0.摘要
目前用于语义分割的先进模型是基于最初设计用于图像分类的卷积网络的改进。然而,像语义分割这样的密集预测问题在结构上与图像分类不同。在这项工作中,我们开发了一个专门为密集预测设计的新的卷积网络模块。所提出的模块使用膨胀卷积来系统地聚合多尺度的上下文信息,而不会丢失分辨率。该架构基于膨胀卷积支持对感受野的指数级扩展,同时不会丢失分辨率或覆盖范围。我们证明了所提出的上下文模块可以提高最先进的语义分割系统的准确性。此外,我们还研究了将图像分类网络适应到密集预测的方法,并证明简化适应网络可以提高准确性。
1.引言
计算机视觉中许多自然问题都是密集预测的实例。其目标是为图像中的每个像素计算一个离散或连续的标签。一个著名的例子是语义分割,它需要将每个像素分类到给定的一组类别中(He et al., 2004; Shotton et al., 2009; Kohli et al., 2009; Krahenbühl & Koltun, 2011)。语义分割具有挑战性,因为它要求在像素级准确性和多尺度上下文推理之间进行组合(He et al., 2004; Galleguillos & Belongie, 2010)。最近通过使用卷积网络(LeCun et al., 1989)通过反向传播(Rumelhart et al., 1986)进行训练,在语义分割中取得了显著的准确性提升。具体而言,Long等人(2015)表明,最初为图像分类开发的卷积网络架构可以成功地重新用于密集预测。这些重新用途的网络在具有挑战性的语义分割基准测试中明显优于先前的最先进方法。这引发了一些新的问题,这些问题受到图像分类和密集预测之间结构差异的启发。在重新用途的网络中,哪些方面是真正必要的,哪些在密集操作时会降低准确性?专门为密集预测设计的专用模块能否进一步提高准确性?
现代图像分类网络通过连续的池化和子采样层集成多尺度的上下文信息,以降低分辨率直到获得全局预测(Krizhevsky et al., 2012; Simonyan & Zisserman, 2015)。相比之下,密集预测需要将多尺度的上下文推理与全分辨率输出相结合。最近的研究工作探讨了两种处理多尺度推理和全分辨率密集预测冲突要求的方法。一种方法涉及重复的上卷积,旨在恢复丢失的分辨率,并将来自下采样层的全局视角保留下来(Noh et al., 2015; Fischer et al., 2015)。这引发了一个问题,即是否真正需要进行严重的中间降采样。另一种方法涉及将图像的多个尺度版本作为网络的输入,并组合这些多个输入获得的预测(Farabet et al., 2013; Lin et al., 2015; Chen et al., 2015b)。同样,目前尚不清楚是否真正需要对调整尺度的输入图像进行单独分析。
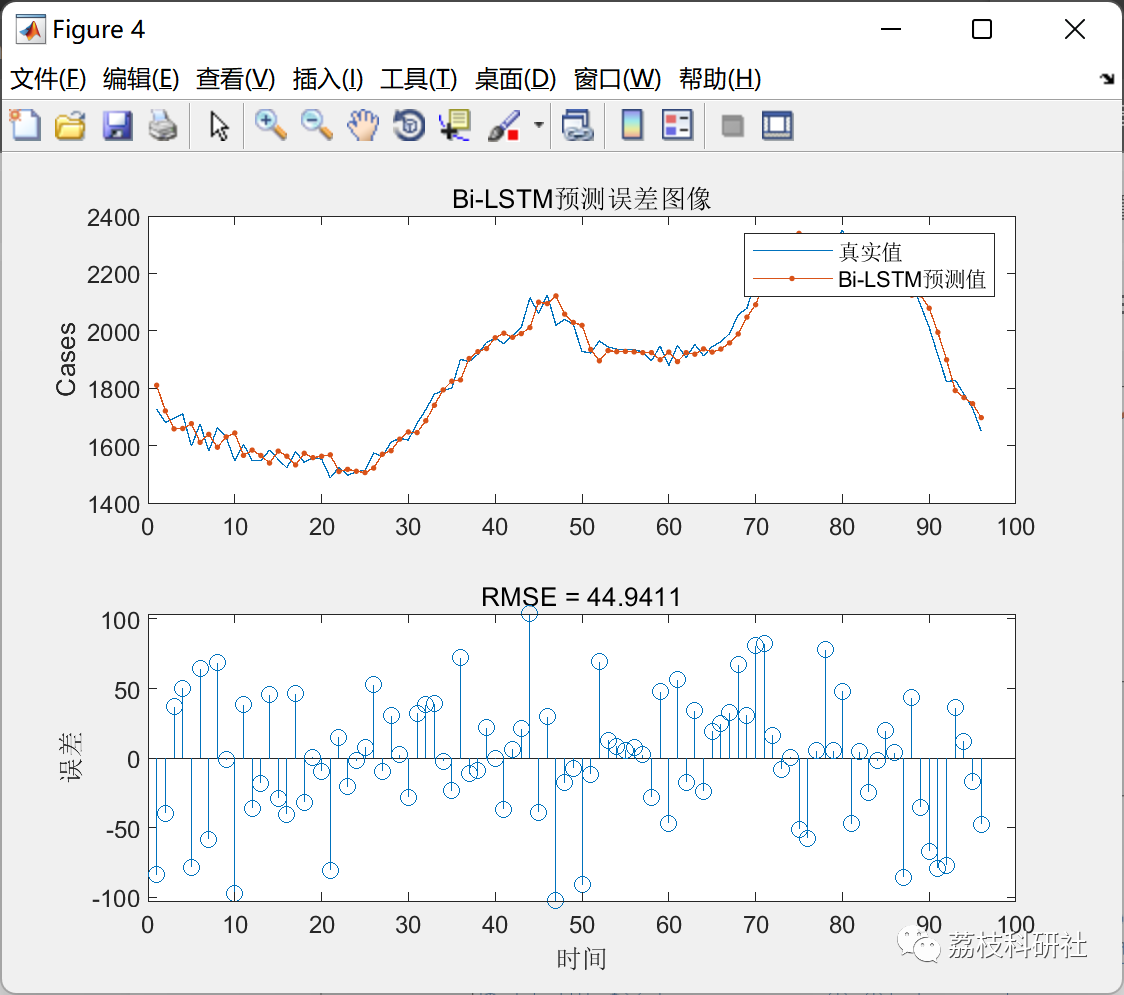
在这项工作中,我们开发了一个卷积网络模块,可以在不失去分辨率或分析调整尺度图像的情况下聚合多尺度的上下文信息。该模块可以插入到任何分辨率的现有架构中。与从图像分类中继承的金字塔形架构不同,所提出的上下文模块专门设计用于密集预测。它是一个由卷积层组成的长方体,没有池化或子采样。该模块基于扩张卷积,可以支持感受野的指数级扩展,而不会丢失分辨率或覆盖范围。作为这项工作的一部分,我们还重新检查了重新用途的图像分类网络在语义分割上的性能。核心预测模块的性能可能会被越来越复杂的系统所混淆,这些系统涉及结构化预测、多列架构、多个训练数据集和其他增强技术。因此,我们在受控环境中研究了深度图像分类网络的主要改进,并移除阻碍密集预测性能的残留组件。结果是一个简化的初始预测模块,比先前的改进方法更简单和更准确。使用简化的预测模块,我们通过对Pascal VOC 2012数据集(Everingham et al.,2010)进行受控实验来评估所提出的上下文网络。实验证明,将上下文模块插入现有的语义分割架构中可可靠地提高其准确性。
2.扩张卷积
设F: Z2 → R是一个离散函数。设Ωr = [−r;r]2 \ Z2,k: Ωr → R是一个大小为(2r + 1)2的离散滤波器。离散卷积运算符∗可以定义为(F ∗k)(p) = Σs+t=p F(s)k(t)。(1) 现在我们推广这个运算符。设l是一个扩张因子,定义∗l为(F ∗l k)(p) = Σs+lt=p F(s)k(t)。(2) 我们将∗l称为扩张卷积或l-扩张卷积。过去,扩张卷积运算符被称为“使用扩张滤波器的卷积”。它在小波分解的algorithme a trous`中扮演着关键的角色(Holschneider et al., 1987; Shensa, 1992)。我们使用术语“扩张卷积”而不是“使用扩张滤波器的卷积”,以澄清没有“构造或表示扩张滤波器”的意思。卷积运算符本身被修改为以不同的方式使用滤波器参数。扩张卷积运算符可以使用不同的扩张因子在不同的范围内应用相同的滤波器。我们的定义反映了扩张卷积运算符的正确实现方式,它不涉及构造扩张滤波器。在最近关于语义分割的卷积网络的研究中,Long等人(2015)分析了滤波器的扩张,但选择不使用它。Chen等人(2015a)使用扩张来简化Long等人(2015)的架构。相比之下,我们开发了一个新的卷积网络架构,系统地使用扩张卷积来进行多尺度上下文聚合。
我们的架构受到一个事实的启发,即扩张卷积支持指数级扩展的感受野,而不会丢失分辨率或覆盖范围。设F0;F1;:::;Fn−1: Z2 → R是离散函数,k0;k1;:::;kn−2: Ω1 → R是离散的3×3滤波器。考虑以指数级增加的扩张率应用这些滤波器:Fi+1 = Fi ∗2i ki,其中i =0;1;:::;n−2。(3)将Fi+1中元素p的感受野定义为改变Fi+1(p)值的F0中的元素集合。定义Fi+1中元素p的感受野大小为这些元素的数量。很容易看出,Fi+1中每个元素的感受野大小为(2i+2 −1)×(2i+2 −1)。感受野是一个指数级增加大小的正方形。如图1所示。

图1:系统化扩张支持感受野的指数级扩展,而不会丢失分辨率或覆盖范围。(a)通过1倍扩张卷积将F0生成F1;F1中的每个元素具有3×3的感受野。(b)通过2倍扩张卷积将F1生成F2;F2中的每个元素具有7×7的感受野。(c)通过4倍扩张卷积将F2生成F3;F3中的每个元素具有15×15的感受野。每个层的参数数量是相同的。感受野呈指数级增长,而参数数量呈线性增长。