Mysql查询
- 一.DQL基础查询
- 1.语法
- 2.特点
- 3.查询结果处理
- 二.单行函数
- (1)字符函数
- (2)逻辑处理
- (3)数学函数
- (4)日期函数
- 三.分组函数
- 四.条件查询
- 五.比较
- 六.模糊查询
- 七.UNION和UNION ALL
- (1)UNION
- (2)UNION ALL
- 八.排序
- 九.数量限制
- 十.分组查询
一.DQL基础查询
DQL(Data Query Language): 数据查询语言查询是使用频率最高的一个操作,
可以从一个表中查询数据,也可以从多个表中查询数据。
1.语法
select 查询列表 from 表名
2.特点
(1)查询列表可以是:表中的字段、常量、表达式、函数
(2)查询的结果是一个虚拟的表格
3.查询结果处理
特定列查询:select column1,column2 from table
全部列查询: select * from table
算数运算符:+ - * /
排除重复行: select distinct column1,column2 from table
查询函数:select 函数; / 例如version()
函数:类似于java中的方法,将一组逻辑语句事先在数据库中定义好,可以直接调用
分类:
单行函数:如concat、length、ifnull等
分组函数:做统计使用,又称为统计函数、聚合函数、组函数
二.单行函数
(1)字符函数
length():获取参数值的字节个数
SELECT id,NAME,LENGTH(NAME) FROM nbaplayer
char_length()获取参数值的字符个数
SELECT id,NAME,CHAR_LENGTH(NAME) FROM nbaplayer
concat(str1,str2,…):拼接字符串
SELECT id,CONCAT(NAME,':',weizhi) FROM nbaplayer
upper()/lower():将字符串变成大写/小写
SELECT id,UPPER(NAME) AS '姓名',weizhi FROM nbaplayer
SELECT id,LOWER(NAME) AS '姓名',weizhi FROM nbaplayer
substring(str,pos,length):截取字符串 位置从1开始
SELECT id,NAME,SUBSTRING(NAME,1,2) AS"截取",weizhi FROM nbaplayer
instr(str,指定字符):返回子串第一次出现的索引,如果找不到返回0
SELECT id,NAME,INSTR(NAME,'特') AS'查找',weizhi FROM nbaplayer
trim(str):去掉字符串前后的空格或子串,trim(指定子串 from 字符串)
SELECT id,NAME,weizhi,TRIM('a' FROM NAME) AS'去掉字串' FROM nbaplayer
lpad(str,length,填充字符):用指定的字符实现左填充将str填充为指定长度
SELECT id,NAME,LPAD(NAME,10,'a') FROM nbaplayerrpad(str,length,填充字符):用指定的字符实现右填充将str填充为指定长度
SELECT id,NAME,RPAD(NAME,10,'a') FROM nbaplayer
replace(str,old,new):替换,替换所有的子串
SELECT id,NAME,REPLACE(NAME,'特','6') FROM nbaplayer
(2)逻辑处理
(1)case when 条件 then 结果1 else 结果2 end; 可以有多个when
SELECTid,NAME,(CASEWHEN weight < 100THEN '太轻了'WHEN weight >= 100AND weight < 150THEN '正常'ELSE '超重'END)
FROMnbaplayer
(2)ifnull(被检测值,默认值)函数检测是否为null,如果为null,则返回指定的值,否则返回原本的值
SELECTid,NAME,IFNULL (weizhi, '位置还没有录入')
FROMnbaplayer
(3)if函数:if else的 效果 if(条件,结果1,结果2)
-- if函数:if else的 效果 if(条件,结果1,结果2)
SELECTid,NAME,IF (weight >= 100AND weight < 150,'正常','不正常')
FROMnbaplayer
(3)数学函数
(1) round(数值):四舍五入
SELECT id,NAME,height,ROUND(height) FROM nbaplayer
(2)ceil(数值):向上取整,返回>=该参数的最小整数
SELECT id,NAME,height,CEIL(height) FROM nbaplayer
(3)floor(数值):向下取整,返回<=该参数的最大整数
SELECT id,NAME,height,FLOOR(height) FROM nbaplayer
(4)truncate(数值,保留小数的位数):截断,小数点后截断到几位
SELECT id,NAME,height,TRUNCATE(height,0) FROM nbaplayer
(5)mod(被除数,除数):取余,被除数为正,则为正;被除数为负,则为负
SELECT id,NAME,weight,height,MOD(weight,height) FROM nbaplayer
(6)rand():获取随机数,返回0-1之间的小数
SELECT id,NAME,height,RAND() AS '随机数' FROM nbaplayer
(4)日期函数
(1)now():返回当前系统日期+时间
SELECT NOW()
(2)curdate():返回当前系统日期,不包含时间
SELECT CURDATE()
(3)curtime():返回当前时间,不包含日期
SELECT CURTIME()
可以获取指定的部分,年、月、日、小时、分钟、秒
(1)YEAR(日期列)
SELECT YEAR(birthday) FROM nbaplayer
(2)MONTH(日期列)
SELECT MONTH(birthday) FROM nbaplayer
(3)DAY(日期列)
SELECT DAY(birthday) FROM nbaplayer
(4)HOUR(日期列)
SELECT HOUR(birthday) FROM nbaplayer
(5)MINUTE(日期列)
SELECT MINUTE('2003-2-20 11:39:12')
(6)SECOND(日期列)
SELECT SECOND('2003-2-20 11:39:12')
str_to_date:将日期格式的字符转换成指定格式的日期
SELECT STR_TO_DATE('2003,2,20','%Y,%m,%d')//这个方法格式必须正确否则会显示NULL
date_format:将日期转换成字符串
SELECT DATE_FORMAT(CURDATE(),'%Y年%m月%d日')
datediff(big,small):返回两个日期相差的天数
SELECT DATEDIFF(CURDATE(),birthday) FROM nbaplayer
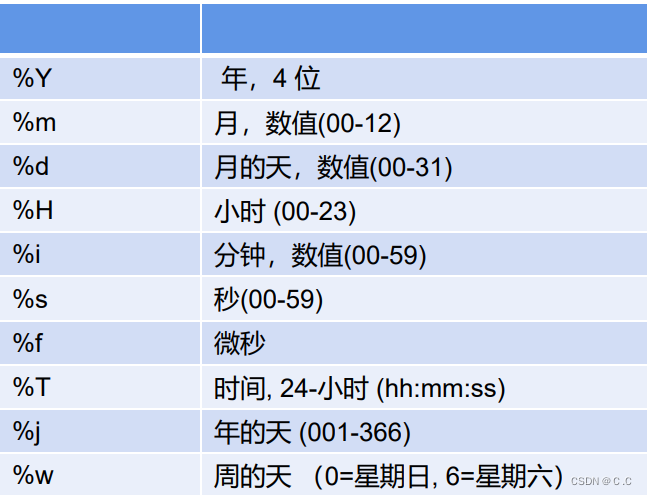
上表是日期转化时的格式
三.分组函数
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:sum 求和,avg 平均值,max 最大值,min 最小值,count 计数(非空)
1.sum,avg一般用于处理数值型,max,min,count可以处理任何类型
2.以上分组函数都忽略null值
3.count函数的一般使用count(*)用作统计行数
4.和分组函数一同查询的字段要求是group by后的字段
四.条件查询
使用WHERE 子句,将不满足条件的行过滤掉,WHERE 子句紧随 FROM 子句。
语法:select <结果> from <表名> where <条件>
五.比较
(1)=, != 或<>, >, <, >=, <=
(2)逻辑运算
and 与
or 或
not
SELECT * FROM nbaplayer WHERE weizhi='后卫' -- =
SELECT * FROM nbaplayer WHERE weizhi!='前锋' -- !=或<>
SELECT * FROM nbaplayer WHERE height>200.0 -- >
SELECT * FROM nbaplayer WHERE height<200.0 -- <
SELECT * FROM nbaplayer WHERE weight>=100 -- >=
SELECT * FROM nbaplayer WHERE weight<=100 -- <=
SELECT * FROM nbaplayer WHERE height<=200 AND weight<=100 --与 AND
SELECT * FROM nbaplayer WHERE weizhi='后卫' OR weizhi='前锋' --或 OR
六.模糊查询
(1)LIKE :是否匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值
或数值型. 通配符: % 任意多个字符,包含0个字符 _ 任意单个字符
(2)between and 两者之间,包含临界值;
(3)in 判断某字段的值是否属于in列表中的某一项
(4)IS NULL(为空的)或 IS NOT NULL(不为空的)
-- is null is not null
SELECT * FROM nbaplayer WHERE weizhi IS NOT NULL
SELECT * FROM nbaplayer WHERE weizhi IS NULL-- not in()/in()in 判断某字段的值是否属于in列表中的某一项
SELECT * FROM nbaplayer WHERE weight IN(96,111,140)
SELECT * FROM nbaplayer WHERE weight NOT IN(96,111,140)-- between and 两者之间,包含临界值
SELECT * FROM nbaplayer WHERE weight BETWEEN 100 AND 150-- 模糊查询
-- LIKE :是否匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值
-- 或数值型. 通配符: % 任意多个字符,包含0个字符 _ 任意单个字符
SELECT * FROM nbaplayer WHERE NAME LIKE '_明'
SELECT * FROM nbaplayer WHERE NAME LIKE '%特%'
七.UNION和UNION ALL
(1)UNION
UNION 的语法如下:
[SQL 语句 1]
UNION
[SQL 语句 2
UNION用于将两条语句合并,并且有自动去重的功能
SELECT * FROM nbaplayer WHERE weizhi='后卫'
UNION
SELECT * FROM nbaplayer WHERE weizhi='前锋'
(2)UNION ALL
UNION ALL 的语法如下:
[SQL 语句 1]
UNION ALL
[SQL 语句 2
UNION ALL同样用于将两条语句合并,但不能自动去重,会把所有记录返回,且效率高于UNION
SELECT * FROM nbaplayer WHERE weizhi='后卫'
UNION ALL
SELECT * FROM nbaplayer WHERE weizhi='前锋'
八.排序
查询结果排序,使用 ORDER BY 子句排序 order by 排序列 ASC/DESC
asc代表的是升序,desc代表的是降序,如果不写,默认是升序
order by子句中可以支持单个字段、多个字段
SELECT * FROM nbaplayer WHERE weizhi='中锋' ORDER BY height DESC, weight ASC九.数量限制
数量限制
limit子句:对查询的显示结果限制数目 (sql语句最末尾位置)
SELECT * FROM table LIMIT offset rows;
SELECT * from table LIMIT 0
一般用于分页操作
SELECT * FROM nbaplayer WHERE weizhi='后卫' ORDER BY height LIMIT 1,2
-- 跳过1个,查询两个
十.分组查询
语法:
select 分组函数,列(要求出现在group by的后面)
from 表
[where 筛选条件]
group by 分组的列表
[having 分组后的筛选]
[order by 子句]
注意:查询列表比较特殊,要求是分组函数和group by后出现的字段
-- 分组
SELECT weizhi,SUM(height)FROM nbaplayer GROUP BY weizhi
SELECT weizhi,AVG(weight)FROM nbaplayer GROUP BY weizhi HAVING AVG(weight)>100
SELECT weizhi,SUM(id) FROM nbaplayer GROUP BY weizhi HAVING SUM(id)<30