目录:
非类型模板参数
模板参数分类:类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。// 非类型模板参数 -- 常量 template<class T, size_t N> // 第一个参数是类型,第二个是常量 // template<class T, size_t N = 10> // 也可以给缺省值,所以模板参数和函数参数是非常像的 class array { private:T _a[N]; };int main() {array<int, 100> a1; // 创建一个对象存放int类型,容量是100array<double, 200> a2; // 创建一个对象存放double类型,容量是200// array<int> a3; // 创建一个对象存放int类型,容量取缺省参数10 }【注意】:非类型模板参数只能是整型一类的,如char,int,size_t,不可以是double或自定义类型。
模板的特化
什么是模板的特化:
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。
template<class T> // 函数模板比较left < right bool Less(T left, T right) {return left < right; }int main() {cout << Less(1, 2) << endl; int n1 = 1;int n2 = 2;cout << Less(n1, n2) << endl;int* p1 = &n1;int* p2 = &n2;cout << Less(p1, p2) << endl;return 0; }
前两个都是正确的,但是,第三个传入参数时默认匹配的是int*,比较的是地址,所以结果不是1,所以只需要使用模板的特化就可以解决。
template<class T> // 函数模板比较left < right bool Less(T left, T right) {return left < right; }// 针对某些类型进行特殊化处理 // 函数模板特化 template<> bool Less<int*>(int* left, int* right) {return *left < *right; }int main() {cout << Less(1, 2) << endl; int n1 = 1;int n2 = 2;cout << Less(n1, n2) << endl;int* p1 = &n1;int* p2 = &n2;cout << Less(p1, p2) << endl;return 0; }
这里就举一个小例子,虽然不是很符合,但是也可以看出特化的作用。在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为函数模板特化与类模板特化。

函数模板特化
函数模板的特化步骤:
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型。
 【注意】:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。不写模板函数,直接写一个这种类型的函数。
【注意】:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。不写模板函数,直接写一个这种类型的函数。bool Less(int* left, int* right) {return *left < *right; }该种实现简单明了,因为对于一些参数类型复杂的函数模板,特化时特别给出,因此函数模板不建议特化。
类模板特化
template<class T> struct Less {bool operator()(const T& x1, const T& x2) const{return x1 < x2;} };// 类模板特化 template<> struct Less<int*> {bool operator()(int* x1, int* x2) const{return *x1 < *x2;} };类模板的步骤和函数模板差不多,差别就是函数模板的<>是写在函数名旁边,类模板的<>要写在类名旁边。
全特化
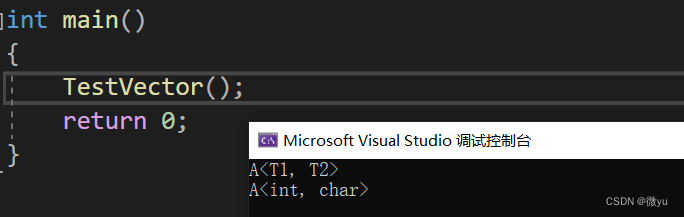
全特化即是将模板参数列表中所有的参数都确定化。template<class T1, class T2> class A { public:A() { cout << "A<T1, T2>" << endl; } };// 全特化 template<> class A<int, char> { public:A() { cout << "A<int, char>" << endl; } };void TestVector() {A<int, int> a1;A<int, char> a2; }int main() {TestVector();return 0; }
偏特化
任何针对模版参数进一步进行条件限制设计的特化版本。template<class T1, class T2> class A { public:A() { cout << "A<T1, T2>" << endl; } };// 偏特化 template<class T1> class A <T1, double> { public:A() { cout << "A<T1, double>" << endl; } };template<class T1, class T2> class A <T1*, T2*> { public:A() { cout << "A<T1*, T2*>" << endl; } };template<class T1, class T2> class A <T1&, T2&> { public:A() { cout << "A<T1&, T2&>" << endl; } };template<class T1, class T2> class A <T1&, T2*> { public:A() { cout << "A<T1&, T2*>" << endl; } };int main() {A<int, int> a0; // 调用基础模板A<int, double> a1; // 调用特化double模板A<int*, int*> a2; // 调用特化指针模板A<int&, int&> a3; // 调用特化引用模板A<int&, int*> a4; // 调用引用和指针模板return 0; }模板的也就是匹配,能匹配的就匹配,尽量去匹配,不能匹配的就报错。
模板分离编译
分离编译为:一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。下面是一段简单的分离编译的代码,是运行正常的。// a.h int A(const int& left, const int& right);// a.cpp int A(const int& left, const int& right) {return left + right; }// main.cpp int main() {cout << A(1, 2) << endl;return 0; }但是模板的分离编译是会出问题的,所以下面就来说一下为什么会出问题。把代码改为分离编译的。// a.h template<class T> T A(const T& left, const T& right);// a.cpp template<class T> T A(const T& left, const T& right) {return left + right; }// main.cpp int main() {cout << A(1, 2) << endl;return 0; }C++程序想要运行就要经过这些步骤:预处理 ----> 编译 ----> 汇编 ----> 链接。
编译是:对程序按照语言特性进行词法、语法、语义分析,错误检查无误后生成汇编代码,但是头文件不参与编译,编译器对工程中的多个源文件是分离开单独编译的。
链接是:将多个.o(bj)文件合并成一个,并处理没有解决的地址问题。
在a.cpp文件中,编译器没有看到对A模板函数的实例化,因此不会生成具体的加法函数;在main.o(bj)中调用A<int>,编译器在链接时才会找到它的地址,但是这两个函数没有实例化没有生成具体代码,所以链接时会报错。
在.h文件中没有定义,T不确定,所以没有办法实例化,没有实例化就无法进符号表,链接的时候肯定会报错。
解决方法
所以模板不推荐使用声明定义分离在两个文件中,声明和定义放到同一个文件中就可以了。
模板特点
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生。
- 增强了代码的灵活性。
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误。
它的优点显而易见,帮助我们实现泛型编程,缺点在编译报错的时候也可以看到很长的一串报错信息,还有一点是,每实现一块类型,编译器都会重新生成一份模板代码。