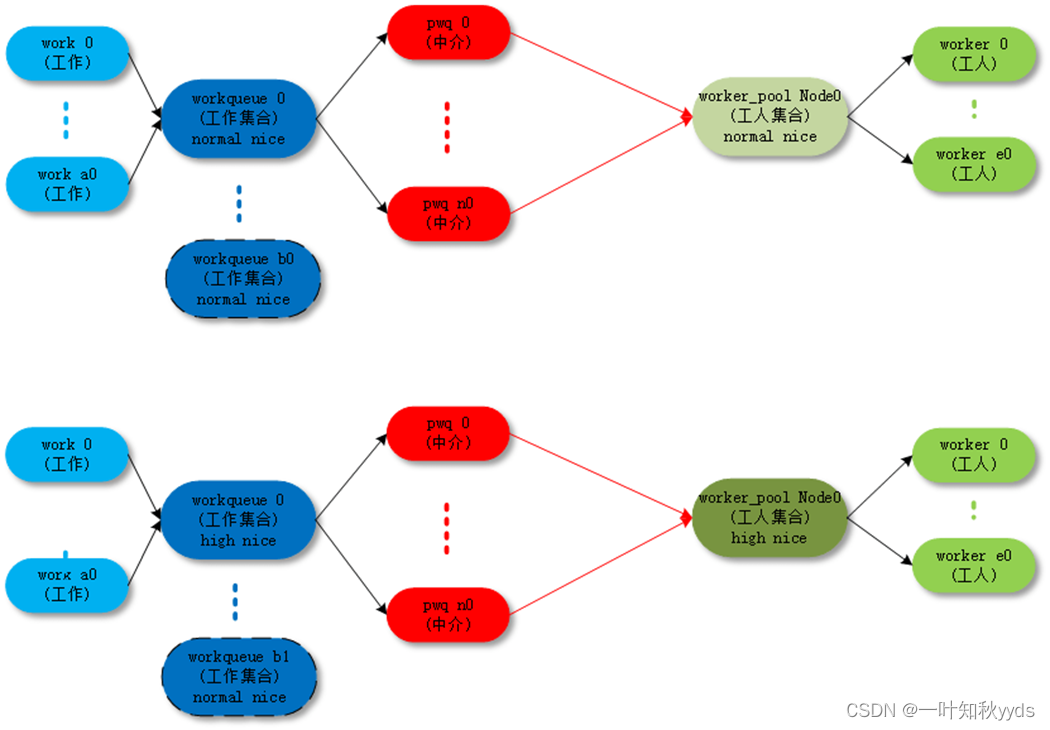
首先介绍一下工作队列使用的术语。
- work:工作,也称为工作项。
- work queue:工作队列,就是工作的集合, work queue 和 work 是一对多的关系。
- worker: 工人, 一个工人对应一个内核线程, 我们把工人对应的内核线程称为工人线程。
- worker_pool:工人池,就是工人的集合,工人池和工人是一对多的关系。
- pool_workqueue:中介,负责建立工作队列和工人池之间的关系。
工作队列和pool_workqueue 是一对多的关系, pool_workqueue 和工人池是一对一的关系。
最终的目的还是把 work( 工作 ) 传递给 worker( 工人 ) 去执行,中间的数据结构和各种关系目的是把这件事组织的更加清晰高效。
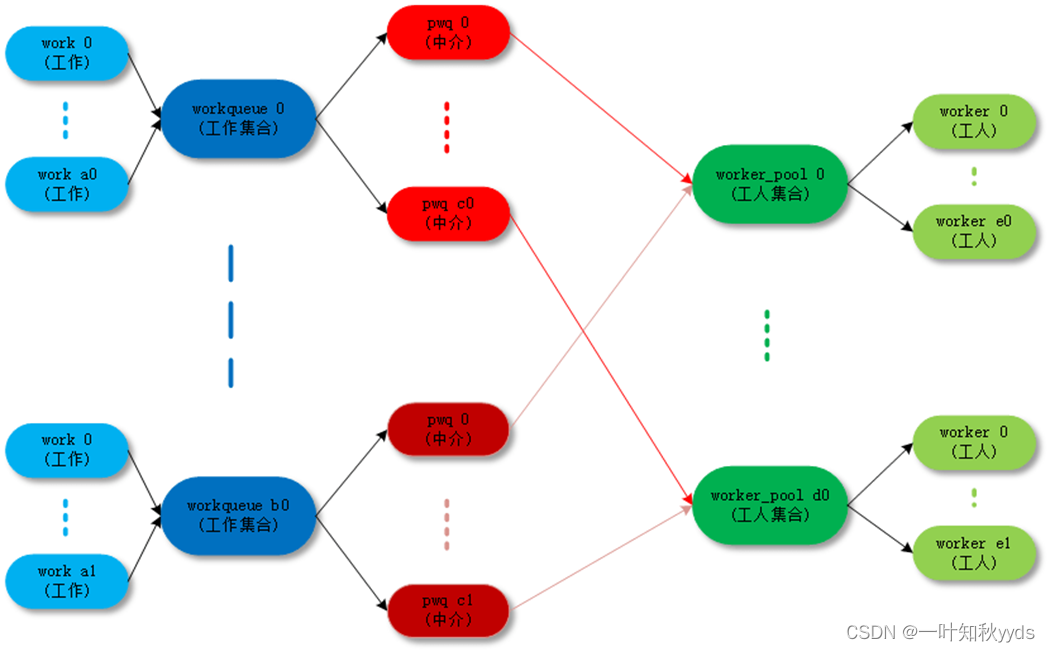
工作队列的分类有三种,分别是PerCpu, Unbound,以及ORDERED这三种类型,其实就是创建工作队列时所传的参数:WQ_UNBOUND、__WQ_ORDERED;其不同的体现主要在绑定的worker_pool的不同来提供不同的运行机制,下面就来看一下worker_pool。
worker_pool
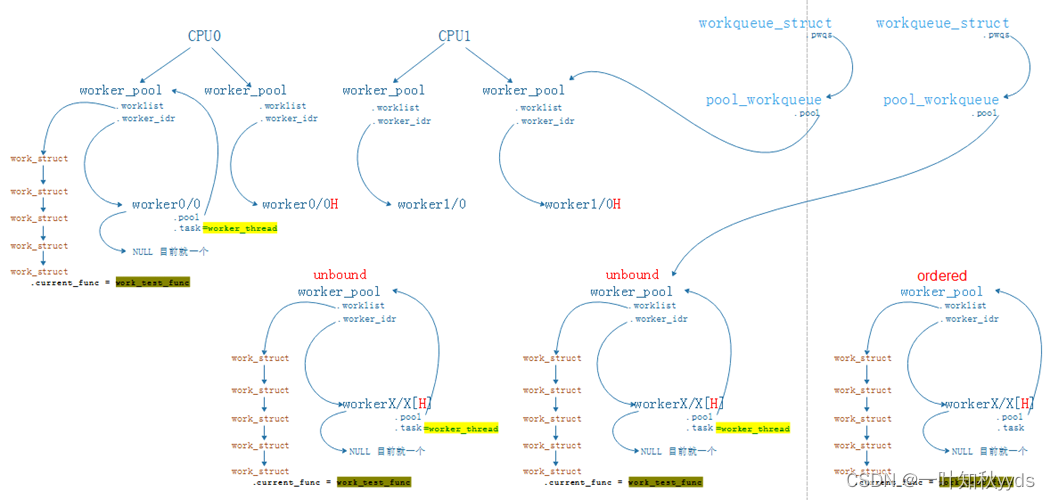
每个执行 work 的线程叫做 worker,一组 worker 的集合叫做 worker_pool。CMWQ 的精髓就在 worker_pool 里面 worker 的动态增减管理上 manage_workers()。
CMWQ 对 worker_pool 分成两类:
· normal worker_pool,给通用的 workqueue 使用;
· unbound worker_pool,给 WQ_UNBOUND 类型的的 workqueue 使用;
其中unbound worker_pool 也分成两类:
· unbound_std_wq。每个 node 对应一个 worker_pool,多个 node 就对应多个 worker_pool;
· ordered_wq。所有 node 对应一个 default worker_pool;
normal worker_pool
默认 work 是在 normal worker_pool 中处理的。系统的规划是每个 CPU 创建两个 normal worker_pool:一个 normal 优先级 (nice=0)、一个高优先级 (nice=HIGHPRI_NICE_LEVEL),对应创建出来的 worker 的进程 nice 不一样。
每个 worker 对应一个 worker_thread() 内核线程,一个 worker_pool 包含一个或者多个 worker,worker_pool 中 worker 的数量是根据 worker_pool 中 work 的负载来动态增减的。
我们可以通过 ps | grep kworker 命令来查看所有 worker 对应的内核线程,normal worker_pool 对应内核线程 (worker_thread()) 的命名规则是这样的:
snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
pool->attrs->nice < 0 ? "H" : "");
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
so 类似名字是 normal worker_pool:
组织图如下:
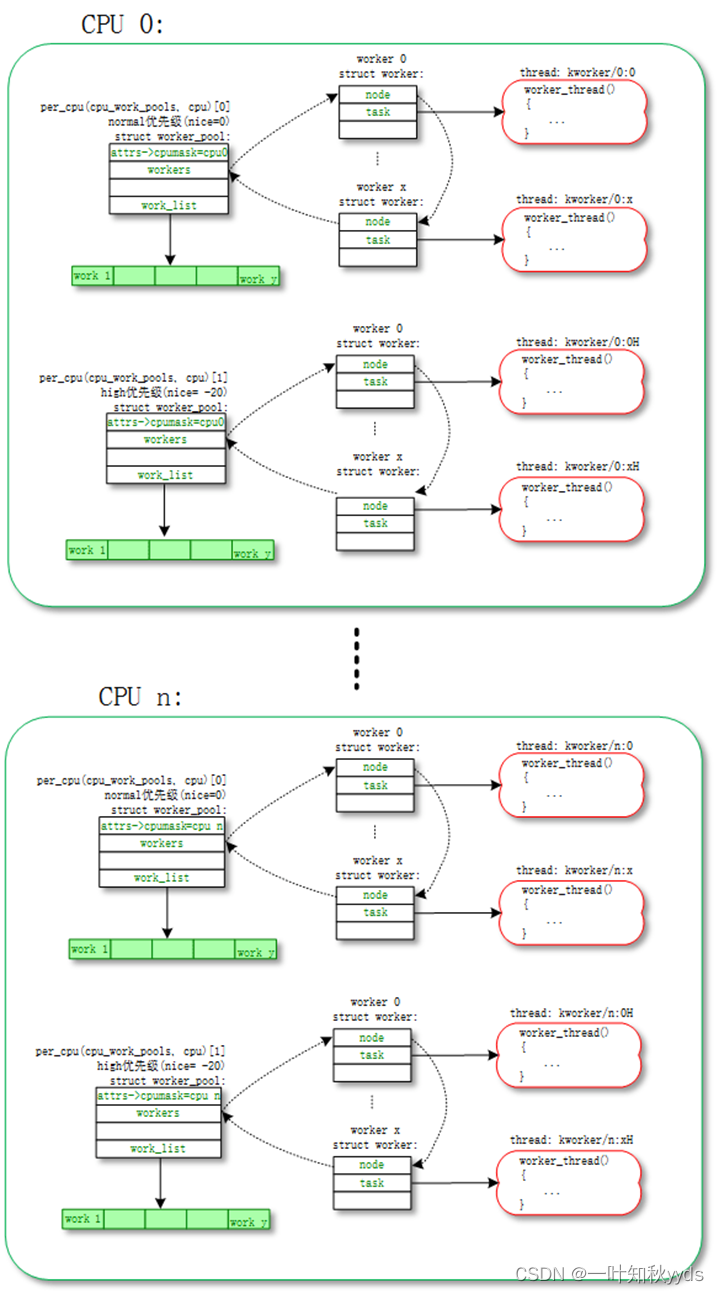
normal worker_pool
对应的拓扑图如下:

unbound worker_pool
大部分的 work 都是通过 normal worker_pool 来执行的 ( 例如通过 schedule_work()、schedule_work_on() 压入到系统 workqueue(system_wq) 中的 work),最后都是通过 normal worker_pool 中的 worker 来执行的。这些 worker 是和某个 CPU 绑定的,work 一旦被 worker 开始执行,都是一直运行到某个 CPU 上的不会切换 CPU。
unbound worker_pool 相对应的意思,就是 worker 可以在多个 CPU 上调度的。但是他其实也是绑定的,只不过它绑定的单位不是 CPU 而是 node。所谓的 node 是对 NUMA(Non Uniform Memory Access Architecture) 系统来说的,NUMA 可能存在多个 node,每个 node 可能包含一个或者多个 CPU。
unbound worker_pool 对应内核线程 (worker_thread()) 的命名规则是这样的:
snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
so 类似名字是 unbound worker_pool:
unbound worker_pool 也分成两类:
unbound_std_wq
每个 node 对应一个 worker_pool,多个 node 就对应多个 worker_pool;
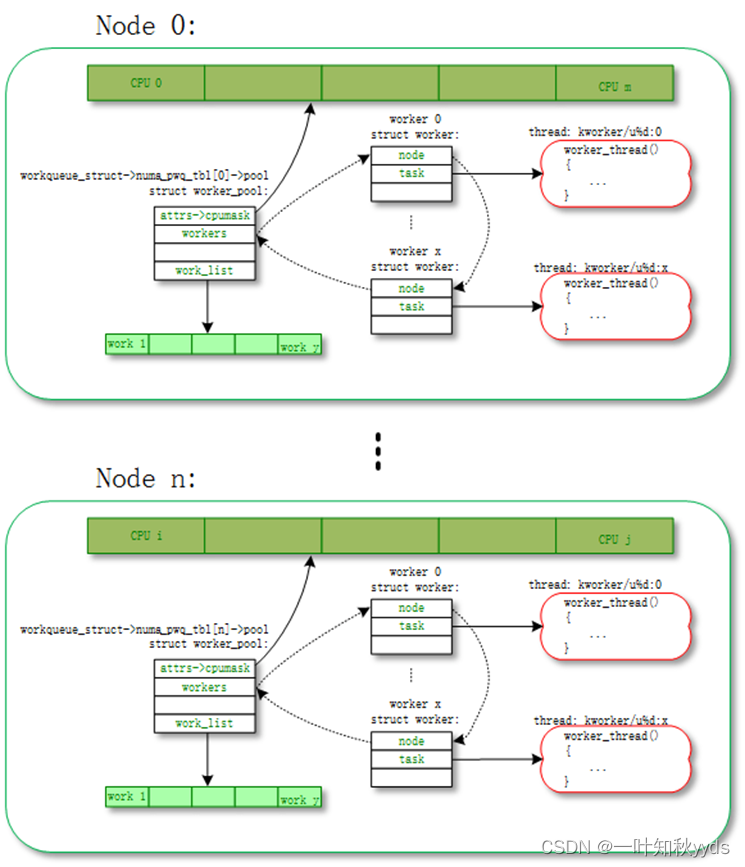
unbound worker_pool: unbound_std_wq
对应的拓扑图如下:

unbound_std_wq topology
ordered_wq
所有 node 对应一个 default worker_pool;
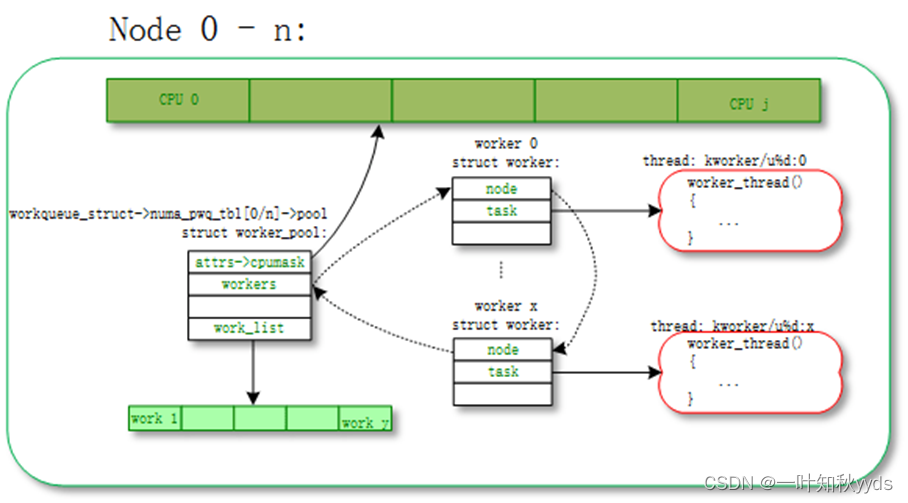
unbound worker_pool: ordered_wq
对应的拓扑图如下:
ordered_wq topology
整体结构图
分析总结
我们知道工作队列有三种,分别是PerCpu, Unbound,以及ORDERED这三种类型,正如之前的文档分析:
1.PerCpu的工作队列:
create_workqueue(name)
这种工作队列在queue_work的时候,首先检查当前的Cpu是哪一个,然后将work调度到该cpu下面的normal级别的线程池中运行。
注:针对PerCpu类型而言,系统在开机的时候会注册2个线程池,一个低优先级的,一个高优先级的。
2.Unbound的工作队列:
create_freezable_workqueue(name)
这种工作队列在queue_work的时候,同样首先检查当前的Cpu是哪一个,随后需要计算当前的Cpu属于哪一个Node,因为对于Unbound的工作队列而言,线程池并不是绑定到cpu的而是绑定到Node的,随后找到该Node对应的线程池中运行。需要留意的是这种工作队列是考虑了功耗的,例如:当work调度的时候,调度器会尽量的让已经休眠的cpu保持休眠,而将当前的work调度到其他active的cpu上去执行。
注:对于NUMA没有使能的情况下,所有节点的线程池都会指向dfl的线程池。
3.Ordered的工作队列:
create_singlethread_workqueue(name) 或者 alloc_ordered_workqueue(fmt,flags, args…)
这种work也是Unbound中的一种,但是这种工作队列即便是在NUMA使能的情况下,所有Node的线程池都会被指向dfl (ordered_wq)的线程池,换句话说Ordered的工作队列只有一个线程池,因为只有这样才能保证Ordered的工作队列是顺序执行的,而这也是本文分析的切入点。
有关并发问题的总结性陈述:
首先对于Ordered的工作队列(create_singlethread_workqueue,其他自定义的API则不一定了)这是严格顺序执行的,绝对不可能出现并发(无论提交给wq的是否是同一个work)。
但是对于PerCpu的工作队列(create_workqueue),其中对于提交给wq的如果是同一个work,那么也不会并发,会顺序执行。但是如果提交给wq的不是同一个work,则会在不同的cpu间并发。需要特别留意的是,其并不会在同一个CPU的不同线程间并发,这是因为create_workqueue这个API定义的max_active为1,也就意味者,当前wq只能最多在每个cpu上并发1个线程。
另外:
if ((flags & WQ_UNBOUND) && max_active == 1)
flags |= __WQ_ORDERED;
对于最大worker为1且没绑定具体cpu的workqueue,系统也是默认整个workqueue是有序执行的。