基于Python的网络爬虫设计与实现
摘要:从互联网时代开始,网络搜索引擎就变得越发重要。大数据时代,一般的网络搜索引擎不能满足用户的具体需求,人们更加注重特定信息的搜索效率,网络爬虫技术应运而生。本设计先对指定URL的网址相关网页进行分析,找出网页内目标信息所在的URL信息规律;然后选择BeautifulSoup模块或lxml的html模块编写函数分级爬取这些URL;最后将URL对应的网页中的信息归类保存到文本文件中。然后利用jieba模块基于TF-IDF指标对爬取的文本中的信息进行分析,再找出词频高的词,做进一步分析。基于Python实现网络爬虫程序,先对我校近几年新闻网页进行分析,找出新闻中的高频词,并绘制词云图;然后针对这次新型冠状病毒所造成的疫情,从腾讯新闻网中爬取疫情相关信息,同时根据相关信息绘制疫情分布图。两个爬虫实例表明本设计的可行性和有效性。
关键词:网络爬虫,互联网,校园,疫情
Design and implementation of web crawler based on Python
Abstract:Since the Internet era, Internet search engines have become more and more essential. In period of big data, common network search engines cannot satisfy the exact needs of users, People attach importance to the search efficiency of specific information, and web crawler technology emerge as the times require. This design first analyzes the URL related web pages of the specified URL to find out the URL information rule of the target information in the web page; then select the beautiful soup module or the HTML module of lxml to write the function to crawl these URLs hierarchically; finally, the information in the web pages corresponding to the URL is classified and saved in the text file. Then use the jeeba module to analyze the information in the crawled text based on TF IDF index, and then find out the words with high word frequency for further analysis. Based on Python, novel coronavirus is first analyzed. We find out the high frequency words in the news and draw the word cloud map. Then, in response to the epidemic situation caused by novel coronavirus, this design crawled the epidemic situation related information from Tencent News Network and drew the epidemic situation distribution map according to the related information. Two crawler examples show the feasibility and effectiveness of the design.
Keywords:Crawler, Internet, campus, epidemic situation
目 录
第1章 绪 论 1
1.1研究背景和实际意义 1
1.2研究现状 1
1.3研究方法和内容 2
1.3.1 研究方法 2
1.3.2 研究内容 2
第2章 基于Python的网络爬虫技术的相关方法 3
2.1网页分类 3
2.1.1静态网页 3
2.1.2动态网页 3
2.2正则表达式 3
2.3中文分词 4
2.4 词云图生成 5
2.5 数据管理 6
2.6 BeautifulSoup 6
第3章 基于Python的校园网新闻信息获取与分析 7
3.1 基于Python的校园网新闻信息爬虫实现 7
3.1.1 网页信息获取 10
3.1.2 版块新闻链接列表搜索 11
3.1.3版块新闻网页新闻内容获取 13
3.2 基于Python的校园网新闻信息分析实现 14
3.2.1新闻信息数据管理 15
3.2.2新闻内容文本分词 17
3.2.3停用词删除 17
3.2.4高频词词云制作 18
3.2.4新闻内容词语分析 19
第4章 基于Python的新型冠状病毒疫情爬虫实现 21
4.1 每日疫情数据获取及曲线图绘制 21
4.1.1 每日疫情数据爬取程序现实 21
4.1.2 每日疫情数据曲线图绘制程序现实 23
4.2 各地疫情数据获取及曲线图绘制 25
4.2.1 各地疫情数据爬取程序现实 26
4.2.2 各地疫情当前数据曲线图绘制程序现实 28
第5章 总 结 31
参考文献 32
致谢 33
第1章 绪 论
1.1研究背景和实际意义
21世纪初起,互联网得到了蓬勃的发展,万维网成为海量信息的载体,人们希望能够有效利用万维网里的数不胜数的数据信息,所以网络信息提取成为这一愿望实现的关键。网络世界里的信息成千上万,特别是近年来信息量呈指数增长,人们更加注重从互联网上搜索自己想要信息的效率。
人们开始运用搜索引擎来帮助自己在互联网中查找所需要的信息。但是一个一般的搜索引擎必然存在着一定的局限性,不同背景、不同深度、不同领域的用户检索的期望信息一定是不同的,互联网用户只想快速找到自己所需求的信息,但一般的搜索引擎返回的搜索结果包含了庞大的无效信息。通用搜索引擎在一般情况下不能提供精准且专业的信息搜索,同时查准率低、无效信息多、也无法避免广告推送。因此一般的搜索引擎不可能满足特定用户的专业需求,对于这特等的用户需求则需要更加准确的搜素引擎,在大量的需求下,网络爬虫的技术得以快速发展。
网络爬虫技术是一种个性化互联网数据信息搜索的网络数据信息获取技术。网络爬虫的英文名称为Web Spider。互联网就像一张巨大且密集的蜘蛛网,Spider这只蜘蛛就在这张网上不断移动。一个生动形象的比喻就是蜘蛛(Web Spider)通过网线的颤抖(网页的链接地址)来搜寻食物(网页)。从任意一个网页(一般情况下是首页)开始,读取网页中数据,从这个网页里搜索其它链接的地址,通过所找的链接地址去找下一个网页。按照这种方式不断循环,直到所选取的网站里全部的网页全部抓取完为止。假定我们把整个互联网比喻成一个网站,网络蜘蛛就可以运用上述方法把互联网中一切的网页都抓取下来。在用户专业性需求下,网络爬虫程序可以在指定网页页面搜索需要的相关信息,而过滤掉其他繁杂的冗余信息,并通过程序对搜索到的信息进行归类保存。
大数据时代的到来,意味着更多信息涌入,想要在互联网这片大海中捞到想要的东西也愈发困难,所以网络爬虫的意义就是越显重要。能够帮助我们节省时间和精力,同时也能确保我们找到我们想要的东西。在这个节奏越来越快的世界中,网络爬虫凭借这高效这一点,就有着无穷的意义与价值。
1.2研究现状
在上世纪九十年代在麻省理工学院一位叫Matthew 的老师就研发出第一款有文献记载的爬虫。爬虫作为核心的搜索引擎技术已经历经近30年的发展,网络爬虫已日趋多样。为满足不同用户不同的需求,人们开发了类型繁多的爬虫。但爬虫技术在西方世界迅速发展的情况下,2004年前我国内基本对于网络爬虫技术没有什么关注,从2005年开始国内才开始关注爬虫技术。目前需求量也是也来越大,急需这方面人才。
目前爬虫也只能分为两大类,一类为Google之类的大型搜索引擎的大型爬虫,另一类就是个人型爬虫或中型爬虫。网络爬虫开源系统喷涌式出现,因此人们研发一个简单的抓取系统变得不再困难,但是由于大量程序开源,使得很少有人愿意潜心研究网络爬虫的关键技术。因此在这种不良的环境下,小型爬虫系统质量不高。所以对于中小爬虫的发展还是任重道远。
1.3研究方法和内容
1.3.1 研究方法
网络爬虫应用宽度搜索技术,对URL进行分析,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。网络爬虫还要完成信息提取任务,对于抓取回来的网页进行筛选、归类。
在学习使用Python软件的同时,复习网络知识,进而掌握基于Python软件的网络爬虫程序编写方法。
本设计拟对我校近几年新闻网页(www.sontan.edu.cn)进行分析,获取相关网页URL及网页文本内容,然后利用jieba模块基于TF-IDF指标对爬取的文本信息进行分析,找出新闻中的高频词,并绘制词云图。
同时针对今年对我国发生的新型冠状病毒肺炎疫情,利用动态网页获取方法从腾讯新闻网站(view.inews.qq.com)下载疫情分析数据,并绘制疫情相关图。
1.3.2 研究内容
本设计具体内容安排如下:
第1章:介绍网络爬虫的历史背景和实际现状,阐述了本设计所使用的爬虫技术,简单描述了本设计的两个实际应用的实现。
第2章:介绍一些基于Python的网络爬虫的相关方法。
第3章:校园网新闻信息获取的程序介绍,分析和运行结果的图片展示。
第4章:新型冠状病毒疫情爬虫的程序介绍,分析和运行结果的图片展示。
第5章:总结。
第2章 基于Python的网络爬虫技术的相关方法
2.1网页分类
互联网里众多网页主要将其分为静态和动态。当然静态是相对于动态而言的,比不是说静态就是一点不会变动的。
2.1.1静态网页
在网站设计中,纯粹HTML(标准通用标记语言下的一个应用)格式的网页通常被称为“静态网页”,静态网页是标准的HTML文件,它的文件扩展名是.htm、.html,可以包含文本、图像、声音、FLASH动画、客户端脚本和ActiveX控件及JAVA小程序等。静态网页是网站建设的基础,早期的网站一般都是由静态网页制作的。
2.1.2动态网页
动态网页 URL的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形动态网页制作格式,而是以.aspx、.asp、.jsp、.php、.perl、.cgi等形式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。 动态网页一般以数据库技术为基础,可以大大降低网站维护的工作量,采用动态网页技术的网站可以实现更多的功能,如用户注册、用户登录、在线调查、用户管理、订单管理等等。同时动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器才返回一个完整的网页。
不只有HTML代码写出的网页被称为动态网页,这些网页一般由CSS,JavaScript代码和HTML代码一起构成网页,它们用Ajax动态加载网页的数据不一定出现在HTML代码中,这就需要复杂的操作。
2.2正则表达式
正则表达式概念:是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。其实就是一种规则。有自己特殊的应用。是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
正则表达式的特点是:
- 灵活性、逻辑性和功能性非常强。
- 可以迅速地用极简单的方式达到字符串的复杂控制。
re模块使 Python 语言拥有全部的正则表达式功能。比如:
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.search 扫描整个字符串并返回第一个成功的匹配。
re.compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
re.findall 方法能够以列表的形式返回能匹配的子串
2.3中文分词
中文分词,即 Chinese Word Segmentation,将一个汉字序列进行切分,得到一个个单独的词。表面上看,分词其实就是那么回事,但分词效果好不好对信息检索、实验结果还是有很大影响的,同时分词的背后其实是涉及各种各样的算法的。
中文分词主要应用于信息检索、汉字的智能输入、中外文对译、中文校对、自动摘要、自动分类等很多方面。下面就以信息检索为例来说明中文分词的应用。例如:“制造业和服务业是两个不同的行业”和“我们出口日本的和服比去年有所增长”中都有“和服”,而被当作同一类来处理,结果是检索“和服”的相关信息,会将他们都检索到,在信息量少的情况下,似乎还能够忍受,如果是海量信息,这样的结果就会令人讨厌了。通过引入分词技术,就可以使机器对海量信息的整理更准确更合理,在“制造业和服务业是两个不同的行业”中“和服”不会被当做一个词来处理,那么检索“和服”当然不会将它检索到,使得检索结果更准确,效率也会大幅度的提高。所以中文分词的应用会改善我们的生活,使人们真正体会到科技为我所用。
从排序里取出预定前N个最优文本特征作为原始语料文本特征子集。基于词频和逆文档频率的TF-IDF算法是一种十分流行的文本特征选取算法。
对于文档的特征词,其在文档中出现的总次数为;文档中出现的词的总数为;表示语料库中文档总数;表示包含词语的文档总数。
TF和IDF分别为词频和逆文档频率,TF-IDF是一种常用的加权指标,多用于信息检索与数据挖掘。基于TF-IDF的特征选择思想是:如果某个词在某篇文章中出现的频率很高,在其他文章中出现的频率相对较低,那么就说明这个词在这篇文档中比较重要,即可作为这篇文章的一个分类特。
公式中,表示包含词语的文档总数,如果不在语料库中,则分母项为0,因此一般情况下使用作分母,一般用IDF平滑后的公式:
词频表示词语在文档中相对于语料库所有文件的出现概率,该词在文档中出现次数越高,值就越大;逆文档频率则用另一种形式表示相反的情况,反应包含词语的文档相对于语料库所有文档出现的逆概率,包含该词的文档出现的次数越多,逆文档频率值越低。
某词语在某特定文件内的高词频,以及其在整个文件集合中的低逆文档频率,可以得出较高的值。基于指标可以过滤掉语料库文档中普遍出现的词语,保留在某些文档中出现频次较高的具有丰富分类特性的重要词语(后文简称特征词)。
2.4 词云图生成
在现在互联网信息时代,我们能在各种手机app或计算机网页上看见各式各样的词云图,词云图可以帮助我们从庞大且杂乱的信息中提取出现概率最高的词,让使用者更加清楚且直观的看到有效信息。词云库把词云当作一个对象,WordCloud()是一个文本中与其相对的词云。本设计依据词语出现频率高低的来绘制图片,同时设定词云图的大小、样式、颜色等。
wordcloud = WordCloud(“simhei.ttf”,)
fontpath=‘simhei.ttf’#字体
aimask=np.array(Image.open(“wordpic.png”))#导入图像数据
wc = WordCloud(font_path=fontpath, # 设置字体路径
background_color=“white”, # 背景颜色
max_words=1000, # 词云显示的最大词数
max_font_size=100, # 字体最大值
min_font_size=10, #字体最小值
random_state=42, #随机数
collocations=False, #避免重复单词
max_words=200 #要显示的词的最大个数
mask=aimask, #造型遮盖
width=1200,height=800,margin=2, #图像宽高,字间距,需要配合下面的plt.figure(dpi=xx)放缩才有效)
word_frequence = {x[0]:x[1] for x in words_count.head(50).values}# words_count前50行数据,即词频前50的词汇
word_cloud=wc.fit_words(word_frequence)#根据词频生成词云
plt.figure(dpi=50) #通过这里可以放大或缩小
plt.axis(“off”) #隐藏坐标
plt.imshow(word_cloud)
2.5 数据管理
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表 DataFrame函数是创建一个二维表,传入参数,是所存放的数据。
2.6 BeautifulSoup
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器。BeautifulSoup最主要的功能是从网页抓取数据。
soup = BeautifulSoup(article_doc, ‘html.parser’)
利用BeautifulSoup模块的find_all()函数搜索新闻信息。将相关信息按指定顺序存入文本文件。
soup = BeautifulSoup(list_page, ‘html.parser’) #利用BeautifulSoup模块
利用标签a的两个属性(href和class)找该对应的链接条件
第3章 基于Python的校园网新闻信息获取与分析
依照用户设定的规则获取互联网网页中的文字,图片或者一切内容的一组程序或脚本就是网络爬虫,网络爬虫的重要作用简单来说就是让互联网网页的内容下载到本地从而本地有了一个镜像备份。时至今日互联网爆炸的时代,几乎所有网页都会提供给互联网网民们大量的信息,但是这些庞大的数据中大部分都是用户不需要的,就算是专门搜索或者在相关的主题网页中,想要找到用户心仪的信息也是十分困难的。在庞大的数据下需要互联网用户一个一个去鉴别,这是十分费心费力的一件事。所以,就可以专门设计一个符合用户需求主题的爬虫进行精准搜索,方便快捷地获取用户需要的数据。主题网络爬虫就完美的符合用户需要。高网速大数据的今天,主题网络爬虫在Web应用中的地位将越发重要甚至是不可代替。
网络爬虫第一步选择爬取对象的链接地址(即URL),将URL放置在待爬取的队列里;第二步从待抓取URL队列里读取一条URL接着进行DNS解析,下载网页内容;第三步分析网页内容,从中搜索符合特定要求的数据,并按指定格式保存;第四步对数据进行分析处理。
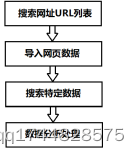
图1 本章网络爬虫和数据处理流程
本章首先利用利用网络爬虫技术从我校校园网的校园新闻和综合新闻两个版块下载、搜索新闻;然后对新闻进行分词处理,分析其中新闻高频词。
编程中用到ThreadPool模块、requests模块、BeautifulSou模块、DataFrame模块、WordCloud模块以及Python的内置os模块、re模块、pandas模块和numpy模块。
3.1 基于Python的校园网新闻信息爬虫实现
利用网络爬虫技术从我校校园网的校园新闻(网址:‘https://www.sontan.edu.cn/CampusNews/list’)和综合新闻(网址:‘https://www.sontan.edu.cn/news/GeneralNews/list_SubjectId_15’)两个主页下载相关新闻网址链接表。利用request模块从每个新闻链接中下载新闻并按指定格式保存到文件中。
图2是以校园新闻版块为例的信息爬取流程图。综合新闻版块新闻爬取方式相同。设计中利用ThreadPool模块将两个版块主页网址输入ThreadPool对象的map函数,由系统并行搜索两个版块的新闻信息。代码如下:
两个新闻版块爬取链接
FILE_CONFIGS = [[‘https://www.sontan.edu.cn/CampusNews/list’, ‘xyxw’, ‘news/xyxw/’],
[‘https://www.sontan.edu.cn/news/GeneralNews/list_SubjectId_15’, ‘zhxw’, ‘news/zhxw/’], ]
pool = ThreadPool()
pool.map(main, FILE_CONFIGS)
pool.close()#关闭进程池(pool),使其不再接受新的任务
pool.join()#主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
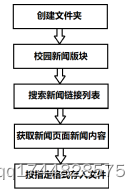
图2 校园新闻版块信息爬取流程图
根据流程,编写主函数main()程序。偌
max_file=300 #最大文件数
requests请求头
HEADERS = {
‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8’,
‘accept-encoding’: ‘gzip, deflate, br’,
‘accept-language’: ‘zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7’,
‘Connection’: ‘close’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit’
‘/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36’#爬虫浏览器
}
CODE = ‘UTF-8’ #全局默认编码
def main(config):
url = config[0] #信息链接地址URL
file_name = config[1] #文件名
dir_path = config[2] #文件夹
file_num = 0
mkdir(dir_path) #创建文件夹
doc = get_html(url+‘.html’) #获取每类别的网址网页内容
if doc != ‘’:
total_page = get_total_page(doc) #当前网页总编号
for i in range(total_page): #遍历所有页
page = i+1
list_page_url = url + ‘page{page}.html’.format(page=page) #获取该类其中一页的链接
list_doc = get_html(list_page_url) #获取该类其中一页的页面信息
if list_doc != ‘’:
if file_name==‘xyxw’:
ftype=1;#校园新闻
else:
ftype=2;#综合新闻
article_urls = get_article_urls(list_doc,ftype) #提取该类其中一页中各个链接
for article_url in article_urls:
article_doc = get_html(article_url) #提取每类每个页面中的信息
if article_doc != ‘’: #将爬取信息中特定信息存入文件中
file_path = dir_path + file_name + str(file_num) + ‘.txt’
flag = save_article(article_doc, article_url, file_path) #按指定格式存入文件
if flag:
file_num += 1
print(‘保存%s类第%d个文件’%(file_name,file_num))
if file_num > max_file:
#每类信息最多保存500个文件
break
if file_num > max_file:
break
本设计实现爬取的关键程序流程图如图3
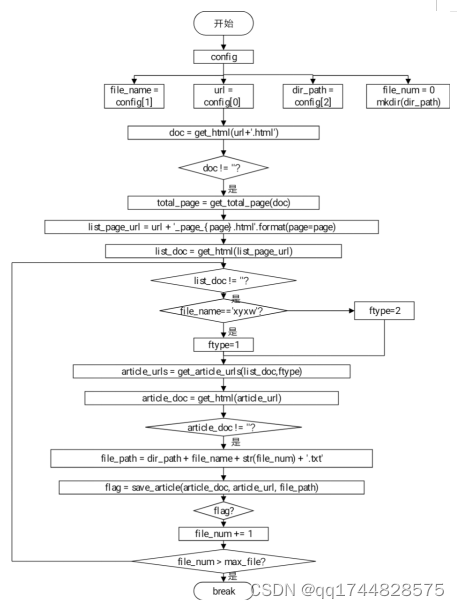
图3
3.1.1 网页信息获取
利用reqests模块获取指定网址URL的页面信息。设置了最大重试次数为3次,如果3次请求目标URL都失败则抛出异常。对于请求返回的状态码为200的响应,将以字符串的形式返回请求到的页面HTML代码。具体代码如下:
def get_html(url):
doc = ‘’
try:
session = requests.session()#开启会话,可以跨请求保持某些参数
session.mount(‘https://’, HTTPAdapter(max_retries=3))
request = requests.get(url=url, headers=HEADERS, timeout=30)#根据网址和HEADERS请求
session.close()#关闭会话
request.close()#关闭请求
if request.status_code == 200:
request.encoding =“utf-8”
doc=request.text
except RequestException as e:
print(‘无法获取文件信息’)
return doc
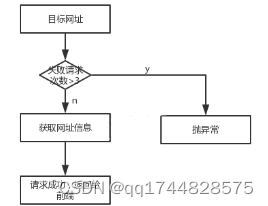
图4 网页信息获取流程图
3.1.2 版块新闻链接列表搜索
利用BeautifulSoup模块和re模块从校园新闻和综合新闻两个版块主页中获取总页数和各自的子网页链接地址列表。
每个版块总页数只需要用re模块的findall()函数,找到其中匹配的参数即可。代码如下:
def get_total_page(doc): #从doc字符串中提取出页码和总页数
regex = ‘共有(\d*?)页’
result = re.findall(regex, doc, re.DOTALL)[0] #寻找匹配括号里(.?)和(\d?)的内容
total_page = int(result)#总页数
return total_page
版块子网页链接地址列表用BeautifulSoup模块的find_all()函数,利用标签a的两个属性(href和class)找该对应条件的链接地址。具体代码如下:
def get_article_urls(list_page,ftype): #获取链接地址列表
if ftype1:#校园新闻
base_url =‘https://www.sontan.edu.cn’
else: #综合新闻
base_url =‘https://www.sontan.edu.cn/news’
soup = BeautifulSoup(list_page, ‘html.parser’) #利用BeautifulSoup模块
#利用标签a的两个属性(href和class)找该对应的链接条件
if ftype1:#校园新闻
urls_tree=soup.find_all(‘a’,href=re.compile(‘/CampusNews/’), class_=‘dot’)
else: #综合新闻
urls_tree=soup.find_all(‘a’,href=re.compile(‘/GeneralNews/’), class_=‘dot’)
article_urls = []
for url in urls_tree:
url = url.get(‘href’)
if url.startswith(‘http’): #以http开头的字符串(即链接地址)
article_urls.append(url) #追加链接地址
else:
article_urls.append(base_url + url) #不以http开头的字符串,则基地址+链接
return article_urls
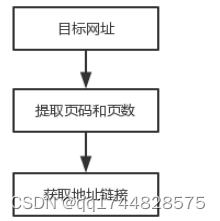
图5 地址链接流程图
3.1.3版块新闻网页新闻内容获取
用re模块的findall()函数搜索新闻标题和发布日期,利用BeautifulSoup模块的find_all()函数搜索新闻信息。将相关信息按指定顺序存入文本文件。具体代码如下:
def save_article(article_doc, article_url, file_path):
try:
regex = ‘
(.?)
’title = re.findall(regex, article_doc, re.DOTALL)[0] #寻找h1标签的内容,即文章的标题
regexd ='
发布日期:(.?)
’datas=re.findall(regexd, article_doc, re.DOTALL)[0] #寻找日期
soup = BeautifulSoup(article_doc, ‘html.parser’) #利用BeautifulSoup模块
elements=soup.find_all(‘p’,style=re.compile(‘text-indent:2em;’))#找新闻信息
content = ‘’
if len(elements) > 0:
for element in elements:#遍历
element = str(element.text)#获取每一簇信息
para = del_space(element)#自定义的删除空格函数,在后面
content += para
with open(file_path, ‘w’, encoding=CODE) as f: #按指定顺序写入文件
f.write(datas + ‘\n’)#首段:发布日期
f.write(title + ‘\n’)#第二段:信息头
f.write(content + ‘\n’)#第三段:信息主题
f.writelines(article_url)#最后一段:信息的链接地址
return True
except IndexError:
print(‘无法保存文件’)
return False
def del_space(string): #去除中文之间的空格 保留英文之间的空格
string = string.strip() #移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
pattern = re.compile(r’([\u4e00-\u9fa5]+)\s+([\u4e00-\u9fa5]+)\s+‘) # ‘\s’用于匹配空白字符
string = pattern.sub(r’\1\2’, string)
return string
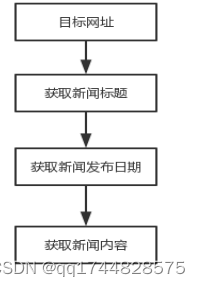
图6 获取新闻流程图
3.2 基于Python的校园网新闻信息分析实现
针对3.1节利用网络爬虫技术获取的校园新闻和综合新闻两个版块的相关新闻信息文件,将新闻文字进行数据管理、分词、停用词删除、统计和制作词云等操作(如图3所示)。
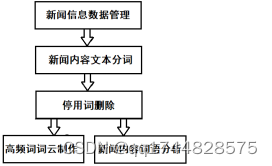
图7 校园新闻版块信息分析流程图
3.2.1新闻信息数据管理
校园新闻和综合新闻两个版块所在文件夹内的所有文本文件数据进行收集处理,按类别、 标题、日期和内容进行管理。先将字符串生成字典,再将文件存为DataFrame格式。
具体代码如下:
def text_processing(folder_path):
folder_list = os.listdir(folder_path) # 查看folder_path的子文件夹
for folder in folder_list: # 遍历每个子文件夹
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #放子文件夹下的txt文件的列表
kind = ‘’
if folder==‘xyxw’:
kind=‘校园新闻’
else:
kind=‘综合新闻’
for file in files: # 读取合并文章数据
path = os.path.join(new_folder_path, file)
data = [kind]
with open(path, mode=‘r’, encoding=CODE) as f:
for line in f:
#读取每一段,顺序将与DataFrame列名对应
data.append(line.strip())
data_dict = dict(zip(COLUMNS, data)) #用zip()函数根据键字进行排序
df_news = DataFrame(data_dict, index=[0]) #DataFrame类的方法,将键字作为列名
df_news.to_csv(‘news_docu.txt’, index=False, header=False, mode=‘a+’, encoding=CODE)
#读取出文件中的数据,以COLUMNS,为列名
df_docs = pd.read_csv(‘news_docu.txt’, names=COLUMNS, encoding=CODE)
# 数据清洗:如果某条数据有缺失值(na数据) 直接删除整条数据
df_docs = df_docs.dropna()
return df_docs
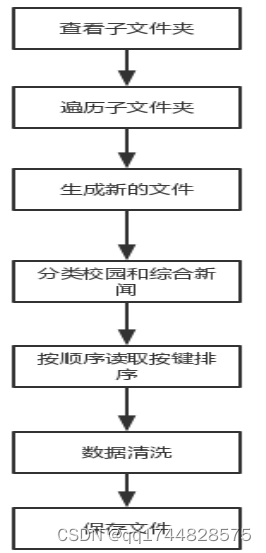
图8 数据管理流程图
3.2.2新闻内容文本分词
新闻内容处理的基础是“词”,这些“词”必须有实际意义的写。利用开源的分词器——jieba分词器对新闻内容分词。jieba支持基于TF-IDF算法选择关键词。
利用jieba分词器对3.2.1得到的数据‘content’列进行分词。代码如下:
def split_word(df_docs):
content = df_docs[‘content’].values.tolist()# jieba 分词需要list格式
content_s = []
for line in content:
current_segment = jieba.lcut(line) #分词,返回列表
if len(current_segment) > 1 and current_segment != ‘\n’: # 换行符
content_s.append(current_segment) #追加
return content_s
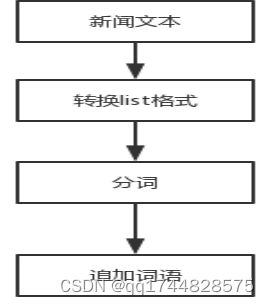
图9 分词流程图
3.2.3停用词删除
对3.2.3得到的分词进行过渡,将其中“停用词”删除。
利用已有的停用词表删除分词中的停用词,保留有效的有实际意义的词。代码如下:
def drop_stopwords(content_s):
stopwords = pd.read_csv(“./files/stopwords.txt”, index_col=False, sep=“\t”, quoting=3, names=[‘stopword’], encoding=‘utf-8’)
stopwords = stopwords.stopword.values.tolist() #转换为list类型
contents_drop = []# 记录去除停用词后出现的词
all_words = []
for line in content_s:
line_clean = []
for word in line:
if word in stopwords:#判断是停用词则不追加
continue
line_clean.append(word) #判断不是停用词,则追加
all_words.append(str(word)) #判断不是停用词,则以字符串形式追加,用于词云
contents_drop.append(line_clean) #追加该行“有效词”
make_wordcloud(all_words) #制作词云图
return contents_drop
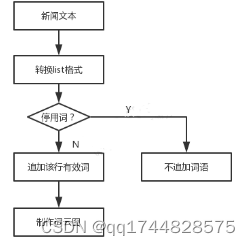
图10 停用词流程图
3.2.4高频词词云制作
针对3.2.2得到的新闻信息中的分词,利用DataFrame类型数据的padas方法进行分析统计,再利用开源库WordCloud绘制50个高频词词云图。
具体代码如下:
def make_wordcloud(all_words):
cy_num=50#词图中的最高频的词条数
df_all_words = pd.DataFrame({‘all_words’: all_words})#由列表生成DataFrame数据
#先分组all_words,再分类统计计数size,通过分组计数,统计每个词出现的次数
words_count = df_all_words.groupby(by=[‘all_words’])[‘all_words’].agg(numpy.size)
words_count = words_count.to_frame() #每个词的词频转换为DataFrame类型,列名为all_words
words_count.columns = [‘count’] #将每个词的词频数据words_count列名换为count
#以count列降序排列
words_count = words_count.reset_index().sort_values(by=[“count”], ascending=False)
# 设置词云图片参数,生成词云对象
wordcloud = WordCloud(font_path=“./files/simhei.ttf”, background_color=“white”, max_font_size=80)
word_frequence = {x[0]: x[1] for x in words_count.head(cy_num).values}
wordcloud = wordcloud.fit_words(word_frequence)#根据词频生成词云图数据
wordcloud.to_file(‘wordcloud_songtian.png’)#生成词云图
print(‘\n根据新闻中词频最高的{num}个词制作的词云图:’.format(num=cy_num))
plt.imshow(wordcloud)
plt.axis(“off”)
plt.show()

图11 校园新闻信息高频词词云图
从图4中可以看出“工作”、“学院”、“松田”、“学生”、“教育”等词在近期的新闻信息中出现频率极高。
3.2.4新闻内容词语分析
针对某一新闻页面内的有效新闻信息进行分析,利用jieba.analyse.extract_tags方法基于TF-IDF算法从中选取指定数量的关键词。具体代码如下:
def word_seq(df_docs, contents_drop,index):
c_num=5#高频
print(‘以下是第{index}号记录的内容及其高频词\n’.format(index=index))
print(df_docs[‘content’].values.tolist()[index]) #index记录号的内容
print(‘\n网址:’+df_docs[‘url’].values.tolist()[index]) #index记录号的网址
content_s_str = “”.join(contents_drop[index]) #index记录号的内容分词
#利用jieba第三方库提取#index记录号内容的分词,显示前topK= c_num个
print(‘\n以下是第{index}号记录的内容中词频最高的{c_num}的词:’.format(index=index,c_num=c_num))
print(" ".join(jieba.analyse.extract_tags(content_s_str, topK=c_num, withWeight=False)))
程序运行结果图如图12:
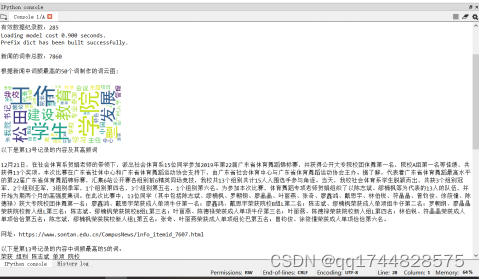
图12
第4章 基于Python的新型冠状病毒疫情爬虫实现
针对今年对我国发生的新型冠状病毒肺炎疫情,利用动态网页获取方法从腾讯的新闻网站(view.inews.qq.com)下载疫情数据,将数据归类统计,并绘制疫情数据曲线图。
为导入疫情数据,对数据进行分析和图形绘制,先导入requests、json、time、datetime、pandas、matplotlib.pyplot和matplotlib.dates模块包。
新型冠状肺炎病毒疫情数据爬取目标网站是腾讯新闻,该网站提供疫情实时追踪数据。
4.1 每日疫情数据获取及曲线图绘制
如图6所示,先request.get()方法从腾讯新闻公布疫情新闻数据所在的网址url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_cn_day_counts&callback=&_=%d’%int(time.time()*1000)中爬取数据;再利用json.loads()方法将数据转换为易于操作的字典类型;然后利用pd.DataFrame()方法将爬取来的数据形成每日疫情二维数据。
图13 每日疫情数据爬取流程
4.1.1 每日疫情数据爬取程序现实
根据每日疫情数据爬取流程图,导入requests、json、time、datetime和pandas模块包,编写程序如下:
url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_cn_day_counts&callback=
&_=%d’%int(time.time()*1000) #数据动态网址
data = json.loads(requests.get(url=url).json()[‘data’]) #爬取的数据
data.sort(key=lambda x:x[‘date’]) #以键字date升序排列
data_day=pd.DataFrame(columns=[‘日期’,‘确诊数’,‘疑似数’,‘治愈数’,‘死亡数’])
#创建数据二维表,指定列名
loc=0
#初始化变量
date_list = list() # 日期
confirm_list = list() # 确诊
suspect_list = list() # 疑似
dead_list = list() # 死亡
heal_list = list() # 治愈
for item in data:
loc+=1
month, day = item[‘date’].split(‘/’)#获取月和日期
rq=datetime.strptime(‘2020-%s-%s’%(month, day), ‘%Y-%m-%d’)#获取日期
qz=int(item[‘confirm’])#确认数
ys=int(item[‘suspect’])#疑似数
zy=int(item[‘heal’])#治愈数
sw=int(item[‘dead’])#死亡数
date_list.append(rq)
confirm_list.append(qz)
suspect_list.append(ys)
dead_list.append(sw)
heal_list.append(zy)
data_day.loc[loc]=[rq,qz,ys,zy,sw]#将数据为一行
运行程序得到date_list、confirm_list、suspect_list、dead_list、heal_list和data_day数据。
下面图14是运行结果:
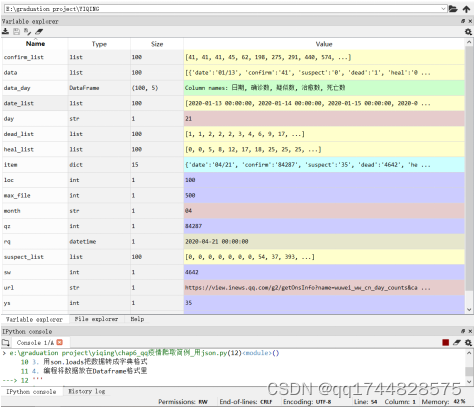
图14
4.1.2 每日疫情数据曲线图绘制程序现实
基于4.1.1程序爬取的数据包,导入matplotlib.pyplot和matplotlib.dates模块包,编写每日疫情数据曲线图绘制程序如下:
plt.figure(‘2020-每日疫情统计图表’, facecolor=‘#f4f4f4’, figsize=(10, 8)) #前景,图尺寸
plt.title(‘2020-每日疫情曲线’, fontsize=20) #图标题
plt.plot(date_list, confirm_list, label=‘确诊数’) #绘制确诊数
plt.plot(date_list, suspect_list, label=‘疑似数’)
plt.plot(date_list, heal_list, label=‘治愈数’)
plt.plot(date_list, dead_list, label=‘死亡数’)
plt.rcParams[‘xtick.direction’] = ‘in’ #把刻度线设置在图的里面
plt.xticks(date_list,date_list,color=‘black’,rotation=90, size = 10) #横轴内容
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter(‘%m-%d’)) #横轴格式
plt.grid(linestyle=‘:’) #显示网格
plt.legend(loc=‘best’) #显示图例
plt.savefig(‘2020-每日疫情曲线.png’) #保存为文件
图15 绘制流程图
运行上述程序,得到如图16的2020-每日疫情曲线图。
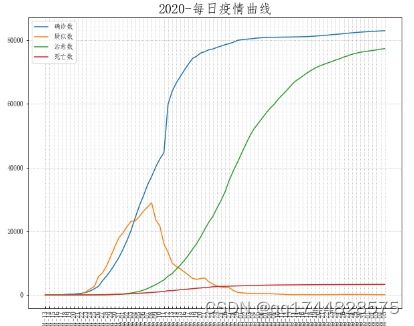
图16
每日疫情曲线图横纵坐标分为’日期’,纵坐标为患者数量(‘确诊数’,‘疑似数’,‘治愈数’,‘死亡数’)。由兰色曲线可知从3月份全国确诊数上升很慢;2月到4月绿色治愈数曲线上升很快;红色死亡数曲线在确诊数上升期延后10上升较快,后趋于平稳,表明医疗技术的作用显现;黄色疑似数曲线在3月份是高峰,随之下降。
从图中看出从一月二十四至二十五号开始,确诊数和疑似数开始猛增。二月八号开始疑似数开始明显下降,治愈数显著升高。可见一月二十四号至二月八号是抗战疫情最为激烈的时期,二月二十九号开始确诊数开始明显降低,说明疫情逐渐得到控制,专家们所说的拐点即将到来。从图表中我们也可看出至四月份死亡数没有明显增长,代表着抗击疫情一线的英雄们的成果和伟大。
从曲线图可知,未来几日全国治愈数将接近确诊数。
4.2 各地疫情数据获取及曲线图绘制
如图17所示,先request.get()方法从腾讯新闻公布疫情新闻数据所在的网址url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&_=%d’%int(time.time()*1000)中爬取数据;再利用json.loads()方法将数据转换为易于操作的字典类型;然后利用pd.DataFrame()方法将爬取来的数据形成各地疫情二维数据。
图17 各地疫情数据爬取流程
4.2.1 各地疫情数据爬取程序现实
根据各地疫情数据爬取流程图,导入requests、json、time、datetime和pandas模块包,编写程序如下:
url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&_=%d’%int(
time.time()*1000)
data_toal=json.loads(requests.get(url=url).json()[‘data’])
data_area=data_toal[‘areaTree’]
#国内各省市分布
data_china_sf=pd.DataFrame(columns=[‘省份’,‘确诊数’,‘疑似数’,‘治愈数’,‘死亡数’])
data_china_ds=pd.DataFrame(columns=[‘地市’,‘确诊数’,‘疑似数’,‘治愈数’,‘死亡数’])
data_ch=data_area[0][‘children’]
loc=0
loc_ds=0
for item in data_ch:
#省级统计
loc+=1
sf=item[‘name’]
qz=int(item[‘total’][‘confirm’])
ys=int(item[‘total’][‘suspect’])
zy=int(item[‘total’][‘heal’])
sw=int(item[‘total’][‘dead’])
data_china_sf.loc[loc]=[sf,qz,ys,zy,sw]#获取各省份的数据
#地市统计
data_ds=item[‘children’]
for item_ds in data_ds:
sf=item_ds[‘name’]
if sf not in ‘地区待确认’:
loc_ds+=1
qz=int(item_ds[‘total’][‘confirm’])
ys=int(item_ds[‘total’][‘suspect’])
zy=int(item_ds[‘total’][‘heal’])
sw=int(item_ds[‘total’][‘dead’])
data_china_ds.loc[loc_ds]=[sf,qz,ys,zy,sw]#获取各地市的数据
运行程序得到data_china_sf和data_china_ds数据。
运行结果如下图18:
图18
4.2.2 各地疫情当前数据曲线图绘制程序现实
基于4.2.1程序爬取的当日数据包,导入matplotlib.pyplot和matplotlib.dates模块包,编写每日疫情数据曲线图绘制程序如下:
plt.figure(‘2020-各省市疫情统计图表’, facecolor=‘#f4f4f4’, figsize=(15, 8))
plt.title(‘2020-各省市疫情曲线’, fontsize=30)
xtk=list(data_china_sf.iloc[:,0])
xz=list(range(len(xtk)))
plt.plot(xz,data_china_sf.iloc[:,1],label=‘确诊数’)
plt.plot(xz,data_china_sf.iloc[:,2],label=‘疑似数’)
plt.plot(xz,data_china_sf.iloc[:,3],label=‘治愈数’)
plt.plot(xz,data_china_sf.iloc[:,4],label=‘死亡数’)
plt.xticks(xz, xtk,color=‘black’,rotation=90)
plt.savefig(‘2020-各省市疫情曲线.png’) # 保存为文件
#绘制各地市疫情统计图
plt.figure(‘2020-各地市疫情统计图表’, facecolor=‘#f4f4f4’, figsize=(100, 8))
plt.title(‘2020-各地市疫情曲线’, fontsize=20)
xtk=list(data_china_ds.iloc[:,0])
xz=list(range(len(xtk)))
plt.plot(xz,data_china_ds.iloc[:,1],label=‘确诊数’)
plt.plot(xz,data_china_ds.iloc[:,2],label=‘疑似数’)
plt.plot(xz,data_china_ds.iloc[:,3],label=‘治愈数’)
plt.plot(xz,data_china_ds.iloc[:,4],label=‘死亡数’)
plt.xticks(xz, xtk,color=‘black’,rotation=90)
plt.savefig(‘2020-各地市疫情曲线.png’) # 保存为文件
运行上述程序,得到如图19和图20的2020-国内当日各省市疫情曲线图和2020-国内当日各地市疫情曲线图。
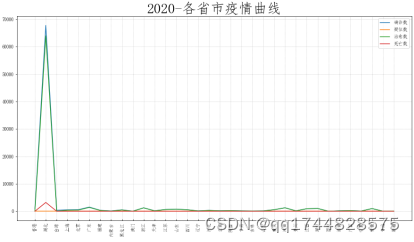
图19 2020-国内当日各省市疫情曲线图
由上图抓取各省疫情图可知,在举国之力的努力下,经过武汉和全国封禁后,我国疫情控制情况良好,没有多点爆发的情况出现。
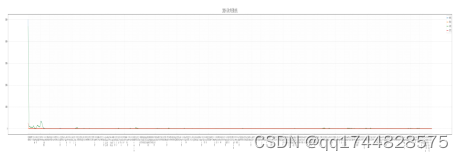
图20 2020-国内当日各地市疫情曲线图
从各地市当日疫情曲线图可看出,湖北武汉确实是疫情爆发的中心,封禁湖北武汉为无奈之举,但确实是必行之法。
第5章 总 结
本设计运用网络爬虫算法设计编写了爬虫系统程序,并爬取了广州大学松田学院校园网(https://www.sontan.edu.cn)的校园新闻和综合新闻两个版块的相关新闻信息文件和腾讯新闻网(view.inews.qq.com)的动态网页获取疫情数据信息,进行处理分类,将数据归类统计分析,并绘制词云图和疫情数据曲线图。从过程与结果来看,网络爬虫能够改善互联网用户搜索信息的体验与感官,减少不必要的信息摄入,节省上网搜索时间,高速提取互联网中的有效信息,从而增加工作效率。
参考文献
[1]王蕾, 安英博, 刘佳杰. 基于Python的互联网金融数据采集[J]. 合作经济与科技, 2017(9).
[2] 舒畅, 黎洪生. 使用Python实现基于Web的水资源监测系统[J]. 武汉理工大学学报(信息与管理工程版), 2006, 28(5):38-40.
[3] 刘洪志. 利用Python批量获取互联网中的桌面壁纸[J]. 电脑编程技巧与维护, 2014(21).
[4] 李培. 基于Python的网络爬虫与反爬虫技术研究[J]. 计算机与数字工程, 2019(6).
[5] 王芳, 张睿, 宫海瑞. 基于Scrapy框架的分布式爬虫设计与实现[J]. 信息技术, 2019(3).
[6] 周海晨. 基于爬虫与文本挖掘的“985”高校图书馆微信公众号的调研[D]. 安徽大学, 2017.
[7] 魏冬梅, 何忠秀, 唐建梅. 基于Python的Web信息获取方法研究[J]. 软件导刊, 2018(1):41-43.
[8]任迪, 万健, 殷昱煜,等. 基于贝叶斯分类的Web服务质量预测方法研究[J]. 浙江大学学报(工学版), 2017, 51(6):1242-1251.
[9] 徐荣飞. Python正则表达式研究[J]. 电脑编程技巧与维护(9):47+51.
[10] 邱清盈, 郑国民, 冯培恩, et al. 基于正则表达式的专利信息提取方法研究[J]. 中国机械工程, 2007, 18(19):2326-2329.
[11] Nurul Afiqah Mat Zaib, Nor Erne NaziraBazin, NoorfaHaszlinnaMustaffa,等. Integration of system dynamics with big data using python: An overview[C]// 2017 6th ICT International Student Project Conference (ICT-ISPC). IEEE, 2017.
[12]Jacob McPadden, Thomas JS Durant, Dustin R Bunch,等. A Scalable Data Science Platform for Healthcare and Precision Medicine Research (Preprint)[J]. Journal of Medical Internet Research, 2018, 21(4).
致谢
时光荏苒,大学四年的学习生活即将结束,四年间的回忆仿佛还在眼前,老师们的教诲与指引,辅导员们的帮助与开导,同学的鼓励与支持,父母的期望与赞许,这些都会让我积极进步。大学四年时光我是快乐和充实的,自己很幸运能结识这么多的良师益友,希望祖国繁荣强大,师长们身体健康,同学们前程似锦,感谢自己人生路上的每一个人。