ViDeNN: Deep Blind Video Denoising
摘要
We propose ViDeNN: a CNN for Video Denoising without prior knowledge on the noise distribution (blind denoising).
The CNN architecture uses a combination of spatial and temporal filtering, learning to spatially denoise the frames first and at the same time how to combine their temporal information, handling objects motion, brightness changes, low-light conditions and temporal inconsistencies.
We demonstrate the importance of the data used for CNNs training, creating for this purpose a specific dataset for lowlight conditions.
- 提出一种无需事先了解噪声分布的视频去噪CNN(架构如上)
- 创建了弱光条件数据集
introduction
1、图像和视频去噪目的是为了获得原始图像X ,其中the noise degradation model定义为:Y=X+N(在加性噪声下)。在弱光条件下,噪声与信号有关,在暗区更敏感,建模为 Y = H(X)+N,H 为退化函数。
2、引入设计的思想
(1)成像噪声的来源:thermal effects(热效应), sensor imperfections or low-light. Hand tuning multiple filter parameters
(2)we automate the denoising procedure with a CNN for flexible and efficient video denoising, capable to blindly remove noise.
3、Solutions based on statistical models 面临两个问题:
(1)只能适用于特定场景tackle specific noise models and levels
(2)手动调参 timeconsuming hand-tuned optimization procedures
4、目前最先进方法
视频去噪关键:video frames are strongly correlated.
VM4D在BM3D(处理单图像)基础上通过搜索相似块扩展,实现在空间时间域中搜索相似补丁
5、本文贡献
提出用于盲视频去噪的卷积神经网络,在没有噪声模型和视频内容的先验知识情况下对其去噪,已在公共可用数据集和自制视频上进行
(1) a novel CNN architecture capable to blind denoise videos, combining spatial and temporal information of multiple frames with one single feed-forward process; (将多帧的空间和时间信息与单个前馈过程相结合)
(2)Flexibility tests on Additive White Gaussian Noise and real data in low-light condition;
(3)Robustness to motion in challenging situations;
(4)A new low-light dataset for a specific Bosch security camera, with sample pairs of noise-free and noisy images.(提供了低光条件下的数据集,包含有噪声和无噪声的样本对)
Related Work
(1)基于CNN的图像去噪 发展历史:CNN–BM3D–DnCNN–FFDnet–MemNet–CBDNet–Noise2Noise
(2)深度神经网络在视频中的应用 :CNN的应用方面,引入参考 U-Net CNN[29]设计三帧堆叠作为输入
(3)(弱光下的)数据集
The architecture of the proposed ViDeNN network.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gIOnUE6A-1689334333940)(https://data-1306794892.cos.ap-beijing.myqcloud.com/imgs/20220422-1040-fad.png)]
所提出的 ViDeNN 网络的架构。每一帧都会经过一个空间去噪 CNN。时间 CNN 将三个空间去噪帧作为输入,并输出对中心帧的最终估计。两个 CNN 都首先估计噪声残差,即加入图像中的(不想要的)噪声,然后从输入的噪声图像中减去它们(⊕ 表示两个信号相加,“-”表示否定)。 ViDeNN 仅由卷积层组成。特征图的数量写在每一层的底部。
ViDeNN
Spatial Denoising CNN
For spatial denoising we build on [14]
A first layer of depth 128 helps when the network has to handle different noise models at the same time.
The network depth is set to 20 and Batch Normalization (BN) (使用批量归一化)[15]
is used.
The activation function is ReLU (Rectified Linear Unit). We also investigated the use of Leaky ReLU as activation function,(后续有比较两种方法)
Our Spatial-CNN uses Residual Learning 用于图像去噪【The loss function L is the L2-norm, also known as least squares error (LSE)】文章有具体说明本设计的L构造形式
A Realistic Noise Model(设计的真实噪声模型)
The denoising performance of a spatial denoising CNN depends greatly on the training data.
由于高斯白噪声AWGN无法代表真实世界的噪声,本文也是为了尽可能的实现用一个网络实现多个噪声模型的训练,如图1所示,其空间去噪模型可以对盲高斯噪声(未知噪声参数)进行去噪。因此,引入信号相关的模型,具体模型等式如下,推导看图文

其中所考虑的索尼传感器的相关术语是:Ag(模拟增益),范围 [0,64],Dg(数字增益),范围 [0,32] 和 s表视将降级的图像。以及其余值为固定值。通过将具有参考图像s相同形状的正态分布N(0,1)的观测值与等式2中的噪声模型M相乘,生成噪声图像。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mRzBMy77-1689334333941)(https://data-1306794892.cos.ap-beijing.myqcloud.com/typora_imgs/typora_imgs/20220310-0900-d4f.png)]
图3:比较来自CBSD68数据集的图像的空间去噪,该数据集损坏为1,Ag=64,Dg=4。
加入AWGN,如CBM3D和DnCNN,不能达到最佳效果。第一种方法会过度模糊图像。使用合适的噪声模型进行训练可以获得更好的结果。(峰值信噪比[dB]/SSIM) 而DnCNN保留了更多的结构。我们的结果表明,为了更好地去噪现实世界的图像,必须对训练集使用真实的噪声模型 。
Temp3-CNN: Temporal Denoising CNN
其架构类似于空间去噪架构,但是不同空间去噪之处:将三帧堆叠作为输入,并且经过实验证明3帧作为输入时最有效的
设帧尺寸w×h×c,那么输入为w×h×3c,同时也会使用residual learning and will estimate the noise residual image of the central input frame combining the information of other frames allowing it to learn temporal inconsistencies.(将估计中心输入帧的噪声残差图像,结合其他帧的信息,允许其学习时间不一致性)
Experiments
Low-Light Dataset Creation
在Renoir已有设计数据集的思路上,设计更简单的收集过程
自制数据集:对于每一种不同的光照强度,我们连续记录200张原始图像。此外,我们在不同的光照条件下,用停止运动技术记录了六个测试视频序列,包括三到四帧中的运动物体或光照变化:每帧我们记录了200幅图像,总共产生4200幅图像。
Spatial CNN Training
为了能够
tackle multiple degradation types at the same time应对多种退化类型,比如Additive White Gaussian Noise (AWGN) and real noise model 2,我们的神经网络将学习如何使用干净的图像作为参考,估计输入噪声图像的残余噪声含量。因此,我们需要一对干净而嘈杂的图像。对于AWGN和等式2中的真实噪声模型,很容易创建。
- 加噪声:使用数据集
Waterloo Exploration Dataset[36],其中一半的图像都添加了σ=[0,55]的AWGN。第二部分用等式2处理,这是真实的噪声模型 - 数据处理:网络使用50×50×3个补丁进行训练**(这里不是对图片进行训练,而是随机提取图像的块(50*50)进行训练,3代表的是3中增强类型(旋转、反转等)不是通道数**)
- 数据汇总:(数据集都需要干净-噪声集)从Waterloo数据集提取120000个patch,为了适应弱光条件,对于自己的数据集提取了80000个patch,对于低光的测试集,我们将使用来自不同场景的相机中的 5 张图像,这些图像不存在于训练集中,还有 Renoir T3 集的一部分。
- 训练过程:我们训练了 100 个 epoch,使用一批 128 和 Adam Optimizer [37],前 20 个 epoch 的学习率为 10-3,最近 80 个 epoch 的学习率为 10-4。
Validation of static Image Denoising(静态图像去噪的验证)
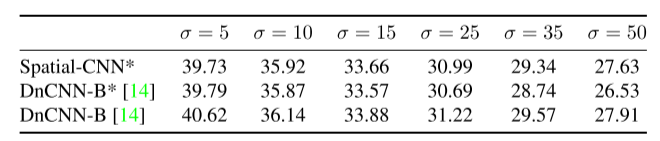
表1:CBSD68数据集上盲高斯去噪的比较。我们改进的DnCNN用于空间去噪,其结果与原DnCNN相当。这些值代表峰值信噪比[dB],越高越好。使用提供的Matlab实现获得的DnCNN结果[38]。
*在[0255]范围内剪裁的噪声图像。
为了验证在真实图片上的去噪效果,我们使用sRGB DND dataset [31]进行测试
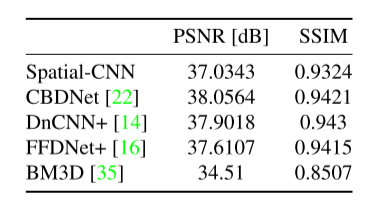
DnCNN+是原作者提出一周后对其进行微调后的新模型
Temp3-CNN: Temporal CNN Training
For video evaluation we need pairs of clean and noisy videos. 常用的噪声方法:For artificially added noise as Additive White Gaussian Noise (AWGN) or the real noise model in equation 2,is easy to create such couples。但是其真实和低光视频的获得几乎不可能(因为这里训练不能用图片了,这是需要至少是一个序列),因此,本文按照以下处理:
- Select 31 publicly available videos from [41].
- Divide videos in sequences of 3 frames.
- Added either Gaussian noise with σ=[0,55] or real noise 2 with Ag=[0,64] and Dg=[0,32].
- Apply Spatial-CNN
- Train on pairs of spatially-denoised and clean video.
同时提出:研究表明,LeakyReLU的表现优于ReLU[34]。然而,我们没有在空间CNN中使用Leaky Relu,因为Relu表现更好。我们在补充材料中给出了比较结果。
同时说明:在Temp3 CNN的最终版本中,没有使用批量归一化(BN):实验表明会减慢训练和去噪过程 (图5有对比)
Exp 1: The Video Denoising CNN Architecture(实验1 视频去噪CNN)
数据来源:we personally recorded with a Blackmagic Design URSA Mini 4.6K, capable to record raw videos. The videos have various levels of Additive White Gaussian Noise (AWGN).
问题1: Is Temp3-CNN able to learn both temporal and spatial denoising?
答:不可以, Temp3-CNN 不能满足同时学习,见表3(略),单独使用 Temp3-CNN 导致结果更不好,甚至不如简单的Simpler Spatial-CNN
问题2: Ordering of spatial and temporal denoising?(排序问题)
答:见表4(略),Spatial CNN+Temp3 CNN的组合表现最好,表现出持续的性能改进∼ 仅在空间上消除1dB的噪声。
问题3: How many frames to consider?
答:见表5(略),虽然使用 the Temp5-CNN 要比 Temp3-CNN多花费不到6秒,差别不大,但是对于真实的大型视频来说,差别会变大。
Exp 2: Sensitivity to Temporal Inconsistency(对时间不一致的敏感性)
为了验证时间一致性,通过取其中三帧,移除第一帧和最后一帧,去噪中间帧,如图
(i) on the video Tennis from [41], add Gaussian noise with standard deviation σ=40;
(ii) Manually remove the white ball on the first and last frame;
(iii) Denoise the middle frame.
PSNR结果方法:在正常情况下和实验情况下得到相同的值,说明:it uses part of the secondary frames and combine them with the reference, but only where the pixel content is similar enough: the ball is not removed from frame 10(网络使用辅助帧并将其作为参考组合,但是这仅在像素内容足够相似的情况下进行:球没有从第10帧移除)

Visualization of temporal filters (时间过滤器可视化表达):将Tech3-CNN中的第一层128个滤波器中两个输出拿出来,如图;a图显示乒乓球是褐色,而前一帧和后一帧的乒乓球是白色的,相反b图中,看到过滤器如何突出显示具有相似颜色平坦区域,并且主要以白色显示当前帧的球。
说明:因此,Temp3-CNN 对三帧中相似和不同的区域赋予不同的重要性。这是关于 CNN 如何处理运动和时间不一致的简单指示。

Exp 3: Evaluating Gaussian Video Denoising
与用于高斯视频去噪的VBM4D和用于单帧去噪的CBM3D和DnCNN进行设计和比较。
其中我们比较了两个版本的 ViDeNN,其中 ViDeNN-G 是专门为 AWGN 去噪训练的模型,而 ViDeNN 是处理多种噪声模型(包括低光照条件)的最终模型。
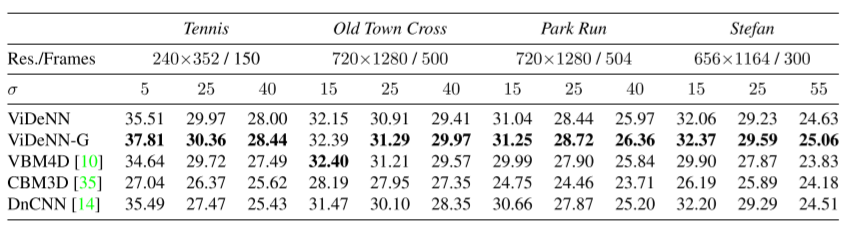
Original videos are publicly available here [41]. Results expressed in terms of PSNR[dB].
Exp 4: Evaluating Low-Light Video Denoising
随着低光数据集的创建,我们还记录了六个序列,每个序列三个或四个帧:
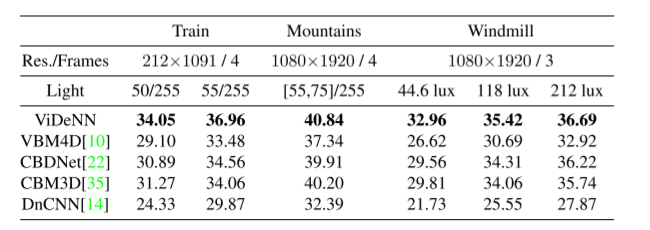
在原始模式下使用 Bosch Autodome IP 5000 IR 记录的六个低光序列上的最先进去噪算法的比较,未激活任何类型的过滤。每个序列由 4 或 3 帧组成,获得的基本事实平均超过 200 张图像。风车序列是用不同的光源记录的,我们可以在其中测量光强度。
令人惊讶的是,单帧降噪器 CBM3D 的性能优于视频版本的 VBM4D:可能是因为CBM3D的盲版本使用的 σ = 50, 而 VBM4D 有一个内置的噪声水平估计器,如果使用与假定的高斯模型完全不同的噪声模型,它的性能可能会更差

在表 7 中,我们以粗体显示了 ViDeNN 的结果,与低光测试集上的其他最先进的去噪算法进行了比较。我们将我们的方法与 VBM4D [10]、CBM3D [35]、DnCNN [14] 和 CBDNet [22] 进行比较。
Discussion
In this paper, we presented a novel CNN architecture for Blind Video Denoising called ViDeNN. We use spatial and temporal information in a feed-forward process, combining three consecutive frames to get a clean version of the middle frame. We perform temporal denoising in simple yet efficient manner, where our Temp3-CNN learns how to handle objects motion, brightness changes, and temporal inconsistencies. We do not address camera motion in videos, since the model was designed to reduce the bandwidth usage of static security cameras keeping the network as simple and efficient as possible. We define our model as Blind, since it can tackle different noise models at the same time, without any prior knowledge nor analysis of the input signal. We created a dataset containing multiple noise models, showing how the right mix of training data can improve image denoising on real world data, such as on the DND Benchmarking Dataset [31].
在本文中,我们提出了一种用于盲视频去噪的新型 CNN 架构,称为 ViDeNN。我们在前馈过程中使用空间和时间信息,组合三个连续的帧以获得中间帧的干净版本。我们以简单而有效的方式执行时间去噪,其中我们的 Temp3-CNN 学习如何处理对象运动、亮度变化和时间不一致。我们不处理视频中的摄像机运动,因为该模型旨在减少静态安全摄像机的带宽使用,使网络尽可能简单和高效。我们将我们的模型定义为 Blind,因为它可以同时处理不同的噪声模型,无需任何先验知识,也无需分析输入信号。我们创建了一个包含多个噪声模型的数据集,展示了训练数据的正确组合如何改善真实世界数据的图像去噪,例如 DND 基准数据集 [31]。
We show how it is possible, with the proper hardware, to address lowlight video denoising with the use of a CNN, which would ease the tuning of new sensors and camera models. Collecting the proper training data would be the most time con-
suming part. ,defining an automatic framework with predefined scenes and light conditions would simplify the process, allowing to further reduce the needed time and resources. Our technique for acquiring clean and noisy lowlight image pairs has proven to be effective and simple, re-
quiring no specific exposure tuning.
我们展示了如何使用适当的硬件来使用 CNN 解决低光视频去噪问题,这将简化新传感器和相机模型的调整。收集正确的训练数据将是最耗时的部分。定义具有预定义场景和光照条件的自动框架将简化流程,从而进一步减少所需的时间和资源。我们获取干净和嘈杂的低光图像对的技术已被证明是有效且简单的,不需要特定的曝光调整。
Limitations and Future Works
(1)The largest real-world limitations of ViDeNN is the required computational power.
(2)We did not try to implement ViDeNN on a mobile device supporting Tensorflow Lite, which converts the model to a lighter version more suitable for handled devices. This could be new development and challenging question to investigate on, since every week the available hardware in the market improves.
(1)最大问题是算力,即使使用高端的英伟达显卡,处理HD高清视频的最快速度只有36fps,但是面对当前的全高清和超分辨等效果较差
(2)未适应移动端:没有尝试在支持 Tensorflow Lite 的移动设备上实现 ViDeNN,它将模型转换为更适合处理设备的更轻版本。这可能是新的发展和具有挑战性的调查问题,因为市场上可用的硬件每周都在改进。
文献
[14] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. In IEEE Transactions on Image Processing, volume 26, pages 3142–3155. 07 2017. 2, 3, 4, 5, 7, 8
[15] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings ofMachine Learning Research,volume 37, pages 448–456. 02 2015. 2
[38] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Dncnn matlab implementation on github, 2016.
4
[41] Xiph.org Video Test Media [derf’s collection]. 5, 6,
[31] Tobias Plotz and Stefan Roth. Benchmarking denoising algorithms with real photographs. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 07 2017.2, 4, 5, 8
[36] Kede Ma, Zhengfang Duanmu, Qingbo Wu, Zhou Wang, Hongwei Yong, Hongliang Li, and Lei Zhang. Waterloo Exploration Database: New challenges for image quality assessment models. volume 26, pages 1004–1016, 02 2017.4
[39] CBSD68 benchmark dataset. 4
[10] Matteo Maggioni, Giacomo Boracchi, Alessandro Foi, and Karen Egiazarian. Video denoising, deblocking, and enhancement through separable 4-d nonlocal spatiotemporal transforms. In IEEE transactions on image processing, volume 21, pages 3952–66. 05 2012. 1, 7, 8
[22] Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, and Lei Zhang. Toward convolutional blind denoising of real photographs, 07 2018. 2, 3, 5, 7, 8
[34] Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. Empirical evaluation of rectified activations in convolutional network. 2015. 2, 5
[35] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian. Color image denoising via sparse 3d collaborative filtering with grouping constraint in luminance-chrominance space. In 2007 IEEE International Conference on Image Processing, volume 1, pages I – 313–I – 316, 09 2007. 3, 5, 7, 8
k, and K. Egiazarian. Color image denoising via sparse 3d collaborative filtering with grouping constraint in luminance-chrominance space. In 2007 IEEE International Conference on Image Processing, volume 1, pages I – 313–I – 316, 09 2007. 3, 5, 7, 8


![[Android 13]Binder系列--获取服务](https://img-blog.csdnimg.cn/cb3b4b19308b4a6aa59abbdef3372f29.png#pic_center)