目录
💜💜1背景
❤️ ❤️2分析
🔥2.1config查看
🔥2.2BaseRunner基类
💚💚3解决
🔥3.1按照epoch
🔥3.2按照iters
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
💜💜1背景
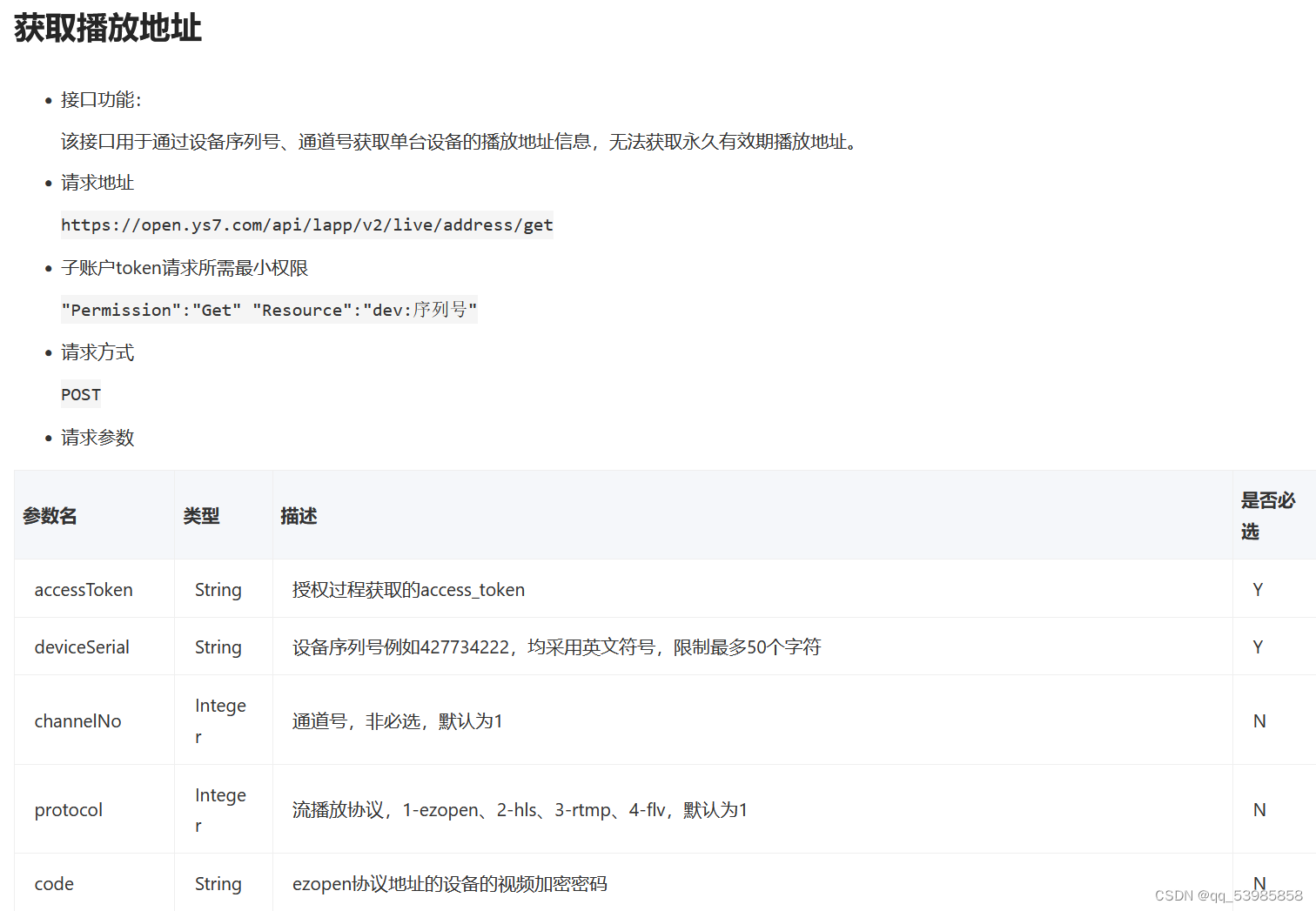
mmseg工程修改变化检测任务时,设置config文件时,运行报错ValueError: Only one of `max_epochs` or `max_iters` can be set.
详细报错信息如下:
fatal: Not a git repository (or any parent up to mount point /data)
Stopping at filesystem boundary (GIT_DISCOVERY_ACROSS_FILESYSTEM not set).
Traceback (most recent call last):File "/data/XX/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/utils/registry.py", line 69, in build_from_cfgreturn obj_cls(**args)File "/data/XX/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/runner/base_runner.py", line 136, in __init__raise ValueError(
ValueError: Only one of `max_epochs` or `max_iters` can be set.报错截图:

❤️ ❤️2分析
🔥2.1config查看
报错信息很明显就是说runner设置的有问题,通过打印出来的config信息看到:

runner = dict(type='EpochBasedRunner', max_iters=200, max_epochs=200)
这一句一看就不对,不能同时max_iters和max_epochs保留。
- 如果按照epoch来训练,删除掉max_iters=200即可;
- 如果按照inters来训练,删除掉max_epochs=200即可。
🔥2.2BaseRunner基类
mmcv中Runner类主要有三个:BaseRunner基类,以及继承于它的EpochBasedRunner类和IterBasedRunner类,顾名思义对应着Epoch和iter两种迭代方式。其中train、val、run、save_checkpoint方法由EpochBasedRunner和IterBasedRunner实现。
先快速看一下BaseRunner的构造函数:
def __init__(self,model,optimizer=None,work_dir=None,logger=None,meta=None,max_iters=None,max_epochs=None):………………self.model = modelself.optimizer = optimizerself.logger = loggerself.meta = meta# create work_dirif isinstance(work_dir,str):self.work_dir = osp.abspath(work_dir)mmcv.mkdir_or_exist(self.work_dir)elif work_dir is None:self.work_dir = Noneelse:raise TypeError('"work_dir" must be a str or None')if hasattr(self.model, 'module'): # 若经DataParallel包装,则获得内部的module名self._model_name = self.model.module.__class__.__name__else:self._model_name = self.model.__class__.__name__self.timestamp = utils.get_time_str() # 获得初始化时的时间戳self.mode = Noneself._hooks = [] # 就是保存hook类的list了self._epoch = 0 # 表示经过多少次train epoch,每经过一次train_epoch加1,val_epoch不加# 特别的IterBasedRunner也用IterLoader类维护了_epoch,每遍历完一次dataloader就加1# 比如workflow为[('train':1000,'val':200)],len(traindataloader)为100,那么会将经历10个epochself._iter = 0 # 表示经过多少次train iter,每经过一次train_iter加1,val_iter不加self._inner_iter = 0# 表示一个val epoch 或者 train epoch内,iter的次数# 经过一个val_iter或者train_iter都加1,经过一个epoch后就归零if max_epochs is not None and max_iters is not None:raise ValueError('Only one of `max_epochs` or `max_iters` can be set.') # 不能同时指定self._max_epochs = max_epochs # EpochBasedRunner看max_epochs,表示_epoch的最大值,即最多训练的epoch数量# 比如max_epochs为50,workflow为[('train',2),('val',1)]。那么将经过50/2=25次workflowself._max_iters = max_iters # IterBasedRunner看max_epochsself.log_buffer = LogBuffer() # 维护了一个字典,一到end of epoch 或者 经过n个iter,就把log_buffer写入日志,将由logger_hook处理可以从BaseRunner的定义可以看到,如果同时指定max_iters和max_epochs,就会报错“Only one of `max_epochs` or `max_iters` can be set.”
if max_epochs is not None and max_iters is not None:raise ValueError('Only one of `max_epochs` or `max_iters` can be set.') # 不能同时指定 因此找到了报错的源头,就能很好的解决了。跟我们发现的问题位置也是一样的,因此修改方案就是删除其中一种即可。![]()
💚💚3解决
🔥3.1按照epoch
修改config文件为:
runner = dict(type='EpochBasedRunner', max_epochs=200) checkpoint_config = dict(by_epoch=True, interval=1)这种epoch的计算方式表示总共的迭代轮数为200,保存模型是按照epoch进行模型保存,每1个epoch计算完保存一次模型。
这里要注意:如果你的baserunner定义为按照epoch计算的,那么下面的checkpoint_config最好也是按照epoch进行计算,每一轮或者每几轮都是通过interval参数进行设置的。如果baserunner定义为按照iters计算,那么最好checkpoint_config也与之保持一致。方便对比。
🔥3.2按照iters
或者修改为inters的计算方式。config代码如下:
runner = dict(type='ItersBasedRunner', max_epochs=20000) checkpoint_config = dict(by_epoch=False, interval=2000)这种iters的计算方式表示总共的迭代次数为20000,保存模型是按照iters进行模型保存,每2000次迭代保存一次模型。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷