亚马逊云服务中的S3对象存储功能和国内阿里云的oss对象存储使用基本一致。但是涉及到存储内容处理时,两家有些差别。
比如:对于云存储中的图片资源,阿里云比较人性化对于基本的缩放裁剪功能已经帮我们封装好了,只需要在url地址后面拼接参数即可,但是亚马逊S3存储本身并不具备这个功能,但是亚马逊提供了很多种方式,虽然灵活但是使用门槛较高(尤其是亚马逊文档基本都是英文的🤣)。
下面详细说一下如何在亚马逊服务上基于S3存储实现图片处理(扩展开可以处理任意类型存储资源)
篇幅较长,看完能懂个大概
使用到的亚马逊服务:
Lambda函数服务:云服务商目前都在推的serverless一种实现,在云端特定功能上运行写好的代码,支持很多种语言,弹性扩展灵活方便。参考(首先要学会简单的创建lambda函数,后面需要使用函数处理图片)
S3对象存储:
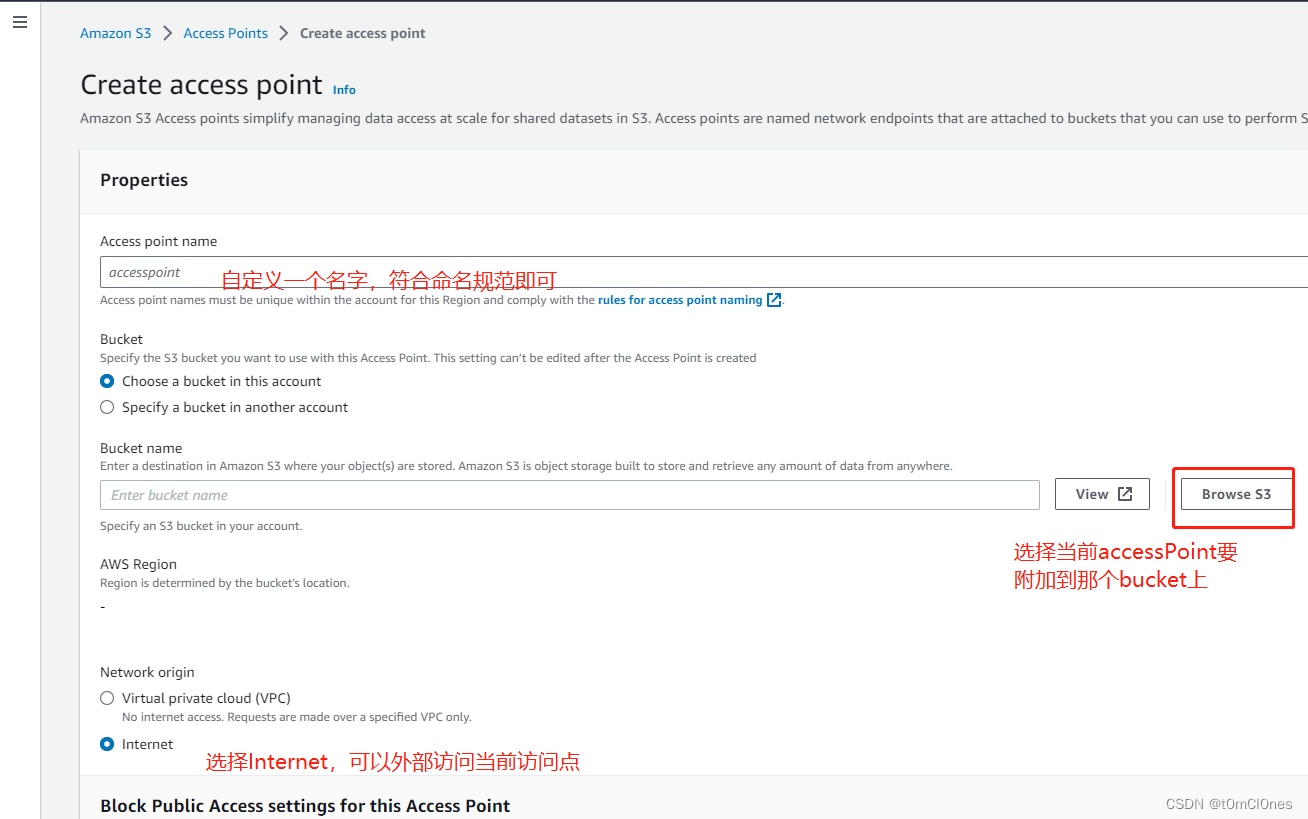
Access Point:作为S3存储的一个外部访问入口,一个access point对应一个S3bucket,一个S3 bucket可以对应多个access point. 常用于外部访问S3存储数据。
Object Lambda Access Point:建立在Access Point之上的Lambda函数切点,可以对访问请求或者响应做进一步处理,或者修改。
CloudFront云端内容分发服务(cdn):亚马逊云端内容分发服务,实现对内容的实时定制化处理,可扩展性高,延迟低。
S3 + CloudFront + Lambda 实现图片缩放具体步骤
1. 在lambda控制台新建Lambda函数 参考:geting-started 本文所需代码如下:
注:代码来自亚马逊文档中的示例,稍作修改实现图片缩放功能
import boto3
import json
import os
import logging
from io import BytesIO
from PIL import Image, ImageDraw, ImageFont
from urllib import request
from urllib.parse import urlparse, parse_qs, unquote
from urllib.error import HTTPError
from typing import Optionallogger = logging.getLogger('S3-img-processing')
logger.addHandler(logging.StreamHandler())
logger.setLevel(getattr(logging, os.getenv('LOG_LEVEL', 'INFO')))
FILE_EXT = {'JPEG': ['.jpg', '.jpeg'],'PNG': ['.png'],'TIFF': ['.tif']
}
OPACITY = 64 # 0 = transparent and 255 = full soliddef get_img_encoding(file_ext: str) -> Optional[str]:result = Nonefor key, value in FILE_EXT.items():if file_ext in value:result = keybreakreturn result# 添加水印示例
def add_watermark(img: Image, text: str) -> Image:# font = ImageFont.truetype("AmazonEmber_Rg.ttf", 82)txt = Image.new('RGBA', img.size, (255, 255, 255, 0))if img.mode != 'RGBA':image = img.convert('RGBA')else:image = imgd = ImageDraw.Draw(txt)# Positioning Textwidth, height = image.sizetext_width, text_height = d.textsize(text, font)x = width / 2 - text_width / 2y = height / 2 - text_height / 2# Applying Textd.text((x, y), text, fill=(255, 255, 255, OPACITY), font=font)# Combining Original Image with Text and Savingwatermarked = Image.alpha_composite(image, txt)return watermarked# 图片缩放
def resize_image(img, max_side_length=768):# 打开图像文件width, height = img.sizeprint("原:宽X高", width, "x", height)# 计算缩放后的尺寸scale_factor = max_side_length / max(width, height)new_width = int(width * scale_factor)new_height = int(height * scale_factor)# 缩放图像resized_img = img.resize((new_width, new_height))return resized_imgdef handler(event, context) -> dict:logger.debug(json.dumps(event))object_context = event["getObjectContext"]# Get the presigned URL to fetch the requested original object# from S3s3_url = object_context["inputS3Url"]# Extract the route and request token from the input contextrequest_route = object_context["outputRoute"]request_token = object_context["outputToken"]parsed_url = urlparse(event['userRequest']['url'])object_key = parsed_url.pathlogger.info(f'Object to retrieve: {object_key}')parsed_qs = parse_qs(parsed_url.query)for k, v in parsed_qs.items():parsed_qs[k][0] = unquote(v[0])filename = os.path.splitext(os.path.basename(object_key))# Get the original S3 object using the presigned URLlogger.info(f'S3 url: {s3_url}, parsed_url: {parsed_url}')req = request.Request(s3_url)try:response = request.urlopen(req)except HTTPError as e:logger.info(f'Error downloading the object. Error code: {e.code}')logger.exception(e.read())return {'status_code': e.code}if encoding := get_img_encoding(filename[1].lower()):logger.info(f'Compatible Image format found! Processing image: {"".join(filename)}')img = Image.open(response)logger.debug(f'Image format: {img.format}')logger.debug(f'Image mode: {img.mode}')logger.debug(f'Image Width: {img.width}')logger.debug(f'Image Height: {img.height}')# img_result = add_watermark(img, parsed_qs.get('X-Amz-watermark', ['Watermark'])[0])img_result = imgif parsed_qs.get('size', [''])[0] != '':img_result = resize_image(img, int(parsed_qs.get('size', ['500'])[0], base=10))img_bytes = BytesIO()if img.mode != 'RGBA':# Watermark added an Alpha channel that is not compatible with JPEG. We need to convert to RGB to saveimg_result = img_result.convert('RGB')img_result.save(img_bytes, format='JPEG')else:# Will use the original image format (PNG, GIF, TIFF, etc.)img_result.save(img_bytes, encoding)img_bytes.seek(0)transformed_object = img_bytes.read()else:logger.info(f'File format not compatible. Bypass file: {"".join(filename)}')transformed_object = response.read()# Write object back to S3 Object Lambdas3 = boto3.client('s3')# The WriteGetObjectResponse API sends the transformed dataif os.getenv('AWS_EXECUTION_ENV'):s3.write_get_object_response(Body=transformed_object,RequestRoute=request_route,RequestToken=request_token)else:# Running in a local environment. Saving the file locallywith open(f'myImage{filename[1]}', 'wb') as f:logger.debug(f'Writing file: myImage{filename[1]} to the local filesystem')f.write(transformed_object)# Exit the Lambda function: return the status codereturn {'status_code': 200}
创建完成如下:

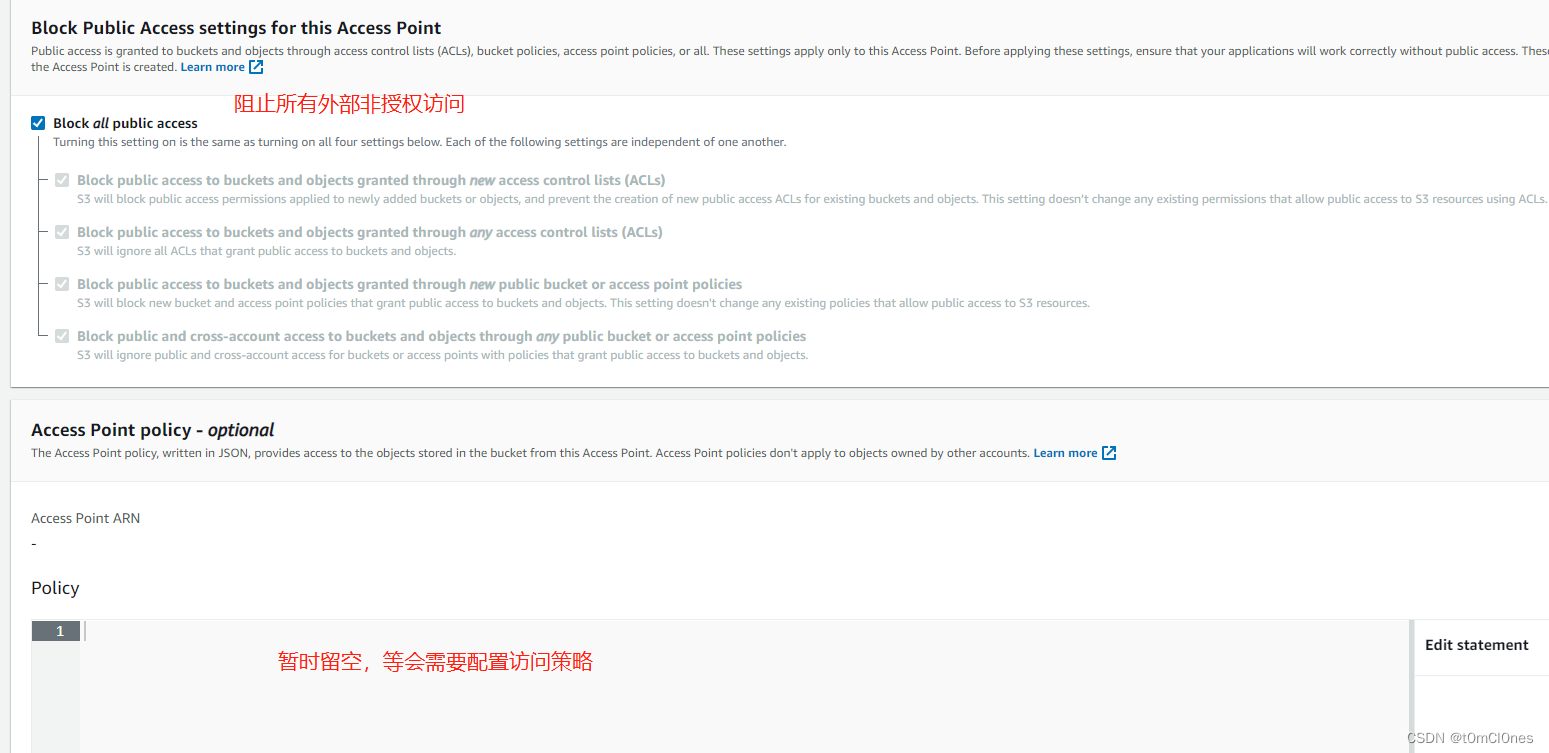
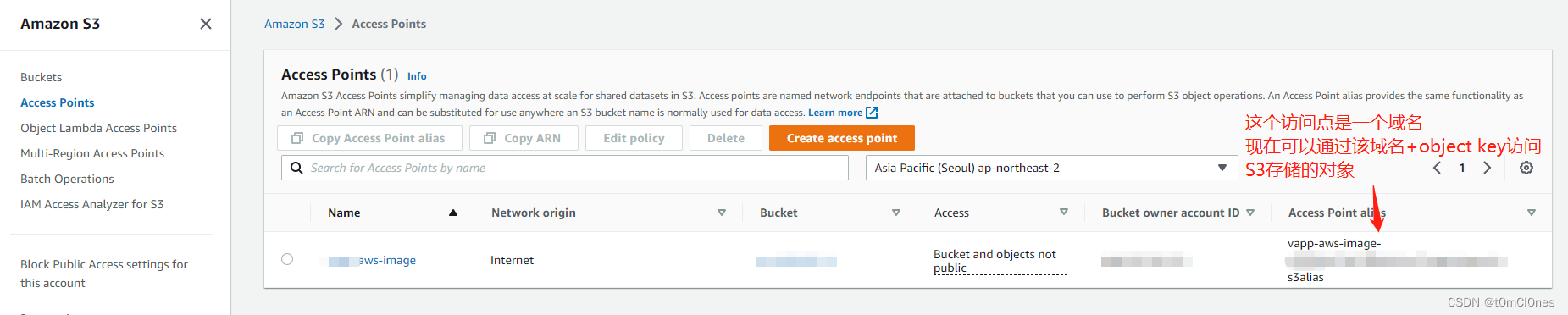
2. 亚马逊S3控制台左侧 Access Point 菜单创建Access Point
3. 亚马逊S3控制台左侧 Object Lambda Access Point 菜单创建Object Lambda Access Point
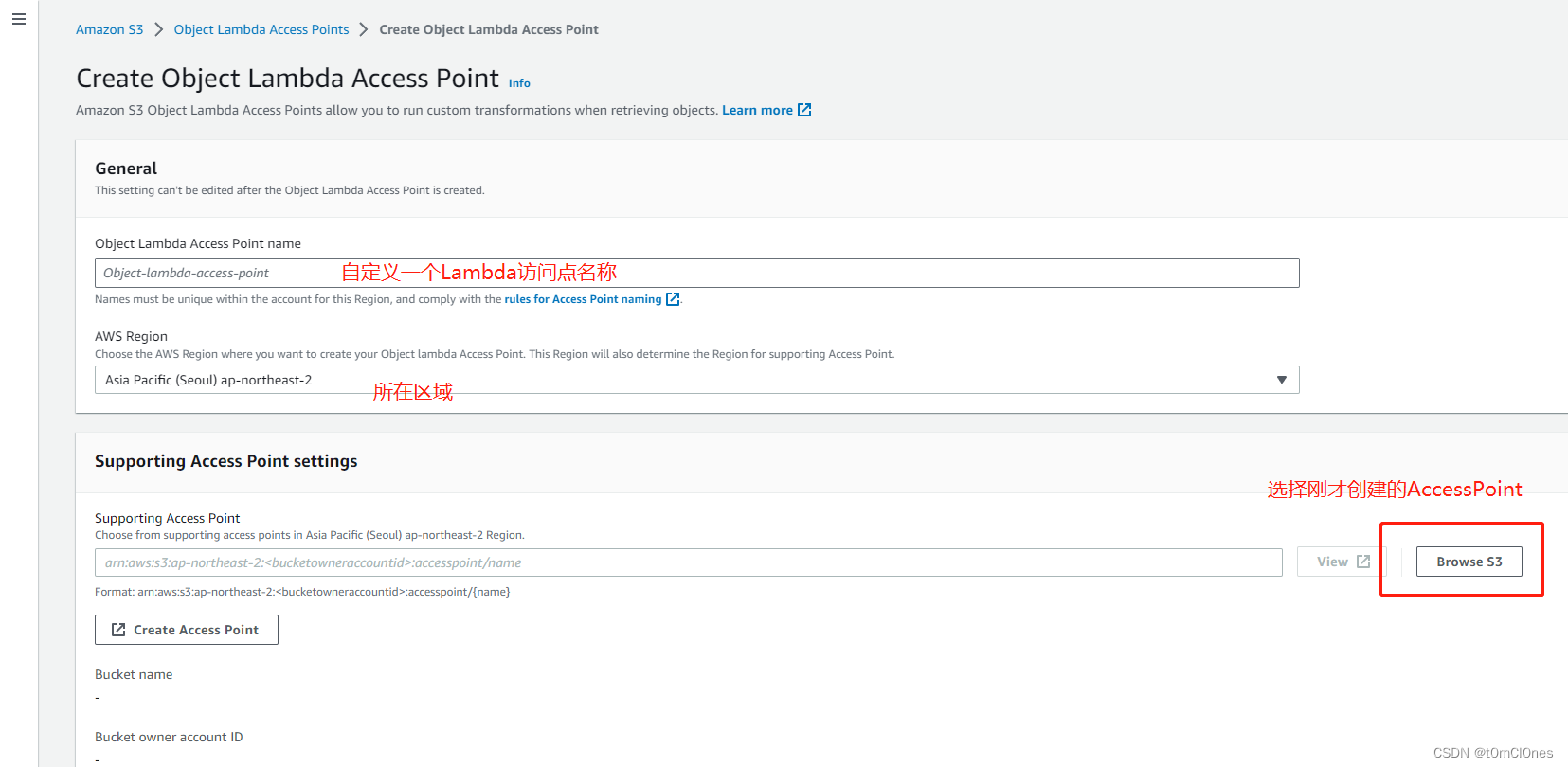
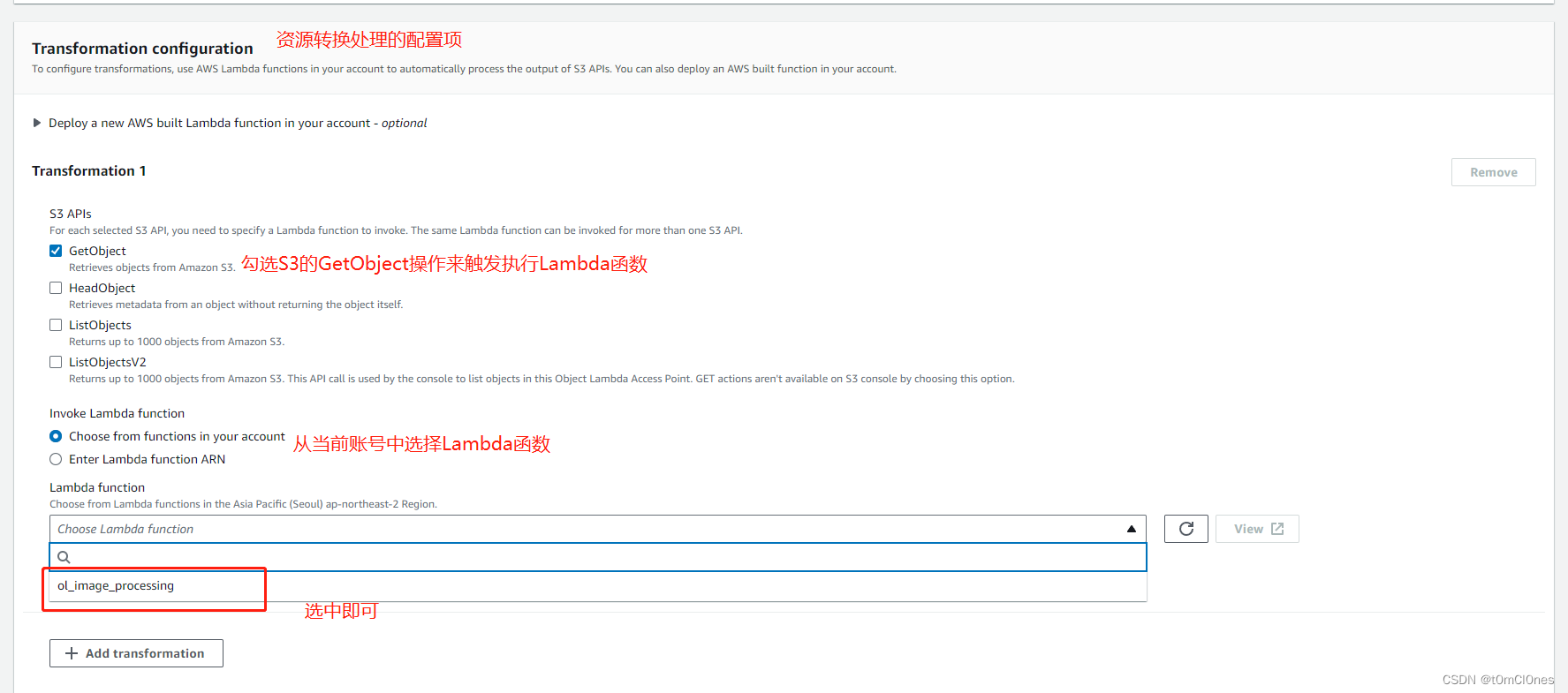
其他选项保持默认,点击创建Object Lambda Access Point即可
4. CloudFront控制台创建分发
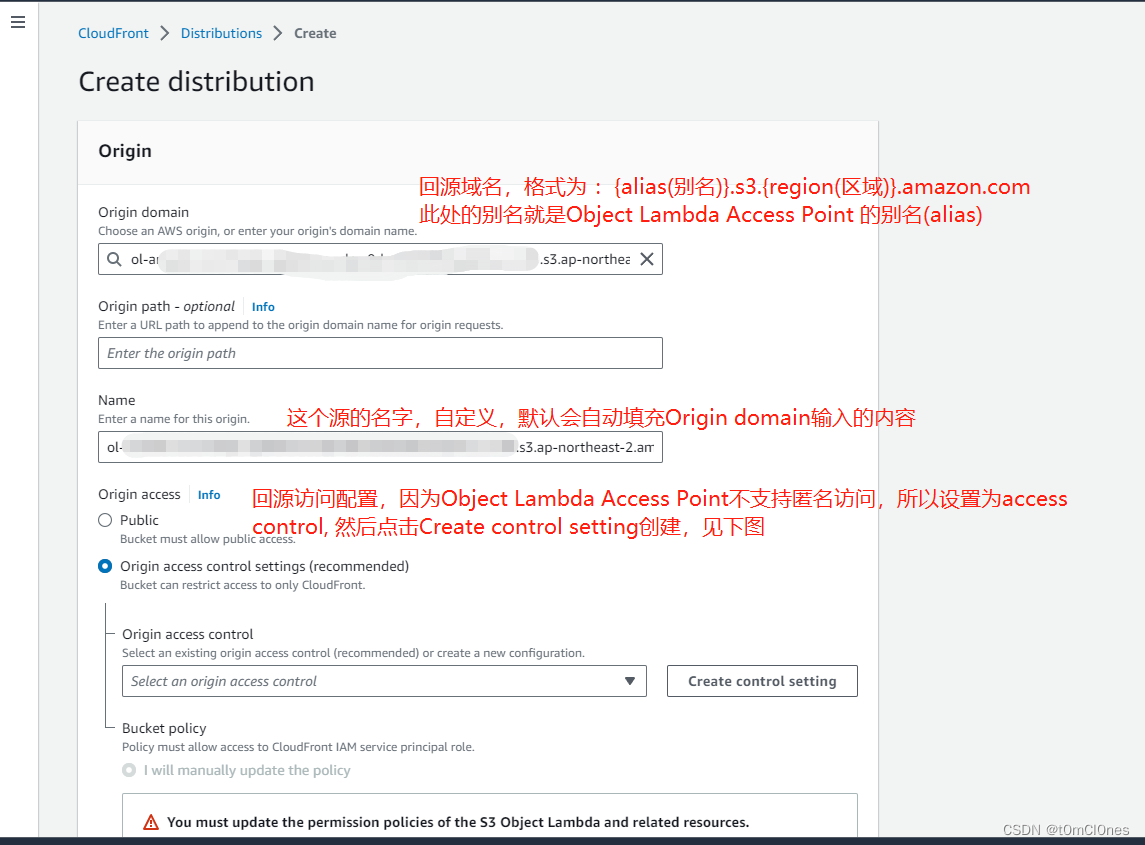
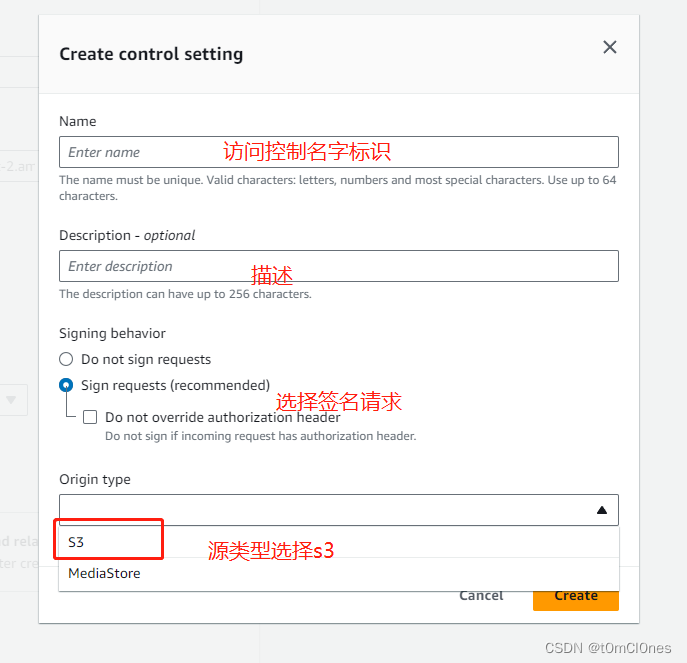
其他先保持默认,点击创建分发。
5. 上面分别创建了所需资源,下面需要为上面创建的资源和S3 bucket配置访问策略权限。
配置Bucket访问策略 ,点击bucket name名称进入下图,最后点击Bucket policy右侧的edit编辑按钮
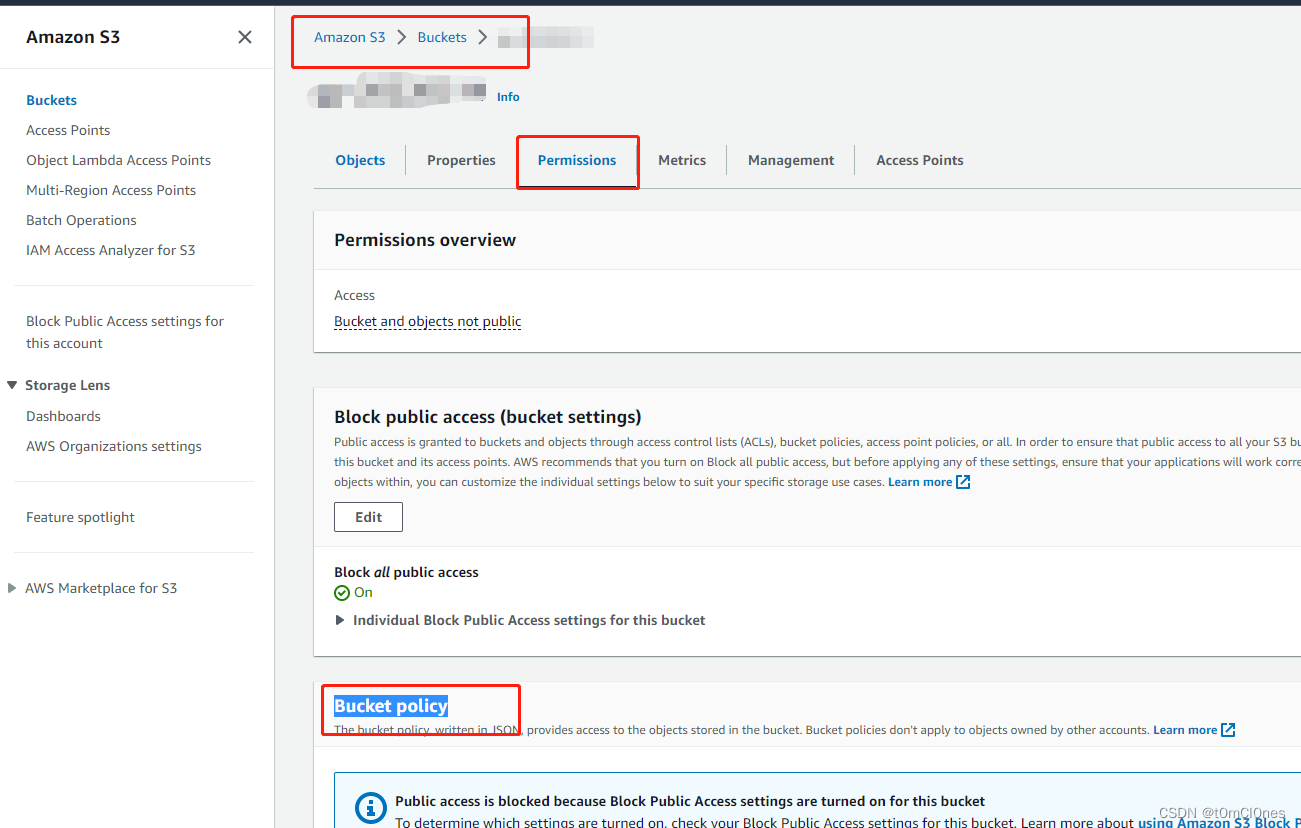
修改如下配置,保存。 (下面的配置为允许aws的所有服务访问s3内的指定bucket内所有对象,并且AccessPoint的账号等于指定的账号)
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"AWS": "*"},"Action": "*","Resource": ["arn:aws:s3:::你的bucket名称","arn:aws:s3:::你的bucket名称/*"],"Condition": {"StringEquals": {"s3:DataAccessPointAccount": "当前登录的账号ID"}}}]
}配置Access Point访问策略
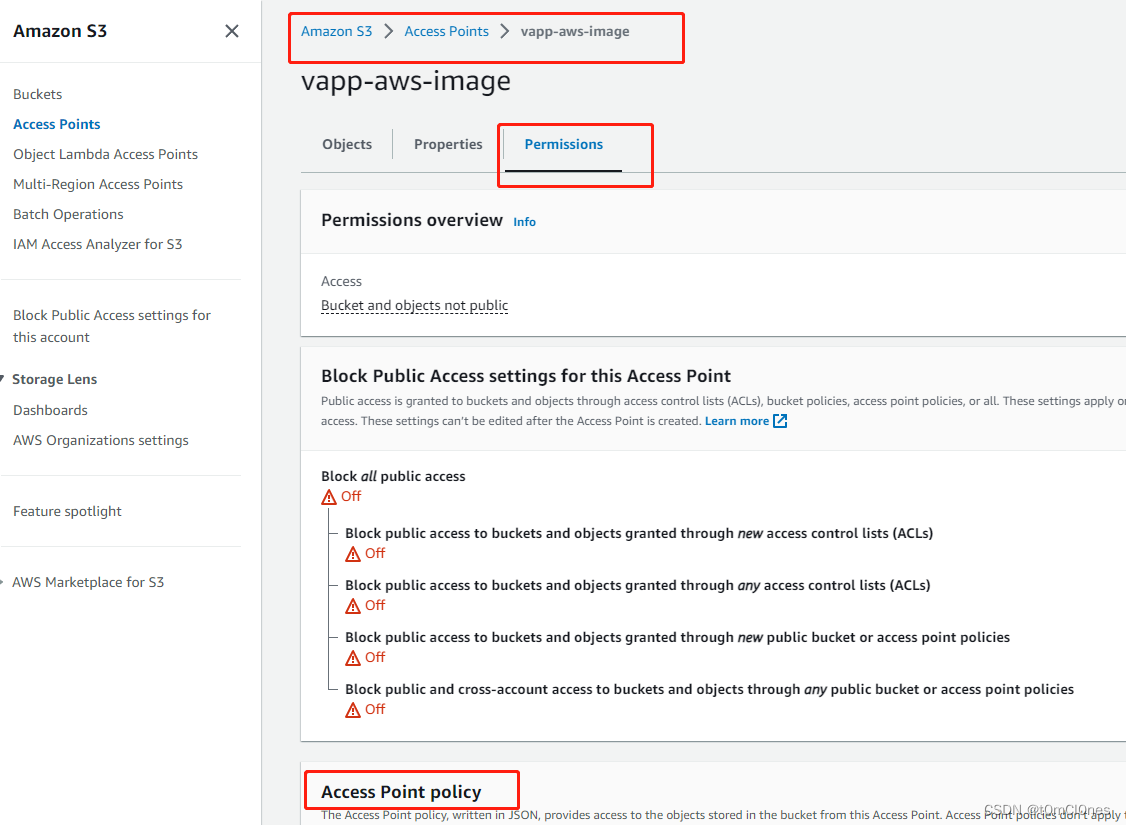
配置内容如下:(下面配置为允许lambda access point访问点 访问 当前 access point内所有对象资源)
{"Version": "2012-10-17","Id": "default","Statement": [{"Sid": "s3objlambda","Effect": "Allow","Principal": {"Service": "cloudfront.amazonaws.com"},"Action": "s3:*","Resource": ["arn:aws:s3:你的区域:当前帐号ID:accesspoint/你的AccessPoint名子标识(我这里是vapp-aws-image)","arn:aws:s3:你的区域:当前帐号ID:accesspoint/你的AccessPoint名子标识/object/*"],"Condition": {"ForAnyValue:StringEquals": {"aws:CalledVia": "s3-object-lambda.amazonaws.com"}}}]
}配置Object Lambda Access Point访问策略
配置策略如下:(下面的配置为允许登陆账号下的内容分发 访问指定的object lambda access point)
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Service": "cloudfront.amazonaws.com"},"Action": "s3-object-lambda:Get*","Resource": "arn:aws:s3-object-lambda:你的区域:登录账号ID:accesspoint/你的ObjectLambdaAccessPoint名字","Condition": {"StringEquals": {"aws:SourceArn": "arn:aws:cloudfront::登录账号ID:distribution/刚才创建的分发ID"}}}]
}6. 资源和策略配置完成后,还有最后一步就是自定义访问参数,用于缓存生成的内容,避免每次访问都需要调用lambda函数处理(或者缓存了不正确的内容,因为默认缓存策略不包含自定义参数),本文自定义参数为size,表示当前图片最大边边长尺寸,等比缩放,需要为自定义参数创建一个Cache policy
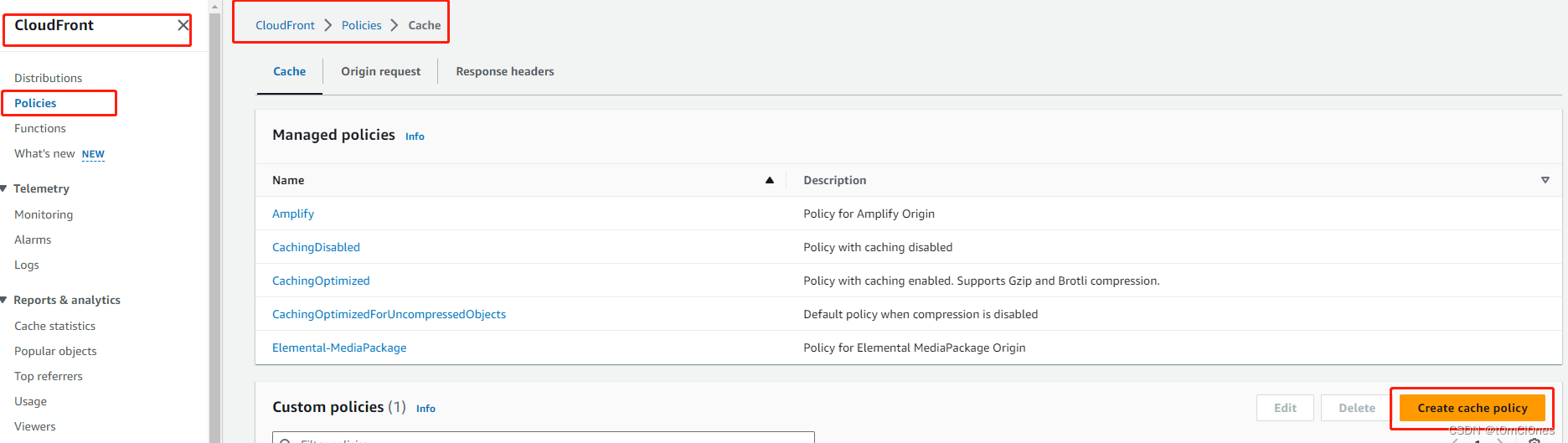
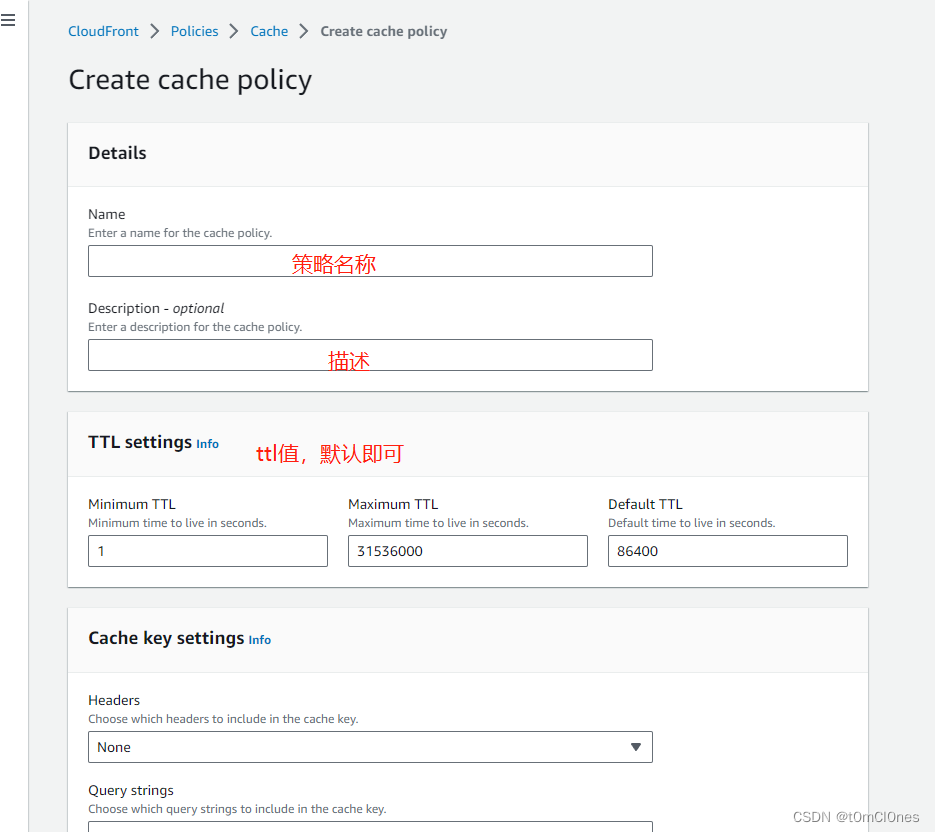
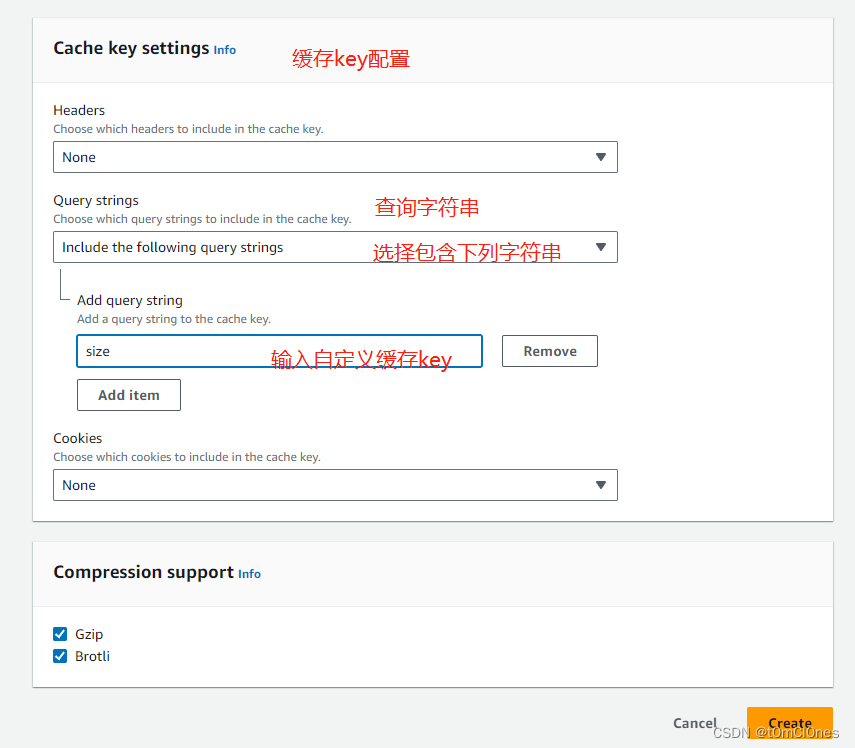
创建成功后,找到刚才创建的CloudFront分发,配置缓存策略如下:
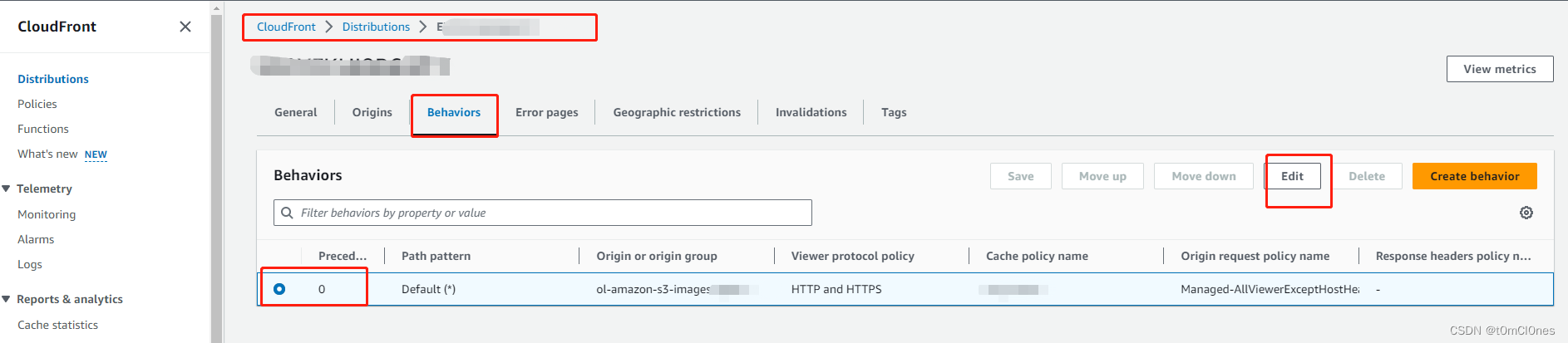
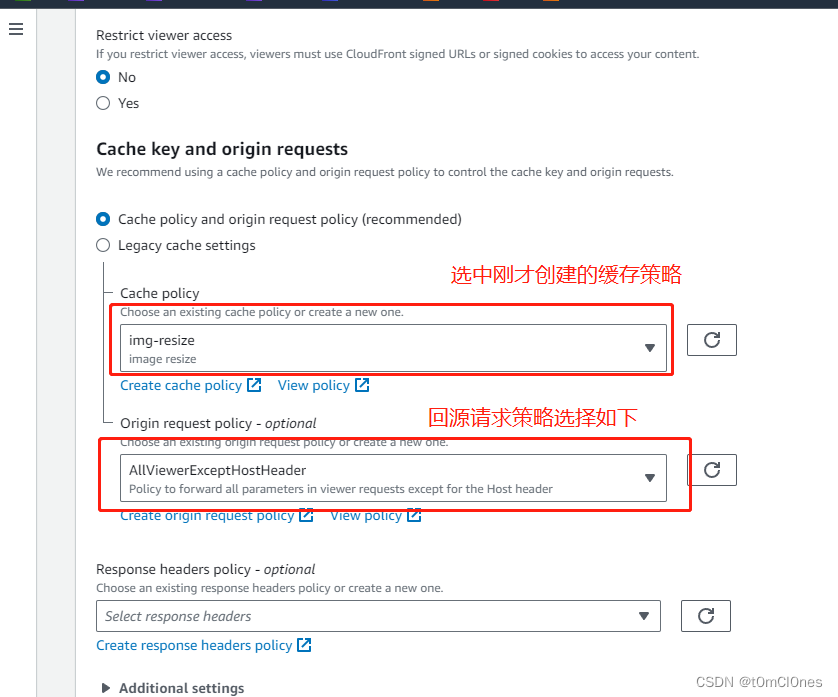
保存后,等会(几分钟)生效。
7. 测试
CloudFront控制台,找到刚才创建的Distribution分发,找到分发域名,如下图:

到bucket中上传一个图片,然后使用该域名访问测试如下:

如果写的lambda函数有问题,会报错,到lambda控制台查找日志根据报错信息调试即可。
上面截图中使用的为英文版控制台,原因是由于亚马逊很多文档都是英文,个别有中文的翻译也不好,对比英文文档使用时会出现对不上号的情况,所以推荐大家使用亚马逊对应文档操作时使用英文控制台。
最后 理一下这套服务整个流程
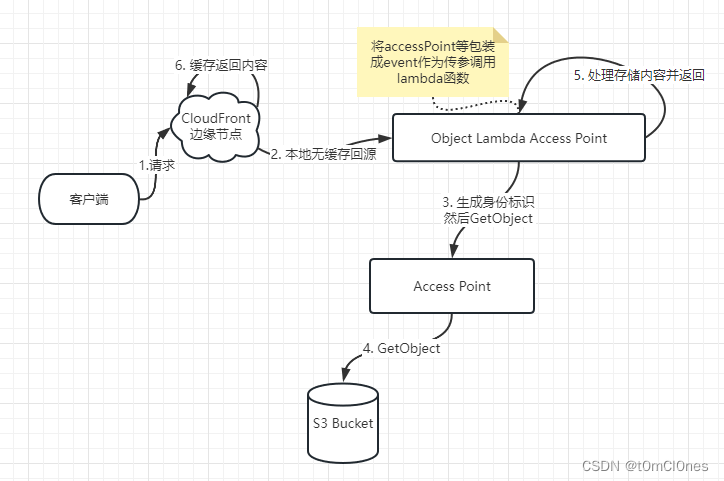
参考:amazon-s3-object-lambda-with-cloudfront