目录
1.并查集
1.结构
2.原理
3.代码实现
1.存储
2.寻找根节点
3.是否为同一集合
4.求集合个数
5.合并为同一集合中
整体代码
2.图
1.基本知识
1.各个属性
2.特殊名词
3.图的解释
2.图的表示
1.邻接矩阵
2.邻接表
3.图的遍历
1.BFS--广度优先遍历
2.DFS--深度优先遍历
1.并查集
定义:n个元素被划分在不相交的集合中,一旦出现某几个元素可以形成一个相同的集合内,那么此时就会被该结构放入同一个集合内.该集合的好处就是当需要查询就能得到某个元素是属于哪个集合中.
1.结构
其实无非就是用于记载是否存在在哪个集合中,那么只需要有一个能存储某个位置对应的集合,而位置是唯一的,那么每一个位置其实就已经代表特定的元素.
1.为了表示存储元素的位置,那么就需要一个vector
2.每个位置对应的元素,那么只需要hash表即可表示特定的元素的特定下标
2.原理
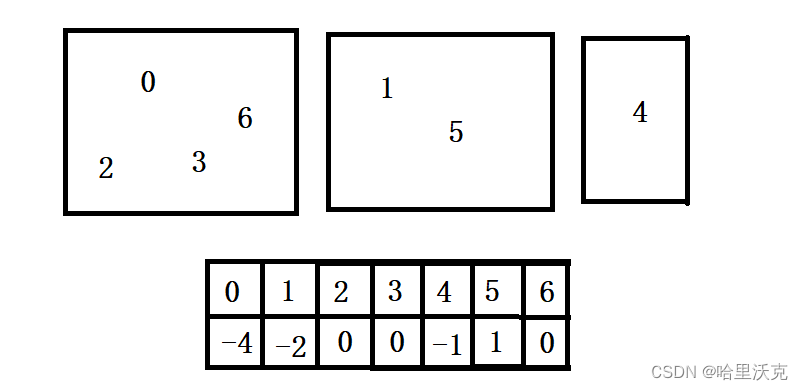
1.其实我们可以把并查集表示为森林
2.如果下标对应的元素为正数,则表示和元素对应下标的元素为同一集合;如果下标对应的元素为负数,表示当前为森林的顶端
3.如果我们已经知道每个下标代表的意义,那么不需要哈希表进行表示.如果需要对下标进行解析,可以使用hash对元素和下标进行映射
3.代码实现
1.存储
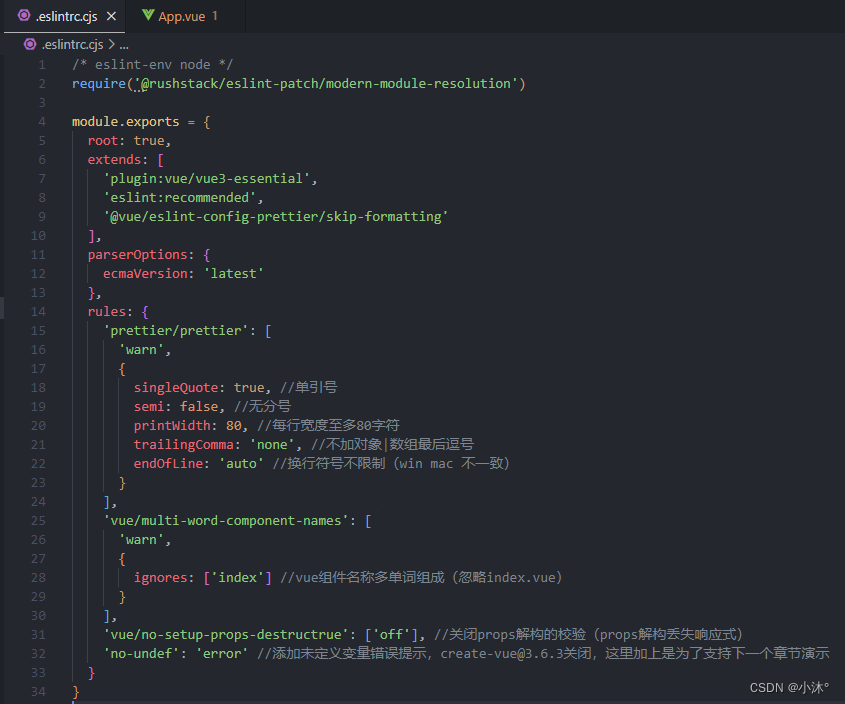
class UnionFindSet { private:vector<int> _ufs; public:UnionFindSet(size_t n):_ufs(n, -1){} }1.先设置一个vector
2.构造时,需要多少元素就设置多少,并且初始化为-1,表示当前的元素独立
2.寻找根节点
int FindRoot(int x) {int root = x;while (_ufs[root] >= 0)root = _ufs[root];while (_ufs[x] >= 0){int parent = _ufs[x];_ufs[x] = root;x = parent;}return root; }我们知道循着元素下标往上找就能找到我们需要的根节点并且实现压缩数据
3.是否为同一集合
bool InSet(int x1, int x2) {return FindRoot(x1)== FindRoot(x2); }对比二者的根节点是否相同即可
4.求集合个数
size_t SetSize() {size_t size = 0;for (size_t i = 0; i < _ufs.size(); i++){if (_ufs[i] < 0) size++;}return size; }只需要根节点就可以了,根节点的特点就是元素为负数,那么只需要遍历vector,计算负数的个数就可以了.
5.合并为同一集合中
void Uinon(int x1, int x2) {int root1 = FindRoot(x1);int root2 = FindRoot(x2);if (root1 == root2) return;if (abs(_ufs[root1]) < abs(_ufs[root2])) swap(root1, root2);_ufs[root1] += _ufs[root2];_ufs[root2] = root1; }1.找到两个元素对应的根节点,如果根节点相同则不需要结合
2.如果不相同,我们需要将数据量小的合并到数据量大的去
3.那么当前root1就是小的下标._ufs[root1] += _ufs[root2]表示当前的root1为根节点时的所有元素个数,_ufs[root2] = root1将root2的下标记作root1
整体代码
class UnionFindSet { private:vector<int> _ufs; public:UnionFindSet(size_t n):_ufs(n, -1){}void Uinon(int x1, int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);if (root1 == root2) return;if (abs(_ufs[root1]) < abs(_ufs[root2])) swap(root1, root2);_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}int FindRoot(int x){int root = x;while (_ufs[root] >= 0)root = _ufs[root];while (_ufs[x] >= 0){int parent = _ufs[x];_ufs[x] = root;x = parent;}return root;}bool InSet(int x1, int x2){return FindRoot(x1)== FindRoot(x2);}size_t SetSize(){size_t size = 0;for (size_t i = 0; i < _ufs.size(); i++){if (_ufs[i] < 0) size++;}return size;} };
2.图
1.基本知识
1.各个属性
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V,E)
1.顶点集合:V = {x|x属于某个数据对象集}是有穷非空集合
2.边集合:E = {(x,y)|x,y属于V}或者E={<x, y>|x,y属于V&&Path(x, y)}是顶点间关系的有穷集合.3.图的种类可分为:有向图和无向图
2.特殊名词
1.完全图:每一个顶点都互相有一个边联通的叫完全图。[其中在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图]
2.邻接顶点:两个顶点通过一个边可互相抵达的。[在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联]
3.顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。[在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)]
4.路径:在图G = (V, E)中,两顶点可经过若干边抵达的,就叫路劲。若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
5.路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和
3.图的解释
1.简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路径;若路径上第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环。
2.子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图
3.连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图4.强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图是强连通图
5.生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
2.图的表示
1.邻接矩阵
1.适合存储非常稠密的图
2.邻接矩阵可以O(1)判断两个顶点之间的连接关系
3.一个点的所有边不方便找
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph{public://图的创建 -- 1.IO 2.关系放在文件中 3.手动添加边Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; ++i){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_matrix.resize(n);for (size_t i = 0; i < n; ++i){for (size_t j = 0; j < n; ++j){_matrix.resize(n, MAX_W);}}}size_t GetVertexIndex(const V& v){auto it = _indexMap.find(v);if (it == _indexMap.end()){throw invalid_argument("顶点不存在");return -1;}else{return it->second;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);_matrix[srci][dsti] = w;if (Direction == false){_matrix[dsti][srci] = w;}}void Print(){// 打印顶点和下标映射关系for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl;cout << " ";for (size_t i = 0; i < _matrix.size(); i++){cout << i << " ";for (size_t j = 0; j < _matrix[0].size(); j++){if (_matrix[i][j] == MAX_W)cout << "* ";elsecout << _matrix[i][j] << " ";}cout << endl;}cout << endl;}private:vector<V> _vertexs; //保存顶点map<V, int> _indexMap; //顶点与下标映射vector<vector<W>> _matrix; //邻接矩阵}; }2.邻接表
1.适合比较稀疏的图
2.适合找到一个顶点的所有边
3.不适合判断两个顶点之间的连接关系
namespace link_table {template<class W>struct Edge{int _dsti; //目标点下标W _w; //权值Edge<W>* _next;Edge(int dsti,const int w):_dsti(dsti),_w(w),_next(nullptr){}};template<class V, class W, bool Direction = false>class Graph{typedef Edge<W> Edge;public:Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; ++i){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_table.resize(n, nullptr);}size_t GetVertexIndex(const V& v){auto it = _indexMap.find(v);if (it == _indexMap.end()){throw invalid_argument("顶点不存在");return -1;}else{return it->second;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);//srci->dstiEdge* eg = new Edge(dsti, w);eg->_next = _table[srci];_table[srci] = eg;//无向图 dsti->srciif (Direction == false){Edge* eg = new Edge(srci, w);eg->_next = _table[dsti];_table[dsti] = eg;}}void Print(){// 打印顶点和下标映射关系for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl;for (size_t i = 0; i < _table.size(); i++){cout << _vertexs[i] << "[" << i << "]->";Edge* cur = _table[i];while (cur){cout << "{" << _vertexs[cur->_dsti] << "[" << cur->_dsti << "]" << cur->_w << "}->";cur = cur->_next;}cout << "{nullptr}" << endl;}}private:vector<V> _vertexs; //保存顶点map<V, int> _indexMap; //顶点与下标映射vector<Edge*> _table; //邻接表}; }3.图的遍历
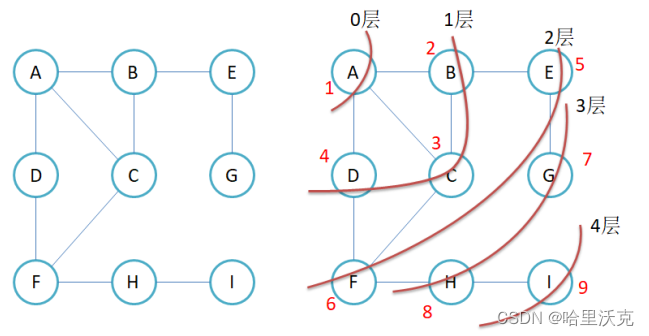
1.BFS--广度优先遍历
1.bfs的实现其实就是基于队列实现的
2.先将第一个顶点push到队列中,那么我们就可以基于该顶点进行遍历.需要注意的是,我们需要一个表来查看走到的点是否已经遍历过了
3.之后的循环,每次都查看每一层的顶点,并且将下一层的相邻顶点连接.遍历过的点pop掉并且将其访问的点进行标记已经访问
void BFS(const V& src){size_t srci = GetVertexIndex(src);// 队列和标记数组queue<int> q;vector<bool> visited(_vertexs.size(), false);q.push(srci);visited[srci] = true;int levelSize = 1;size_t n = _vertexs.size();while (!q.empty()){// 一层一层出for (int i = 0; i < levelSize; ++i){int front = q.front();q.pop();cout << front << ":" << _vertexs[front] << " ";// 把front顶点的邻接顶点入队列for (size_t i = 0; i < n; ++i){if (_matrix[front][i] != MAX_W){if (visited[i] == false){q.push(i);visited[i] = true;}}}}cout << endl;levelSize = q.size();}cout << endl;}2.DFS--深度优先遍历
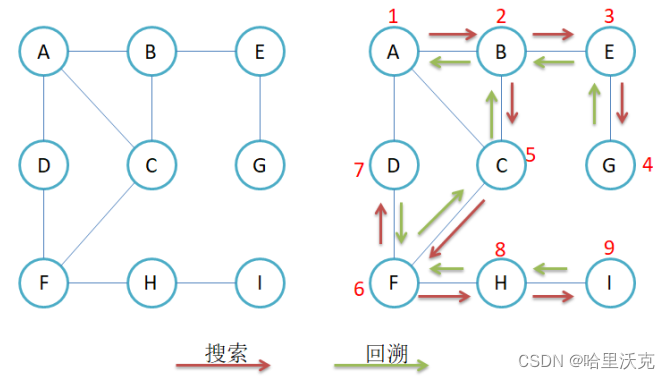
将当前访问的点进行遍历,随后标记为访问过了,循环该点的其他相邻点,同样的逻辑
void _DFS(size_t srci, vector<bool>& visited){cout << srci << ":" << _vertexs[srci] << endl;visited[srci] = true;for (size_t i = 0; i < _vertexs.size(); ++i){if (_matrix[srci][i] != MAX_W && visited[i] == false){_DFS(i, visited);}}}void DFS(const V& src){size_t srci = GetVertexIndex(src);vector<bool> visited(_vertexs.size(), false);_DFS(srci, visited);}这样的代码其实有弊端,就是只能遍历相邻的点.一旦该图不是连通图就会出现只能访问一部分.那么就需要在DFS处遍历每一个点,如果没有被_DFS遍历标记过就需要再一次进行_DFS遍历