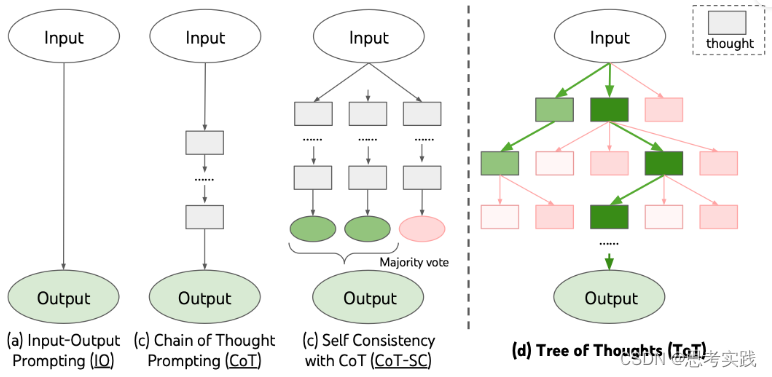
论文题目:
A Joint Network Based on Interactive Attention for Speech Emotion Recognition
作者列表:
胡英,侯世静,杨华敏,黄浩,何亮
研究背景
语音情感识别(Speech Emotion Recognition,SER)指通过让机器检测和识别人类语音信号中如喜悦、愤怒、悲伤、惊讶、恐惧等多种情感类别。为了适用于如客服对话等说话人身份是不重要因素的真实场景,即避免说话人的特征影响语音情感识别的结果,进一步研究说话人无关设置下的语音情感识别任务变得非常必要[1]。且在语音情感识别研究领域,带有注释的大数据集很难获得,现有的小数据集可能包含偏差,在说话人无关设置下这些数据集上训练得到模型可能无法很好的泛化。
本文方案
在本文中提出了一个单独频谱模型和一个结合了预训练模型和频谱模型语音情感识别联合网络。首先设计一个频谱模型提取到语音情感的特性表征,再通过Wav2Vec2.0[2]预训练模型学习到语音的共有表征。通过设计不同的交互注意力模块将两个中间特征进行融合,更好地利用音频信息。并设计多分支训练策略对联合网络进行优化。在说话人无关设置下取得良好的实验结果。
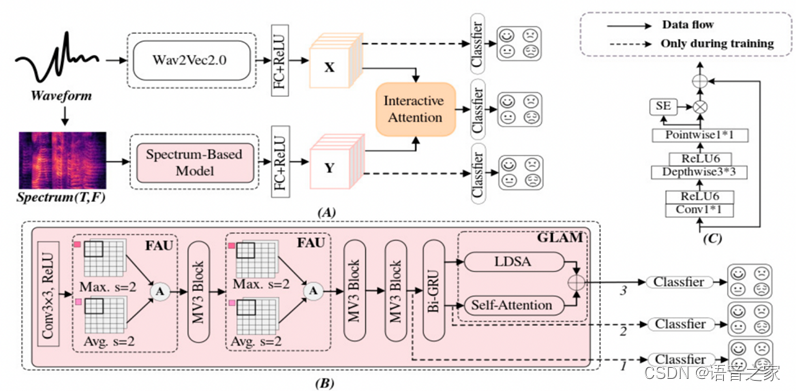
图1. 本文提出的SER框架。(A)联合网络,(B)基于频谱的模型,(C)MobileNetV3(MV3) 模块
基于频谱的模型:将音频信号经过预处理得到的对数梅尔谱图作为输入特征,经过卷积神经网络以及特征聚合单元[3]提取情感相关的语义特征,继而通过Bi-GRU及全局-局部注意力模块得到语音情感相关的特性特征。
Wav2Vec2.0预训练模型:在大规模无标签的数据集上通过自监督学习从原始语音中学习到语音的一个共有表征,通过微调方式迁移到语音情感识别任务上。
联合网络:在上述两个单支路语音情感识别模型基础上提出了一个联合网络,如图二所示,将从预训练模型和基于频谱的模型中得到的共性特征和特性特征通过不同交互注意力模块[4]融合,更好地利用语音中的情感信息。
多分支训练策略:在联合网络的训练阶段中采用了多分支训练策略[5],从预训练模型和基于频谱的模型得到的共性特征和特性特征𝑌,以及经过交互注意力模块融合得到的融合特征都分别通过一个分类器产生语音情感识别预测,在测试阶段只有联合网络通过线性层进行情感识别分类。
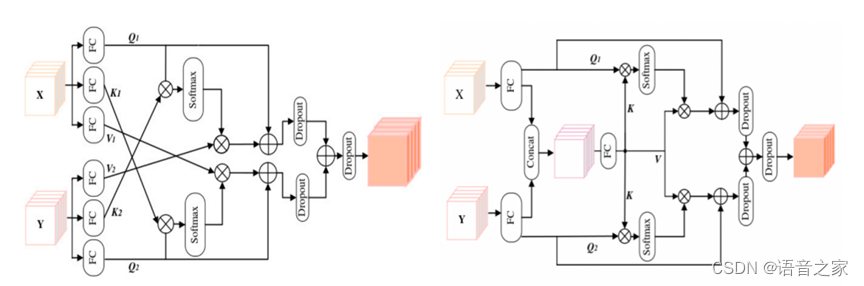
图2. 两种不同的交互注意力模块
实验结果分析
实验使用了IEMOCAP数据集对上述提出的联合网络进行训练和测试。表1可以看出提出的单分支频谱模型在说话人相关的设置下优于其他四种基于频谱的算法。并进一步进行消融实验,验证了特征聚合单元、全局-局部注意力、多阶段训练策略的有效性。
表1. 说话人相关设置下对基于频谱的模型与主流的四种算法进行比较及消融实验
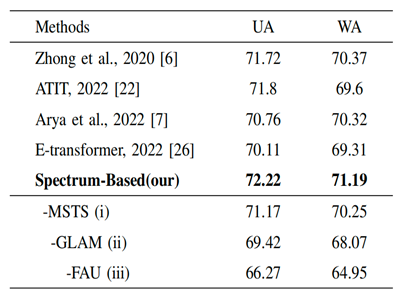
表2将基于频谱的模型在说话人相关和无关设置下进行比较,可得在说话人无关的设置下,UA和WA分别较说话人相关设置下降低了11%左右。为了应用于说话人特征是不重要因素的实际场景中,在之后实验中选择说话人无关设置。
表2. 说话人相关和无关设置下基于频谱的模型的性能比较(无 MSTS)
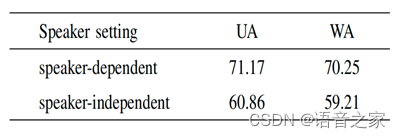
表3上半部分为在说话人无关设置下将Wav2Vec2.0预训练模型作为特征、微调Wav2Vec2.0预训练模型以及微调Hubert 预训练模型迁移到语音情感识别上进行比较,验证选择微调Wav2Vec2.0预训练模型的有效性。下半部分为验证交互注意力模块IAM2优于IAM1以及多分支训练策略的有效性。
表3. 说话人无关设置下单支模型性能评估以及联合网络中IAM和MBTS的消融实验

表4为说话人无关设置下将联合网络与四种仅利用语音的单模态方法和两种利用语音和文本的双模态方法进行了比较,可得本文提出的联合网络在单模态方法中表现最佳,与多模态算法也有一定的可比性。
表4. 说话人无关设置下对联合网络和其他主流六种算法评估

小结
本文提出了一种单分支的基于频谱的SER模型和结合预训练和基于频谱模型的联合网络,并设计了不同的交互关注模块融合联合网络的两个单分支模型的中间特征。而且采用多分支训练策略优化联合网络。为了更好地应用于实际应用场景,本文在说话人无关的设置下进行了实验,验证了语音情感识别联合网络的优越性。
参考文献
[1] Zou H, Si Y, Chen C, et al. Speech emotion recognition with co-attention based multi-level acoustic information[C]//International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022: 7367-7371.
[2]Baevski A, Zhou Y, Mohamed A, et al. wav2vec 2.0: A framework for self-supervised learning of speech representations[J]. Advances in neural information processing systems, 2020, 33: 12449-12460.
[3] Peng Z, Lu Y, Pan S, et al. Efficient speech emotion recognition using multi-scale cnn and attention[C]//International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 3020-3024.
[4] Tang Y, Hu Y, He L, et al. A bimodal network based on Audio–Text Interactional-Attention with ArcFace loss for speech emotion recognition[J]. Speech Communication, 2022, 143: 21-32.
[5] Hu Y, Chen Y, Yang W, et al. Hierarchic temporal convolutional network with cross-domain encoder for music source separation[J]. IEEE Signal Processing Letters, 2022, 29: 1517-1521.