一、zookeeper
zookeeper+kafka(2.7.0版本)
kafka(3.4.1版本)不依赖于zookeeper
1、定义:zookeeper开源,分布式架构,提供协调服务(Apache项目),基于观察者模式涉及的分布式服务管理架构。作用:存储和管理数据,分布式节点上的服务接受观察者的注册,一旦分布式节点上的数据发生变化,由zookeeper来负责通知分布式节点上的服务

2、特点:zookeeper分为领导者(leader)和追随者(follower)。只要有一般以上的集群存活,zookeeper集群就可以正常工作,适用于安装奇数台的服务器集群;全局数据一致,每个zookeeper节点都保存相同的数据
3、主要作用
(1)维护监控服务器的数据一致,每个zookeeper节点都保存相同的数据;
(2)数据更新的原子性,要么全成功,要么全失败;
(3)实时性,只要有变化,立刻同步
4、应用场景(记)
(1)统一命名服务:在分布式环境下,对所有的应用和服务进行统一命名
(2)统一配置管理(配置文件同步):假设kafka的配置文件被修改,可以快速同步到其他节点
(3)统一集群管理★★★:实时掌握所有节点的状态
(4)服务器动态上下线
(5)实现服务在均衡:将访问服务器的数据发送到访问最少的服务器,来处理客户端的请求
5、选举机制
以三台服务器为例:A B C
第一步:A先启动,发起第一次选举,投票给自己,只有1票,不满足半数,此时A是looking状态
第二步:B启动,再发起一次选举,A和B分别投自己一票,交换选票信息,A发现B的myid比自己大,A的这1票会转投给B,此时B2票,A1票,还是不满足半数,A和B都是looking状态
B可能成为leader,C直接成为follower,如果B没有成为leader,那么执行第三步
特殊情况:
①leader已存在,建立连接即可
②leader不存在,服务器ID大的胜出
服务器ID:zookeeper集群中的机器都有一个ID,和myid保持一致
③epoch大,直接胜出
epoch:每个leader任期的代号,如果没有leader代号,大家的逻辑地位相同,但是每投完一次之后,数据递增
④epoch相同,事务ID大的胜出
事务ID:用来标识服务器的每一次变更,每变更一次,事务ID变化一次
第三步:C启动,若C的myid最大,A和B都会把票投给C,此时A—0票,B—0票,C—3票,C的状态变为leader,A和B变为follower
只有leader确定,后续的服务器都是追随者,无论myid大小
只有两种情况重新开启选举机制:
①初始化的情况下产生选举
②服务器之间和leader丢失连接状态
二、消息队列kafka(重要)
1、为什么要引入消息队列(MQ)?
kafka是一个中间件,负责发消息。在高并发环境下,同步请求来不及处理,会形成阻塞。比如,数据库会形成表锁或行锁。请求线程超标,会出现错误too many connection,整个系统崩溃(系统雪崩)
客户端————kafka————服务端
2、消息队列的作用
(1)异步处理请求(留一个延迟时间)
(2)流量削峰
(3)应用解耦
(4)可恢复性
(5)缓冲机制
(6)峰值处理能力
(7)异步通信★★★
2、消息队列的模式
(1)点对点模式(一对一模式)
消息的产生者发送消息到队列中,消费者从队列中提取消息,消费者提取完消息后,队列中的消息将会被移除,后续消费者不能再消费队列中的消息。消息队列可以有多个消费者,但是一个消息只能由一个消费者提取(举例:rabbitmq)
(2)发布和订阅模式(一对多、观察者模式)
生产者发布一个消息到主题(topic)中,所有消费者都是通过主题获取消息,消费者提取数据后,队列中的消息不会被移除
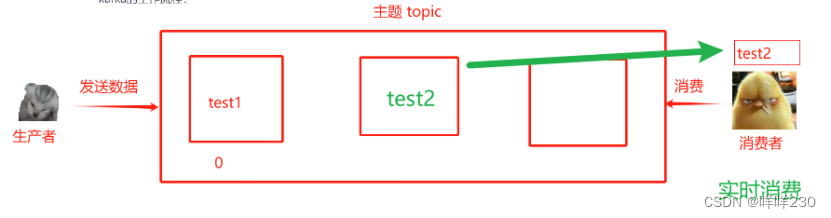
★主题:topic,类似于一个数据流管道,生产者把消息发布到主题,消费者从主题中订阅数据(获取数据),每个主题可以分成多个分区,每个分区有自己的偏移量。kafka默认不允许删除主题(可以理解成微信群)
★分区:partition,每个主题可以分成多个分区,每个分区是数据有序子集,分区可以允许kafka进行水平拓展,以处理大量数据,消息在分区中按照偏移量存储,消费者可以独立读取每个分区的数据【人为创建】(可以理解成备份)
★偏移量:是每个消息在分区中的唯一标识,消费者通过偏移量来跟踪、获取、已读、未读消息的位置;也可以通过提交偏移量记录已处理的信息——指示消费者到底要获取哪个位置的数据(可以理解成微信群中的聊天时间)
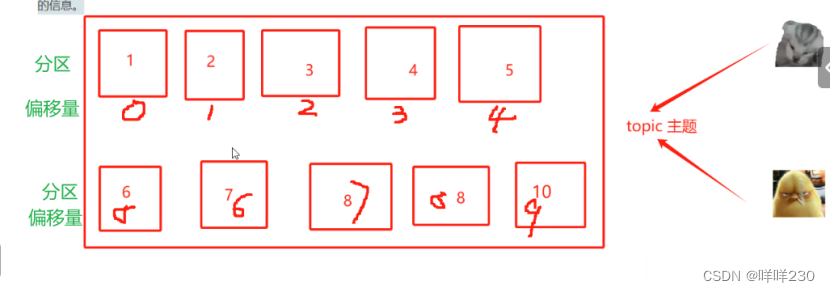
分区数量越多,存储数据越多,处理并发能力越强
获取消息的两种方式:
①begin:从头开始获取所有【常用】
②实时获取,只消费后续产生的消息【常用】
③指定偏移量消费【代码实现】
生产者:producer,生产者把数据发送到kafka的主题中,负责写入消息
消费者:consumer,从主题中读取数据,消费者是一个或多个,每个消费者都有一个唯一的消费者组ID,kafka通过消费者实现负载均衡和容错
3、kafka的工作流程

至少一次语义:只要消费者进入,确保消息至少被消费一次
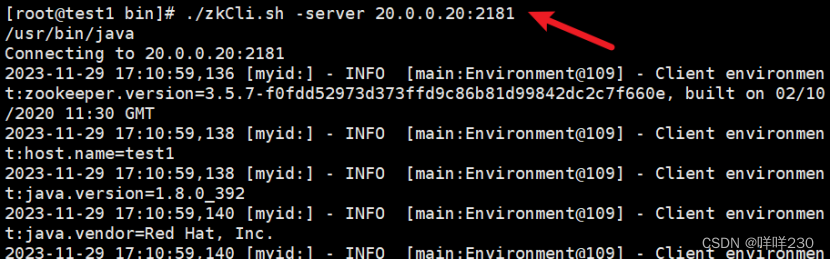
三、zookeeper+kafka实验
实验目的:监控所有服务器上的数据一致
实验条件:
| 主机名 | IP地址 | 组件 | 硬件条件 (最少) |
| test1 | 20.0.0.10 | zookeeper+kafka(2.7.0版本) | 2核4G |
| test2 | 20.0.0.20 | zookeeper+kafka(2.7.0版本) | 2核4G |
| test3 | 20.0.0.30 | zookeeper+kafka(2.7.0版本) | 2核4G |
实验步骤:
1、部署zookeeper【所有服务器】
(1)升级java环境
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel


(2)解zookeeper安装包,改名
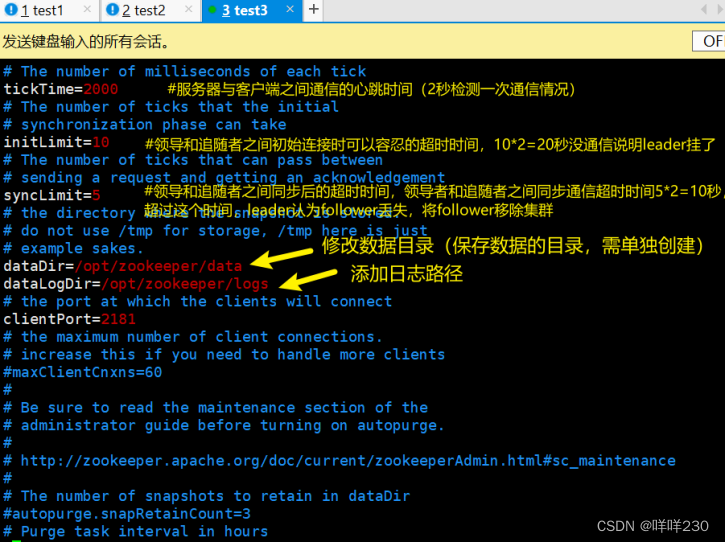
(3)修改zookeeper配置文件

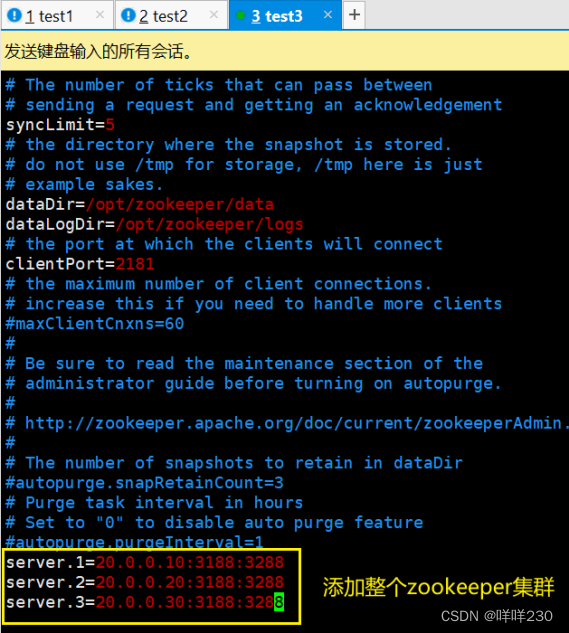
1,2,3表示每个zookeeper集群的初始myid【自定义】
3188表示领导者和追随者之间交换信息的端口(内部通信的端口)
3288表示一旦leader丢失响应,重新开启选举的端口(选举端口—互相通知选票信息的端口)
(4)创建目录【已在配置文件中自定义】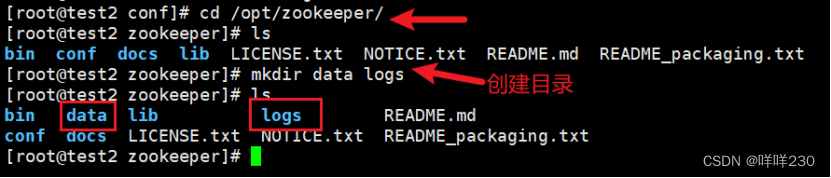
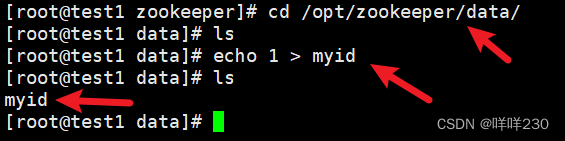
(5)给集群中的每台服务器分配myid
test1
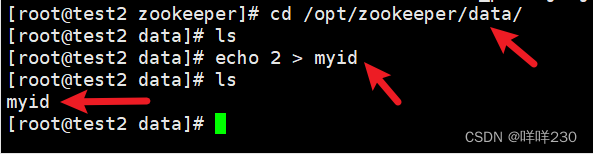
test2
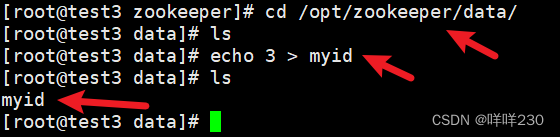
test3
(6)启动脚本【所有服务器】
1)创建脚本文件
![]()
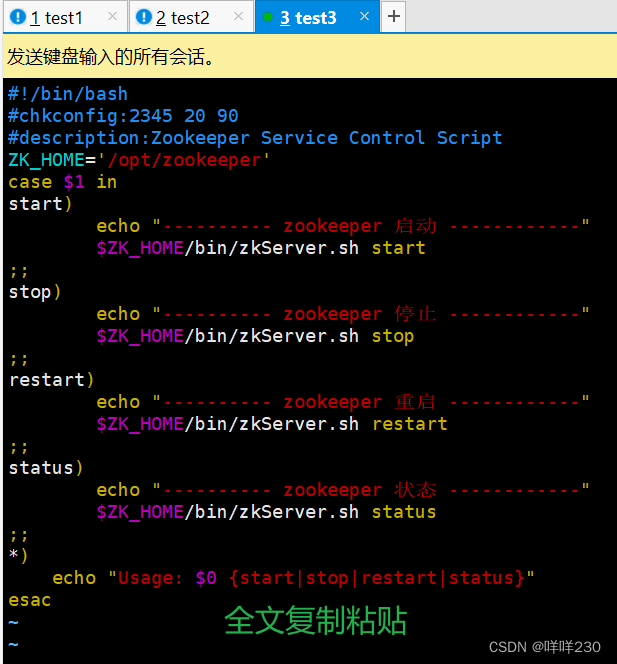
2)赋权脚本文件
chmod +x /etc/init.d/zookeeper
![]()
3)添加到系统服务中,让系统识别
chkconfig --add zookeeper
![]()
4)依次启动zookeeper,查看leader和follower状态
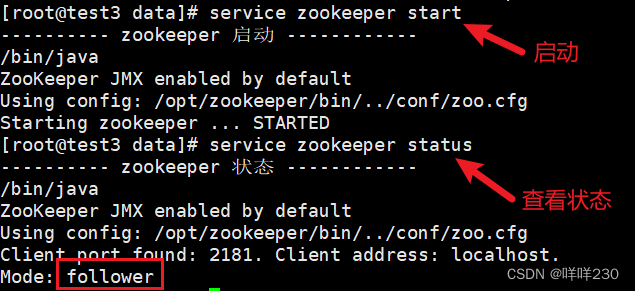
启动service zookeeper start
查看service zookeeper status
①第一次先启动test1
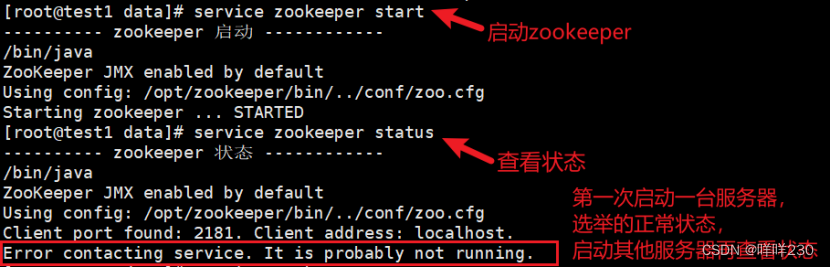
②第二次启动test2
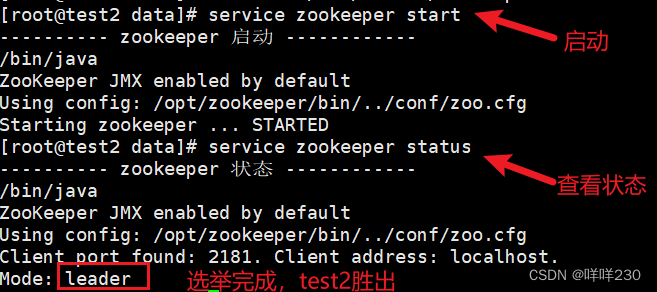
此时再次查看test1的状态,选举完成后test1自动变为follower
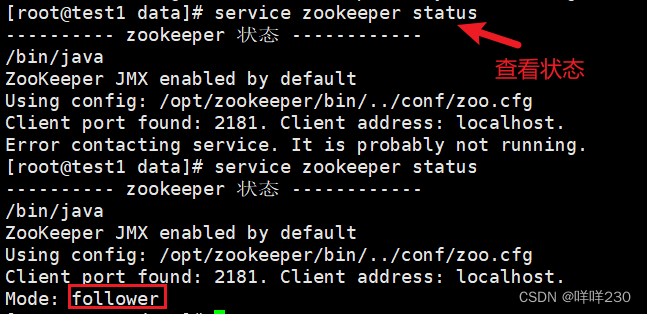
③第三次启动test3
选举完成,2票大于1票,即便test3启动,leader也不会改变
2、部署kafka【所有服务器】
(1)升级java环境
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel


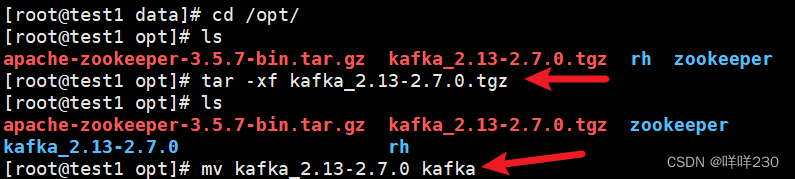
(2)解kafka压缩包
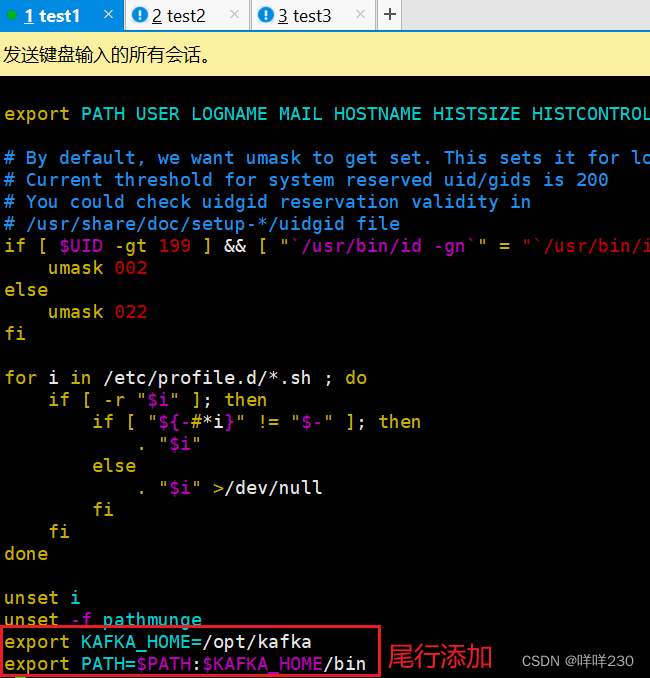
(3)声明kafka环境变量
添加
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin
![]()
![]()
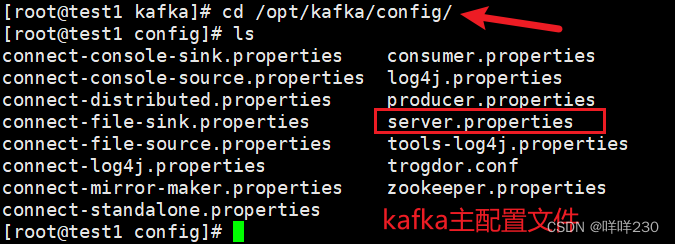
(4)修改kafka的配置文件
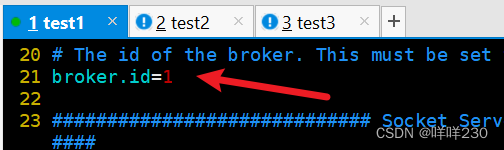
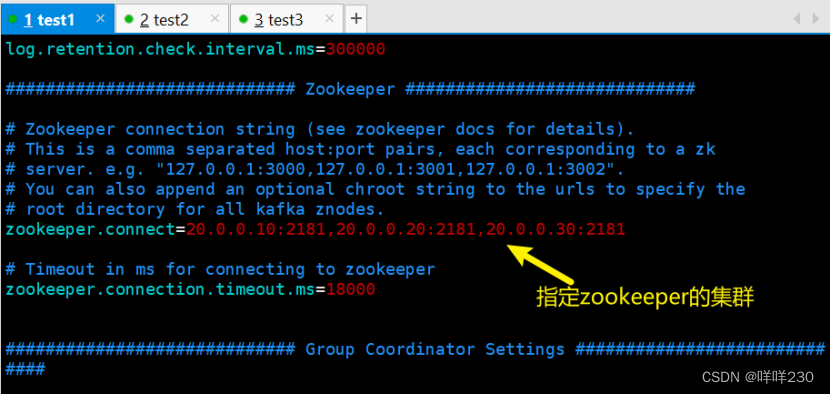
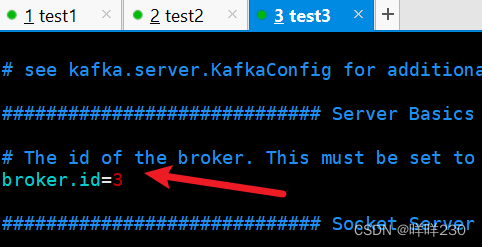
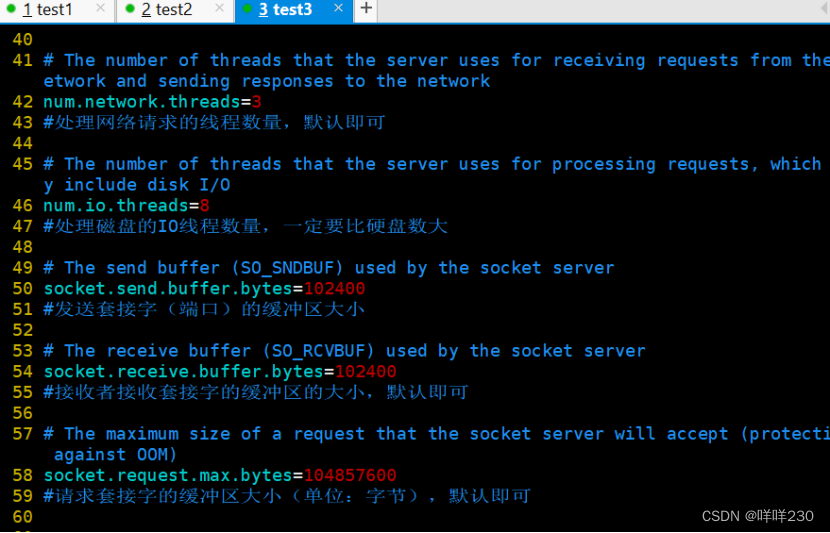
test1
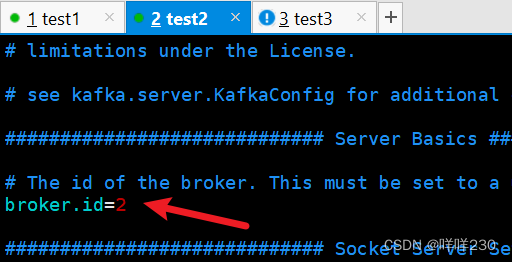
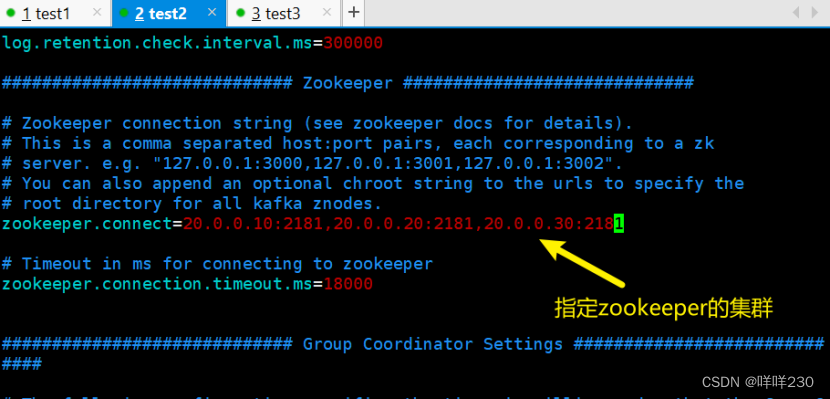
test2
test3
(5)创建kafka的启动脚本【所有服务器】
![]()
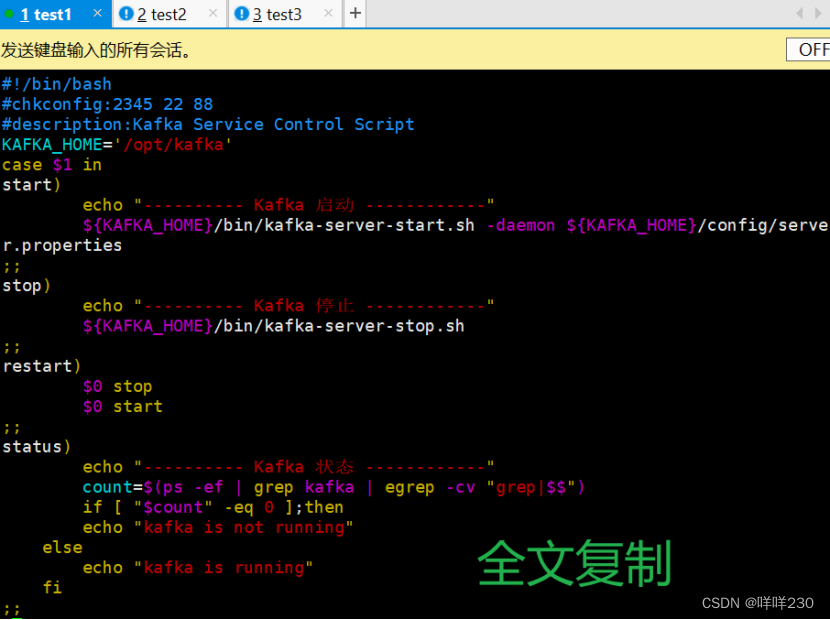
①赋权脚本chmod +x /etc/init.d/kafka
![]()
②添加系统命令,让系统识别chkconfig --add kafka
![]()
③启动kafka
![]()

kafka的默认端口号9092
(6)主机映射
![]()
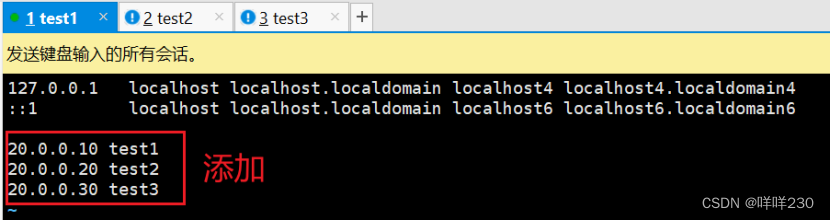
【注意:在kafka的bin目录下创建,bin是kafka所有可执行命令文件】

(7)创建主题topic
【在任意一台服务器上创建主题即可,所有服务器都可使用这个主题】
kafka-topics.sh --create --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --replication-factor 2 --partitions 3 --topic yyy

①查看所有主题topic详情



②查看指定主题topic详情

(8)发布消息
test1发布

(9)消费(订阅)
test2消费
①实时同步



②begin同步

test3也能同步获取消息

(10)不同主机订阅不同主题
①test3创建主题mmm
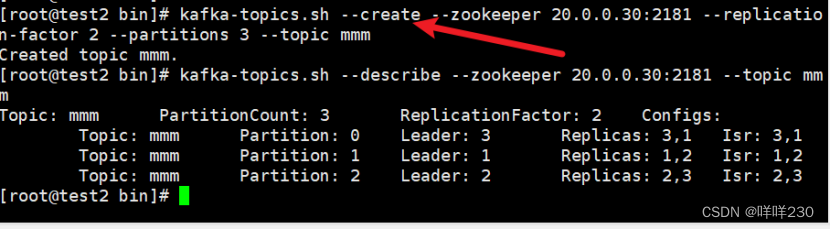
test3创建主题nnn
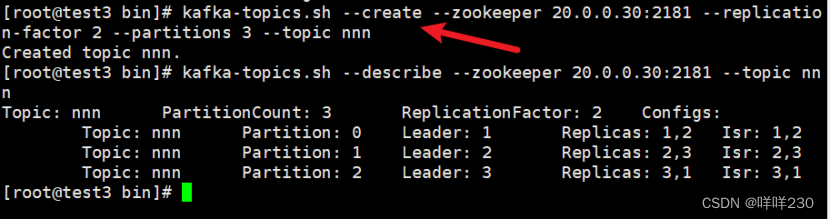
②test2在mmm主题上发布消息

test1订阅主题mmm

③test2在nnn主题上发布消息

test1订阅mmm

结论:主题之间互相隔离
(11)修改分区数
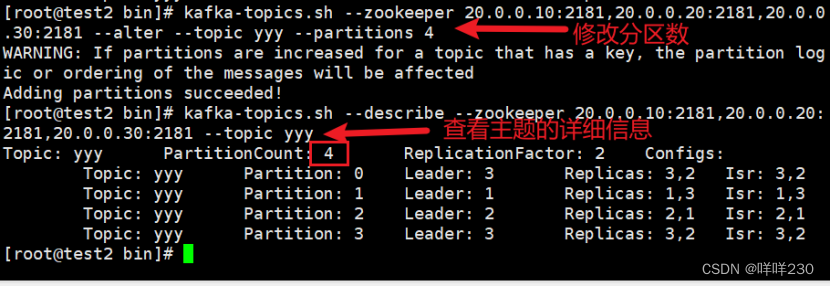
(12)删除主题【kafka机制默认不能删除主题】


(13)查看内部保存的元数据信息