几个月前我们就聊过RAG的经典方案解密Prompt系列14. LLM Agent之搜索应用设计。前几天刚看完openAI在DevDay闭门会议上介绍的RAG相关的经验,有些新的感悟,借此机会再梳理下RAG相关的优化方案。推荐直接看原视频(外网)A Survey of Techniques for Maximizing LLM Performance
RAG最关键的一环其实不是LLM而是相关内容的召回,作为大模型推理的上文,优秀的内容召回应该满足以下条件:
-
多样性和召回率:召回的内容要可以回答问题,并且内容丰富度,包括同一问题多个观点,多角度
-
相关性和准确率:召回内容和问题相关,总不能召回100篇里面只有2篇和问题有关
-
一致性和低冲突:召回内容间的观点一致性较高
-
更高要求:高时效性,权威性,观点完整性,内容重复度低
这里不妨借鉴前人经验,参考搜索的主流框架:Query理解和扩展 -> 多路召回 -> 合并排序 -> 重排和打散。过去几个月RAG的论文也像是把传统搜索的方案,使用LLM轮番做了一遍范式更新。本章我们先围绕召回内容的多样性唠上两句。
直接使用用户Query进行向量检索,召回率往往不高,原因有以下几个
-
query较短,本身信息有限
-
短文本的embedding效果较差
-
query短文本向量和document长文本向量存在空间表征差异
-
用户对自己想问的内容比较模糊
-
用户的query提问可能需要多个方向的信息聚合才能回答
以上问题其实覆盖了两个点:Query本身包含信息的多样性,搜索索引的多样性。下面我们结合新老论文,以及langchain新增的一些功能,来分别介绍~
1. Query多样性
2019 Query Expansion Techniques for Information Retrieval: a Survey
传统搜索Query的扩展,有基于用户搜索日志挖掘的相似Query,有基于相同召回文档关联的相似Query,也有基于SMT的Query改写方案。那和大模型时代更搭配的自然是改写方案,LLM的加持很大程度上降低了Query改写的难度,也为改写提供了更多的可能性。
1.1 相似语义改写
Learning to Rewrite Queries,雅虎(2016)
webcpm: Interactive Web Search for Chinese Long-form Question Answering,清华(2023)
比较早在16年yahoo就探索过query改写的方案,那时还是个seq2seq的LSTM。再就是之前介绍的webcpm也有使用大模型进行query改写来提高内容召回。近期langchain也集成了MultiQueryRetriever的类似功能。逻辑就是把用户的Query改写成多个语义相近的Query,使用多个Query一起进行召回,如下
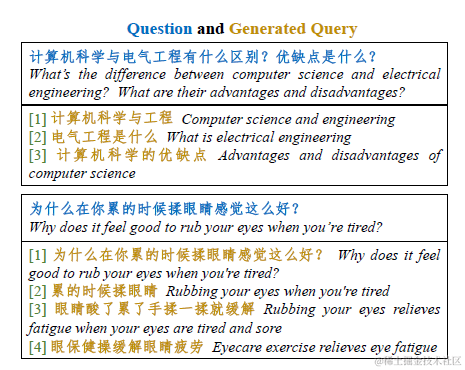
1.2 双向改写
Query2doc: Query Expansion with Large Language Models,微软(2023)
Query Expansion by Prompting Large Language Models, 谷歌(2023)
除此之外还有一种另类Query的改写方案,就是Query2doc中提到的把Query改写成document。论文使用4-shot prompt让LLM先基于query生成一个pseudo-document,然后使用生成的答案来进行相关内容的召回。这种改写方案确实有一些显著的优点
-
缓解短文本query向量化效果较差的问题
-
缓解document长文本向量和query短文本向量存在空间差异的问题
-
提高BM25等离散索引抽取的效果,毕竟文本长了更容易抽出有效关键词
当然缺点也很显著,一个是pseudo-docuemnt可能发生语义漂移,幻觉回答会引入错误的关键词降低召回的准确率,以及解码的耗时较长~

这里Query2Doc反过来写,Doc2Query也是另外一个优化方向,就是给每篇文档都生成N个关联Query(pseudo-query),使用关联Query的embedding向量来表征文档,和真实Query进行相似度计算。langchain的MultiVector Retriever也集成了类似的功能。
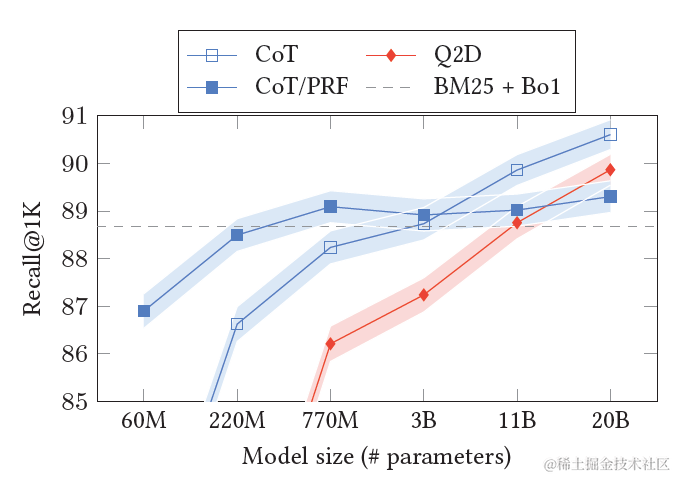
谷歌也做了类似的尝试。分别对比了Query2Doc(Q2D), Query2Keyword(Q2E), Query2COT几种改写方案,以及使用zero-shot,few-shot,召回文档增强等不同prompt指令的效果。其中Query2Doc采用了和上面微软相同的prompt指令,其他指令如下

结果显示,当模型规模足够大之后,Query2COT展现出了显著更优的效果。甚至超越了在上文中加入相关文档的COT/PRF 方案。一方面COT会对Query进行多步拆解,一方面思考的过程会产生更有效的关键词,以及不使用相关文档可以更有效的释放模型本身的知识召回能力和创造力。
1.3 强化学习改写
ASK THE RIGHT QUESTIONS: ACTIVE QUESTION REFORMULATION WITH REINFORCEMENT LEARNING,谷歌(2018)
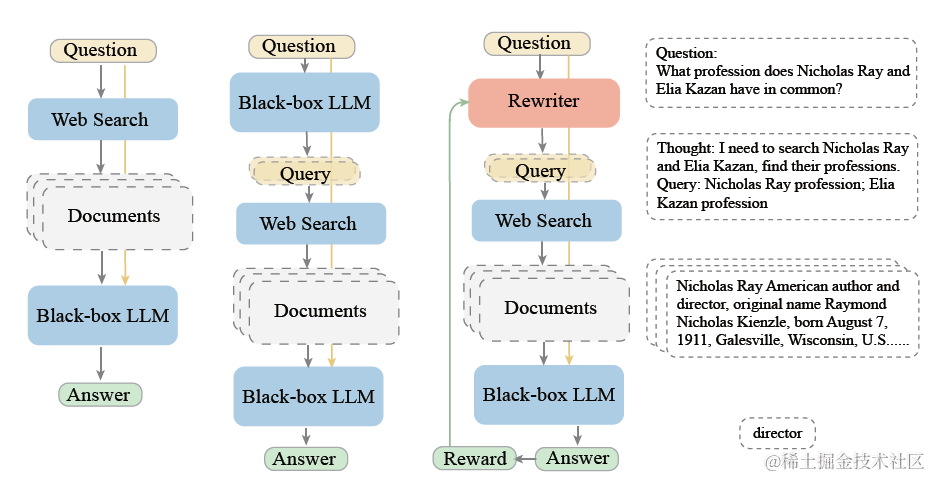
Query Rewriting for Retrieval-Augmented Large Language Models,微软(2023)
以上的改写方案在openai的闭门会都有提到,确实一定程度上可以提升RAG的效果,可以用于初期的尝试。不过这种改写是无监督的,也就是基于相似语义进行改写,并不能保证改写后的query搜索效果一定更好。那我们不妨引入一个目标来定向优化改写效果。
2018年谷歌就曾尝试使用强化学习来优化改写模型,把搜索系统视作Environment,seq2seq模型生成多个Query的改写候选作为Action。把原始Query的召回内容,和改写Query的召回内容,一起送入后面的排序模块,使用排序模块TopK内容中改写Query召回内容的召回率作为Reward打分,来梯度更新改写模型,最大化改写召回率。毕竟不论你改写的多么花里胡哨,能有效提高内容召回,拥有更高的独占召回率才是真正有用的改写模型。
而在大模型时代,改写模块被升级为LLM。在微软提出的rewrite-retrieve-read框架中,使用大模型作为rewriter,Bing搜索作为Retriever,chatgpt作为Reader,在QA任务上,尝试使用PPO微调改写模型,Reward模型的目标是不同改写query召回后推理内容和真实答案的Exact Match和F1。不过真实场景中,这种有标准答案的QA问答其实占比很小,更多都是开放式问答。那么其实可以类比以上的传统方案,使用大模型推理的引用率,作为Reward目标。毕竟大模型选择哪几条输入的上文进行推理,和精排原理其实是相似的。
2. 索引扩展
简单说完query扩展,我们再来看下索引扩展。当前多数RAG得召回索引还是以单一的Embedding向量模型为主,但单一向量作为召回索引有以下几个常见问题
-
文本的相似有不同类型:有语义相似,有语法结构相似,有实体关键词相似,单一维度无法区分etc
-
文本的相似有不同粒度:有些场景下需要召回精准匹配的内容,有些则需要模糊匹配,多数向量模型的区分度有限
-
不同领域相似定义不同:在垂直领域存在向量模型适配度较低的问题
-
长短文本间的相似问题:长短文本向量可能不在一个向量空间
下面我们看下还有哪些索引类型可以作为单一向量的补充
2.1 离散索引扩展
Query Expansion by Prompting Large Language Models, 谷歌(2023)
ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
传统搜索中往往会使用到大量的离散索引,在很多垂直领域的内容召回中往往和向量召回有很好的互补效果,部分离散索引例如实体的召回准确率可能会显著高于向量召回。一些常见的Query理解生成离散索引的方案包括:
-
抽取: 分词,新词ngram识别,词性识别,实体抽取,关键词抽取etc
-
分类:意图分类,话题分类,概念分类,地点分类etc
-
多跳:实体链接,同义词扩展,KG查询etc
最先想到使用大模型来进行范式改良的方向,大家都不约而同把目光放在了关键词扩展。
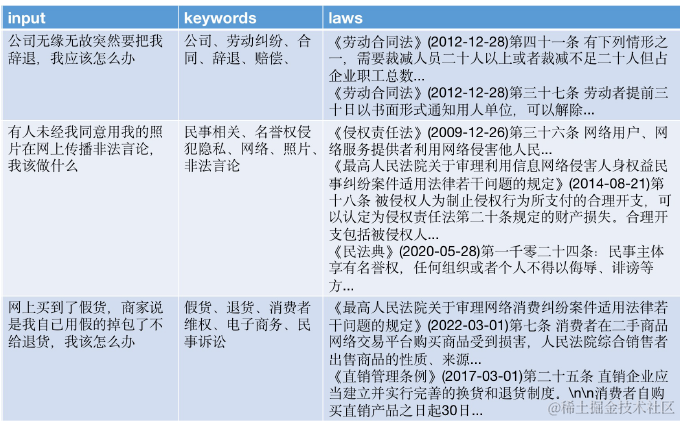
虽然在上面谷歌的论文中尝试query2Keyword的效果并没有超越query2Doc和Query2COT。但是关键词生成本身低耗时,以及在一些垂直领域其实有很好的效果。例如ChatLaw一个法律领域的大模型,就是用了LLM进行法律条文的关键词联想。论文使用LLM针对用户Query生成法律相关联想关键词,并使用关键词的Ensemble Embedding来召回对应的法律条款。当然也可以使用关键词直接进行召回。这种设计其实是针对在法律领域,领域关键词往往有显著更好的召回效果而设计的。
2.2 连续索引扩展
https://github.com/FlagOpen/FlagEmbedding
https://github.com/shibing624/text2vec
https://github.com/Embedding/Chinese-Word-Vectors
AUGMENTED EMBEDDINGS FOR CUSTOM RETRIEVALS, 微软2023
向量索引的扩展,最先想到的就是同时使用多种不同的连续向量索引,包括
-
朴素模式:不同的Embedding模型,常见的就是OpenAI的Ada,智源的BGE,还有Text2vec系列,使用多路embedding模型同时召回,或者加权召回的方案,取长补短。
-
简单模式:使用以上抽取的关键词,使用词向量加权进行召回。相比文本向量,词向量的召回率往往更高,在一些垂直领域有很好的效果。当然反过来就是词向量可能准确率偏低,不过召回阶段本来就是广撒网多敛鱼
-
Hard模式:训练领域Embedding。成本最高,可以放在最后面尝试,在openai devday上提及的观点也是领域模型对比通用模型提升有限,且成本较高
不过微软近期提出了一个相比微调领域embedding模型更加轻量化的方案,和lora微调的思路类似,咱不动基座模型,但是在上面微调一个adapter来定向优化query和document的匹配效果。
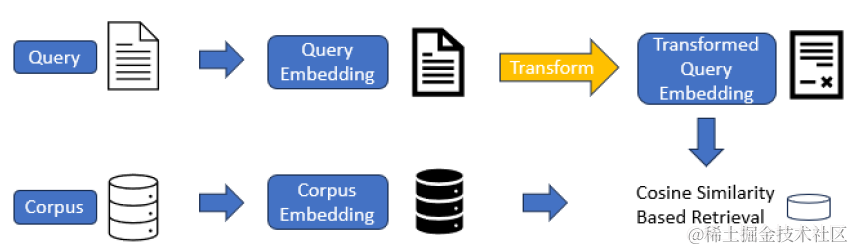
向量变化的adapter,论文使用了向量加法,就是在原始模型输出的D维embedding的基础上加一个residual,residual的计算是一个Key-Value lookup函数,包含两个相同shape的变量K和v。例如针对openai的向量输出是D =1536维,residual会选用h<<D来进行变换,h的取值在16~128,则K和V都分别是h*D维的矩阵,也就是adapter部分只需要梯度更新2hD量级的参数,如下
微调损失函数使用了对比学习的GlobalNegative Loss,也就是每个(query,content)pair是正样本,其余样本内所有content均是负样本,学习目标是query和正样本的相似度>和其余所有负样本相似度的最大值。看起来似乎是很轻量的方案,有机会准备去试一下~
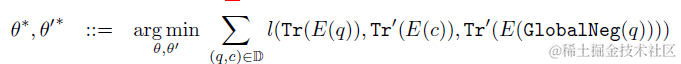
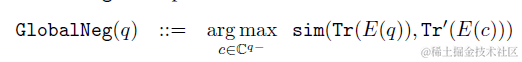
2.3 混合索引召回
Hybrid search scoring (RRF) - Azure AI Search | Microsoft Learn
把BM25等离散索引召回和Embedding向量等连续索引召回进行混合召回,langchain的Ensemble Retriever集成了这个功能。不过混合召回最大的问题是不同召回的打分较难进行排序。因此当多路混合召回内容较多时,需要引入排序模块对内容做进一步筛选过滤,这个我们放到后面再说啦~
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
文章转载自:风雨中的小七
原文链接:https://www.cnblogs.com/gogoSandy/p/17873827.html