线程级并行(Thread Level Parallelism,TLP)是指在多个处理器或多个核心上同时执行多个线程,从而提高程序的性能和吞吐量。线程级并行的基本原理是利用程序中的数据或任务的并行性,将程序划分为若干个相对独立的子任务,分配给不同的线程执行,然后通过同步机制协调线程之间的数据依赖和通信。
线程具有状态和当前程序计数器,但线程通常共享单个进程的地址空间,允许线程轻松访问同一进程内其他线程的数据。 多线程是一种多线程共享处理器而不需要中间进程切换的技术。 线程之间快速切换的能力使得多线程能够用于隐藏管道和内存延迟。
多线程允许多个线程以重叠的方式共享单个处理器的功能单元。 相比之下,利用线程级并行性 (TLP) 的更通用方法是使用具有多个同时并行运行的独立线程的多处理器。 然而,多线程并不像多处理器那样复制整个处理器。 相反,多线程在一组线程之间共享大部分处理器核心,仅复制私有状态,例如寄存器和程序计数器。
线程级并行有两种主要的实现方式:
- 硬件多线程(Hardware Multithreading):这种方式是在处理器硬件层面上支持多个线程的并发执行,即一个处理器可以同时拥有多个程序计数器(PC)和寄存器堆,从而在一个时钟周期内执行多条指令。硬件多线程又分为两种类型:
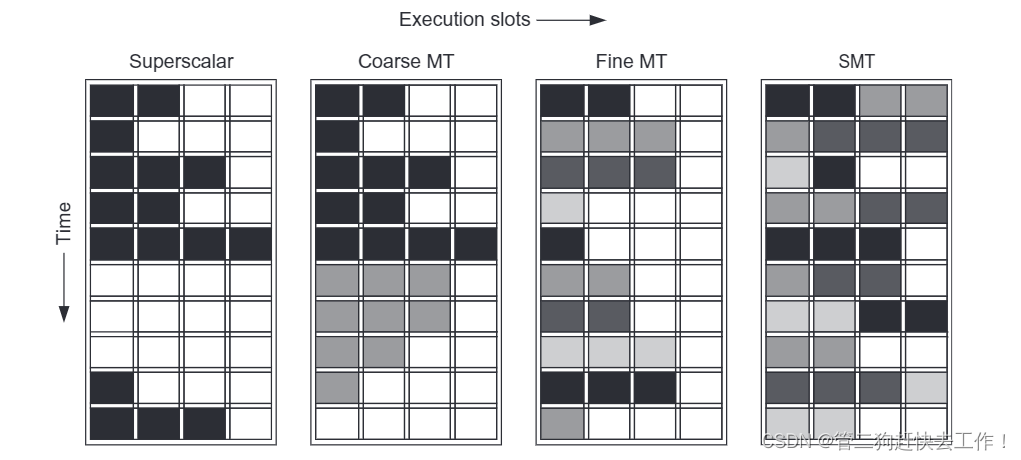
- - 细粒度多线程(Fine-Grained Multithreading):这种类型是指每个时钟周期切换一个线程,从而隐藏流水线中的停顿(stall)。例如,当一个线程遇到缓存不命中或分支错误预测时,处理器就可以切换到另一个就绪的线程继续执行,而不需要等待缓存填充或分支解析。这样可以提高处理器的利用率和吞吐量,但是每个线程的延迟会增加。主要缺点是它会减慢单个线程的执行速度,因为准备好执行而不会停顿的线程将被其他线程的指令延迟。
- - 粗粒度多线程(Coarse-Grained Multithreading):这种类型是指只有当一个线程遇到长时间的停顿(例如访问主存或I/O设备)时才切换到另一个线程。这样可以减少线程切换的开销和频率,提高每个线程的性能,但是对于短时间的停顿无法隐藏,粗粒度多线程有一个主要缺点:它克服吞吐量损失的能力有限,尤其是较短的停顿。。
- - 同时多线程(SMT)。 同步多线程是细粒度多线程的一种变体,当细粒度多线程在多问题、动态调度的处理器之上实现时,就会自然出现。 与其他形式的多线程一样,SMT 使用线程级并行性来隐藏处理器中的长延迟事件,从而提高功能单元的使用率。 SMT 的关键见解是寄存器重命名和动态调度允许执行来自独立线程的多个指令,而不考虑它们之间的依赖关系; 依赖关系的解决可以通过动态调度能力来处理。
- 超标量处理器(Superscalar Processor):这种方式是指在一个处理器内部集成多个功能部件(如算术逻辑单元、浮点单元、加载/存储单元等),从而在一个时钟周期内执行多条指令。超标量处理器需要使用复杂的指令调度和寄存器重命名技术来解决指令之间的数据依赖和资源冲突。超标量处理器可以实现指令级并行(Instruction Level Parallelism,ILP),也可以结合硬件多线程技术实现线程级并行。
下图 从概念上说明了以下处理器配置的处理器利用超标量资源的能力的差异:
下面是一个使用超标量处理器来实现线程级并行的例子:
假设我们有一个双发射(dual-issue)超标量处理器,它可以在每个时钟周期内发射两条指令,并且支持两个硬件线程。假设我们有以下两个线程:
```
Thread 0: Thread 1:
LD R1, 0(R2) LD R5, 0(R6)
ADD R3, R1, R4 SUB R7, R5, R8
ST R3, 0(R2) ST R7, 0(R6)
```
如果只有一个线程在运行,那么它需要6个时钟周期才能完成,如下所示:
```
Cycle Thread 0
1 LD R1, 0(R2)
2 stall (waiting for load result)
3 ADD R3, R1, R4
4 ST R3, 0(R2)
5 stall (waiting for store address)
6 stall (waiting for store data)
```
如果两个线程同时运行,并且交替发射指令,那么它们只需要4个时钟周期就能完成,如下所示:
```
Cycle Thread 0 Thread 1
1 LD R1, 0(R2) LD R5, 0(R6)
2 stall SUB R7, R5, R8
3 ADD R3, R1, R4 ST R7, 0(R6)
4 ST R3, 0(R2) stall
```
可以看出,线程级并行可以有效地利用处理器的资源,提高程序的性能和吞吐量。