1、先正常python train 一个模型
yolo task=detect mode=train model=/home//v8/v8-ori-x/yolov8x.pt data=/home/v8/v8-ori-x/ultralytics/cfg/datasets/111.yaml epochs=300 batch=16 device=6
2、再正常python val --各种参数 --save_json=True,这一步的作用是要生成自己模型预测的json文件
yolo task=detect mode=val model=/home/v8yolov8-main/runs/train/exp/weights/best.pt data=/home/v8/yolov8-main/dataset/pheno.yaml batch=1 device=6 save_txt save_conf split=test save_json=True
3、将自己的YOLO格式数据集和标签转化为json格式,类别也需要改一下,下面只需要修改图片路径和你的标签路径就行,然后保存路径也可以改改
python yolo2coco.py
转化的代码:
yolo2coco.py:
import os
import cv2
import json
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import argparseclasses = ['soil', 'crop', 'weed']# 这里改一下parser = argparse.ArgumentParser()
parser.add_argument('--image_path', default='/home/val/images',type=str, help="path of images")# 图片路径改一下
parser.add_argument('--label_path', default='/home/val/labels',type=str, help="path of labels .txt")#图片标签路径改一下
parser.add_argument('--save_path', type=str,default='/home/val.json', help="if not split the dataset, give a path to a json file")
arg = parser.parse_args()def yolo2coco(arg):print("Loading data from ", arg.image_path, arg.label_path)assert os.path.exists(arg.image_path)assert os.path.exists(arg.label_path)originImagesDir = arg.image_path originLabelsDir = arg.label_path# images dir nameindexes = os.listdir(originImagesDir)dataset = {'categories': [], 'annotations': [], 'images': []}for i, cls in enumerate(classes, 0):dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})# 标注的idann_id_cnt = 0for k, index in enumerate(tqdm(indexes)):# 支持 png jpg 格式的图片.txtFile = f'{index[:index.rfind(".")]}.txt'stem = index[:index.rfind(".")]# 读取图像的宽和高try:im = cv2.imread(os.path.join(originImagesDir, index))height, width, _ = im.shapeexcept Exception as e:print(f'{os.path.join(originImagesDir, index)} read error.\nerror:{e}')# 添加图像的信息if not os.path.exists(os.path.join(originLabelsDir, txtFile)):# 如没标签,跳过,只保留图片信息.continuedataset['images'].append({'file_name': index,'id': stem,'width': width,'height': height})with open(os.path.join(originLabelsDir, txtFile), 'r') as fr:labelList = fr.readlines()for label in labelList:label = label.strip().split()x = float(label[1])y = float(label[2])w = float(label[3])h = float(label[4])# convert x,y,w,h to x1,y1,x2,y2H, W, _ = im.shapex1 = (x - w / 2) * Wy1 = (y - h / 2) * Hx2 = (x + w / 2) * Wy2 = (y + h / 2) * H# 标签序号从0开始计算, coco2017数据集标号混乱,不管它了。cls_id = int(label[0]) width = max(0, x2 - x1)height = max(0, y2 - y1)dataset['annotations'].append({'area': width * height,'bbox': [x1, y1, width, height],'category_id': cls_id,'id': ann_id_cnt,'image_id': stem,'iscrowd': 0,# mask, 矩形是从左上角点按顺时针的四个顶点'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]})ann_id_cnt += 1# 保存结果with open(arg.save_path, 'w') as f:json.dump(dataset, f)print('Save annotation to {}'.format(arg.save_path))if __name__ == "__main__":yolo2coco(arg)
4、修改你自己的数据集json文件和预测的json文件,就可以输出了
python get_COCO_metrice.py --pred_json /home/yolov8-main/runs/val/exp3/predictions.json
get_COCO_metrice.py:
import argparse
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOevaldef parse_opt():parser = argparse.ArgumentParser()parser.add_argument('--anno_json', type=str, default='/home/val.json', help='training model path')parser.add_argument('--pred_json', type=str, default='', help='data yaml path')return parser.parse_known_args()[0]if __name__ == '__main__':opt = parse_opt()anno_json = opt.anno_jsonpred_json = opt.pred_jsonanno = COCO(anno_json) # init annotations apipred = anno.loadRes(pred_json) # init predictions apieval = COCOeval(anno, pred, 'bbox')eval.evaluate()eval.accumulate()eval.summarize()
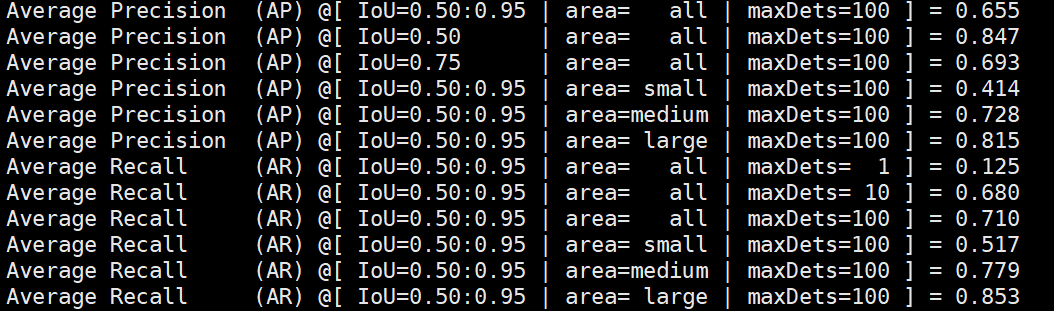
5、生成结果图,实测可行


![[论文精读]利用大语言模型对扩散模型进行自我修正](https://img-blog.csdnimg.cn/direct/c3e4df843fc34f8da407de61f6620427.png#pic_center)