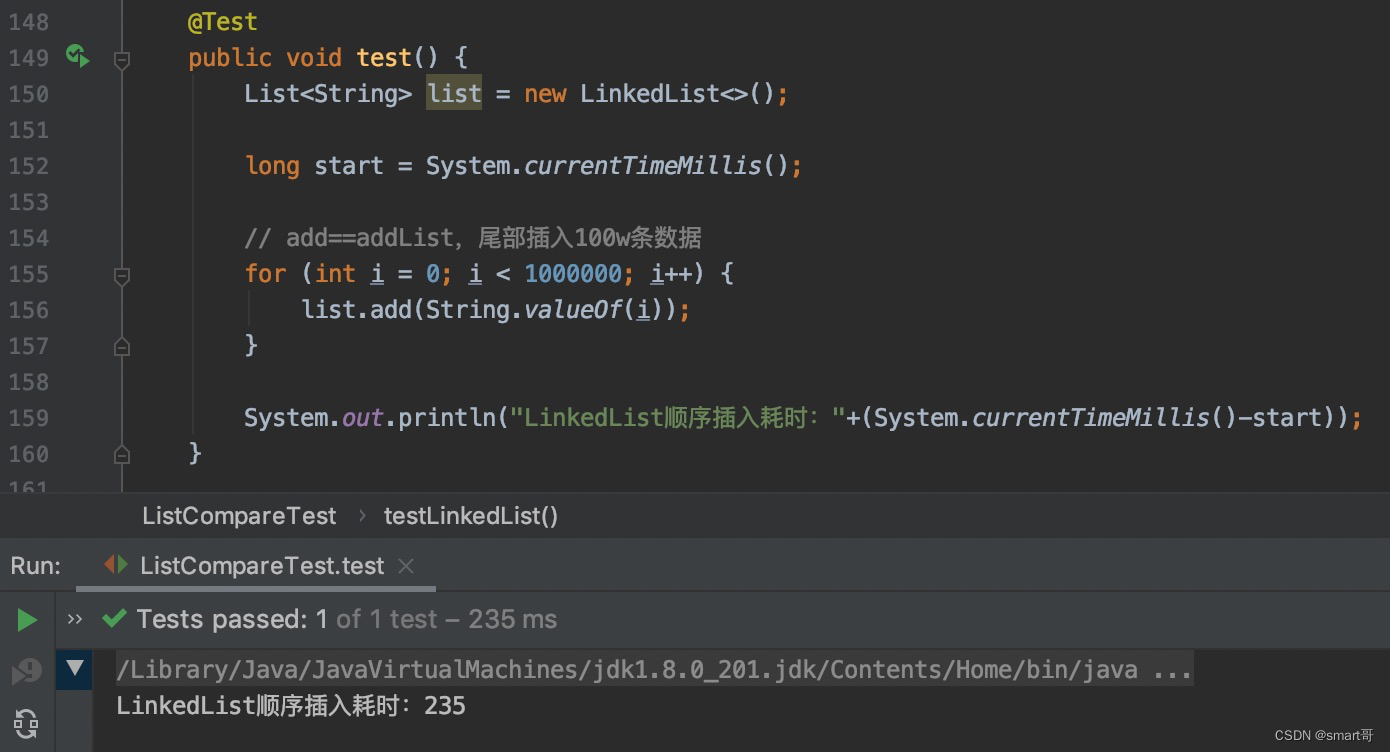
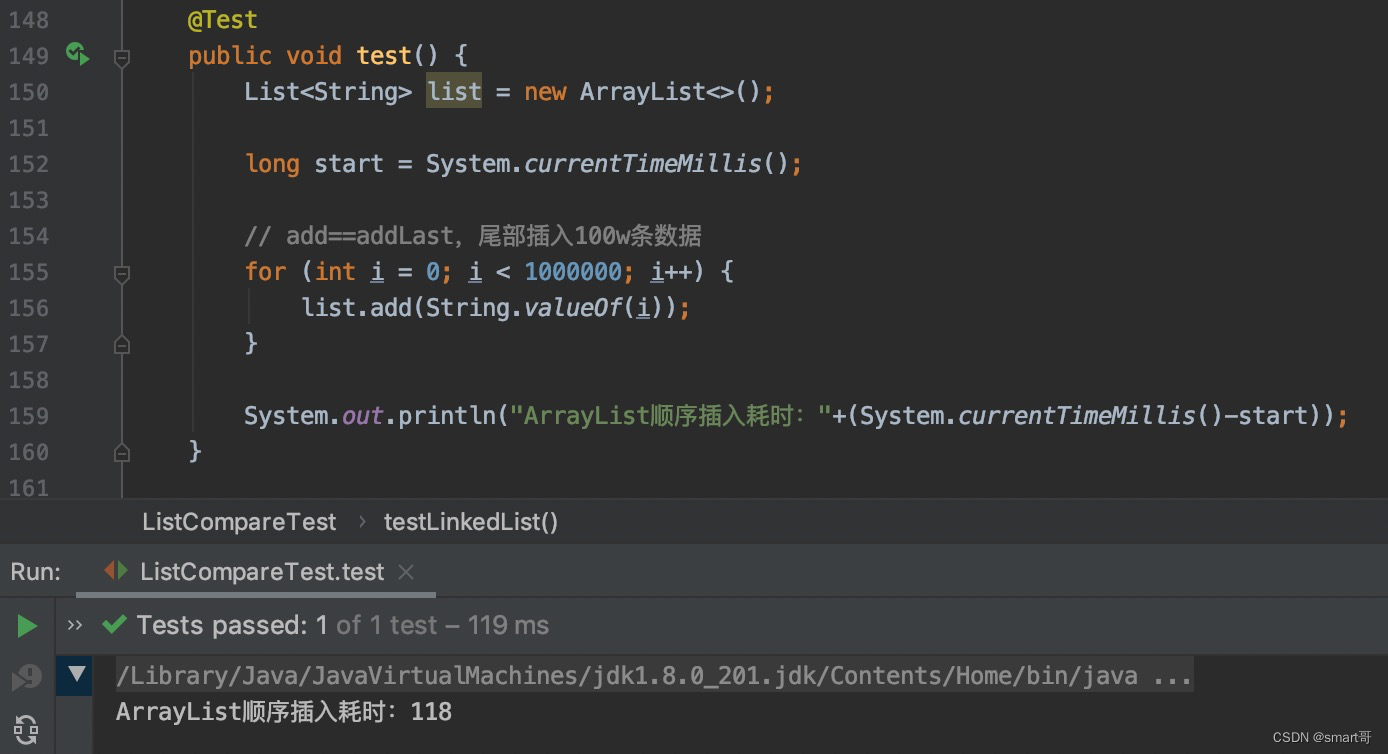
经过多次比较,得出一个意想不到的结果:ArrayList尾部插入效率高于LinkedList。我猜测,ArrayList本身只有数组满了才扩容,且由于是尾部插入不涉及数组拷贝,所以相对较快。而LinkedList由于插入时需要解绑元素并重新绑定新元素,效率反而低了(虽然是对尾结点操作)。
对结果有疑问的同学可以自己测一下:
@Test
public void testList() {List<String> list = new LinkedList<>();long start = System.currentTimeMillis();// 插入10000条数据for (int i = 0; i < 1000000; i++) {list.add(String.valueOf(i));}System.out.println(System.currentTimeMillis() - start);
}头部插入:LinkedList胜
LinkedList头插入和尾插入是一样的:
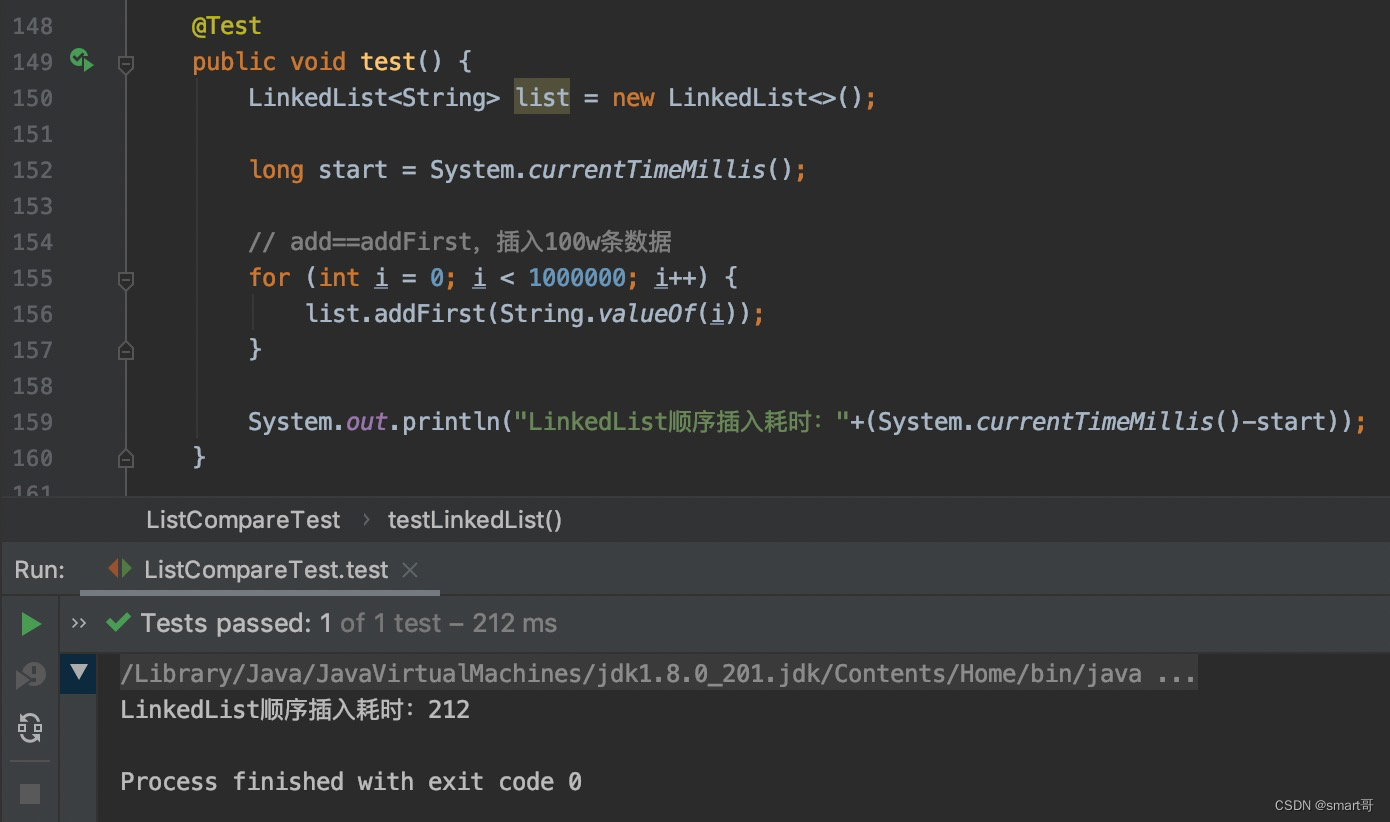
ArrayList头插入效率极低,但是我相信没有人会故意头插入,毕竟我设计头插入这个案例都愣了几秒钟,才发现可以add(0, element)实现头插入。即使真的需要反过来,那么只要遍历时倒序遍历即可:
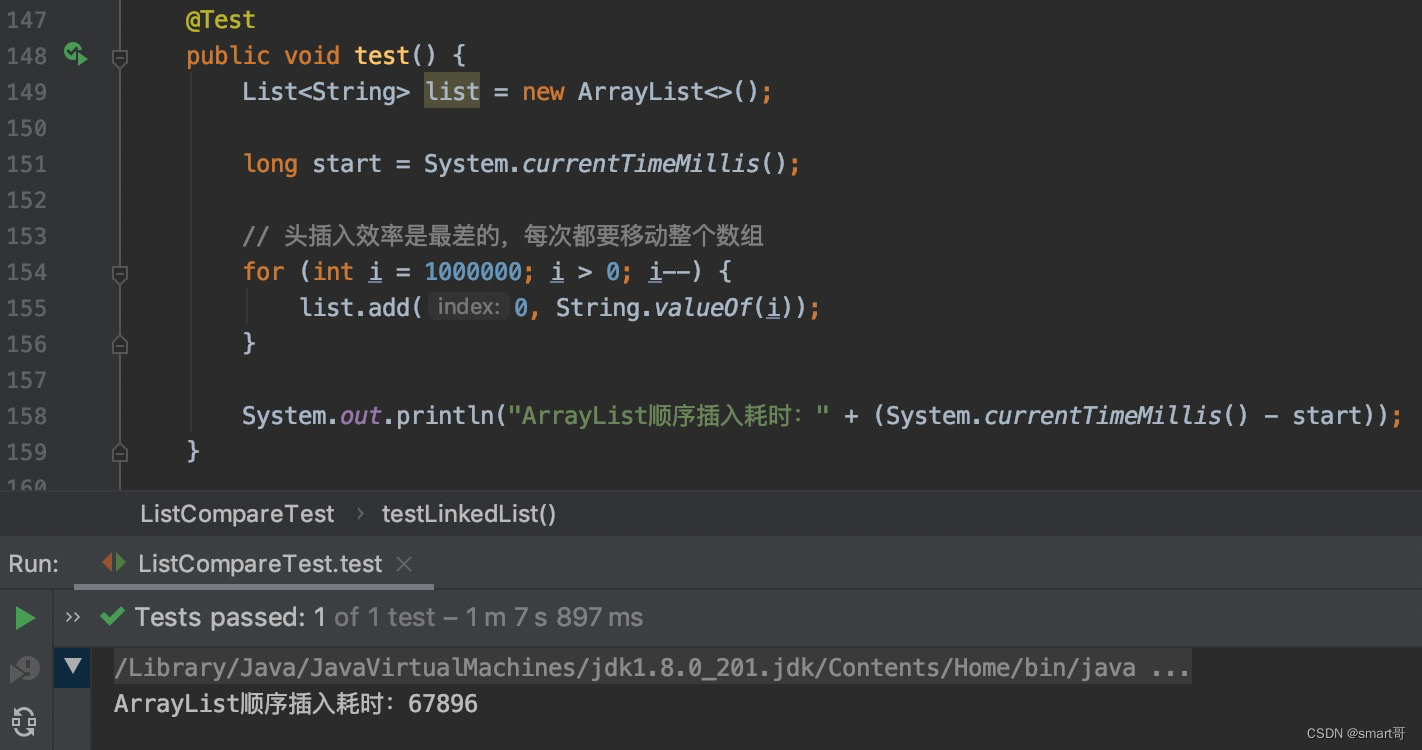
@Test
public void testList() {ArrayList<String> list = new ArrayList<>();long start = System.currentTimeMillis();// 头插入10000条数据for (int i = 0; i < 1000000; i++) {list.add(0, String.valueOf(i));}System.out.println(System.currentTimeMillis() - start);
}随机位置插入:ArrayList胜
原因在于,对于每次随机,add(i, e)内部都要先遍历...所以即使数组底层需要拷贝扩容,无奈LinkedList的遍历实在太慢!
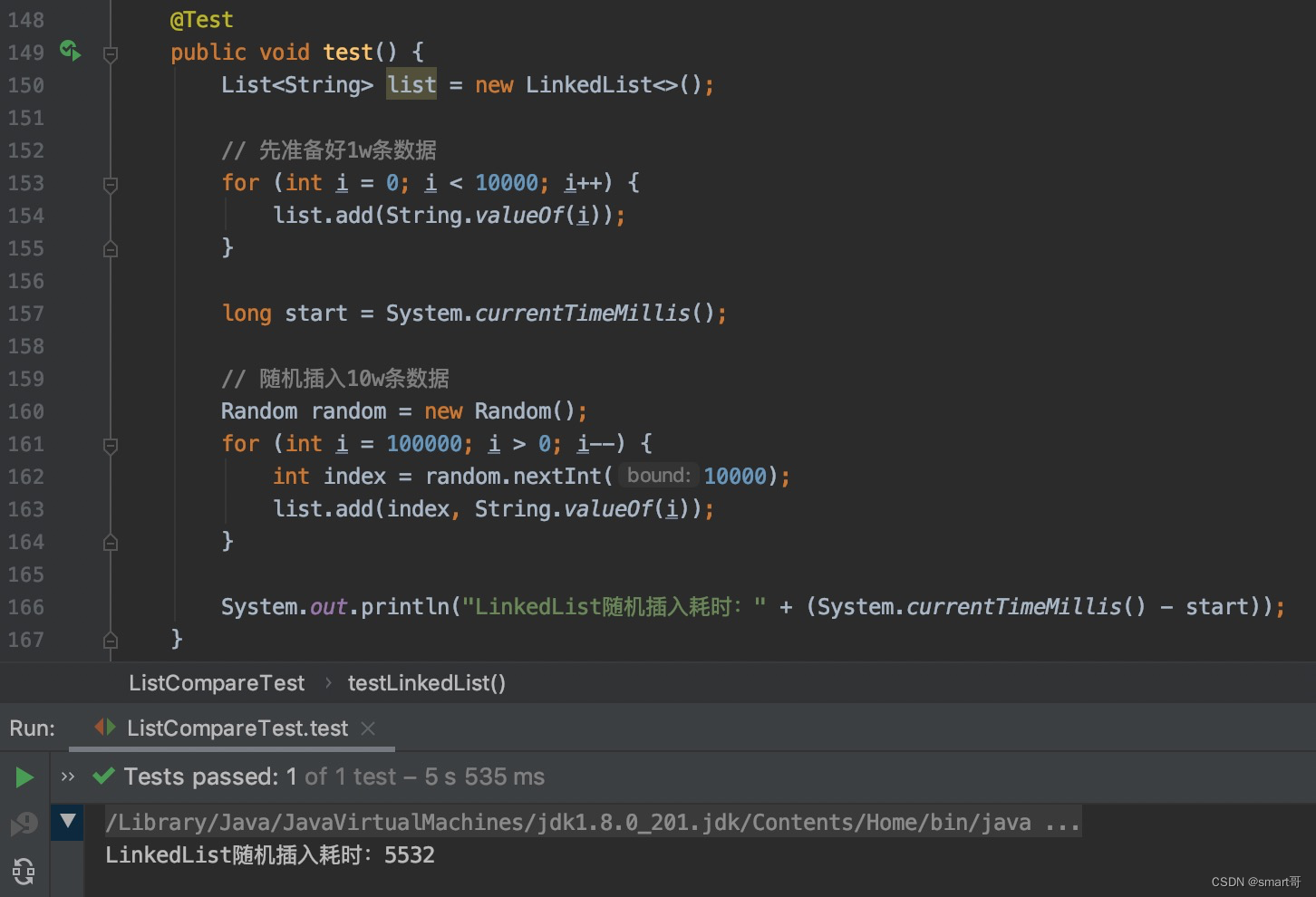
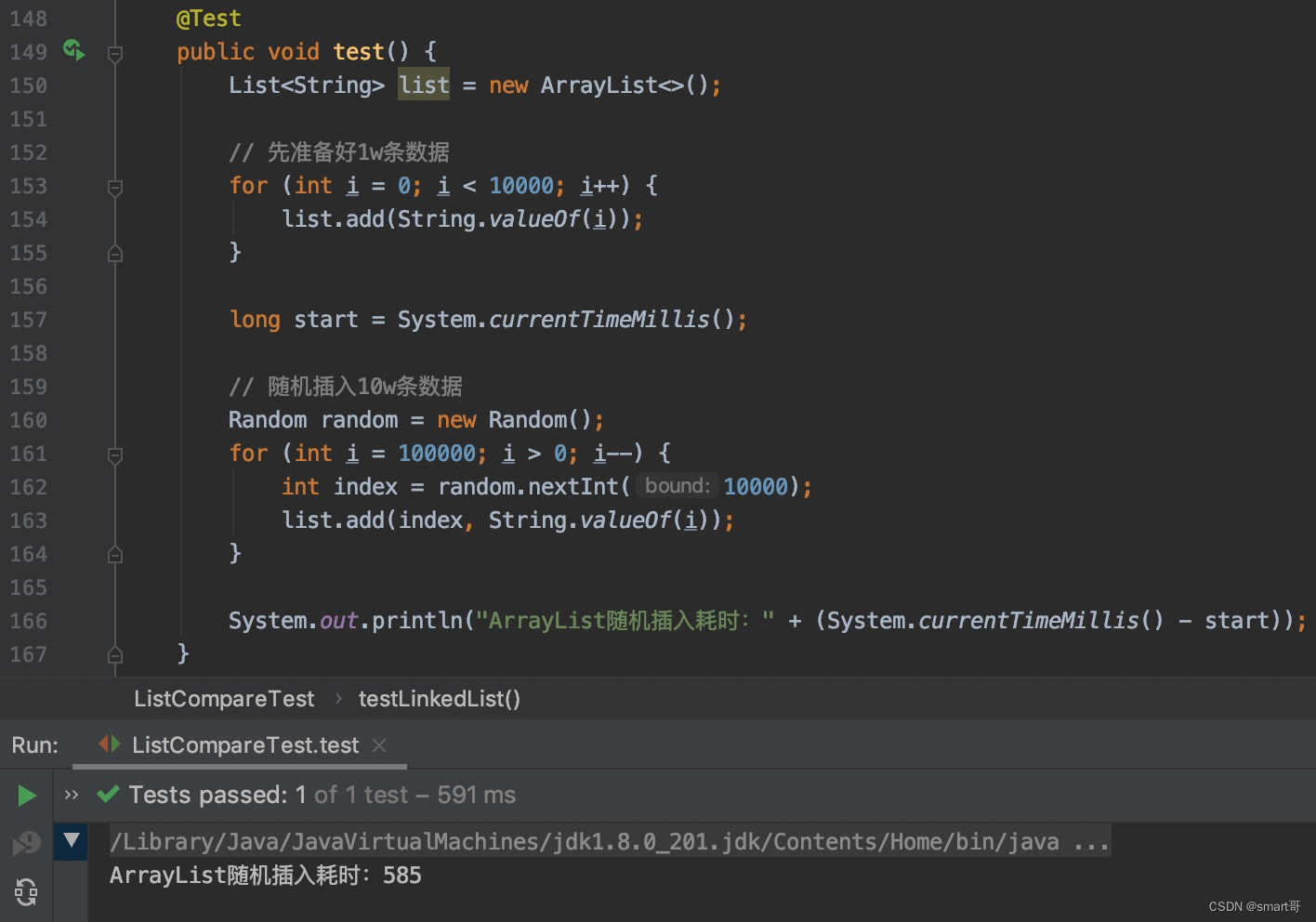
删除比较
尾部删除:ArrayList胜
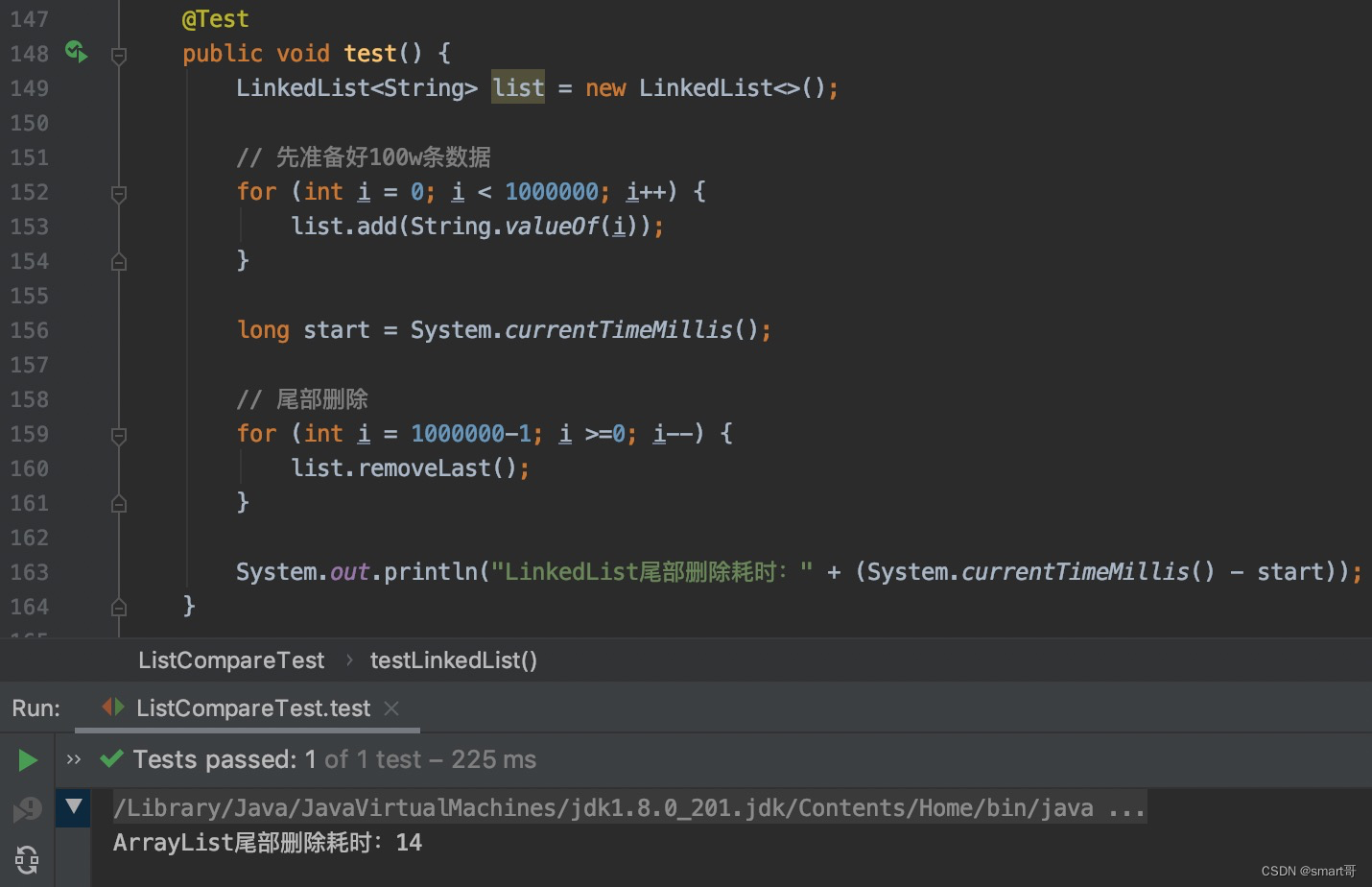
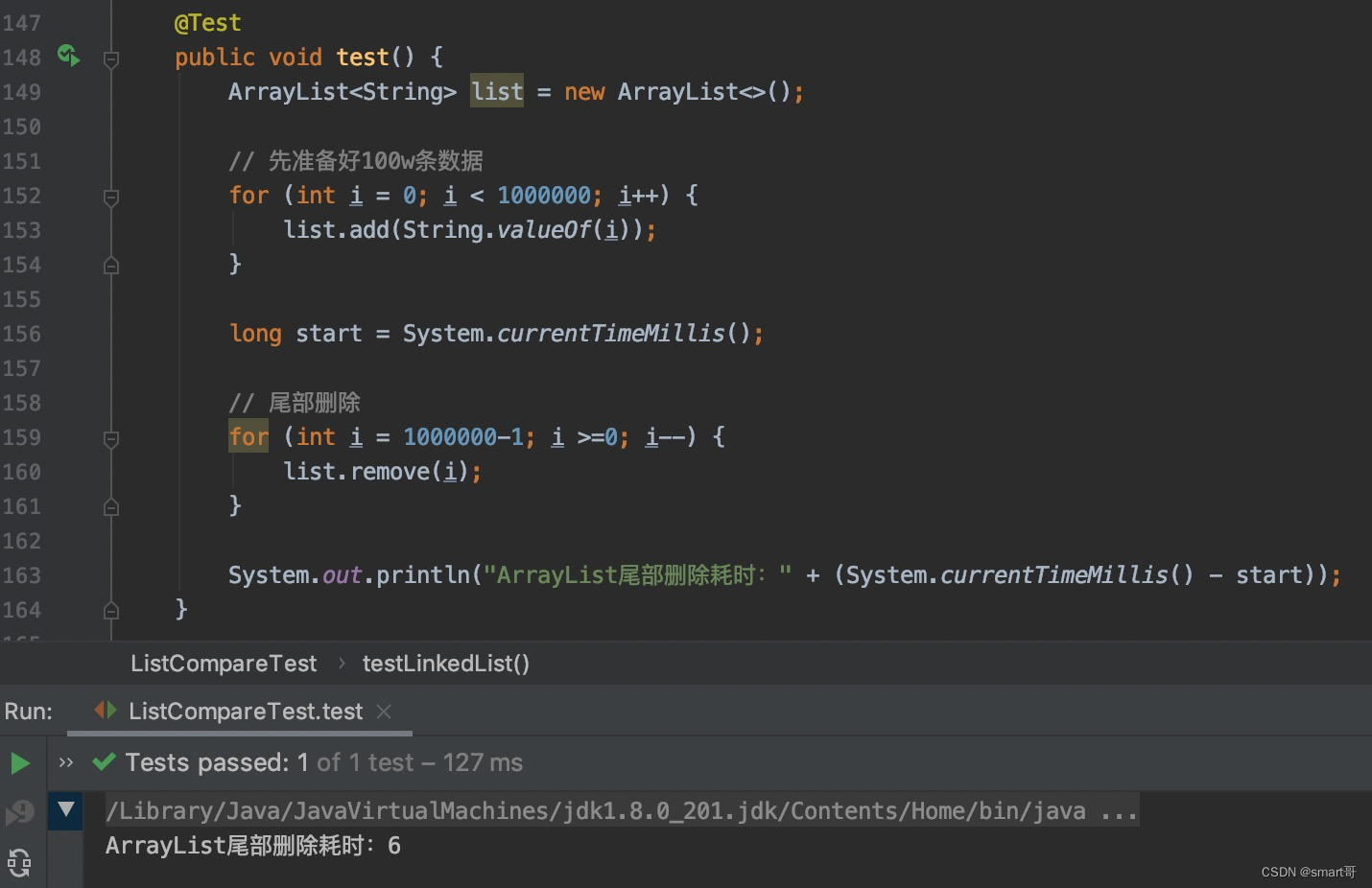
因为ArrayList尾部删除既不会触发扩容,也无需拷贝,所以速度很快。
头部删除:LinkedList胜
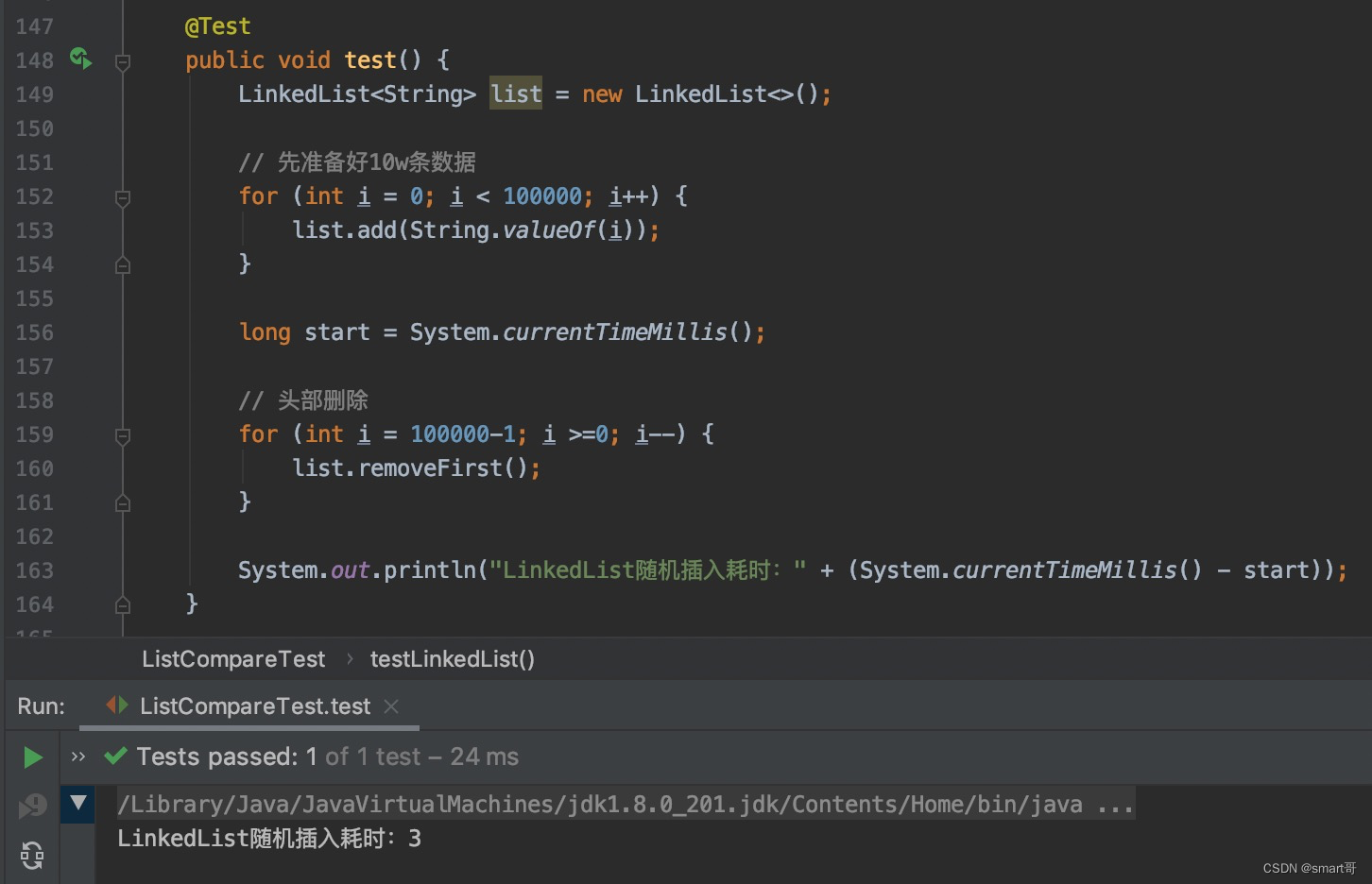
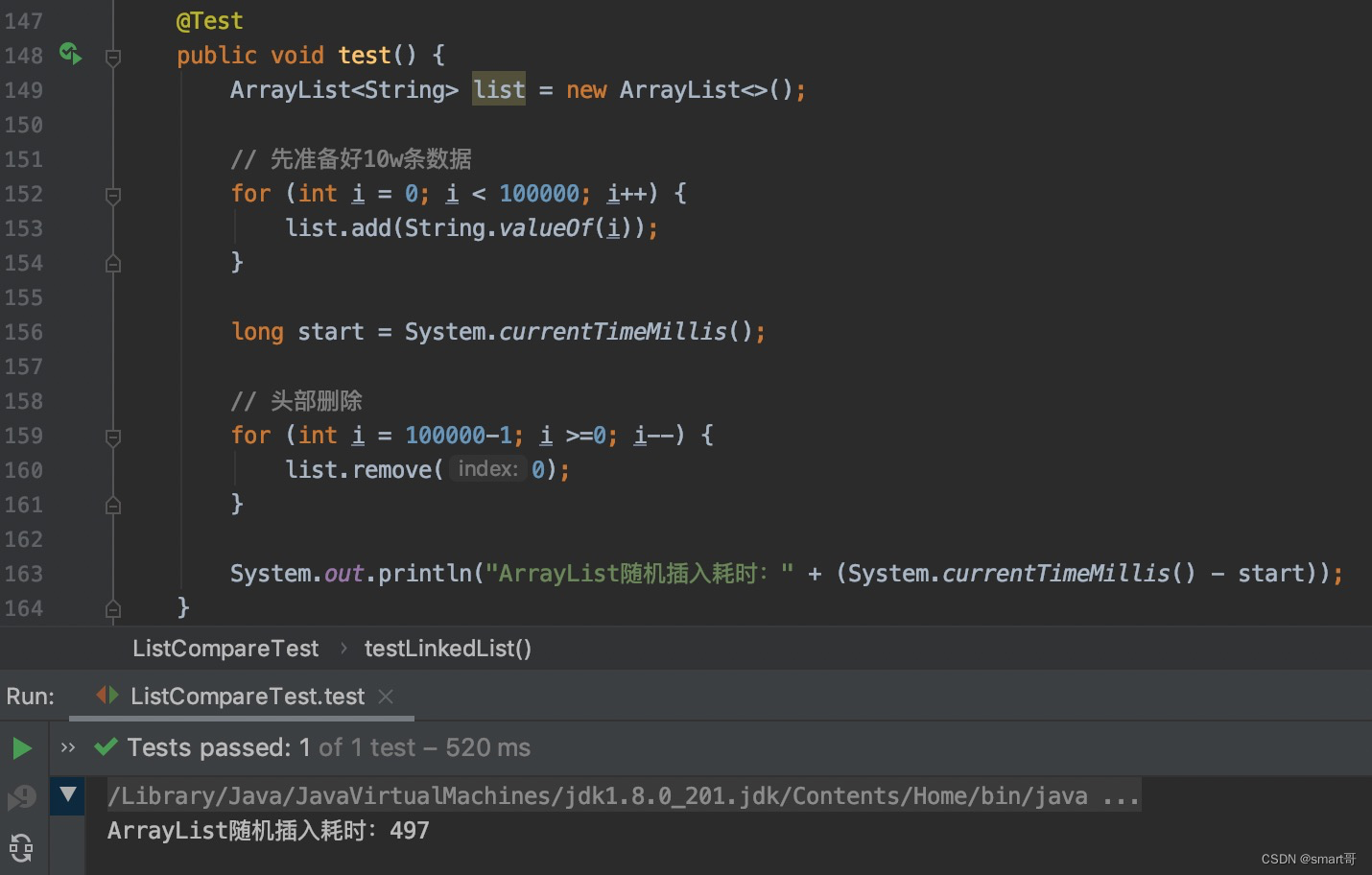
和ArrayList的头插入相似,头删除会触发数组拷贝,但不扩容。
随机删除:ArrayList胜
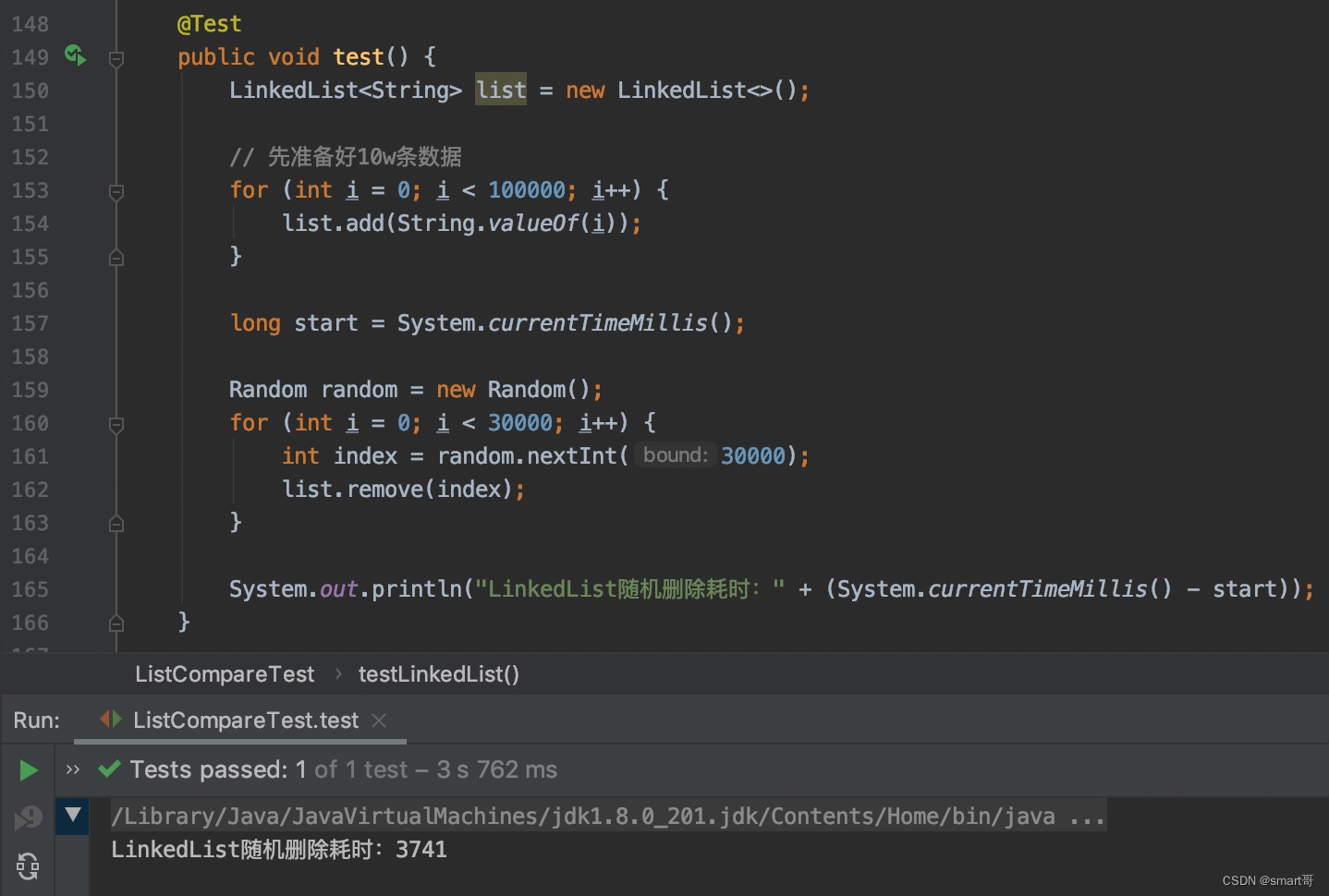
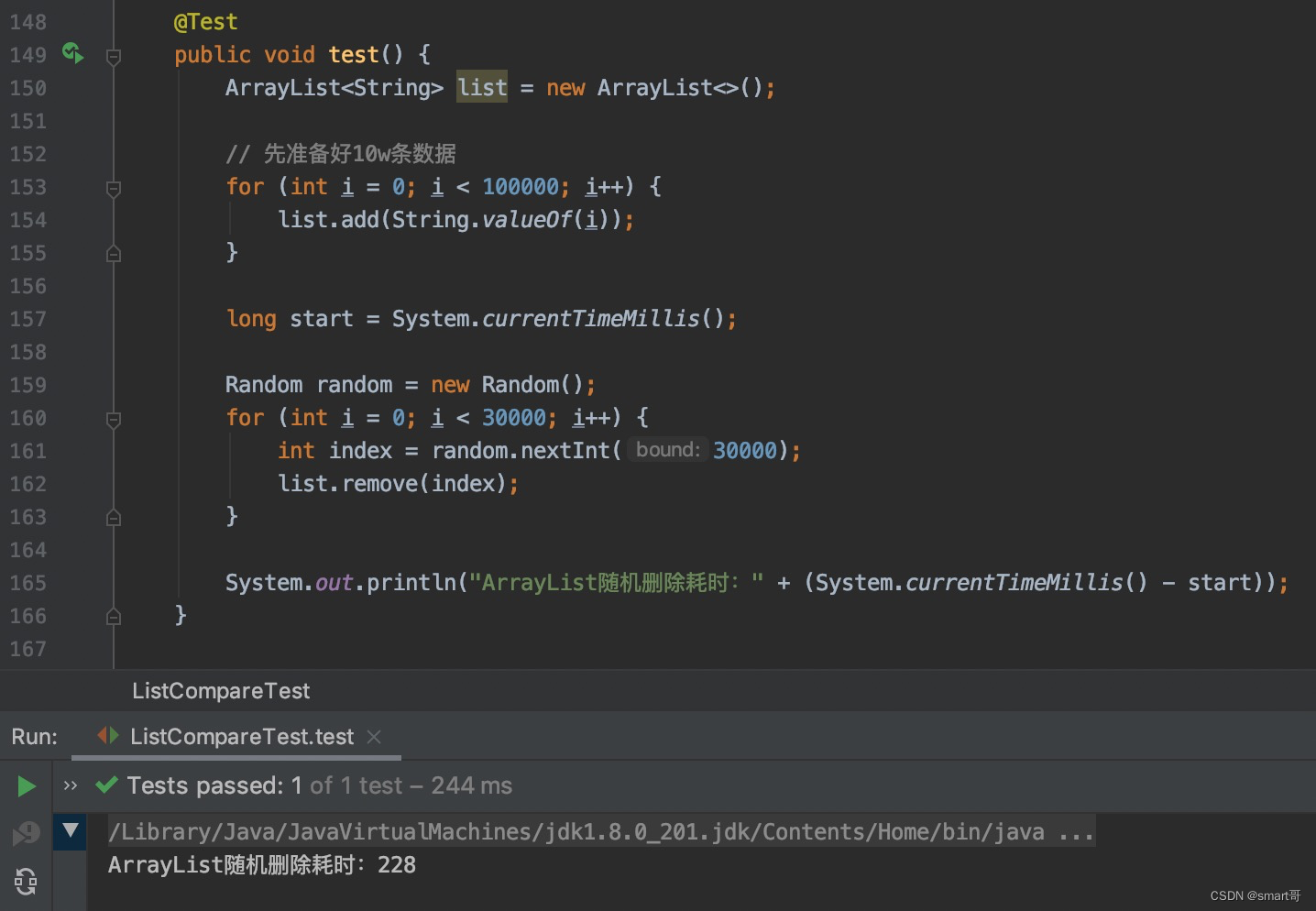
还是那句话,LinkedList的删除优势比不过遍历劣势。
替换比较
顺序替换:ArrayList胜
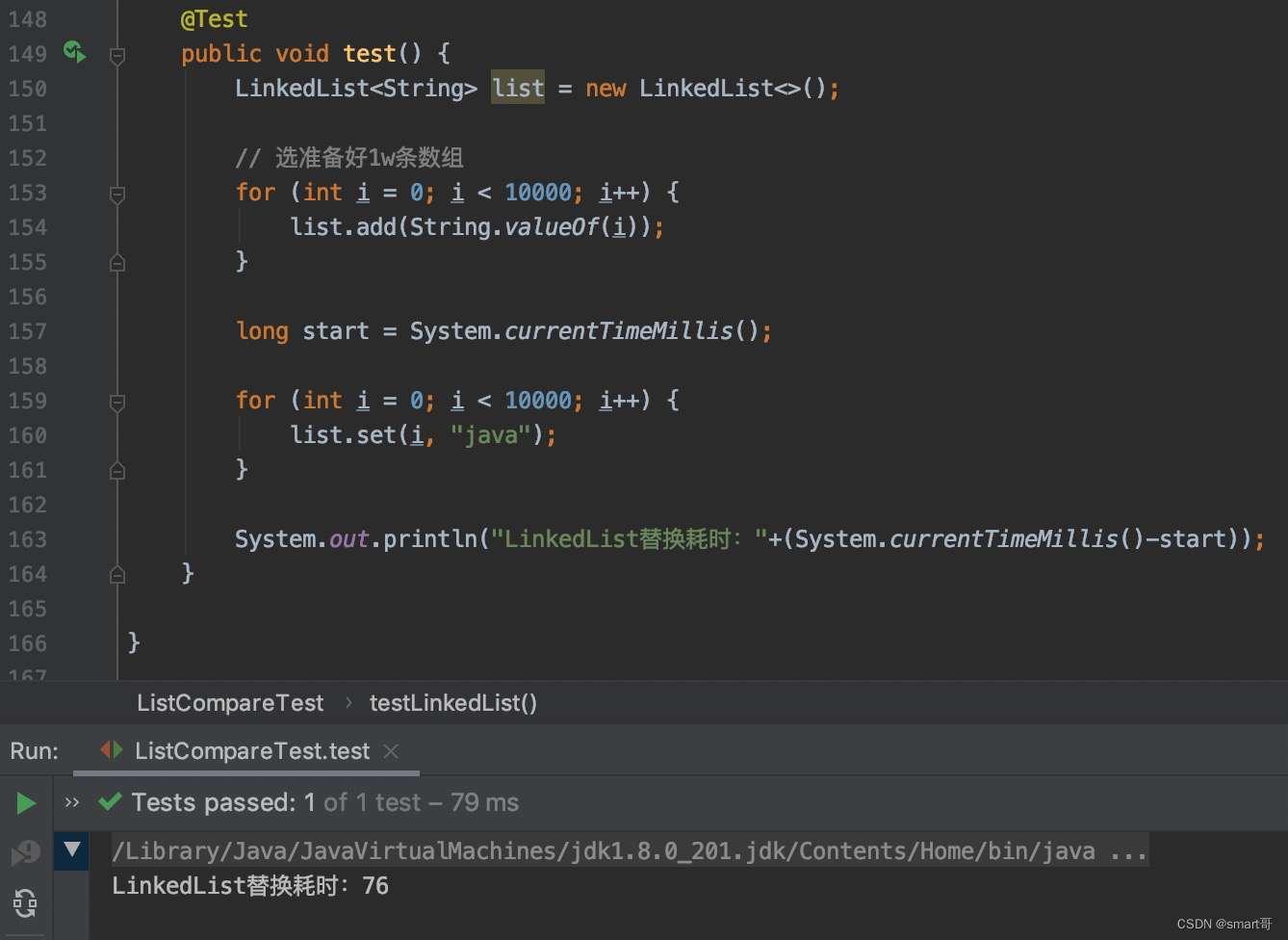
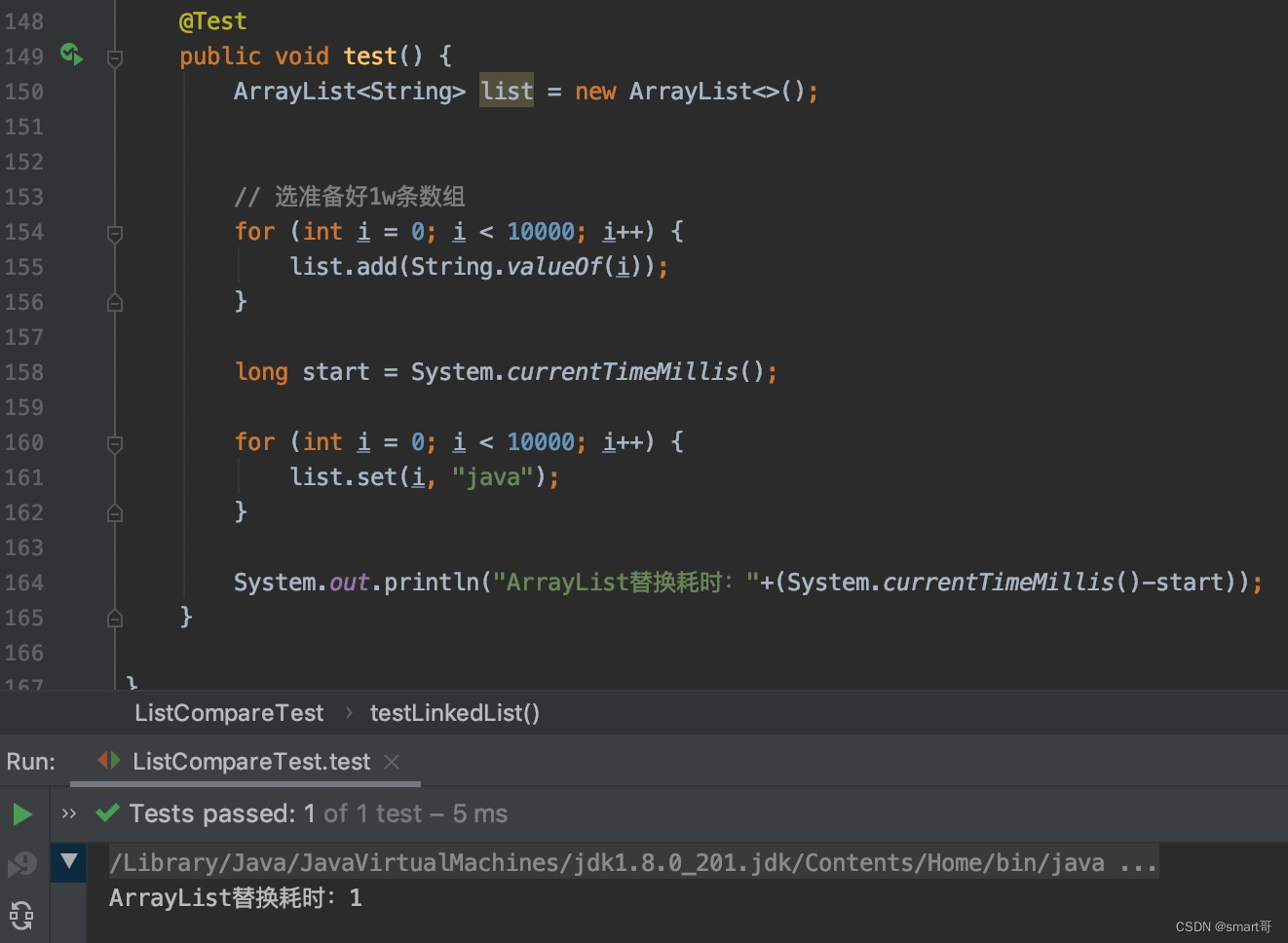
set(i)需要内部遍历,这使得LinkedList效率不如ArrayList
随机替换:ArrayList胜
不测了
总结
理应来说LinkedList作为链表结构,插入删除操作应该比ArrayList效率高,但在遍历的大前提下,LinkedList只要涉及索引操作(index),由于get(i)/set(i, e)等方法内部需要遍历,最终表现往往不如ArrayList。
最后的结论就是,除非你要用list进行头插入或头删除,否则都是ArrayList快。但你觉得这种情况多吗?是什么需求这么变态呀?所以我在构建山寨Stream API时没有考虑LinkedList,也推荐大家平时不知道用哪种List时,优先选择ArrayList。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬