在大数据和人工智能时代,数据的重要性变得更加突出。以下是数据在这个时代的重要性所体现的几个方面:
决策依据
模型训练
个性化服务
创新驱动
智能决策支持
本文,将介绍两个获取数据的方法
1、利用爬虫框架写采集程序
在前面,我介绍了两个编写爬虫程序获取数据的经典案例:
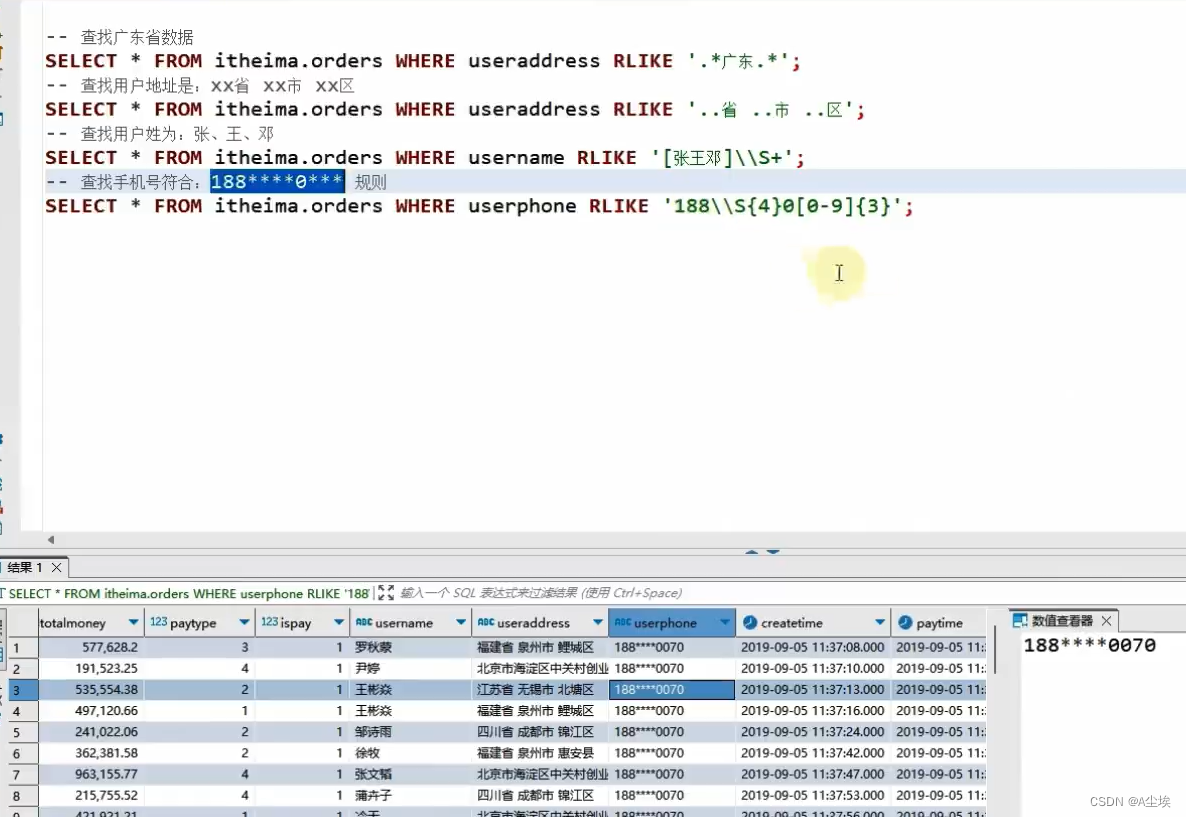
Python数据分析实战-爬取以某个关键词搜索的最新的500条新闻的标题和链接(附源码和实现效果)
Python数据分析实战-爬取豆瓣电影Top250的相关信息并将爬取的信息写入Excel表中(附源码和实现效果)
回顾总结一下第一个案例,通过爬虫获取数据有以下几个步骤:
1、安装所需的库:你需要安装requests和beautifulsoup4库。可以使用以下命令通过pip安装:
pip install requests beautifulsoup4
-
发起搜索请求并获取多个搜索结果页面的HTML内容。可以使用以下代码实现:
import requestsdef search_baidu(keyword, page):url = f"https://www.baidu.com/s?wd={keyword}&pn={page}&rn=10"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:return None
-
解析搜索结果并提取新闻标题和链接:使用
beautifulsoup4库解析HTML内容。可以使用以下代码实现:
from bs4 import BeautifulSoupdef parse_search_results(html):soup = BeautifulSoup(html, "html.parser")news_results = soup.find_all("h3", class_="t")news_list = []for result in news_results:title = result.a.textlink = result.a["href"]news_list.append({"title": title, "link": link})return news_list
-
完整的爬取过程:将上述步骤整合到一个函数中,实现完整的爬取过程。可以使用以下代码实现:
def crawl_latest_news(keyword, num_news):news_list = []num_pages = num_news // 10 + 1 # 每页10条新闻,计算需要请求的页面数for page in range(num_pages):html = search_baidu(keyword, page * 10)if html:page_news = parse_search_results(html)news_list.extend(page_news)else:print(f"无法获取第 {page+1} 页的搜索结果")return news_list[:num_news]
主程序入口:调用crawl_latest_news函数,并传入你想要搜索的关键词和要获取的新闻数量(这里是500),获取最新的500条新闻列表。例如:
keyword = "开源之夏"
num_news = 500
news_list = crawl_latest_news(keyword, num_news)
if news_list:for news in news_list:print(news["title"])print(news["link"])print()
else:print("无法获取搜索结果")上述中,我们总结了 python 编写采集程序实现简单的爬虫的几个步骤。但是在实际中会遇到很多问题,主要体现在以下几个方面:
-
限制 IP 的访问次数(许多站点有反爬机制)
-
复杂页面爬虫,对代码要求比较高
-
对大型爬虫项目,数据的后期处理比较麻烦
在此,我为大家介绍第二种获取数据的方法,数据收集平台Bright Data
2、全球网络数据一站式平台-Bright Data
作为世界一号数据收集平台,财富500强,学术机构和中小企业信赖和喜爱的公司,亮数据Bright Data以高效、可靠和灵活的方式检索提取关键的公共网络数据而著称,这些数据帮助用户研究、监控、分析并做出最好的决策。亮数据Bright Data的产品涵盖了从零代码解决方案到工程师和IT专业人员使用的强大基础设施,数据收集平台被全球几乎所有行业的,成千上万客户所使用。

使用教程:
-
注册完成之后登录界面
-
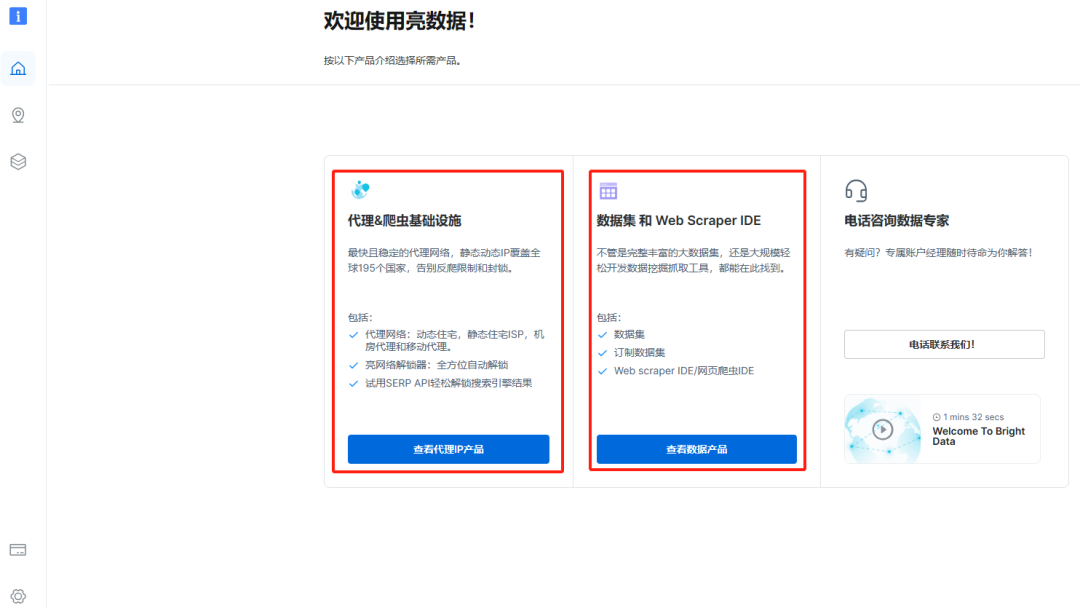
可以看到主要有两部分:代理爬虫基础设施 和 数据集和Web Scraper IDE,平台大致提供了以下三种服务:
-
代理服务:通过真实的代理 IP 来爬虫,避免 IP 地址的限制。
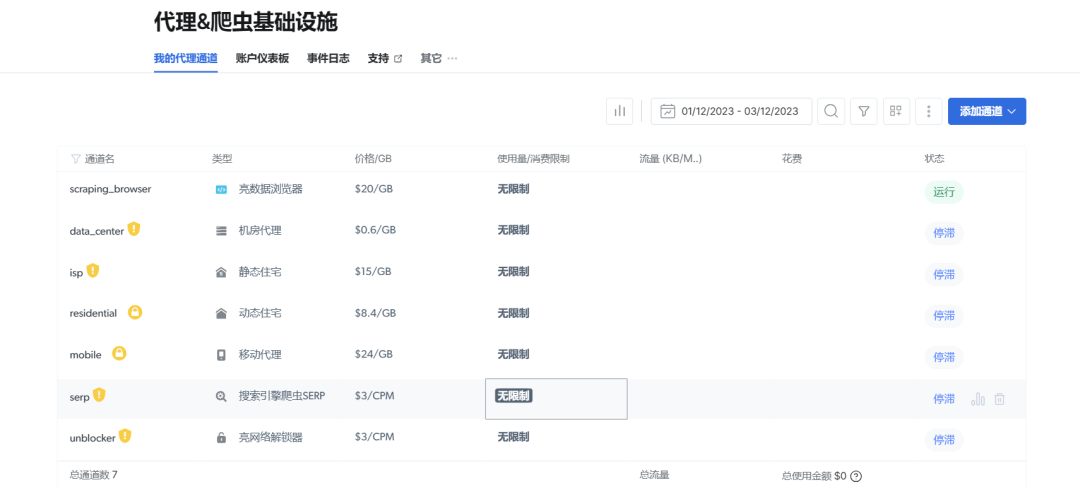
-
数据集服务
-
数据集商城:提供已爬好的一些知名站点数据,可以直接使用。
-
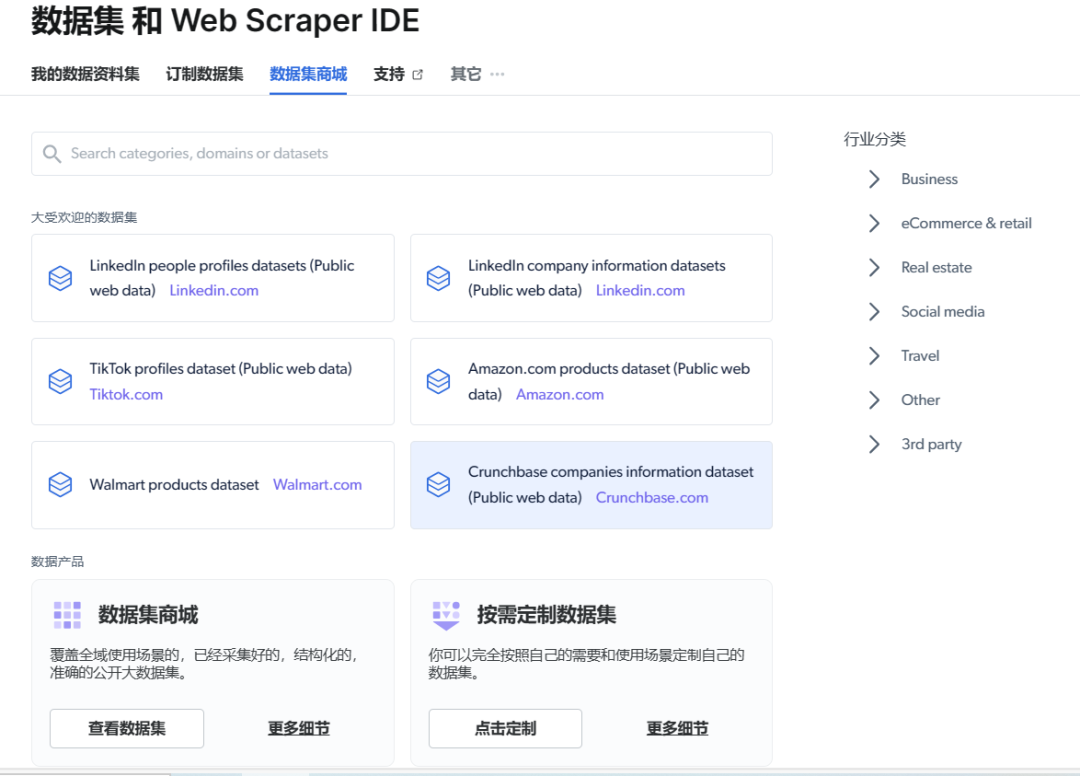
-
-
按需定制数据集:可以定制数据。以获取豆瓣电影Top250的数据为例。
-
定义收集范围、频率并提供示例
-
-
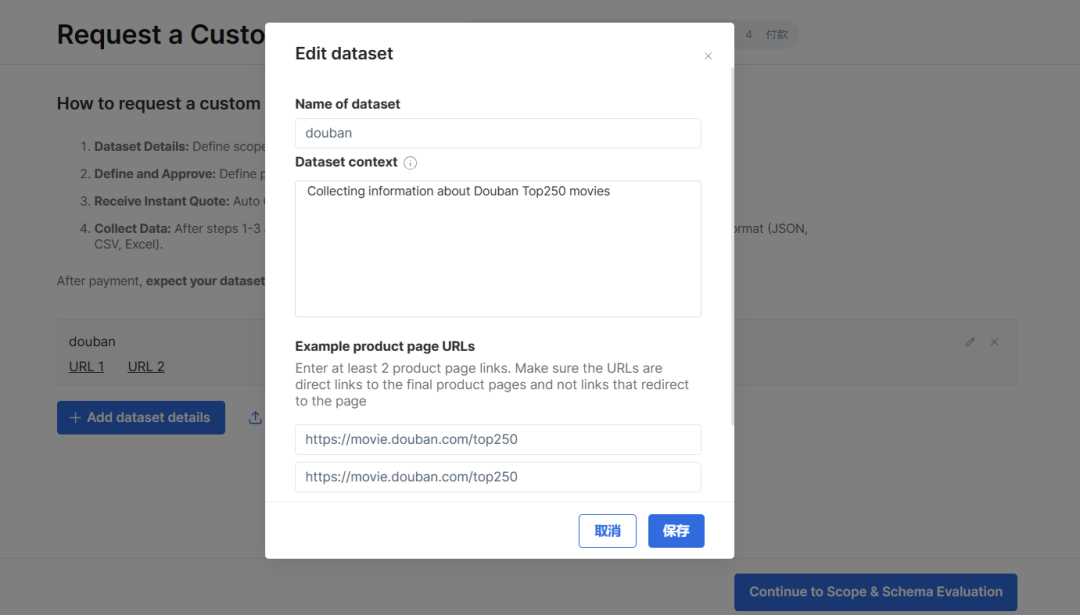
-
-
-
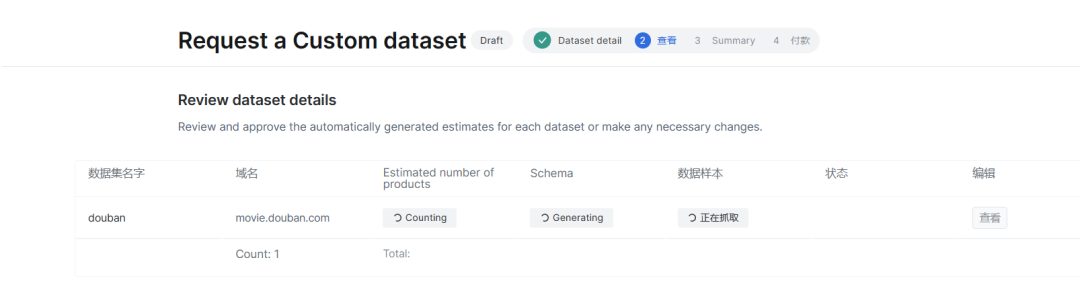
定义项目范围,审查并批准数据模式和样本
-
-
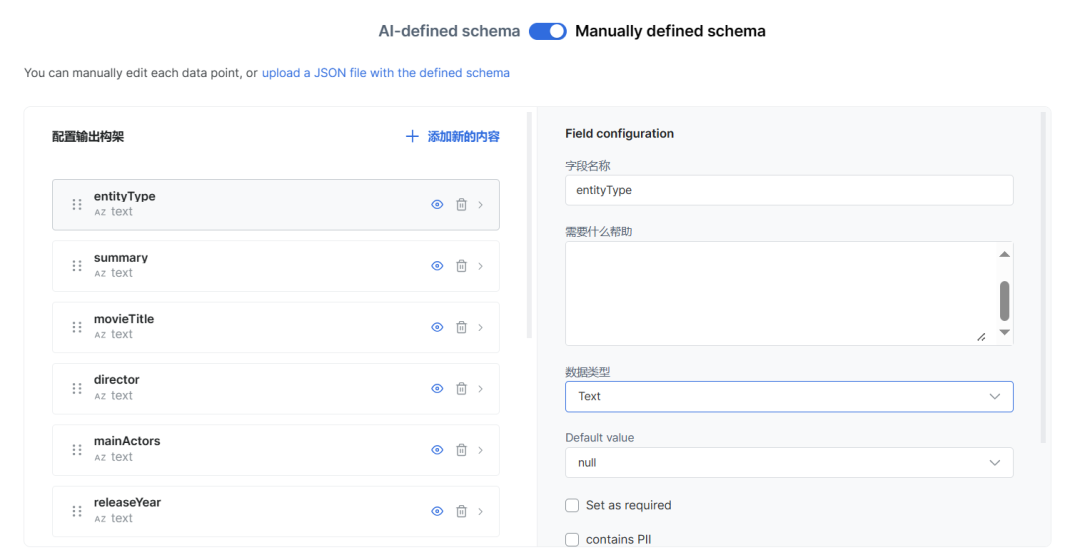
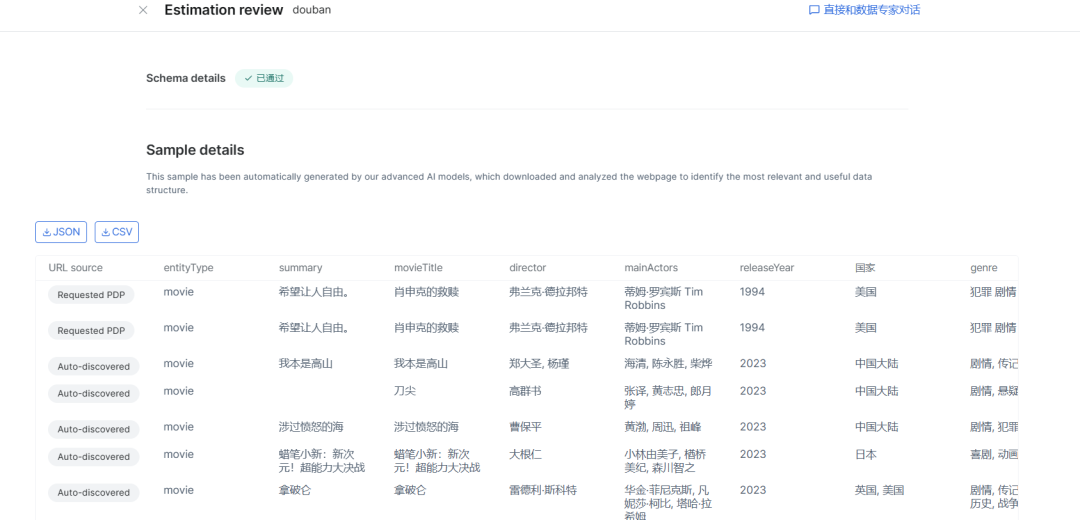
-
-
-
开始收集数据,并以您喜欢的频率和格式(JSON、CSV、Excel)提供数据
-
-

-
网络爬虫IDE服务:官方提供了 web 端的 IDE工具,并提供了相关的示例代码,可以直接使用!
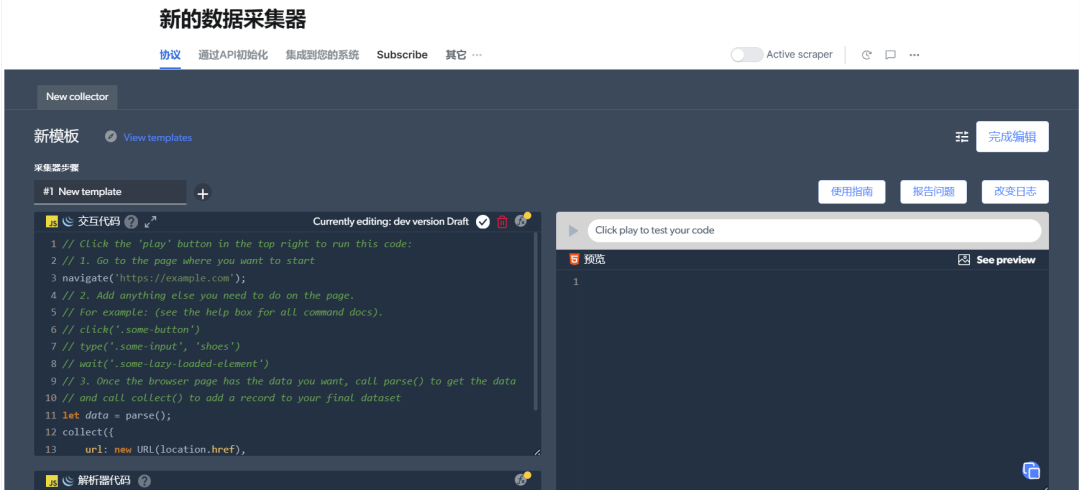
想要获取重要数据,对于不懂编程、苦恼于反爬以及后期数据处理的你,不妨去试一试这个产品!
点击阅读原文或者打开下面地址即可使用:https://get.brightdata.com/q05ze5izo1i9