☁️主页 Nowl
🔥专栏《机器学习实战》 《机器学习》
📑君子坐而论道,少年起而行之

文章目录
一、任务描述
二、数据集描述
三、主要代码
(1)主要代码库的说明与导入方法
(2)数据预处理
(3)模型训练
(4)模型预测与性能评估
(5)除数据预处理外的完整代码
四、本章总结
一、任务描述
手写数字识别是机器学习中的一个经典问题,通常涉及将手写数字的图像与其对应的数字进行关联。这种问题通常被认为是计算机视觉领域的一个入门任务,也是许多深度学习框架和算法的基础测试案例之一。

二、数据集描述

手写数字识别数据集包含了一列数字标签,每个数字标签有784个像素值,代表这个数字图片的像素值
三、主要代码
(1)主要代码库的说明与导入方法
import pandas as pd
pandas 是一个数据分析库,提供了灵活的数据结构,如 DataFrame,用于处理和分析结构化数据。它常被用于数据清洗、处理和分析。
import matplotlib.pyplot as plt
matplotlib 是一个用于绘制图表和可视化数据的库。pyplot模块是 matplotlib 的一个子模块,用于创建各种类型的图表,如折线图、散点图、直方图等。
import numpy as np
NumPy 是用于科学计算的库,提供了高性能的数组对象和各种数学函数。它在数据处理和数值计算中被广泛使用,尤其是在机器学习中。
import matplotlib as mpl
这里再次导入 matplotlib 库,但是这次将其别名设置为mpl。这样做是为了在代码中使用更短的别名,以提高代码的可读性。
from sklearn.model_selection import train_test_split
scikit-learn(sklearn)是一个用于机器学习的库。train_test_split函数用于将数据集划分为训练集和测试集,这是机器学习模型评估的一种常见方式。
from sklearn.neighbors import KNeighborsClassifier
这里导入了 scikit-learn 中的KNeighborsClassifier类,该类实现了 k-近邻分类器,用于进行基于邻近样本的分类。
from sklearn.metrics import accuracy_score
从 scikit-learn 中导入accuracy_score函数,用于计算分类模型的准确度分数。准确度是分类模型预测的正确样本数占总样本数的比例。
为确保代码能正常运行,请先复制以下代码,导入本文用到的所有库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score当代码无法运行时,还有可能是文件路径问题,注意改成自己的文件路径
(2)数据预处理
1.导入数据
使用pandas库导入数据集文件,文件路径要换成自己的
digit = pd.read_csv("datasets/digit-recognizer/train.csv")2.划分训练集与测试集
使用train_test_split函数将数据集分为训练集和测试集,测试集比例为0.2
再将特征和标签分离出来
train, test = train_test_split(digit, test_size=0.2)train_x = train.drop(columns="label")
train_y = train["label"]
test_x = test.drop(columns="label")
test_y = test["label"]3.图片显示
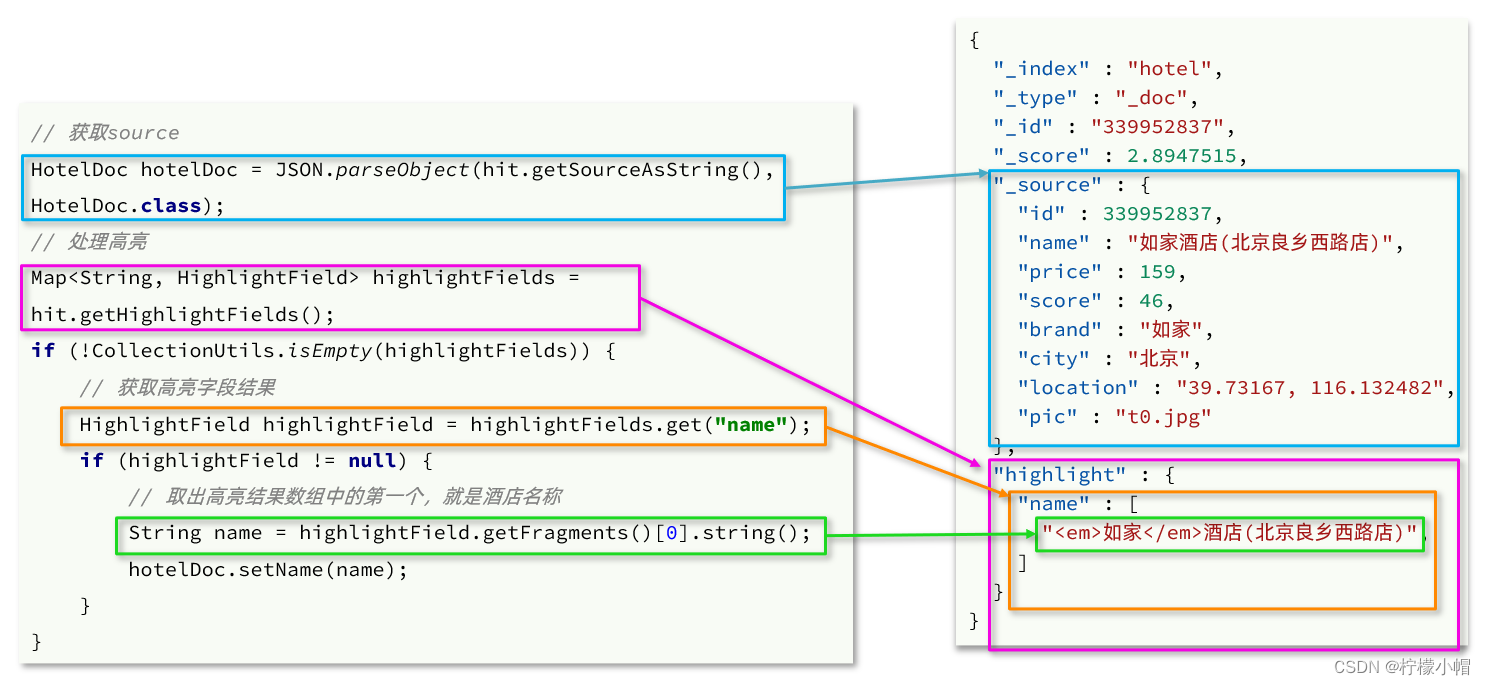
我们可以使用matplotlib库将图片显示出来
- train_x.iloc[2]选取训练集的第3行数据
- np.array()将数组转化为numpy数组,以便使用reshape函数
- .reshape(28,28)将原来的784个特征转化为(28,28)格式的数据,这代表一个正方形图片
- cmap=mpl.cm.binary使图片颜色为黑白
- plt.imshow()函数可以将一个像素数组转化为图片
plt.imshow(np.array(train_x.iloc[2]).reshape(28, 28), cmap=mpl.cm.binary)
plt.show()
print(train_y.iloc[2])显示图片并打印数据标签
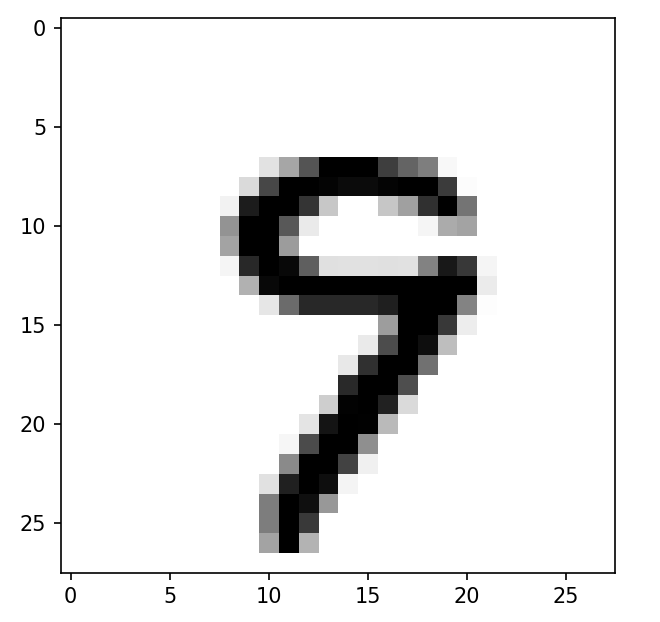
我们可以看到图像是一个数字9,打印标签也确实是9,接下来我们就来训练一个数字识别机器学习模型
(3)模型训练
由于这是一个分类任务,我们可以选择使用KNN近邻算法,第一步设置模型,第二步训练模型
model = KNeighborsClassifier(n_neighbors=3)
model.fit(train_x, train_y)(4)模型预测与性能评估
寻找最优参数
对于大部分机器学习模型来说,设置不同的参数得到的模型性能都不同,我们可以绘制不同参数的准确率曲线图来寻找最优参数
accuracy = []for i in range(1, 10):model = KNeighborsClassifier(n_neighbors=i)model.fit(train_x, train_y)prediction = model.predict(test_x)accuracy.append(accuracy_score(prediction, test_y))print()plt.plot(range(1, 10), accuracy)
plt.xlabel("neighbors")
plt.ylabel("accuracy")
plt.show()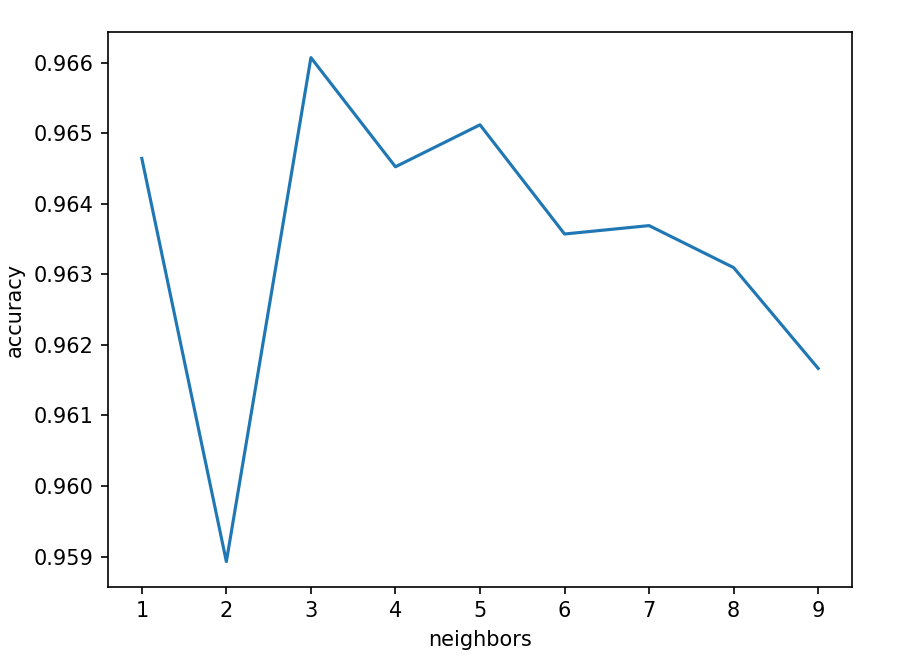
可以看到当neighbors为3时模型效果最好,我们在应用时就将模型参数设置为3
(5)除数据预处理外的完整代码
这里是舍弃了一些寻找特征等工作的完整模型训练代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_scoredigit = pd.read_csv("datasets/digit-recognizer/train.csv")train, test = train_test_split(digit, test_size=0.2)train_x = train.drop(columns="label")
train_y = train["label"]
test_x = test.drop(columns="label")
test_y = test["label"]model = KNeighborsClassifier(n_neighbors=3)
model.fit(train_x, train_y)
prediction = model.predict(test_x)
print(accuracy_score(prediction, test_y))四、本章总结
- 学习了使用numpy处理图像数据的方法
- 学习了打印准确率曲线来寻找最优参数的方法
- 使用KNN模型来完成分类任务
当然,也可以自己处理特征,自己选择模型,调整参数,看看会不会获得更好的结果
感谢阅读,觉得有用的话就订阅下本专栏吧