本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在Pytorch:
Pytorch(2)---《MNIST手写数字识别》
MNIST手写数字识别
目录
一、 实验目的
二、 实验内容
2.1 MNIST数据集介绍
2.2 代码解析
三、运行结果
一、 实验目的
掌握利用卷积神经网络CNN实现对MNIST手写数字的识别。一个简单的神经网络实验
二、 实验内容
2.1 MNIST数据集介绍
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。官方下载网站:http://yann.lecun.com/exdb/mnist/,下载得到的数据集一共包含4个文件,训练集、训练集标签、测试集、测试集标签。
type Markdown and LaTeX: α2α2
直接下载得到的数据集是无法通过普通的解压或者应用程序打开的,因为这些文件不是任何标准的图像格式而是以字节的形式进行存储的,所以必须编写相关程序将其打开。
而torchvision.datasets包中已经包含MNIST数据集,可以通过在编译器中输入代码进行数据集的获取,步骤如下:
Step1:归一化,softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
Step2:下载/获取数据集,其中root为数据集存放路径,train=True即训练集否则为测试集。 train_dataset = datasets.MNIST(root='./data/', train=True, download=False, transform=transform) # train=True训练集,=False测试集 test_dataset = datasets.MNIST(root='./data/', train=False, download=Falese, transform=transform) # download=True表示可自动下载,此处=False表示直接从本地导入
Step3:实例化一个dataset后,然后用Dataloader 包起来,即载入数据集。这里的batch_size为超参数;shuffle=True即打乱数据集,这里我们打乱训练集进行训练,而对测试集进行顺序测试。 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
可以按照上述尝试下载数据集,但本次实验过程为节约时间,可直接导入本地下载好的数据集,本地保存相对路径为:root='./data/'
2.2 代码解析
首先导入运行过程中需要的文件包:
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim"""
卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential
添加载入测试集数据
"""
# Super parameter ------------------------------------------------------------------------------------
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 10
# Prepare dataset ------------------------------------------------------------------------------------
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差train_dataset = datasets.MNIST(root='./data/', train=True, download=False, transform=transform)
# download=False加载本地数据集,否则自动下载;train=True训练集,=False测试集
#从本地导入,transform的方式与训练集数据一致
test_dataset = datasets.MNIST(root='./data/', train=False, download=True, transform=transform) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) #shuffle=True 表示数据集打乱
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)展示MNIST数据集
这里举例展示12幅图,包含图片内容和标签。
fig = plt.figure()
for i in range(12):plt.subplot(3, 4, i+1)plt.tight_layout()plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')plt.title("Labels: {}".format(train_dataset.train_labels[i]))plt.xticks([])plt.yticks([])
plt.show()
构建CNN网络模型
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Sequential(torch.nn.Conv2d(1, 10, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)# 第二层卷积核维度是[10, 20, 5 ,5], 输入通道是10, 输出通道是20, 卷积核大小是 5*5, (默认padding=0, stride = 1)# 第二层的激活函数是Relu# 第二层池化层: 采用的是MaxPooling, 大小是2*2.self.conv2 = torch.nn.Sequential(torch.nn.Conv2d(10, 20, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.fc = torch.nn.Sequential(torch.nn.Linear(320, 50),torch.nn.Linear(50, 10),)def forward(self, x):batch_size = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x)return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)# 实例化模型:
model = Net()
# 损失函数和优化器损失函数 使用交叉熵损失参数优化使用随机梯度下降
# Construct loss and optimizer ------------------------------------------------------------------------------
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量模型训练
Step1:前馈(forward propagation)
Step2:反馈(backward propagation)
Step3:更新(update)
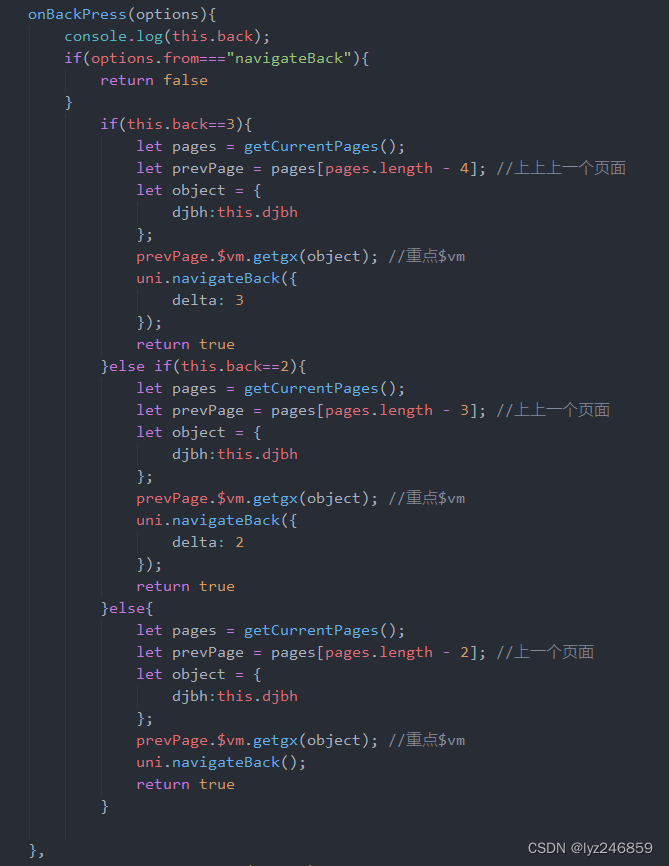
def train(epoch):running_loss = 0.0 # 这整个epoch的loss清零running_total = 0running_correct = 0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()# forward + backward + updateoutputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()# 把运行中的loss累加起来,为了下面300次一除running_loss += loss.item()# 把运行中的准确率acc算出来_, predicted = torch.max(outputs.data, dim=1)running_total += inputs.shape[0]running_correct += (predicted == target).sum().item()if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率print('[%d, %5d]: loss: %.3f , acc: %.2f %%'% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))running_loss = 0.0 # 这小批300的loss清零running_total = 0running_correct = 0 # 这小批300的acc清零torch.save(model.state_dict(), './model.pth') #保存模型参数torch.save(optimizer.state_dict(), './optimizer.pth') #保存优化器参数测试轮
测试集不用算梯度(无需反馈),首先从test_loader中读取每一次的图片和标签,进行前馈运算后,预测每一轮的准确率
测试轮代码
def test():model.eval()correct = 0total = 0with torch.no_grad(): # 测试集不用算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标total += labels.size(0) # 张量之间的比较运算,表示预测标签的所有次数correct += (predicted == labels).sum().item() #标签预测准确的次数# acc表示标签预测的准确率,即预测准确次数除以预测标签的所有次数,acc的计算代码公式acc = correct/totalprint('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数return acc开始训练
超参数:用到的超参数主要有小批量数据的batch size,梯度下降算法中用到的学习率(learning rate)和冲量(momentum),同时定义进行10轮次的训练。 主函数:共进行10轮次的训练:每训练一轮,就进行一次测试。
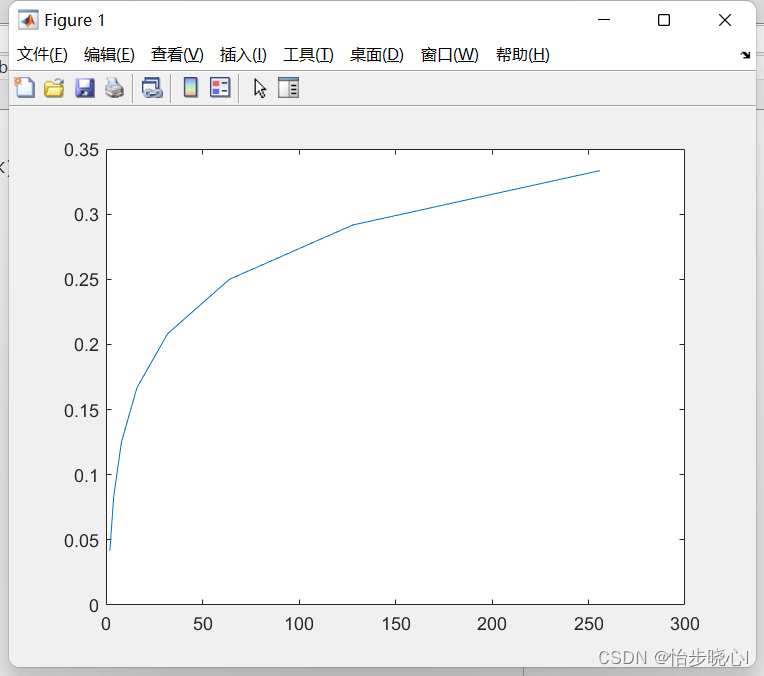
if __name__ == '__main__':acc_list_test = [] #创建保存测试数据的列表for epoch in range(EPOCH):train(epoch)# if epoch % 10 == 9: #每训练10轮 测试1次acc_test = test()#接下来需要把每次的测试结果即acc_test,添加到列表acc_list_test中acc_list_test.append(acc_test)plt.plot(acc_list_test)plt.xlabel('TEST-EPOCH')plt.ylabel('Accuracy On TestSet')plt.show()三、运行结果

文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。