🌷🍁 博主猫头虎 带您 Go to New World.✨🍁
🦄 博客首页——猫头虎的博客🎐
🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🌊 《IDEA开发秘籍专栏》学会IDEA常用操作,工作效率翻倍~💐
🌊 《100天精通Golang(基础入门篇)》学会Golang语言,畅玩云原生,走遍大小厂~💐
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
(Gemini)双子座:一系列高能力多模态模型的前世今生
文章目录
- (Gemini)双子座:一系列高能力多模态模型的前世今生
- 1. 介绍
- 2. 模型架构
- 3. 培训基础设施
- 4. 训练数据集
- 5. 评估
- 6. 负责任的部署
- 7. 讨论和结论
- 8. 贡献和致谢
- 9. 附录
- 原创声明

Gemini团队,Google1
本报告介绍了一种新的多模态模型家族Gemini,它在图像、音频、视频和文本理解方面具有卓越的能力。Gemini系列包括Ultra、Pro和Nano三种尺寸,适用于从复杂的推理任务到设备内存受限的应用场景。对广泛的基准测试的评估表明,我们最有能力的Gemini Ultra模型在32个基准测试中的30个中提高了最先进的水平-特别是第一个在经过充分研究的考试基准测试MMLU上实现人类专家性能的模型,并在我们检查的20个多模态基准测试中的每一个中提高了最先进的水平。我们相信Gemini模型在跨模态推理和语言理解方面的新能力将能够实现各种用例,并且我们讨论了我们负责任地向用户部署它们的方法。
1. 介绍
我们在Google开发了一系列高性能的多模态模型Gemini。我们通过图像、音频、视频和文本数据共同训练了Gemini,目的是构建一个在各个模态中具有强大的通用能力以及在各个领域中具有尖端的理解和推理性能的模型。
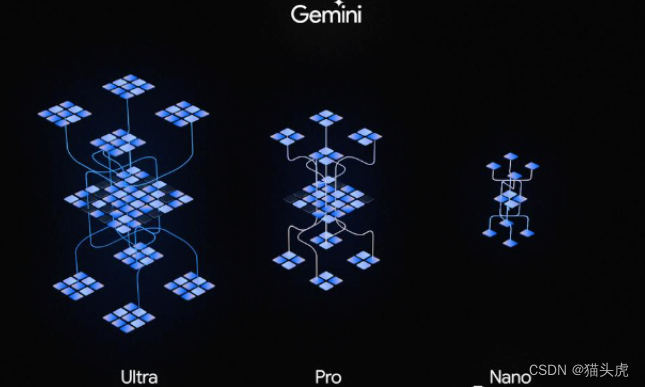
Gemini 1.0,我们的第一个版本,有三种尺寸:Ultra适用于高度复杂的任务,Pro提供增强性能和可扩展性,适用于大规模部署,Nano适用于设备上的应用程序。每个尺寸都经过特别设计以满足不同的计算限制和应用要求。我们对Gemini模型在广泛的语言、编码、推理和多模态任务上进行了全面的内部和外部基准测试。
Gemini推进了大规模语言建模的最新技术(Anil等,2023; Brown et al.,77.7%2023; Hoffmann et al.,2022年;OpenAI,2023a;Radford等人,2019; Rae等人,2021年),图像理解(Alayrac等人,2022年; Chen等人,2022年; Dosovitskiy等人。从中学和高中数学竞赛(MATH基准)中抽取的难度增加的数学问题中观察到类似的积极趋势,Gemini Ultra模型表现优于所有竞争对手模型,在4次提示下达到53.2%的准确率。2022年; 于等人,2017年)通过改进架构和模型优化,实现了稳定的大规模训练和在Google的Tensor Processing Units上进行优化推理。2022a),音频处理(Radford等人,Google的2023年;张等人,2023年),以及视频理解(Alayrac等人,2022年; Chen等人,2023年。它还基于序列模型的工作(Sutskever等人)。2014年,基于神经网络的深度学习有着悠久的历史(LeCun等人)。此外,Gemini可以直接从通用语音模型(USM)(Zhang等人,2020; Chowdhery等人,2015)中以16kHz的音频信号进行输入。2022; Bradbury等人。2018; Dean et al.2012),使大规模培训成为可能。
我们最强大的模型Gemini Ultra在我们报告的32个基准测试中,在30个基准测试中取得了最新的最先进结果,其中包括12个流行的文本和推理基准测试中的10个,9个图像理解基准测试中的9个,6个视频理解基准测试中的6个,以及5个语音识别和语音翻译基准测试中的5个。Gemini Ultra是第一个在MMLU上实现人类专家水平表现的模型(Hendrycks等人)。2021 a)-通过一系列考试测试知识和推理的突出基准-得分超过90%。除了文本,Gemini Ultra在具有挑战性的多模态推理任务方面取得了显着进展。例如,在最近的MMMU基准(Yue等人,2023年),其中包括关于多学科任务上的图像的问题,需要大学水平的学科知识
请参阅贡献和致谢部分以获取完整的作者列表。请发送信件至gemini-1-report@google.com
通过知识和深思熟虑的推理,Gemini Ultra实现了62.4%的最新技术水平,超过了之前最佳模型超过5个百分点。它为视频问答和音频理解基准测试提供了统一的性能提升。
定性评估展示了令人印象深刻的跨模态推理能力,使模型能够原生地理解和推理音频、图像和文本的输入序列(见图5和表13)。以图1所示的教育环境为例。一位老师画了一个物理问题,描述了一个滑雪者下坡的情景,而一位学生已经解决了这个问题。通过双子座的多模态推理能力,该模型能够理解混乱的手写文字,正确理解问题的表述,将问题和解决方案转换为数学排版,识别学生在解决问题时出错的具体推理步骤,然后给出一个经过正确求解的问题的解答。这为令人兴奋的教育可能性打开了大门,我们相信Gemini模型的新的多模态和推理能力在许多领域具有重大应用。
图1 验证学生对物理问题的解决方案。该模型能够正确识别所有手写内容并验证推理。除了理解图像中的文本外,它还需要理解问题的设置并正确遵循指示以生成LATEX。
大型语言模型的推理能力显示出在构建能够解决更复杂的多步问题的通用代理方面的潜力。AlphaCode团队构建了AlphaCode 2(Leblond等人,2023年),这是一个新的基于Gemini的代理程序,它将Gemini的推理能力与搜索和工具使用相结合,以在解决竞争性编程问题方面表现出色。AlphaCode 2在Codeforces竞技编程平台上排名前15%的参赛者中,相比于排名前50%的最新技术前身有了很大的改进(Li等人)2022年)。
双子座:一系列高能力多模态模型
同时,我们通过Gemini Nano推进了效率的前沿,这是一系列针对设备部署的小型模型。这些模型在设备上的任务中表现出色,如摘要、阅读理解、文本补全任务,并且相对于其大小,在推理、STEM、编码、多模态和多语言任务中展示出令人印象深刻的能力。
在下面的部分中,我们首先提供模型架构、训练基础结构和训练数据集的概述。然后,我们提出了详细的评估双子座模型的家庭,涵盖了良好的研究基准和人类偏好的评估文本,代码,图像,音频和视频-其中包括英语性能和多语言能力。我们还讨论了我们负责任的部署方法,包括在部署决策之前进行影响评估、制定模型策略、评估和减轻危害的过程。最后,我们讨论了Gemini的更广泛影响,以及它的局限性和潜在应用,为人工智能研究和创新开辟了新时代的道路。
2. 模型架构
Gemini模型是基于Transformer解码器构建的(Vaswani等人,2020;OpenAI,2023b;Reed等人)。例如,在HumanEval上,一个标准的代码补全基准(Chen等人,51.2%)。它们经过训练以支持32k的上下文长度,采用高效的注意机制(例如,多查询注意力(Shazeer,2019))。我们的第一个版本Gemini 1.0包括三种主要尺寸,以支持广泛的应用,如表1所述。
模型大小 模型描述
Ultra我们最强大的模型,可在各种高度复杂的任务(包括推理和多模式任务)中提供最先进的性能。由于Gemini架构,它在TPU加速器上能够高效地进行规模化服务。
在成本和延迟方面优化的专业模型,能够在各种任务中提供显著的性能。该模型展示了强大的推理性能和广泛的多模态能力。
Nano是我们最高效的型号,设计用于设备上运行。我们训练了两个版本的Nano,分别具有1.8B(Nano-1)和3.25B(Nano-2)参数,分别针对低内存和高内存设备。它是通过从更大的Gemini模型中提炼训练的。它经过4位量化以进行部署,并提供最佳性能。
表1 | Gemini 1.0模型系列概览。
Gemini模型经过训练,可以适应与各种音频和视觉输入(如自然图像、图表、屏幕截图、PDF和视频)交织的文本输入,并且可以生成文本和图像输出(请参见图2)。Gemini模型的视觉编码受到我们自己对Flamingo的基础工作的启发(Alayrac等人,2022)、CoCa(Yu等人,2022a)和PaLI(Chen等人)2022年),重要的区别在于这些模型从一开始就是多模态的,并且可以使用离散的图像标记本地输出图像(Ramesh等人)2021; Yu et al.,2022b)。
通过将视频编码为大上下文窗口中的一系列帧来实现视频理解。视频帧或图像可以自然地与文本或音频交错作为模型输入的一部分。这些模型可以处理可变的输入分辨率,以便在计算上花费更多的资源。
我们计划在Gemini Ultra型号正式发布之前,通过更多细节来更新这份报告。
图2 Gemini支持以文本、图像、音频和视频的交错序列作为输入(在输入序列中用不同颜色的标记表示)。它可以输出交错的图像和文本响应。
需要细粒度理解的任务。在这些基准测试中进行评估是具有挑战性的,并且可能受到数据污染的影响。2023) 特点。这使模型能够捕捉通常在音频被简单地映射到文本输入时丢失的细微差别(例如,请参阅网站上的音频理解演示)。
训练Gemini系列模型需要在训练算法、数据集和基础设施方面进行创新。对于Pro模型,我们基础设施和学习算法的固有可扩展性使我们能够在几周内完成预训练,利用了Ultra的一小部分资源。Nano系列模型利用了蒸馏和训练算法的进一步改进,为各种任务(如摘要和阅读理解)提供了最佳的小型语言模型,为我们的下一代设备体验提供动力。
3. 培训基础设施
我们使用TPUv5e和TPUv4(Jouppi等人)训练了Gemini模型。这些模型的大小和配置可能会有所不同(取决于2023年)。训练Gemini Ultra使用了多个数据中心的大型TPUv4加速器群。这代表着相对于我们之前的旗舰模型PaLM-2而言规模的显著增加,这也带来了新的基础设施挑战。加大加速器数量会导致整个系统中硬件故障的平均时间间隔成比例地减少。我们尽量减少计划重新安排和抢占的频率,但在如此大规模的硬件加速器中,由于宇宙射线等外部因素,真正的机器故障是普遍存在的(Michalak等人,Gemini Pro是Gemini系列模型中第二大的模型,同时在提供服务时也更加高效。
TPUv4加速器部署在4096个芯片的“SuperPods”中,每个芯片都连接到一个专用的光开关,可以在大约10秒钟内将4x4x4芯片立方体动态重新配置为任意的3D环形拓扑结构(Jouppi等人,2023年。对于Gemini Ultra,我们决定保留每个超级节点一小部分的立方体,以便进行热备份和滚动维护。
TPU加速器主要通过高速芯片间互连进行通信,但在Gemini Ultra规模下,我们使用Google的集群内和集群间网络将SuperPods组合在多个数据中心中(Poutievski等人,2022年;Wetherall等人。2023年; 姚红等人2018年)。机器翻译是机器学习中的一个经典基准,具有丰富的历史。
网络延迟和带宽足以支持常用的同步训练范式,在超级节点内利用模型并行性和超级节点间进行数据并行性。
Jax的“单控制器”编程模型(Bradbury等人)。2018年)和Pathways(Barham等人。在2022年,允许一个单独的Python进程来编排整个训练过程,极大地简化了开发工作流程。GSPMD分区器(Xu等人,2019年)2021年,XLA编译器在训练步骤计算中进行了分区,并且MegaScale XLA编译器(XLA,2019)通过静态调度适当的集合操作,以使其与计算最大程度地重叠,步骤时间变化很小。
在这个规模上保持高吞吐量是不可能的,采用传统的周期性权重检查点到持久性集群存储的方法。对于双子座,我们使用了模型状态的冗余内存副本,当出现任何意外的硬件故障时,我们可以直接从完整的模型副本中快速恢复。的比较在2023年,尽管使用的训练资源显著增加,但这大大加快了恢复时间。因此,最大规模的训练任务的整体吞吐量从85%增加到97%。
在前所未有的规模上进行的训练不可避免地会出现新的有趣的系统故障模式-在这种情况下,我们需要解决的一个问题是“静默数据损坏(SDC)”(Dixit等,2021年),我们发现Gemini Ultra在思维链和自洽性提示下达到了94.4%的准确率(Wang等)。2021年; Hochschild等人。2021年;Vishwanathan等人,2023年)2015年。尽管这些情况非常罕见,但Gemini的规模意味着我们可以预期SDC事件每一两周影响训练。快速检测和移除故障硬件需要利用确定性重放来隔离错误计算的几种新技术,结合在空闲机器和热备份上的主动式SDC扫描器。我们完全确定性的基础设施使我们能够在开发过程中快速识别到根本原因(包括硬件故障),这对于稳定的训练是至关重要的。
4. 训练数据集
Gemini模型是在一个既包含多模态又包含多语言的数据集上进行训练的。我们的预训练数据集使用来自网络文档、书籍和代码的数据,并包括图像、音频和视频数据。
我们使用SentencePiece分词器(Kudo和Richardson,2018),发现在整个训练语料库的大样本上训练分词器可以改善推断的词汇,并进而提高模型性能。例如,我们发现Gemini模型可以高效地标记非拉丁脚本,这反过来可以提高模型质量以及训练和推理速度。
训练最大模型所使用的标记数量是根据Hoffmann等人(2022)的方法确定的。为了在给定的推理预算下提高性能,较小的模型被训练了更多的标记,类似于Touvron等人(2023a)提倡的方法。
我们对所有数据集应用质量过滤器,使用启发式规则和基于模型的分类器。我们还进行安全过滤以删除有害内容。我们从训练语料库中筛选出我们的评估集。通过对较小的模型进行消融实验,确定了最终的数据混合和权重。我们在训练过程中进行分阶段训练,通过增加领域相关数据的权重来改变混合组合,直到训练结束。我们发现数据质量对于一个高性能的模型至关重要,并且相信在寻找预训练的最佳数据集分布方面还存在许多有趣的问题。
我们将goodput定义为在训练作业的经过时间内计算有用新步骤所花费的时间。
5. 评估
Gemini模型是本地多模态的,因为它们在文本、图像、音频和视频上进行联合训练。一个未解决的问题是,这种联合训练是否能够产生一个在每个领域都具有强大能力的模型,即使与专门针对单个领域的模型和方法进行比较。我们发现这是事实:Gemini在广泛的文本、图像、音频和视频基准测试中树立了新的技术水平。
5.1. 文本
5.1.1. 学术基准
我们将Gemini Pro和Ultra与一系列外部LLM模型和我们先前的最佳模型PaLM 2进行比较,涵盖推理、阅读理解、STEM和编码等一系列基于文本的学术基准。我们在表2中报告了这些结果。总体而言,我们发现Gemini Pro的性能优于GPT-3.5等推理优化模型,并且与几个最强大的模型表现相当,而Gemini Ultra则优于所有当前模型。在本节中,我们将研究其中一些发现。
在 MMLU(Hendrycks 等人)上2021a) Gemini Ultra可以超越所有现有模型,达到90.04%的准确率。MMLU是一个全面的考试基准,衡量了57个科目的知识水平。基准作者将人类专家表现评估为89.8%,而Gemini Ultra是第一个超过此阈值的模型,先前的最先进结果为86.4%。实现高性能需要在许多领域(如法律、生物学、历史等)具备专业知识,同时还需要阅读理解和推理能力。我们发现当与一种思维链提示方法结合使用时,Gemini Ultra的准确性最高(Wei等人,2022年)。2022年)考虑了模型的不确定性。该模型生成了一个包含 k 个样本(例如 8 或 32)的思维链。如果存在超过预设阈值的共识(基于验证集选择),则选择此答案;否则,它将回到基于最大似然选择的贪婪采样,而没有思维链。我们将读者引至附录,详细比较了这种方法与仅基于思维链提示或仅贪婪采样的差异。
在数学领域,这是一个常用于评估模型分析能力的领域,Gemini Ultra在初级考试和竞赛级问题集上表现出强大的性能。对于小学数学基准测试,GSM8K(Cobbe等人)2021年)。2022年)与相同提示技术的先前最佳准确率92%相比,取得了类似的积极趋势。从中学和高中数学竞赛(MATH基准)中提取的难度增加的数学问题也观察到类似的积极趋势,Gemini Ultra模型表现优于所有竞争对手模型,在4次提示下达到53.2%。该模型在源自美国数学竞赛的更难任务上也优于现有技术(来自2022年和2023年的150个问题)。在这个具有挑战性的任务中,较小的模型表现不佳,得分接近随机,但是Gemini Ultra可以解答32%的问题,而GPT-4的解答率为30%。
Gemini Ultra在编码方面也表现出色,这是当前LLMs的一个流行用例。我们在许多传统和内部基准测试中评估模型,并在更复杂的推理系统(如AlphaCode 2)中衡量其性能(请参见第5.1.7节关于复杂推理系统)。2022年; 于等人,2017年)通过改进架构和模型优化,实现了稳定的大规模训练和在Google的Tensor Processing Units上进行优化推理。2021年)将函数描述映射到Python实现,经过指令调优的Gemini Ultra正确实现了74.4%的问题。在一个新的针对Python代码生成任务的保密评估基准Natural2Code上,我们确保没有网络泄漏,Gemini Ultra取得了最高分74.9%。
离子-2
ons
CoT@ 32∗
a) 5- shot
5- shot
5- shot(报道)
GSM8K
小学数学(Cobbe等人,2021年) 94.4%
Maj1@ 32 86.5%
Maj1@ 32 92.0%
SFT&
5次CoT 57.1%
5- shot 80.0%
5- shot 88.0%
0- shot 81.4%
8- shot 62.9%
8- shot 56.8%
5- shot
MATH
涵盖5个难度级别的数学问题
7个子学科(Hendrycks等人,2021b) 53.2%
4-射击 32.6%
4-射击 52.9%
4-射击
(通过API∗∗)
50.3%
(郑等人,2023年) 34.1%
4-射击
(通过API∗∗) 34.4%
4-投篮 — 34.8% 23.9%
4-投篮 13.5%
4-投篮
BIG-Bench-Hard
作为CoT问题编写的一部分困难的BIG-bench任务子集
(Srivastava等人,2022年) 83.6%
3- shot 75.0%
3- shot 83.1%
3- shot
(通过API∗∗) 66.6%
3- shot
(通过API∗∗) 2015年),以及机器学习分布式系统(Barham等人)。
3- shot — — — 例如,在HumanEval上,一个标准的代码补全基准(Chen等人,51.2%)。
3- shot
人工评估
Python编码任务(Chen等人,2021年) 74.4%
0-投篮(IT) 67.7%
0- shot(IT) 与PaLM和PaLM-2(Anil等人)相比
0-shot(报告) 48.1%
0- shot — 70.0%
0- shot 44.5%
0- shot 63.2%
0- shot 29.9%
0- shot
Natural2Code
Python代码生成。(新的无泄漏网络集合) 74.9%
0- shot 69.6%
0- shot 73.9%
0- shot
(通过API∗∗) 62.3%
0- shot
(通过API∗∗) — — — — —
DROP
阅读理解和算术。
(度量:F1-分数)(Dua等人,67.0% 82.4
可变镜头 74.1
可变镜头 80.9
3- shot(报道) 64.1
3- shot 82.0
可变镜头 — — — —
HellaSwag
(验证集)
常识多项选择题
( Zellers et al.,67.0% 87.8%
10-射击 84.7%
10-射击 95.3%
10次试验(报道) 85.5%
10-射击 86.8%
10-射击 — 89.0%
10-射击 — 80.0%∗∗∗
WMT23
机器翻译(度量:BLEURT)
(Tom等人,2023年) 74.4
1-shot(IT) 71.7
1-shot 73.8
1-shot
(通过API∗∗) — 72.7
1-shot — — — —
表2 Gemini在带有外部比较和PaLM 2-L的文本基准测试中的性能。
∗ 如果有一个阈值以上的共识(根据验证集选择),模型会生成一个思路链,其中k=8或32个样本,它会选择这个答案,否则它会回到贪婪采样。附录9.1中有进一步的分析。
∗∗ 结果是通过2023年11月的API自行收集的。
∗∗∗结果显示使用Touvron等人(2023b)报告中的去污染数据作为与已经去污染的Gemini模型最相关的比较。
在这些基准测试中进行评估是具有挑战性的,并且可能受到数据污染的影响。我们在训练后进行了广泛的泄露数据分析,以确保我们在这里报告的结果尽可能科学可靠,但仍然发现了一些小问题,并决定不报告结果。
例如LAMBADA(Paperno等,2016)。作为评估过程的一部分,在一个流行的基准测试中,HellaSwag(Zellers等人,2019年),我们发现,在对应于HellaSwag训练集(不包括在Gemini预训练集中)的特定网站提取物上额外增加100个微调步骤,将Gemini Pro的验证准确度提高到89.6%,Gemini Ultra提高到96.0%,当使用1次提示进行测量时(我们测量了GPT- 4,当通过API进行1次评估时获得92.3%)。这表明基准结果对预训练数据集的组成具有敏感性。我们选择仅在10次射击评估设置中报告HellaSwag的去污结果。我们认为,有必要制定更加健全和细致入微的标准化评估基准,而不泄露数据。因此,我们对Gemini模型进行了几个新的保留评估数据集的评估,这些数据集最近发布,例如WMT23和Math-AMC 2022-2023问题,或者是从非网络来源生成的,例如Natural2Code。我们将读者引至附录,以获取我们评估基准的全面列表。
即便如此,模型在这些基准测试中的表现给我们提供了模型能力和它们在现实任务中可能产生影响的线索。例如,Gemini Ultra令人印象深刻的推理和STEM能力为教育领域内的LLM进步铺平了道路4。解决复杂的数学和科学概念的能力为个性化学习和智能辅导系统开辟了令人兴奋的可能性。
5.1.2. 能力趋势
我们通过在六个不同能力的50多个基准测试中对Gemini模型系列进行评估,研究其能力的趋势,注意到一些最显著的基准测试在上一节中已经讨论过。这些能力包括:“事实性”涵盖开放/封闭书检索和问题回答任务;“长文本”涵盖长篇摘要、检索和问题回答任务;“数学/科学”包括数学问题解决、定理证明和科学考试任务;“推理”任务需要算术、科学和常识推理;“多语言”任务涉及多种语言的翻译、摘要和推理。请参阅附录以获取每个能力所包含的任务的详细列表。
1.4
1.2
1.0
0.8
0.6
0.4
0.2
0.0
图3 Gemini模型系列在不同能力下的语言理解和生成性能(以Gemini Pro模型为基准进行归一化)。
我们在图3中观察到随着模型规模的增加,特别是在推理、数学/科学、摘要和长上下文方面,质量稳定提升。Gemini Ultra是所有六种能力的最佳模型。Gemini Pro是Gemini系列模型中第二大的模型,同时在提供服务时也更加高效。
5.1.3. Nano
将人工智能更接近用户,我们讨论了专为设备部署而设计的Gemini Nano 1和Nano 2模型。这些模型在总结和阅读理解任务中表现出色,并对每个任务进行微调。图3显示了这些预训练模型与更大的Gemini Pro模型的性能对比,而表3则更深入地探讨了特定的事实性、编码、数学/科学和推理任务。Nano-1和Nano-2模型的参数分别仅为1.8B和3.25B。尽管他们的规模,他们显示出异常强大的性能,
即检索相关任务,并在推理、STEM、编码、多模态和
在网站https://deepmind.google/gemini上查看演示。
多语种任务。随着新的能力可在更广泛的平台和设备上使用,Gemini模型扩大了对所有人的可访问性。
Gemini Nano 1 Gemini Nano 2
准确性 由Pro进行归一化 准确性 由Pro进行归一化
BoolQ 71.6 0.81 79.3 0.90
TydiQA(GoldP) 68.9 0.85 74.2 0.91
自然问题(检索) 38.6 0.69 46.5 0.83
自然问题(闭卷) 18.8 0.43 24.8 0.56
BIG-Bench-Hard(3-射击) 34.8 0.47 42.4 0.58
MBPP 20.0 0.33 27.2 0.45
MATH(4次迭代) 13.5 0.41 22.8 0.70
MMLU(5次射击) 45.9 0.64 55.8 0.78
表3 Gemini Nano系列在事实性、摘要、推理、编码和STEM任务上的性能与规模更大的Gemini Pro模型相比。
5.1.4. 多语言能力
通过使用多种任务对Gemini模型的多语言能力进行评估,这些任务需要多语言理解、跨语言泛化以及生成多种语言的文本。这些任务包括机器翻译基准测试(WMT 23用于高、中、低资源翻译;Flores、NTREX用于低资源和极低资源语言),摘要基准测试(XLSum、Wikilingua),以及常见基准测试的翻译版本(MGSM:专业翻译成11种语言)。
2012年)。我们在WMT 23翻译基准的整个语言对集合上评估了应用指令调优的Gemini Ultra(见第6.4.2节)在少量样本设置中的性能。总体而言,我们发现Gemini Ultra(以及其他Gemini型号)在从英语翻译成任何其他语言方面表现出色,并且在高资源、中资源和低资源语言的翻译中超过了基于LLM的翻译方法。在WMT 23个英语翻译任务中,Gemini Ultra实现了基于LLM的最高翻译质量,平均BLEURT为(Sellam等人,2020年)得分为74.8,而GPT-4的得分为73.6,PaLM 2的得分为72.2。在WMT 23的所有语言对和方向上取平均值,我们可以看到Gemini Ultra 74.4、GPT-4 73.8和PaLM 2-L 72.7在这个基准测试上的平均BLEURT分数呈类似趋势。
(平均BLEURT)
英译中 73.9 72.0 69.0 63.5 74.1 73.4
表4 | Gemini 模型在 WMT 23 翻译基准上的性能。所有带有1次拍摄的数字。
除了上述的语言和翻译任务外,我们还在非常低资源的语言上评估了Gemini Ultra。这些语言是从以下语言集的尾部进行抽样的:Flores-200(塔马齐格语和卡努雷语),NTREX(北恩德贝勒语)和内部基准(克丘亚语)。
对于这些语言,无论是从英语翻译成其他语言,还是从其他语言翻译成英语,Gemini Ultra在一次性设置中的平均chrF得分为27.0,而下一个最佳模型PaLM 2-L的得分为25.3。
除了翻译,我们还评估了Gemini在各种语言的挑战性任务中的表现,包括多语言数学和摘要。我们特别调查了数学基准MGSM(Shi等人,2023年)。2023年),这是数学基准测试GSM8K的一个翻译变体(Cobbe等人,2021年)。我们发现,在8次训练中,Gemini Ultra在所有语言中的平均准确率为79.0%,相比之下,PaLM 2-L的准确率为74.7%。我们还在多语言摘要基准测试XLSum(Hasan等人)上对Gemini进行了基准测试。2021) 和 WikiLingua(Ladhak 等人,2020年。在XLSum中,Gemini Ultra的平均rougeL得分为17.6,而PaLM 2为15.4。对于Wikilingua,Gemini Ultra(5-shot)在BLEURT得分上落后于PaLM 2(3-shot)的表现。完整结果请参见表5。总体而言,多样化的多语言基准测试表明,Gemini系列模型具有广泛的语言覆盖范围,使其能够覆盖资源匮乏的地区和地域。
Gemini Ultra Gemini Pro GPT-4 PaLM 2-L
MGSM (8次射击) 79.0 63.5 74.5 74.7
XLsum(3- shot)17.6 16.2
Wikilingua 48.9 47.8 — 15.4
- 50.4
表5 | Gemini模型在多语言数学和摘要上的性能。
5.1.5. 长上下文
Gemini 模型的训练使用了长度为32,768个标记的序列,我们发现它们有效地利用了上下文长度。我们首先通过运行一个合成检索测试来验证这一点:我们将键值对放置在上下文的开头,然后添加长的填充文本,并询问与特定键相关联的值。我们发现,当在完整的上下文长度查询时,Ultra模型以98%的准确率检索到正确的值。我们通过在图4中绘制负对数似然(NLL)与标记索引之间的关系来进一步研究这个问题,这是在一个长文档的保留集上进行的。我们发现负对数似然(NLL)随着序列位置的增加而减少,直到完整的32K上下文长度。Gemini模型更长的上下文长度使得可以进行新的用例,例如在5.2.2节中讨论的文档检索和视频理解。
8 16 32 64 128 256 512 1K 2K 4K 8K 16K 32K
序列位置
图4 在一个长文档的保留集上,作为令牌索引的负对数似然函数随32K上下文长度的变化。
5.1.6. 人类偏好评估
人类对模型输出的偏好提供了一个重要的质量指标,补充了自动评估。我们对Gemini模型进行了并行盲评估,人工评分员评判两个模型对相同提示的回应。我们进行指令调整(Ouyang等人)2022年,我们使用第6.4.2节讨论的技术对预训练模型进行了优化。模型的指导调优版本在多个特定能力上进行评估,如遵循指令、创造性写作、多模态理解、长篇上下文理解和安全性。这些能力涵盖了一系列受当前用户需求和研究潜在未来用例启发的用例。
经过调整的Gemini Pro模型在一系列能力上有很大的改进,包括在创意写作方面优于PaLM 2模型API,提高了65.0%的时间,在遵循指令方面提高了59.2%的时间,并在更安全的响应方面提高了68.5%的时间,如表6所示。这些改进直接转化为更有帮助和更安全的用户体验。
创造力 指令跟随 安全性
胜率 65.0% 59.2% 68.5%
95%置信区间。间隔 [ 62.9%, 67.1%] [ 57.6%, 60.8%] [66.0%,70.8%]
表6 | Gemini Pro在PaLM 2(文本- bison@ 001)上的胜率,带有95%的置信区间。
5.1.7. 复杂推理系统
双子座还可以与搜索和工具使用等附加技术相结合,创建强大的推理系统,可以解决更复杂的多步问题。这样一个系统的一个例子是AlphaCode 2,这是一个在解决竞争性编程问题方面表现出色的最新技术代理人(Leblond等,2023年)。AlphaCode 2使用了一种专门版本的Gemini Pro,该版本经过了类似于Li等人(2022年)中使用的竞赛编程数据的调整,以在可能的程序空间中进行大规模搜索。然后,我们采用了定制的过滤、聚类和重新排序机制。Gemini Pro经过微调,既可以作为一个编码模型生成解决方案候选,又可以作为一个奖励模型,用于识别和提取最有前途的代码候选。
AlphaCode 2在Codeforces上进行评估,与AlphaCode相同的平台,在1和2分区的12个比赛中,共计77个问题。AlphaCode 2解决了这些竞赛问题的43%,相比之前记录的AlphaCode系统的25%有了1.7倍的改进。将这个与竞争排名相对应,AlphaCode 2 在Gemini Pro的基础上平均位于估计的第85百分位数 - 即它的表现优于85%的参赛者。这是对AlphaCode的重大进步,AlphaCode只超过了50%的竞争对手。
将强大的预训练模型与搜索和推理机制相结合是朝着更通用的智能体方向的一个令人兴奋的方向;另一个关键要素是在多种形式之间进行深入理解,我们将在下一节中讨论。
5http:// codeforces.com/
5.2. 多模态
Gemini:一系列高度能干的多模型
Gemini模型本身就是多模态的。这些模型展示了无缝结合跨模态能力的独特能力(例如从表格、图表或图形中提取信息和空间布局),以及语言模型的强大推理能力(例如在数学和编码方面的最新性能),如图5和12中的示例所示。这些模型在识别输入中的细微细节、在空间和时间上聚合上下文以及在一系列视频帧和/或音频输入上应用这些能力方面也表现出强大的性能。
下面的部分提供了对模型在不同模态(图像、视频和音频)上的更详细评估,以及模型在图像生成和跨不同模态的信息组合能力方面的定性示例。
5.2.1. 图像理解
我们评估了模型在四个不同的能力上:使用字幕或问答任务(如VQAv2)进行高级对象识别;使用TextVQA和DocVQA等任务进行细粒度转录,要求模型识别低级细节;使用ChartQA和InfographicVQA任务要求模型理解输入布局的空间理解;以及使用Ai2D、MathVista和MMMU等任务进行多模态推理。对于零-shot QA评估,模型被指示提供与特定基准对齐的简短答案。所有数字都是通过贪婪采样获得的,没有使用任何外部OCR工具。
Gemini Ultra
(仅像素) Gemini Pro
(仅像素) Gemini Nano 2
(仅像素) Gemini Nano 1
(仅像素) GPT-4V 先前的SOTA
MMMU(验证) 59.4% 47.9% 32.6% 26.3% 56.8% 56.8%
多学科大学级问题通过@ 1
(Yue等人,2023年62.4%
Maj1@ 32 GPT-4V,0-shot
(Singh等人,2019)
(Mathew等人)。2021年
(Masry等人。2022)
(Mathew等人)。2022)
(Lu等人,2023年
(Kembhavi等人,2016年
VQAv2(测试-开发)
自然图像理解(Goyal等人)2017年)
77.8% 71.2% 67.5% 62.7%
77.2% 86.1%
Google PaLI- X,微调
表7 图像理解Gemini Ultra在零射击中始终优于现有方法,特别是对于自然图像、文本、文档和图形的OCR相关图像理解任务,而不使用任何外部OCR引擎(仅限像素)。许多现有方法在相应任务上进行微调,用灰色突出显示,这使得与0射击的比较不是苹果对苹果。
我们发现Gemini Ultra在表7中的各种图像理解基准测试中都是最先进的。它在回答自然图像和扫描文档的问题,以及理解信息图表、图表和科学图解等各种任务中表现出强大的性能。与其他模型(尤其是GPT-4V)公开报告的结果相比,Gemini在零射击评估中表现更好。它还超过了几个专门在基准训练集上进行微调的现有模型,适用于大多数任务。Gemini模型的能力在学术基准测试中取得了显著的改进,如MathVista(+ 3.1%)6或InfographicVQA(+ 5.2%)。
MMMU(Yue等人)2023) 是一个最近发布的评估基准,其中包含了关于图像的问题,涵盖了6个学科,每个学科中又有多个主题,需要大学水平的知识来解答这些问题。Gemini Ultra在这个基准测试中取得了最好的分数,比最先进的结果提高了5个百分点以上,并在6个学科中的5个学科中超过了以前的最佳结果(见表8),从而展示了它的多模态推理能力。
MMMU(val)Gemini Ultra(0- shot)GPT- 4V(0- shot)
Maj@ 32 pass@ 1 pass@ 1
艺术与设计 74.2 70.0 65.8
商业 62.7 56.7 59.3
科学 49.3 48.0 54.7
健康与医学 71.3 67.3 64.7
人文社科 78.3 78.3 72.5
技术与工程 53.0 47.1 36.7
总体上为62.4 59.4 56.8
表8显示了Gemini Ultra在MMMU基准测试中的性能(Yue等人)。每个学科的2023年度。每个学科涵盖多个科目,需要大学水平的知识和复杂的推理能力。
Gemini模型还能够同时处理多种模态和全球语言的任务,无论是图像理解任务(例如包含冰岛文本的图像)还是生成任务(例如为多种语言生成图像描述)。我们在Crossmodal- 3600(XM- 3600)基准测试的选定语言子集上使用Flamingo评估协议(Alayrac等人,2018)在4-shot设置下评估生成图像描述的性能。英语视频字幕如表9所示,Gemini模型相比现有最佳模型Google PaLI-X取得了显著的改进。
XM-3600(CIDER)Gemini Ultra 4-射击
Gemini Pro 4- shot
Google PaLI-X 4射击
英语 86.4 87.1 77.8
法语 77.9 76.7 62.5
Hindi 31.1 29.8 22.2
现代希伯来语 54.5 52.6 38.7
罗马尼亚语 39.0 37.7 30.2
泰国86.7 77.0 56.0
中文 33.3 30.2 27.7
平均(7个) 58.4 55.9 45.0
表9 多语言图像理解Gemini模型在XM-3600数据集的部分语言上,在为图像加标题的任务上胜过现有模型(Thapliyal等人)。2022年)。
6MathVista是一个包含28个先前发布的多模态数据集和三个新创建的数据集的综合数学推理基准。我们的MathVista结果是通过运行MathVista作者的评估脚本获得的。
图5 Gemini的多模态推理能力生成matplotlib代码以重新排列子图。多模态提示显示在左上角,颜色为灰色。Gemini Ultra的响应,包括其生成的代码,显示在右侧蓝色的列中。左下方的图示显示了生成代码的渲染版本。成功解决这个任务表明模型具备结合多种能力的能力:(1)识别图中所示的功能;(2)逆向图形推断生成子图的代码;(3)按照指示将子图放置在所需位置;以及(4)抽象推理,推断指数图必须保持在原位,因为正弦图必须让位给三维图。
图5中的定性评估展示了Gemini Ultra多模态推理能力的一个例子。该模型需要解决生成由用户提供的一组子图重新排列的 matplotlib 代码的任务。模型输出显示它成功解决了这个任务
结合了多种能力,包括理解用户的绘图、推断生成所需的代码、按照用户的指示将子图放置在所需位置以及对输出图进行抽象推理。这突出了Gemini Ultra的本地多模态性,并暗示了它在图像和文本的交错序列中更复杂的推理能力。我们将读者引至附录中获取更多定性示例。
5.2.2. 视频理解
理解视频输入是朝着有用的通用代理的重要一步。我们通过几个已建立的基准测试来衡量视频理解能力,这些基准测试是从训练中排除的。这些任务衡量模型是否能够理解和推理一系列时间相关的帧。对于每个视频任务,我们从每个视频剪辑中采样16个等间距的帧,并将它们输入到Gemini模型中。对于YouTube视频数据集(除了NextQA和感知测试之外的所有数据集),我们在2023年11月仍然公开可用的视频上评估了Gemini模型。
Gemini Ultra在各种少样本视频字幕任务以及零样本视频问答任务上取得了最先进的结果,如表10所示。这证明了它在多个帧之间具有强大的时间推理能力。附录中的图21提供了一个关于理解足球运动员击球机制的视频的定性示例,并推理出运动员如何改善他们的比赛。
(Wang等人,2019)
(Wang等人,2019)
(Zhou等人,2022年)对所有模型没有进行任何微调。2018年)
(Xiao等)2021年
(Yu等人,2019)
(Pătrăucean等人,2023年
在选定的学术基准上,表10展示了跨任务和语言的少样本视频理解。视频字幕的报告指标是CIDER,NextQA的报告指标是WUPS,感知测试和ActivityNet-QA的报告指标是top-1准确率。对于ActivityNet-QA,我们使用了Video-LLAVA(Lin等人,2023年评估协议。
5.2.3. 图像生成
Gemini能够直接输出图像,而无需依赖中间的自然语言描述,这可以避免模型在表达图像时受到瓶颈的影响。这使得该模型能够在几次试验的环境中使用交错的图像和文本序列生成带有提示的图像。例如,用户可以提示模型为博客文章或网站设计图像和文本建议(见附录中的图10)。
图6展示了一次性设置中图像生成的示例。Gemini Ultra 模型会提示一个交错的图像和文本示例,用户需要提供两种颜色(蓝色和黄色)以及使用纱线创造一个可爱的蓝猫或者一个蓝狗带黄耳朵的图像建议。然后,模型被给予两种新颜色(粉红色和绿色),并被要求提供使用这些颜色创造两个想法。该模型成功地生成了一个交错的图像和文本序列,并提供了一些建议,可以用纱线制作一个可爱的绿色鳄梨带粉色种子或一个绿色的兔子带粉色耳朵。
图6 图像生成。Gemini可以根据由图像和文本组成的提示,输出多个交错的图像和文本。在左图中,Gemini Ultra在一个一次性设置中被提示,当给定两种颜色,蓝色和黄色时,生成创建猫和狗的建议示例。然后,模型被提示生成两种新颜色(粉色和绿色)的创意建议,并生成了创意建议的图像,如右图所示,制作了一个带有粉色种子的可爱绿色鳄梨或者一个带有粉色耳朵的绿色兔子。
Gemini:一系列高度能干的多模型
5.2.4. 音频理解
我们在各种公共基准测试中评估了Gemini Nano-1和Gemini Pro模型,并与Universal Speech Model(USM)(Zhang等人,2023年)或large-v3(OpenAI,2023年)进行了比较。2023年)和Whisper(large-v2(Radford等人)2023年),VoxPopuli(Wang等人,2023年)以及语音翻译任务CoVoST 2,将不同语言翻译成英语(Wang等人)。这些基准包括自动语音识别(ASR)任务,如FLEURS(Conneau等人)。2015年)。2021年),多语言Librispeech(Panayotov等人)。2015),以及语音翻译任务CoVoST 2,将不同的语言翻译成英语(Wang等人,2020年。我们还报告了一个内部基准YouTube测试集的结果。ASR任务报告了一个词错误率(WER)指标,较低的数字表示更好的性能。翻译任务报告双语评估助手(BLEU)得分,得分越高越好。FLEURS 在与训练数据有语言重叠的 62 种语言上进行了报告。四种分段语言(普通话、日语、韩语和泰语)报告字符错误率(CER),而不是词错误率(WER),类似于Whisper(Radford等人)。2023年。
表11表明,我们的Gemini Pro模型在所有ASR和AST任务中,无论是英语还是多语种测试集,都明显优于USM和Whisper模型。注意,与USM和Whisper相比,FLERS有很大的收益,因为我们的模型也使用FLERS训练数据集进行训练。然而,如果没有FLEURS数据集训练相同的模型,WER为15.8,仍然优于Whisper。除了FLEURS数据集外,Gemini Nano-1模型在所有数据集上的表现也优于USM和Whisper。请注意,我们尚未对Gemini Ultra进行音频评估,尽管我们预计增加模型规模会带来更好的性能。
任务指标Gemini Pro
Gemini Nano-1
Whisper
( OpenAI, 2023;
Radford等人。2023年
USM
( Zhang等人,2023年
自动语音识别
自动语音翻译
YouTube
(en-us)
多语种Librispeech
(en-us)
(Panayotov等人,2015年)
FLEURS
(62种语言)
(Conneau等人)2023年
VoxPopuli
(14种语言)
(Wang等人,2021年
CoVoST 2
(21郎)
(Wang等人,2020)
WER(↓) 4.9% 5.5% 6.5%
( v3)
WER(↓)4.8% 5.9% 6.2%
( v2)
WER(↓) 7.6% 14.2% 17.6%
( v3)
WER(↓) 9.1% 9.5% 15.9%
( v2)
BLEU(↑)40.1 35.4 29.1
( v2)
6.2%
7.0%
11.8%
13.4%
30.7
表11显示了ASR和AST的选定基准的语音评估结果。对于ASR,报告的度量是WER,较低的值表示性能更好。对于AST,报告的度量标准是BLEU,数值越高越好。
表12显示了使用USM和Gemini Pro进行的进一步错误分析。我们发现Gemini Pro在罕见的词汇和专有名词上产生了更易理解的回答。
领域真相USM Gemini Pro Wav
Fleurs Scotturb公交403路定期往返于Sintra,停靠在Cabo da Roca。
Fleurs群岛位于半岛以北120公里处。最大的是乔治王岛,设有维拉拉斯埃斯特雷斯定居点。
Scotboard巴士four3定期穿越到Centra,在Cabo de Roga停车。
该群岛位于半岛以北120公里处。最大的是Kingurch岛,有Cua Losas的定居点。
Scotturb公交403路定期前往辛特拉,停靠在罗卡角。
该群岛位于半岛以北120公里处。最大的是乔治王岛,设有维拉拉斯埃斯特雷斯定居点。
)))
)))
表12基准中ASR任务的定性示例。错误的转录以红色突出显示。
5.2.5. 模态组合
多模态演示通常包括文本与单一模态(通常是图像)交错组合。我们展示了原生处理音频和图像序列的能力。
考虑一个关于制作煎蛋卷的烹饪场景,我们用一系列的音频和图像提示模型。表13显示了与模型的逐步交互,提供图片并口头询问下一步煮煎蛋的问题。我们注意到模型的响应文本相当准确,并显示模型处理细致的图像细节,以评估煎蛋是否煮熟。在网站上查看演示。
输入图像 输入音频(转录) 模型回答:文本
谢谢您的指示。我开始做我的煎蛋了,现在看起来准备好了吗?
看起来它几乎准备好了。您可以将其翻转过来煮另一面。
(没有图像-这是对前一个问题的跟进)
)))为什么还没有准备好?它还没有准备好,因为鸡蛋还没熟透。
表13 音频- 视觉定性示例展示了Gemini模型处理交错的文本、视觉和音频序列以及跨模态推理的能力。这个例子在烹饪场景中输入了用户的交错图像和音频。用户向模型询问如何制作煎蛋并检查是否煮熟。
6. 负责任的部署
在开发双子座模型期间,我们采用结构化方法进行负责任的部署,以识别、衡量和管理我们模型可预见的对社会的影响,与谷歌AI技术的先前版本保持一致(Kavukcuoglu等人)。2022年)。在项目的整个生命周期中,我们遵循以下结构。本节概述了我们通过这个过程的广泛方法和主要发现。我们将在即将发布的报告中分享更多细节。
6.1. 影响评估
我们开展模型影响评估,以识别、评估和记录与先进的双子模型开发相关的重要下游社会效益和危害。这些评估是基于先前的学术文献对语言模型风险的研究(Weidinger等人)。2021年),在整个行业范围内进行的类似先前实验的研究结果(Anil等人,2023年;Anthropic,2023年;OpenAI,2023a),与内部和外部专家的持续合作,并进行非结构化的尝试以发现新的模型漏洞。关注的领域包括:事实性、儿童安全、有害内容、网络安全、生物风险、代表性和包容性。这些评估与模型开发同步更新。
影响评估用于指导缓解和产品交付工作,并且为部署决策提供信息。双子座的影响评估涵盖了双子模型的不同能力,评估了这些能力与谷歌的AI原则(谷歌,2023年)可能产生的后果。
6.2. 模型政策
在对已知和预期效果的理解基础上,我们制定了一套“模型政策”来引导模型的开发和评估。模型策略定义作为负责任开发的标准化准则和优先级模式,并作为上线准备的指示。Gemini模型的政策涵盖了多个领域,包括:儿童安全、仇恨言论、事实准确性、公平与包容以及骚扰。
6.3. 评估
为了评估双子座模型在政策领域和其他在影响评估中确定的关键风险领域中的表现,我们在模型开发的整个生命周期中开展了一系列评估。
开发评估旨在通过训练和优化双子座模型进行“攀登”。这些评估是由Gemini团队设计的,或者是针对外部学术基准的评估。评估考虑诸如有用性(遵循指示和创造力)、安全性和事实性等问题。请参阅第5.1.6节和下一节的缓解措施的样本结果。
保证评估是为了治理和审查而进行的,通常在关键里程碑或培训运行结束时由模型开发团队之外的团队进行。保证评估按照模态进行标准化,数据集严格保密。只有高层次的见解被反馈到训练过程中,以协助缓解工作。保证评估包括对Gemini政策的测试,并包括对潜在生物危害、说服力和网络安全等危险能力的持续测试(Shevlane等,2022年)以修订回应并在多个回应候选项之间进行选择。2023年)。
外部评估由谷歌之外的合作伙伴进行,以发现盲点。外部团体对我们的模型进行了一系列问题的压力测试,包括白宫承诺书中列出的领域,测试通过结构化评估和非结构化的红队测试进行。这些评估的设计是独立的,并且结果定期报告给Google DeepMind团队。
除了这套外部评估之外,专业的内部团队还在各个领域进行我们的模型的持续红队测试,如双子座政策和安全性。这些活动包括涉及复杂对抗攻击以识别新漏洞的较少结构化的过程。发现潜在弱点可以用于减轻风险并改进内部评估方法。我们致力于持续的模型透明度,并计划随着时间的推移分享我们评估套件中的其他结果。
6.4. 缓解措施
针对上述评估、政策和评估方法的结果,制定了缓解措施。评估和缓解措施以迭代方式使用,缓解措施后重新运行评估。我们在下面讨论了我们在数据、指导调整和真实性方面减轻模型伤害的努力。
6.4.1. 数据
在训练之前,我们在数据策划和数据收集阶段采取各种措施来减轻潜在的下游危害。如在“训练数据”部分讨论的那样,我们会对高风险内容的训练数据进行过滤,以确保所有训练数据具有足够的高质量。除了过滤之外,我们还采取措施确保所有收集的数据符合Google DeepMind的数据丰富最佳实践,该实践是基于AI伙伴关系的“负责任数据丰富服务采购”的基础上开发的。这包括确保所有数据丰富工作者至少获得当地的生活工资。
7https://whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf 8https://deepmind.google/discover/blog/best-practices-for-data-enrichment/ 9https://partnershiponai.org/responsible-sourcing-considerations/
6.4.2. 指令调整
指令调优包括通过奖励模型进行监督微调(SFT)和通过人类反馈进行强化学习(RLHF)。我们在文本和多模态设置中应用指令调整。指导调整配方经过精心设计,以在提高有用性的同时减少与安全和幻觉相关的模型伤害(Bai等人,2022a)。
SFT需要对“优质”数据进行整理,以进行奖励模型训练和RLHF。数据混合比例通过较小的模型进行消融,以平衡有用性指标(如遵循指示、创造力)和减少模型危害,并且这些结果可以很好地推广到较大的模型。我们还观察到数据质量比数量更重要(Touvron等人,2023b; Zhou等人,特别是针对较大的模型。同样,对于奖励模型训练,我们发现平衡数据集非常重要,其中包含模型倾向于出于安全原因说“我无法帮助”的示例以及输出有帮助回答的示例。我们使用多目标优化,通过从有用性、真实性和安全性的奖励分数的加权和来训练多头奖励模型。
我们进一步阐述了我们的方法来减轻有害文本生成的风险。我们在各种用例中列举了大约20种有害类型(例如仇恨言论,提供医疗建议,建议危险行为)。我们通过政策专家和机器学习工程师的手动方式,或者通过使用主题关键词作为种子来提示高能力语言模型,生成了一个潜在危害查询的数据集。
鉴于造成伤害的查询,我们通过并行评估探索我们的Gemini模型并分析模型响应。正如上面讨论的,我们平衡了模型输出响应无害与有帮助的目标。从检测到的风险区域中,我们创建额外的监督微调数据来展示理想的回答。为了在规模上生成这样的响应,我们在数据生成方面严重依赖于受宪法AI(Bai等人)启发的自定义数据生成方法。2022b),我们将谷歌的内容政策语言的变体注入为“宪法”,并利用语言模型的强大的零射击推理能力(Kojima等人。WikiLingua:Rohan Anil,Andrew M. Dai,Orhan Firat,Melvin Johnson,Dmitry Lepikhin,Alexandre Passos,Siamak Shakeri,Emanuel Taropa,Paige Bailey,Zhifeng Chen,Eric Chu,Jonathan H. Clark,Laurent El Shafey,我们发现这个配方非常有效-例如在Gemini Pro中,这个整体配方能够减轻大部分我们发现的文本伤害案例,而不会对响应的有用性产生明显的降低。
6.4.3. 事实性
我们的模型在各种情况下生成准确的回答非常重要,并且要减少幻觉的频率。我们将指导调优的努力集中在三个关键的期望行为上,反映了真实世界的场景:
-
归因:如果被指示生成一个完全归因于给定上下文的响应,Gemini应该产生与上下文最高程度的忠实度的响应(Rashkin等人,2023年)。这包括根据用户提供的来源进行摘要,根据问题和提供的片段生成细粒度引文,类似于Menick等人(2022年);Peng等人(2023年),从长篇来源(如书籍)回答问题(Mihaylov等人,2018年),并将给定的源转换为所需的输出(例如从会议记录的一部分生成电子邮件)。
-
闭卷回答生成:如果提供了一个事实寻求提示而没有给出任何来源,Gemini不应该产生错误信息(参见Roberts等人的第2节(2020)的定义)。这些提示可以从寻求信息的提示(例如“印度总理是谁?”)到半创造性的提示,可能要求提供事实信息(例如“写一篇500字的支持可再生能源采用的演讲稿”)。
-
对冲:如果输入提示为“无法回答”的情况,Gemini不应该产生幻觉。相反,它应该承认无法通过对冲提供回应。这些情况包括输入提示包含错误前提问题(参见Hu等人的示例(2023年)),输入提示指示模型执行开放式问答,但答案无法从给定的上下文中推导出等等。
我们通过策划有针对性的监督微调数据集并进行RLHF,从Gemini模型中引出了这些期望的行为。请注意,这里产生的结果不包括赋予Gemini工具或检索,据称可以提高事实性(Menick等人,2022年; Peng等人。2023年)。我们在下面的各个挑战集上提供了三个关键结果。 -
事实集:一个包含事实寻求提示的评估集(主要是闭卷的)。这是通过人工注释者进行评估的,他们会手动事实核查每个回答;我们报告注释者判断为事实不准确的回答的百分比。
-
归属集合:一个包含各种需要在提示中引用来源的提示的评估集。这是通过人工标注员手动检查每个回答中对提示来源的归因来评估的;报告的指标是 AIS(Rashkin等人,2022年)。2023年)。
-
对冲集合:一种自动评估设置,我们在其中测量Gemini模型的对冲准确性。
我们在表14中将Gemini Pro与一种没有任何事实性适应的指令调整的Gemini Pro模型版本进行了比较。我们观察到,在事实性集合中,错误率减少了一半,在归因集合中,归因准确性提高了50%,并且模型在提供的避险集任务中成功避险了70%(从0%增加)。
Gemini Pro
没有事实性专注的适应
Gemini Pro
指令调优的最后阶段
事实集
(不准确率)
7.9%
[7%,9%]
3.4%
[2.8%,4.1%]
归因集
( AIS)
40.2%
[37.9%,42.4%]
59.7%
[57.2%,61.9%]
对冲集
(准确度)
0%
69.30%
表14 事实减轻措施:指导调整对不准确率、归因存在和准确避免率的影响(附带95%置信区间)。
6.5. 部署
完成审查后,为每个经批准的Gemini模型创建模型卡,以便结构化和一致地记录关键性能和责任指标,并随时间适时向外界传达这些指标的信息。
6.6. 负责任的治理
在负责任的开发过程中,我们与Google DeepMind的责任和安全委员会(RSC)进行伦理和安全审查,这是一个跨学科小组,评估Google DeepMind的项目、论文和合作是否符合Google的AI原则。RSC就影响评估、政策、评估和缓解措施提供意见和反馈。在双子座项目期间,RSC在关键政策领域(例如儿童安全)设定了具体的评估目标。
https://deepmind.google/about/responsibility-safety/
7. 讨论和结论
我们提出了Gemini,这是一系列新的模型,提升了文本、代码、图像、音频和视频的多模态模型能力。这份技术报告评估了Gemini在一系列广泛研究的基准测试中的能力,我们最强大的模型Gemini Ultra在各个方面都取得了重大进展。在自然语言领域,通过在大规模数据和模型训练中进行精心开发,性能的提升持续为质量改进做出贡献,在几个基准测试中创造了新的技术水平。特别是,Gemini Ultra在考试基准MMLU上超过了人类专家的表现,得分为90.0%,自2020年首次发布以来,这一指标一直是衡量LLM进展的事实标准。在多模态领域,Gemini Ultra在大多数图像理解、视频理解和音频理解基准测试中都达到了最新的技术水平,而无需特定任务的修改或调整。特别是,Gemini Ultra的多模态推理能力在最近的MMMU基准测试中表现出最先进的性能(Yue等人,2023年),其中包括需要大学水平学科知识和深思熟虑的图像问题。
除了在基准测试中取得的最新成果,我们最为兴奋的是 Gemini 模型所带来的新的应用案例。Gemini模型的新功能可以解析复杂的图像,如图表或信息图表,对交错的图像、音频和文本序列进行推理,并生成交错的文本和图像作为响应,开辟了各种各样的新应用。正如报告和附录中的图表所示,双子座可以在教育、日常问题解决、多语言交流、信息摘要、提取和创造力等领域开启新的方法。我们预计这些模型的用户将发现我们自己的调查中只是触及到了一小部分的各种有益的新用途。
尽管语言模型具有令人印象深刻的能力,但我们应该注意到其使用存在一些限制。需要继续进行关于由LLMs生成的“幻觉”的研究和开发,以确保模型输出更可靠和可验证。尽管LLMs在考试基准上取得了令人印象深刻的表现,但它们在需要高级推理能力(如因果理解、逻辑推理和反事实推理)的任务上也存在困难。这凸显了需要更具挑战性和强大的评估来衡量它们对真正理解的能力,因为当前最先进的LLM在许多基准测试中已经饱和。
Gemini是我们解决智能、推进科学和造福人类使命的进一步步骤,我们对看到这些模型如何被谷歌及其他人使用感到热情。我们在机器学习、数据、基础设施和负责任的开发等领域上积累了许多创新,这些领域我们在谷歌已经追求了十多年。我们在本报告中提出的模型为我们未来开发大规模、模块化系统的广泛泛化能力奠定了坚实的基础,该系统将在许多模态上具有广泛的泛化能力。
参考文献
Jean-Baptiste Alayrac,Jeff Donahue,Pauline Luc,Antoine Miech,Iain Barr,Yana Hasson,Karel Lenc,Arthur Mensch,Katherine Millican,Malcolm Reynolds等。Flamingo:用于少样本学习的视觉语言模型。《神经信息处理系统的进展,第35卷:23716-23736,2022年》中有关机器学习的光学可重构超级计算机,具备嵌入式硬件支持。
Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey,Yanping Huang,Kathy Meier-Hellstern,Gaurav Mishra,Erica Moreira,Mark Omernick,Kevin Robinson,Sebastian Ruder,Yi Tay,Kefan Xiao,Yuanzhong Xu,Yujing Zhang,Gustavo Hernandez Abrego。Junwhan Ahn,Jacob Austin,Paul Barham,Jan Botha,James Bradbury,Siddhartha Brahma,Kevin Brooks,Michele Catasta,Yong Cheng,Colin Cherry,Christopher A. Choquette-Choo,Aakanksha Chowdhery,Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vlad Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann,Lucas Gonzalez,Guy Gur-Ari,Steven Hand,Hadi Hashemi,Le Hou,Joshua Howland,Andrea Hu,Jeffrey Hui,Jeremy Hurwitz,Michael Isard,Abe Ittycheriah,Matthew Jagielski,Wenhao Jia,Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Music Li, Wei Li, YaGuang Li, Jian Li, Hyeontaek Lim, Hanzhao Lin, Zhongtao Liu, Frederick Liu,Marcello Maggioni、Aroma Mahendru、Joshua Maynez、Vedant Misra、Maysam Moussalem、Zachary Nado、John Nham、Eric Ni、Andrew Nystrom、Alicia Parrish、Marie Pellat、Martin Polacek、Alex Polozov、Reiner Pope,Siyuan Qiao,Emily Reif,Bryan Richter,Parker Riley,Alex Castro Ros,Aurko Roy,Brennan Saeta,Rajkumar Samuel,Renee Shelby,Ambrose Slone,Daniel Smilkov,David R. So,Daniel Sohn,Simon Tokumine,Dasha Valter,Vijay Vasudevan,Kiran Vodrahalli,Xuezhi Wang,Pidong Wang,Zirui Wang,Tao Wang,John Wieting,Yuhuai Wu,Kelvin Xu,Yunhan Xu,Linting Xue,Pengcheng Yin, Jiahui Yu, Qiao Zhang, Steven Zheng, Ce Zheng, Weikang Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu.Palm 2技术报告,2023年。
人类学。Claude模型的模型卡和评估,2023年。
Yuntao Bai,Andy Jones,Kamal Ndousse,Amanda Askell,Anna Chen,Nova DasSarma,Dawn Drain,Stanislav Fort,Deep Ganguli,Tom Henighan,Nicholas Joseph,Saurav Kadavath,Jackson Kernion,Tom Conerly,Sheer El-Showk,Nelson Elhage,Zac Hatfield-Dodds,Danny Hernandez,Tristan Hume,Scott Johnston,Shauna Kravec,Liane Lovitt,Neel Nanda,Catherine Olsson,Dario Amodei,Tom Brown,Jack Clark,Sam McCandlish,Chris Olah,Ben Mann和Jared Kaplan。通过从人类反馈中进行强化学习,训练一个有用且无害的助手。2022年4月。URL https://arxiv.org/abs/2204.05862.
Yuntao Bai,Saurav Kadavath,Sandipan Kundu,Amanda Askell,Jackson Kernion,Andy Jones,Anna Chen,Anna Goldie,Azalia Mirhoseini,Cameron McKinnon等。宪法AI:来自AI反馈的无害性。arXiv预印本arXiv:2212.08073,2022b。
Paul Barham,Aakanksha Chowdhery,Jeff Dean,Sanjay Ghemawat,Steven Hand,Daniel Hurt,Michael Isard,Hyeontaek Lim,Ruoming Pang,Sudip Roy等。 Pathways:用于机器学习的异步分布式数据流。机器学习和系统论文集,第4卷:430-449,2022年。
James Bradbury,Roy Frostig,Peter Hawkins,Matthew James Johnson,Chris Leary,Dougal Maclaurin,George Necula,Adam Paszke,Jake VanderPlas,Skye Wanderman-Milne和Qiao Zhang。JAX:Python + NumPy程序的可组合转换,2018年。URL http://github.com/google/jax。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey
Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei.语言模型是少样本学习者。在H. Larochelle,M. Ranzato,R. Hadsell,M.F.的论文中。Balcan和H。Lin,编辑,神经信息处理系统的进展,第33卷,第1877-1901页。Curran Associates,Inc.,2020.URL https:// proceedings.neurips.cc/ paper_ files/ paper/ 2020/ file/ 1457c0d6bfcb4967418bfb8ac142f64a- Paper.pdf。
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert- Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba.Evaluating large language models trained on code. arXiv preprint arXiv: 2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
Xi Chen、Xiao Wang、Soravit Changpinyo、A J Piergiovanni、Piotr Padlewski、Daniel Salz、Sebastian Goodman、Adam Grycner、Basil Mustafa、Lucas Beyer、Alexander Kolesnikov、Joan Puigcerver、Nan Ding、Keran Rong、Hassan Akbari、Gaurav Mishra、Linting Xue、Ashish Thapliyal、James Bradbury、Weicheng Kuo、Mojtaba Seyedhosseini、Chao Jia、Burcu Karagol Ayan、Carlos Riquelme、Andreas Steiner、Anelia Angelova、Xiaohua Zhai、Neil Houlsby和Radu Soricut。PaLI:一个共同缩放的多语言语言-图像模型。arXiv预印本arXiv: 2209.06794, 2022。URL https:
// arxiv.org/ abs/ 2209.06794.
Xi Chen,Josip Djolonga,Piotr Padlewski,Basil Mustafa,Soravit Changpinyo,Jialin Wu,Carlos Riquelme Ruiz,Sebastian Goodman,Xiao Wang,Yi Tay,Siamak Shakeri,Mostafa Dehghani,Daniel Salz,Mario Lucic,Michael Tschannen,Arsha Nagrani,Hexiang Hu,Mandar Joshi,Bo Pang,Ceslee Montgomery,Paulina Pietrzyk,Marvin Ritter,AJ Piergiovanni,Matthias Minderer,Filip Pavetic,Austin Waters,Gang Li,Ibrahim Alabdulmohsin,Lucas Beyer,Julien Amelot,Kenton Lee,Andreas Peter Steiner,Yang Li,Daniel Keysers,Anurag Arnab,Yuanzhong Xu,Keran Rong,Alexander Kolesnikov,Mojtaba Seyedhosseini,Anelia Angelova,Xiaohua Zhai,Neil Houlsby和Radu Soricut。PaLI-X:关于扩展多语言视觉和语言模型的研究。arXiv预印本arXiv:2305.18565,2023年。
Aakanksha Chowdhery,Sharan Narang,Jacob Devlin,Maarten Bosma,Gaurav Mishra,Adam Roberts,Paul Barham,Hyung Won Chung,Charles Sutton,Sebastian Gehrmann,Parker Schuh,Kensen Shi,Sasha Tsvyashchenko,Joshua Maynez,Abhishek Rao,Parker Barnes,Yi Tay,Noam Shazeer,Vinodkumar Prabhakaran,Emily Reif,Nan Du,Ben Hutchinson,Reiner Pope,James Bradbury,Jacob Austin,Michael Isard,Guy Gur-Ari,Pengcheng Yin,Toju Duke,Anselm Levskaya,Sanjay Ghemawat,Sunipa Dev,Henryk Michalewski,Xavier Garcia,Vedant Misra,Kevin Robinson,Liam Fedus,Denny Zhou,Daphne Ippolito,David Luan,Hyeontaek Lim,Barret Zoph,Alexander Spiridonov,Ryan Sepassi,David Dohan,Shivani Agrawal,Mark Omernick,Andrew M. Dai,Thanumalayan Sankara-narayana Pillai,Marie Pellat,Aitor Lewkowycz,Erica Moreira,Rewon Child,Oleksandr Polozov,Katherine Lee,Zongwei Zhou,Xuezhi Wang,Brennan Saeta,Mark Diaz,Orhan Firat,Michele Catasta,Jason Wei,Kathy Meier-Hellstern,Douglas Eck,Jeff Dean,Slav Petrov和Noah Fiedel。Palm:通过路径扩展语言建模。机器学习研究杂志,24(240):1-113, 2023年。网址http://jmlr.org/papers/v24/22-1144.html。
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova.BoolQ:探索自然的是/否问题的令人惊讶的困难。在2019年北美计算语言学协会会议论文集中:人类语言技术,第1卷(长篇和短篇论文),2019年,第2924-2936页。URL https://aclanthology.org/N19-1300。
Jon Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki.TydiQA:A benchmark for information- seeking question answering in typo- logically diverse languages.Transactions of the Association for Computational Linguistics, 2020.URL https:// storage.googleapis.com/ tydiqa/ tydiqa.pdf。
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman.训练验证器解决数学问题。arXiv预印本arXiv:2110.14168,2021年。URL https://arxiv.org/abs/2110.14168.
Alexis Conneau,Min Ma,Simran Khanuja,Yu Zhang,Vera Axelrod,Siddharth Dalmia,Jason Riesa,Clara Rivera和Ankur Bapna。Fleurs:通用语音表示的少样本学习评估。在2022年IEEE口语语言技术研讨会(SLT)上,第798-805页。IEEE, 2023.
Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc’aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang等人。大规模分布式深度网络。神经信息处理系统的进展,25, 2012。
Harish Dattatraya Dixit,Sneha Pendharkar,Matt Beadon,Chris Mason,Tejasvi Chakravarthy,Bharath Muthiah和Sriram Sankar。大规模的静默数据损坏。arXiv预印本arXiv: 2102.11245,2021年。
Alexey Dosovitskiy,Lucas Beyer,Alexander Kolesnikov,Dirk Weissenborn,Xiaohua Zhai,Thomas Unterthiner,Mostafa Dehghani,Matthias Minderer,Georg Heigold,Sylvain Gelly,Jakob Uszkoreit和Neil Houlsby。一张图片相当于16x16个单词:用于大规模图像识别的Transformer。在ICLR 2020中。
Dheeru Dua,Yizhong Wang,Pradeep Dasigi,Gabriel Stanovsky,Sameer Singh和Matt Gardner。删除:一个需要对段落进行离散推理的阅读理解基准。在2019年北美计算语言学协会会议论文集中:人类语言技术,第1卷(长篇和短篇论文),第2368-2378页,2019年。网址https://aclanthology.org/N19-1246。
Christian Federmann, Tom Kocmi, and Ying Xin.NTREX-128-用于评估128种语言的机器翻译的新闻测试参考。在首届多语言评估扩展研讨会论文集上,第21-24页,2022年11月在线。计算语言学协会。URL https://aclanthology.org/2022.sumeval-1.4.
谷歌。Google的AI原则。2023.网址 https://ai.google/responsibility/principles/。
Yash Goyal,Tejas Khot,Douglas Summers-Stay,Dhruv Batra和Devi Parikh。让VQA中的V变得重要:提升图像理解在视觉问答中的作用。在2017年IEEE计算机视觉和模式识别会议论文集中,第6904-6913页。
Tahmid Hasan, Abhik Bhattacharjee, Md. Saiful Islam, Kazi Mubasshir, Yuan- Fang Li, Yong- Bin Kang,
M. Sohel Rahman 和 Rifat Shahriyar。XL-总结:44种语言的大规模多语言抽象摘要。在计算语言学协会的发现中:ACL-IJCNLP 2021
页面4693–4703,在线,2021年8月。计算语言学协会。doi:10.18653/v1/2021.findings-acl.413。URL https://aclanthology.org/2021.findings-acl.413。
Dan Hendrycks,Collin Burns,Steven Basart,Andy Zou,Mantas Mazeika,Dawn Song和Jacob Steinhardt。测量大规模多任务语言理解。国际学习表示会议论文集(ICLR),2021a。
Dan Hendrycks,Collin Burns,Saurav Kadavath,Akul Arora,Steven Basart,Eric Tang,Dawn Song和Jacob Steinhardt。用MATH数据集测量数学问题解决能力。arXiv预印本arXiv: 2103.03874,2021b。URL https://arxiv.org/abs/2103.03874。
Peter H Hochschild,Paul Turner,Jeffrey C Mogul,Rama Govindaraju,Parthasarathy Ranganathan,David E Culler和Amin Vahdat。不计算的核心。在操作系统热门话题研讨会论文集上,第9-16页,2021年。
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre.Training compute- optimal large language models. arXiv preprint arXiv: 2203.15556, 2022.
Shengding Hu,Yifan Luo,Huadong Wang,Xingyi Cheng,Zhiyuan Liu和Maosong Sun。不会再被愚弄了:回答带有错误前提的问题。arXiv预印本arXiv: 2307.02394, 2023。
EunJeong Hwang和Vered Shwartz。Memecap:一个用于字幕和解释模因的数据集,2023年。
Norm Jouppi,George Kurian,Sheng Li,Peter Ma,Rahul Nagarajan,Lifeng Nai,Nishant Patil,Suvinay Subramanian,Andy Swing,Brian Towles等。TPU v4:一种具有嵌入式硬件支持的用于机器学习的光学可重构超级计算机。在第50届国际计算机体系结构年会论文集上,第1-14页,2023年。
Ashwin Kalyan, Abhinav Kumar, Arjun Chandrasekaran, Ashish Sabharwal, and Peter Clark.emnlp 2019期间喝了多少咖啡?费米问题:2021年人工智能的新推理挑战。
Jungo Kasai,Keisuke Sakaguchi,Yoichi Takahashi,Ronan Le Bras,Akari Asai,Xinyan Yu,Dragomir Radev,Noah A. Smith,Yejin Choi和Kentaro Inui。实时问答:现在的答案是什么?2022年。网址https://arxiv.org/abs/2207.13332。
K Kavukcuoglu,P Kohli,L Ibrahim,D Bloxwich和S Brown。我们的原则如何帮助定义alphafold的发布。google deepmind,2022年。
Aniruddha Kembhavi,Mike Salvato,Eric Kolve,Minjoon Seo,Hannaneh Hajishirzi和Ali Farhadi。
一张图值十几张图片。在ECCV,2016年。
Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette.NarrativeQA阅读理解挑战。《计算语言学协会交易》,6: 317-328,2018年。doi:10.1162/tacl_a_00023.URL https:// aclanthology.org/ Q18- 1023。
Tom Kocmi,Rachel Bawden,Ondřej Bojar,Anton Dvorkovich,Christian Federmann,Mark Fishel,Thamme Gowda,Yvette Graham,Roman Grundkiewicz,Barry Haddow,Rebecca Knowles,Philipp Koehn,Christof Monz,Makoto Morishita,Masaaki Nagata,Toshiaki Nakazawa,Michal Novák,
Martin Popel和Maja Popović。2022 年机器翻译会议(WMT22)的发现。在第七届机器翻译会议(WMT)论文集中,2022年12月。网址https://aclanthology.org/2022.wmt-1.1。
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa.Large language models are zero- shot reasoners.NeurIPS,2022年。URL https:// arxiv.org/ abs/ 2205. 11916。
Taku Kudo和John Richardson。SentencePiece:一种简单且与语言无关的子词标记器和去标记器,用于神经文本处理。EMNLP(系统演示),2018年。doi:10.18653/v1/D18-2012.URL https://aclanthology.org/D18-2012.
Tom Kwiatkowski,Jennimaria Palomaki,Olivia Redfield,Michael Collins,Ankur Parikh,Chris Alberti,Danielle Epstein,Illia Polosukhin,Jacob Devlin,Kenton Lee,Kristina Toutanova,Llion Jones,Matthew Kelcey,Ming- Wei Chang,Andrew M. Dai,Jakob Uszkoreit,Quoc Le和Slav Petrov。自然问题:一个用于问答研究的基准。计算语言学协会交易,7:452-466,2019年。doi:10.1162/tacl_a_00276.URL https://aclanthology.org/Q19-1026。
Faisal Ladhak,Esin Durmus,Claire Cardie和Kathleen McKeown。2022年)。一个新的用于跨语言抽象摘要的基准数据集。在计算语言学协会的发现中:EMNLP 2020,第4034-4048页,在线,2020年11月。计算语言学协会。doi:10.18653/v1/2020.findings-emnlp.360.URL https:// www.aclweb.org/ anthology/ 2020. findings- emnlp. 360.
Leblond等人。AlphaCode 2技术报告。2023.URL https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf。
Yann LeCun,Yoshua Bengio和Geoffrey Hinton。深度学习。自然,521(7553):436-444,2015年。
Yujia Li,David Choi,Junyoung Chung,Nate Kushman,Julian Schrittwieser,Rémi Leblond,Tom Eccles,James Keeling,Felix Gimeno,Agustin Dal Lago等。使用alphacode进行竞赛级别的代码生成。科学,378(6624):1092–1097,2022年。
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan。Video- llava:通过对齐而不是投影学习统一的视觉表示。arXiv预印本arXiv: 2311.10122,2023年。
Pan Lu,Ran Gong,Shibiao Jiang,Liang Qiu,Siyuan Huang,Xiaodan Liang和Song-Chun Zhu。Inter-gps:可解释的几何问题求解与形式语言和符号推理。在第59届计算语言学协会年会和第11届国际自然语言处理联合会议(ACL-IJCNLP 2021)中,2021年。
潘璐,Hritik Bansal,夏天,刘家成,李春源,Hannaneh Hajishirzi,程浩,常凯伟,Michel Galley和高建峰。Mathvista:在视觉背景下评估基础模型的数学推理。arXiv预印本arXiv: 2310.02255,2023年。
Ahmed Masry,Do Long,Jia Qing Tan,Shafiq Joty和Enamul Hoque。ChartQA:一个关于图表的问题回答的基准,包括视觉和逻辑推理。在ACL 2022的发现中。
Minesh Mathew,Dimosthenis Karatzas和CV Jawahar。Docvqa:一个用于文档图像的视觉问答数据集。在2021年IEEE/CVF冬季计算机视觉应用会议论文集上,第2200-2209页。
Minesh Mathew,Viraj Bagal,Rubèn Tito,Dimosthenis Karatzas,Ernest Valveny和CV Jawahar。Infographicvqa。在IEEE / CVF冬季计算机视觉应用会议论文集上,第1697-1706页,2022年。
Jacob Menick,Maja Trebacz,Vladimir Mikulik,John Aslanides,Francis Song,Martin Chadwick,Mia Glaese,Susannah Young,Lucy Campbell-Gillingham,Geoffrey Irving等。教授语言模型使用经过验证的引用支持答案。arXiv预印本arXiv:2203.11147,2022。
Sarah E. Michalak,Andrew J. DuBois,Curtis B. Storlie,Heather M. Quinn,William N. Rust,David H. DuBois,David G. Modl,Andrea Manuzzato和Sean P. Blanchard。评估宇宙射线诱导中子对Roadrunner超级计算机硬件的影响。IEEE设备和材料可靠性交易,12(2):445-454,2012年。doi:10.1109/ TDMR. 2012.2192736。
Todor Mihaylov,Peter Clark,Tushar Khot和Ashish Sabharwal。一套盔甲能导电吗?一个用于开放式书籍问答的新数据集。在2018年经验方法在自然语言处理会议论文集中,第2381-2391页,比利时布鲁塞尔,2018年10月-11月。计算语言学协会。doi:10.18653/v1/D18-1260.网址 https://aclanthology.org/D18-1260。
Shashi Narayan,Shay B. Cohen和Mirella Lapata。不要给我细节,只要摘要!用于极端摘要的主题感知卷积神经网络。在2018年自然语言处理实证方法会议论文集中,页码为1797-1807,比利时布鲁塞尔,2018年10月-11月。计算语言学协会。doi:10.18653 / v1 / D18- 1206。URL https://aclanthology.org/D18-1206。
Oktatási Hivatal。Matematika írásbéli vizsga。Középszintű Írásbéli Vizsga,2023年5月。URL https:// dload- oktatas.educatio.hu/ erettsegi/ feladatok_2023tavasz_kozep/ k_matang_23maj_fl.pdf。用匈牙利语。
OpenAI。GPT-4技术报告。2023a.OpenAI。GPT-4V(视觉)系统卡,2023b。
OpenAI。Whisper, 2023.URL https://github.com/openai/whisper。
Long Ouyang,Jeff Wu,Xu Jiang,Diogo Almeida,Carroll L. Wainwright,Pamela Mishkin,Chong Zhang,Sandhini Agarwal,Katarina Slama,Alex Ray,John Schulman,Jacob Hilton,Fraser Kelton,Luke Miller,Maddie Simens,Amanda Askell,Peter Welinder,Paul Christiano,Jan Leike和Ryan Lowe。通过人类反馈训练语言模型遵循指示。Preprint, 2022.URL https:// cdn.openai.com/ papers/ Training_language_models_to_follow_ instructions_with_human_feedback.pdf。
Vassil Panayotov,Guoguo Chen,Daniel Povey和Sanjeev Khudanpur。Librispeech: 基于公共领域有声读物的语音识别语料库。在2015年IEEE国际会议上的声学、语音和信号处理(ICASSP)上,第5206-5210页。IEEE,2015年。
Denis Paperno,Germán Kruszewski,Angeliki Lazaridou,Quan Ngoc Pham,Raffaella Bernardi,Sandro Pezzelle,Marco Baroni,Gemma Boleda和Raquel Fernández。LAMBADA数据集:需要广泛的话语背景的词语预测。arXiv预印本arXiv: 1606.06031, 2016。
Viorica Pătrăucean, Lucas Smaira, Ankush Gupta, Adrià Recasens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang等。感知测试:多模态视频模型的诊断基准。arXiv预印本arXiv: 2305.13786,2023年。
Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen等。检查你的事实,然后再试一次:通过外部知识和自动化反馈改进大型语言模型。arXiv预印本arXiv: 2302.12813,2023年。
Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukarram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregard, Patrick Conner, Steve Gribble, et al. Jupiter evolving: transforming google’s datacenter network via optical circuit switches and software- defined networking.在2022年ACM SIGCOMM会议论文集中,第66-85页,2022年。
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever.语言模型是无监督的多任务学习者。OpenAI博客,1(8):9,2019。URL https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
Alec Radford、Jong Wook Kim、Tao Xu、Greg Brockman、Christine McLeavey和Ilya Sutskever。通过大规模弱监督实现强大的语音识别。在机器学习国际会议上,页码为28492-28518。PMLR,2023年。
Jack W. Rae,Sebastian Borgeaud,Trevor Cai,Katie Millican,Jordan Hoffmann,H. Francis Song,John Aslanides,Sarah Henderson,Roman Ring,Susannah Young,Eliza Rutherford,Tom Hennigan,Jacob Menick,Albin Cassirer,Richard Powell,George van den Driessche,Lisa Anne Hendricks,Maribeth Rauh,Po-Sen Huang,Amelia Glaese,Johannes Welbl,Sumanth Dathathri,Saffron Huang,Jonathan Uesato,John Mellor,Irina Higgins,Antonia Creswell,Nat McAleese,Amy Wu,Erich Elsen,Siddhant M. Jayakumar,Elena Buchatskaya,David Budden,Esme Sutherland,Karen Simonyan,Michela Paganini,Laurent Sifre,Lena Martens,Xiang Lorraine Li,Adhiguna Kuncoro,Aida Nematzadeh,Elena Gribovskaya,Domenic Donato,Angeliki Lazaridou,Arthur Mensch,Jean-Baptiste Lespiau,Maria Tsimpoukelli,Nikolai Grigorev,Doug Fritz,Thibault Sottiaux,Mantas Pajarskas,Toby Pohlen,Zhitao Gong,Daniel Toyama,Cyprien de Masson d’Autume,Yujia Li,Tayfun Terzi,Vladimir Mikulik,Igor Babuschkin,Aidan Clark,Diego de Las Casas,Aurelia Guy,Chris Jones,James Bradbury,Matthew Johnson,Blake A. Hechtman,Laura Weidinger,Iason Gabriel,William S. Isaac,Edward Lockhart,Simon Osindero,Laura Rimell,Chris Dyer,Oriol Vinyals,Kareem Ayoub,Jeff Stanway,Lorrayne Bennett,Demis Hassabis,Koray Kavukcuoglu和Geoffrey Irving。扩展语言模型:来自Gopher培训的方法、分析和见解。CoRR, abs/ 2112.11446, 2021.
Aditya Ramesh,Mikhail Pavlov,Gabriel Goh,Scott Gray,Chelsea Voss,Alec Radford,Mark Chen和Ilya Sutskever。零样本文本到图像生成。在国际机器学习会议上,第8821-8831页。PMLR,2021年。
Hannah Rashkin,Vitaly Nikolaev,Matthew Lamm,Lora Aroyo,Michael Collins,Dipanjan Das,Slav Petrov,Gaurav Singh Tomar,Iulia Turc和David Reitter。测量自然语言生成模型中的归因。计算语言学,第1-64页,2023年。
Scott Reed,Konrad Zolna,Emilio Parisotto,Sergio Gomez Colmenarejo,Alexander Novikov,Gabriel Barth- Maron,Mai Gimenez,Yury Sulsky,Jackie Kay,Jost Tobias Springenberg等。一种通用的代理。arXiv预印本arXiv: 2205.06175,2022年。
Parker Riley,Timothy Dozat,Jan A Botha,Xavier Garcia,Dan Garrette,Jason Riesa,Orhan Firat和Noah Constant。格式:一种用于少样本区域感知机器翻译的基准。计算语言学协会交易,2023年。
Hannah Ritchie,Veronika Samborska和Max Roser。塑料污染。我们的世界数据,2023年。https://ourworldindata.org/plastic-pollution。
Adam Roberts,Colin Raffel和Noam Shazeer。你能把多少知识装进语言模型的参数中?在2020年经验方法自然语言处理会议(EMNLP)论文集中,第5418-5426页,2020年11月在线。计算语言学协会。doi:10.18653/v1/2020.emnlp-main.437. URL https:
//aclanthology.org/2020.emnlp-main.437.
Thibault Sellam,Dipanjan Das和Ankur Parikh。BLEURT:学习文本生成的鲁棒度量。在计算语言学协会第58届年会论文集中,页码为7881-7892,在线发表,2020年7月。计算语言学协会。doi:10.18653/v1/2020.acl-main.704. URL https://aclanthology.org/2020.acl-main.704.
Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, and Omer Levy.SCROLLS:长语言序列的标准化比较。在2022年自然语言处理经验方法会议论文集中,页码为12007-12021,地点为阿布扎比,阿拉伯联合酋长国,时间为2022年12月。计算语言学协会。URL https://aclanthology.org/2022.emnlp-main.823。
Noam Shazeer.快速变压器解码:只需要一个写头。arXiv预印本arXiv: 1911.02150,2019年。
Toby Shevlane,Sebastian Farquhar,Ben Garfinkel,Mary Phuong,Jess Whittlestone,Jade Leung,Daniel Kokotajlo,Nahema Marchal,Markus Anderljung,Noam Kolt等。极端风险的模型评估。arXiv预印本arXiv:2305.15324,2023年。
Freda Shi,Mirac Suzgun,Markus Freitag,Xuezhi Wang,Suraj Srivats,Soroush Vosoughi,Hyung Won Chung,Yi Tay,Sebastian Ruder,Denny Zhou等。语言模型是多语言的思维链推理者。ICLR,2023年。
Amanpreet Singh,Vivek Natarajan,Meet Shah,Yu Jiang,Xinlei Chen,Dhruv Batra,Devi Parikh和Marcus Rohrbach。朝着能够阅读的VQA模型。在2019年IEEE/ CVF计算机视觉和模式识别会议论文集上,页码8317-8326。
Aarohi Srivastava,Abhinav Rastogi,Abhishek Rao,Abu Awal Md Shoeb,Abubakar Abid,Adam Fisch,Adam R. Brown等。超越模仿游戏:量化和推断语言模型的能力。arXiv预印本arXiv: 2206.04615,2022年。网址https://arxiv.org/abs/2206.04615.
Ilya Sutskever,Oriol Vinyals和Quoc V Le。使用神经网络的序列到序列学习。
神经信息处理系统的进展,2014年第27卷。
Oyvind Tafjord, Bhavana Dalvi和Peter Clark。校对者:生成自然语言的含义、证明和推理语句。在2020年的调查中。URL https://api.semanticscholar.org/ CorpusID: 229371222。
NLLB团队,Marta R. Costa-jussà,James Cross,Onur Çelebi,Maha Elbayad,Kenneth Heafield,Kevin Heffernan,Elahe Kalbassi,Janice Lam,Daniel Licht,Jean Maillard,Anna Sun,Skyler Wang,Guillaume Wenzek,Al Youngblood,Bapi Akula,Loic Barrault,Gabriel Mejia Gonzalez,Prangthip Hansanti,John Hoffman,Semarley Jarrett,Kaushik Ram Sadagopan,Dirk Rowe,Shannon Spruit,Chau Tran,Pierre Andrews,Necip Fazil Ayan,Shruti Bhosale,Sergey Edunov,Angela Fan,Cynthia Gao,Vedanuj Goswami,Francisco Guzmán,Philipp Koehn,Alexandre Mourachko,Christophe Ropers,Safiyyah Saleem,Holger Schwenk和Jeff Wang。没有被遗忘的语言:扩展以人为中心的机器翻译。2022.
Ashish V. Thapliyal, Jordi Pont- Tuset, Xi Chen, and Radu Soricut.跨模态-3600:A massively multilingual multimodal evaluation dataset.在EMNLP 2022年。
Kocmi Tom,Eleftherios Avramidis,Rachel Bawden,Ondřej Bojar,Anton Dvorkovich,Christian Federmann,Mark Fishel,Markus Freitag,Thamme Gowda,Roman Grundkiewicz等。2023年机器翻译会议(wmt23)的发现:LLMs已经出现,但还没有完全成熟。在WMT23-第八届机器翻译会议上,第198-216页,2023年。
Hugo Touvron,Thibaut Lavril,Gautier Izacard,Xavier Martinet,Marie-Anne Lachaux,Timothée Lacroix,Baptiste Rozière,Naman Goyal,Eric Hambro,Faisal Azhar等。Llama:开放高效的基础语言模型。arXiv预印本arXiv: 2302.13971, 2023a。
Hugo Touvron,Louis Martin,Kevin Stone,Peter Albert,Amjad Almahairi,Yasmine Babaei,Nikolay Bashlykov,Soumya Batra,Prajjwal Bhargava,Shruti Bhosale等。Llama 2:开放基础和精调聊天模型。arXiv预印本arXiv: 2307.09288, 2023b。
Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Lukasz Kaiser和Illia Polosukhin。注意力就是你所需要的。CoRR,abs/1706.03762,2017年。网址http://arxiv.org/abs/1706.03762。
Petar Veličković, Adrià Puigdomènech Badia, David Budden, Razvan Pascanu, Andrea Banino, Misha Dashevskiy, Raia Hadsell, and Charles Blundell.clrs算法推理基准。arXiv预印本arXiv: 2205.15659,2022年。
Manoj Vishwanathan, Ronak Shah, Kyung Ki Kim, and Minsu Choi.各种GPGPU工作负载上GPU的静默数据损坏(SDC)漏洞。在2015年国际SoC设计会议(ISOCC)上,第11-12页,2015年。doi:10.1109/ISOCC.2015.7401681。
Changhan Wang,Anne Wu和Juan Pino。Covost 2和大规模多语言语音到文本翻译。arXiv预印本arXiv: 2007.10310,2020年。
Changhan Wang,Morgane Riviere,Ann Lee,Anne Wu,Chaitanya Talnikar,Daniel Haziza,Mary Williamson,Juan Pino和Emmanuel Dupoux。Voxpopuli:用于表示学习、半监督学习和解释的大规模多语言语音语料库。arXiv预印本arXiv:2101.00390,2021年。
Xin Wang,Jiawei Wu,Junkun Chen,Lei Li,Yuan-Fang Wang和William Yang Wang。VATEX:一个大规模、高质量的多语言视频和语言研究数据集。在 ICCV 2019 中。
Xuezhi Wang,Jason Wei,Dale Schuurmans,Quoc Le,Ed Chi和Denny Zhou。自洽性改善了语言模型中的思维链推理。arXiv预印本arXiv: 2203.11171,2022年。
Jason Wei,Xuezhi Wang,Dale Schuurmans,Maarten Bosma,Brian Ichter,Fei Xia,Ed Chi,Quoc Le和Denny Zhou。启发思维链激发了大型语言模型的推理能力。NeurIPS,2022年。URL https://arxiv.org/abs/2201.11903。
Laura Weidinger,John Mellor,Maribeth Rauh,Conor Griffin,Jonathan Uesato,Po-Sen Huang,Myra Cheng,Mia Glaese,Borja Balle,Atoosa Kasirzadeh,Zac Kenton,Sasha Brown,Will Hawkins,Tom Stepleton,Courtney Biles,Abeba Birhane,Julia Haas,Laura Rimell,Lisa Anne Hendricks,William S. Isaac,Sean Legassick,Geoffrey Irving和Iason Gabriel。语言模型的道德和社会风险。CoRR,abs/2112.04359,2021年。URL https://arxiv.org/abs/2112.04359。
David Wetherall,Abdul Kabbani,Van Jacobson,Jim Winget,Yuchung Cheng,Brad Morrey,Uma Parthavi Moravapalle,Phillipa Gill,Steven Knight和Amin Vahdat。改进网络
具有保护性重路由的可用性。在SIGCOMM 2023年,2023年。URL https:// dl.acm.org/ doi/ 10.1145/ 3603269.3604867.
Junbin Xiao,Xindi Shang,Angela Yao和Tat-Seng Chua。NExT-QA:问答的下一个阶段是解释时间动作。在 CVPR 2021 中。
XLA。XLA:TensorFlow的优化编译器。https://www.tensorflow.org/xla,2019年。[在线;访问日期:2023年12月]。
Yuanzhong Xu,HyoukJoong Lee,Dehao Chen,Blake Hechtman,Yanping Huang,Rahul Joshi,Maxim Krikun,Dmitry Lepikhin,Andy Ly,Marcello Maggioni等。 Gspmd:通用且可扩展的ML计算图并行化。 arXiv预印本arXiv:2105.04663,2021年。
Chi yao Hong, Subhasree Mandal, Mohammad A. Alfares, Min Zhu, Rich Alimi, Kondapa Naidu Bollineni, Chandan Bhagat, Sourabh Jain, Jay Kaimal, Jeffrey Liang, Kirill Mendelev, Steve Padgett, Faro Thomas Rabe, Saikat Ray, Malveeka Tewari, Matt Tierney, Monika Zahn, Jon Zolla, Joon Ong和Amin Vahdat。B4之后:在谷歌的软件定义广域网中管理层次结构、分区和不对称性以实现可用性和规模。在SIGCOMM’18,2018年。URL https:
// conferences.sigcomm.org/ sigcomm/ 2018/ program_tuesday.html。
Jiahui Yu,Zirui Wang,Vijay Vasudevan,Legg Yeung,Mojtaba Seyedhosseini和Yonghui Wu。可口可乐:对比式字幕生成模型是图像-文本基础模型,2022a。
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, 等。扩展自回归模型以进行内容丰富的文本到图像生成。arXiv预印本arXiv: 2206.10789, 2(3): 5, 2022b。
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal.自我锁定的图像-语言模型用于视频定位和问题回答。arXiv预印本arXiv: 2305.06988, 2023。
Zhou Yu,Dejing Xu,Jun Yu,Ting Yu,Zhou Zhao,Yueting Zhuang和Dacheng Tao。ActivityNet- QA:通过问答理解复杂网络视频的数据集。在AAAI 2019中。
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen.Mmmu:一个面向专家通用人工智能的大规模多学科多模态理解和推理基准,预计于2023年发布。
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi和Yejin Choi。Hellaswag:一台机器真的能完成你的句子吗?arXiv预印本arXiv: 1905.07830,2019年。
Yu Zhang, Wei Han, James Qin, Yongqiang Wang, Ankur Bapna, Zhehuai Chen, Nanxin Chen, Bo Li, Vera Axelrod, Gary Wang, et al. Google usm:将自动语音识别扩展到100种以上语言。arXiv预印本 arXiv: 2303.01037, 2023.
Chuanyang Zheng,Zhengying Liu,Enze Xie,Zhenguo Li和Yu Li。Progressive- hint prompting improves reasoning in large language models, 2023.
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji- Rong Wen, and Jiawei Han.不要让你的llm成为一个评估基准作弊者。arXiv预印本arXiv: 2311.01964,2023年。
Luowei Zhou, Chenliang Xu, and Jason J Corso.从网络教学视频中自动学习程序的方法。在AAAI人工智能会议上,页码7590-7598,2018年。
8. 贡献和致谢
领导
Rohan Anil,文本共同负责人Sebastian Borgeaud,文本共同负责人Yonghui Wu,文本共同负责人
Jean-Baptiste Alayrac,联席负责人,多媒体视觉
Jiahui Yu,联合负责人,多媒体视觉Radu Soricut,联合负责人,多媒体视觉Johan Schalkwyk,负责人,多媒体音频Andrew M. Dai,联合负责人,数据Anja Hauth,联合负责人,数据
Katie Millican,联合负责人,数据David Silver,联合负责人,微调Slav Petrov,联合负责人,微调
Melvin Johnson,负责人,指令调优,Ioannis Antonoglou,联合负责人,强化学习技术,Julian Schrittwieser,联合负责人,强化学习技术,Amelia Glaese,负责人,人类数据
吉林陈,领导,安全
Emily Pitler,共同负责工具使用 Timothy Lillicrap,共同负责工具使用 Angeliki Lazaridou,共同负责评估 Orhan Firat,共同负责评估
James Molloy,联合负责人,基础设施 Michael Isard,联合负责人,基础设施 Paul R. Barham,联合负责人,基础设施 Tom Hennigan,联合负责人,基础设施
Benjamin Lee, Co- Lead, Codebase& Parallelism Fabio Viola, Co- Lead, Codebase& Parallelism Malcolm Reynolds, Co- Lead, Codebase& Parallelism Yuanzhong Xu, Co- Lead, Codebase& Parallelism Ryan Doherty, Lead, Ecosystem
Eli Collins,产品负责人
Clemens Meyer,合作运营负责人 Eliza Rutherford,合作运营负责人 Erica Moreira,合作运营负责人 Kareem Ayoub,合作运营负责人 Megha Goel,合作运营负责人
核心贡献者:George Tucker、Enrique Piqueras、Maxim Krikun
Iain Barr Nikolay Savinov Ivo Danihelka Becca Roelofs
核心贡献者:Anaïs White、Anders Andreassen、Tamara von Glehn、Lakshman Yagati、Mehran Kazemi、Lucas Gonzalez、Misha Khalman、Jakub Sygnowski
Alexandre Frechette Charlotte Smith Laura Culp
Lev Proleev Yi Luan
陈曦 詹姆斯·洛特斯
Nathan Schucher Federico Lebron Alban Rrustemi Natalie Clay
Phil Crone Tomas Kocisky Jeffrey Zhao Bartek Perz Dian Yu
Heidi Howard Adam Bloniarz Jack W. Rae Han Lu Laurent Sifre
Marcello Maggioni Fred Alcober
Dan Garrette,Megan Barnes,Shantanu Thakoor,Jacob Austin
Gabriel Barth-Maron William Wong Rishabh Joshi Rahma Chaabouni Deeni Fatiha
Arun Ahuja Ruibo Liu Eric Li
Sarah Cogan Jeremy Chen
核心贡献者
Chao Jia Chenjie Gu Qiao Zhang
Jordan Grimstad Ale Jakse Hartman Martin Chadwick
Gaurav Singh Tomar Xavier Garcia
伊万·森特尔埃马努埃尔·塔罗帕
Thanumalayan Sankaranarayana Pillai Jacob Devlin
Michael Laskin Diego de Las Casas Dasha Valter Connie Tao Lorenzo Blanco
Adrià Puigdomènech Badia David Reitter
Mianna Chen Jenny Brennan Clara Rivera Sergey Brin Shariq Iqbal Gabriela Surita Jane Labanowski Abhi Rao
Stephanie Winkler Emilio Parisotto Yiming Gu
Kate Olszewska Yujing Zhang Ravi Addanki Antoine Miech Annie Louis Laurent El Shafey Denis Teplyashin Geoff Brown Elliot Catt
Nithya Attaluri Jan Balaguer Jackie Xiang Pidong Wang Zoe Ashwood Anton Briukhov Albert Webson
Sanjay Ganapathy Smit Sanghavi
核心贡献者
Ajay Kannan Ming- Wei Chang Axel Stjerngren Josip Djolonga Yuting Sun Ankur Bapna
Matthew Aitchison Pedram Pejman Henryk Michalewski Tianhe Yu
Cindy Wang Juliette Love Junwhan Ahn Dawn Bloxwich Kehang Han Peter Humphreys Thibault Sellam James Bradbury Varun Godbole Sina Samangooei Bogdan Damoc Alex Kaskasoli
Sébastien M. R. Arnold Vijay Vasudevan Shubham Agrawal Jason Riesa
Dmitry Lepikhin Richard Tanburn Srivatsan Srinivasan Hyeontaek Lim Sarah Hodkinson Pranav Shyam Johan Ferret
Steven Hand Ankush Garg Tom Le Paine Jian Li
Yujia Li Minh Giang
Alexander Neitz Zaheer Abbas Sarah York Machel Reid Elizabeth Cole
Aakanksha Chowdhery Dipanjan Das Dominika Rogozińska Vitaly Nikolaev
核心贡献者Pablo Sprechmann Zachary Nado Lukas Zilka Flavien Prost Luheng He
Marianne Monteiro Gaurav Mishra Chris Welty
Josh Newlan Dawei Jia
Miltiadis Allamanis Clara Huiyi Hu Raoul de Liedekerke Justin Gilmer
Carl Saroufim Shruti Rijhwani Shaobo Hou Disha Shrivastava
Anirudh Baddepudi Alex Goldin
Adnan Ozturel Albin Cassirer Yunhan Xu Daniel Sohn Devendra Sachan
Reinald Kim Amplayo Craig Swanson Dessie Petrova
沙希·纳拉扬 阿瑟·格斯 西德哈塔·布拉玛 杰西卡·兰登 米特扬·帕特尔 邹瑞哲
Kevin Villela Luyu Wang Wenhao Jia Matthew Rahtz Mai Giménez Legg Yeung Hanzhao Lin James Keeling Petko Georgiev Diana Mincu Boxi Wu
Salem Haykal Rachel Saputro Kiran Vodrahalli
核心贡献者
James Qin Zeynep Cankara
Abhanshu Sharma Nick Fernando Will Hawkins
Behnam Neyshabur、Solomon Kim、Adrian Hutter、Priyanka Agrawal、Alex Castro-Ros
George van den Driessche Tao Wang
Fan Yang
Shuo-yiin Chang Paul Komarek Ross McIlroy Mario Lučić Guodong Zhang Wael Farhan Michael Sharman Paul Natsev
Paul Michel Yong Cheng Yamini Bansal Siyuan Qiao Kris Cao Siamak Shakeri
Christina Butterfield Justin Chung
Paul Kishan Rubenstein Shivani Agrawal
Arthur Mensch Kedar Soparkar Karel Lenc Timothy Chung Aedan Pope Loren Maggiore Jackie Kay Priya Jhakra Shibo Wang Joshua Maynez Mary Phuong Taylor Tobin
Andrea Tacchetti Maja Trebacz Kevin Robinson Yash Katariya Sebastian Riedel
核心贡献者
Paige Bailey Kefan Xiao Nimesh Ghelani Lora Aroyo Ambrose Slone Neil Houlsby Xuehan Xiong Zhen Yang
Elena Gribovskaya Jonas Adler
Mateo Wirth Lisa Lee Music Li
Thais Kagohara Jay Pavagadhi Sophie Bridgers Anna Bortsova Sanjay Ghemawat Zafarali Ahmed Tianqi Liu Richard Powell Vijay Bolina Mariko Iinuma
Polina Zablotskaia James Besley
Da- Woon Chung Timothy Dozat Ramona Comanescu Xiance Si
Jeremy Greer Guolong Su Martin Polacek
Raphaël Lopez Kaufman Simon Tokumine Hexiang Hu
Elena Buchatskaya Yingjie Miao Mohamed Elhawaty Aditya Siddhant Nenad Tomasev Jinwei Xing Christina Greer Helen Miller Shereen Ashraf Aurko Roy
Zizhao Zhang Angelos Filos Milos Besta
核心贡献者
Rory Blevins Ted Klimenko Chih-Kuan Yeh
Soravit Changpinyo Jiaqi Mu
Oscar Chang Mantas Pajarskas Carrie Muir Vered Cohen Charline Le Lan
Krishna Haridasan Amit Marathe Steven Hansen Sholto Douglas Rajkumar Samuel Mingqiu Wang Sophia Austin Chang Lan
Jiepu Jiang Justin Chiu
Jaime Alonso Lorenzo Lars Lowe Sjösund Sébastien Cevey
Zach Gleicher Thi Avrahami Anudhyan Boral Hansa Srinivasan Vittorio Selo Rhys May
Kostas Aisopos Léonard Hussenot Livio Baldini Soares Kate Baumli Michael B. Chang Adrià Recasens
Ben Caine Alexander Pritzel Filip Pavetic Fabio Pardo Anita Gergely Justin Frye
Vinay Ramasesh Dan Horgan Kartikeya Badola Nora Kassner Subhrajit Roy Ethan Dyer Víctor Campos
核心贡献者
Yunhao Tang Basil Mustafa Oran Lang Abhishek Jindal Sharad Vikram Zhitao Gong Sergi Caelles Ross Hemsley
Gregory Thornton Fangxiaoyu Feng Wojciech Stokowiec Ce Zheng
Phoebe Thacker Çağlar Ünlü Zhishuai Zhang Mohammad Saleh James Svensson Max Bileschi Piyush Patil Ankesh Anand Roman Ring Katerina Tsihlas Arpi Vezer
Marco Selvi Toby Shevlane Mikel Rodriguez
Tom Kwiatkowski Samira Daruki Keran Rong
Allan Dafoe Nicholas FitzGerald Keren Gu- Lemberg Mina Khan
Lisa Anne Hendricks Marie Pellat Vladimir Feinberg James Cobon-Kerr Tara Sainath Maribeth Rauh Sayed Hadi Hashemi Richard Ives
Yana Hasson YaGuang Li Eric Noland Yuan Cao Nathan Byrd Le Hou
Thibault Sottiaux
核心贡献者:Michela Paganini,Alexandre Moufarek,Samer Hassan,Kaushik Shivakumar,Joost van Amersfoort,Amol Mandhane,Pratik Joshi
Anirudh Goyal Matthew Tung Andrew Brock Hannah Sheahan Vedant Misra Cheng Li
Nemanja Rakićević Mostafa Dehghani Fangyu Liu
Sid Mittal Junhyuk Oh Seb Noury Eren Sezener Fantine Huot
马修·拉姆·尼古拉·德·考·查理·陈
贡献者Gamaleldin Elsayed Ed Chi
Mahdis Mahdieh Ian Tenney
南华
伊万·彼得里琴科帕特里克·凯恩迪伦·斯坎迪纳罗里舒布·贾因乔纳森·乌埃萨托罗米娜·达塔亚当·萨多夫斯基奥斯卡·布尼扬亚历克斯·托马拉多米尼克·拉比耶夫舒穆·吴
John Zhang Betty Chan
Pam G Rabinovitch David Steiner Shirley Chung Harry Askham
贡献者:Gautam Vasudevan,Edouard Leurent,Ionut Georgescu,Nan Wei
Ivy Zheng Piotr Stanczyk Ye Zhang
Subhajit Naskar Michael Azzam Christopher Choquette Matthew Johnson Adam Paszke
Chung- Cheng Chiu Jaume Sanchez Elias Afroz Mohiuddin Faizan Muhammad Jin Miao
Andrew Lee Nino Vieillard Sahitya Potluri Jane Park Elnaz Davoodi Jiageng Zhang Jeff Stanway Drew Garmon
Abhijit Karmarkar Zhe Dong
Jong Lee Aviral Kumar Luowei Zhou
Jonathan Evens,William Isaac,Zhe Chen,Johnson Jia,Anselm Levskaya,Zhenkai Zhu
Chris Gorgolewski Peter Grabowski Yu Mao
Alberto Magni Kaisheng Yao Javier Snaider
Norman Casagrande Paul Suganthan Evan Palmer Michael Fink
Daniel Andor Vikas Yadav
贡献者 Geoffrey Irving Edward Loper Manaal Faruqui Isha Arkatkar Nanxin Chen Izhak Shafran Rama Pasumarthi Nathan Lintz
Anitha Vijayakumar Lam Nguyen Thiet Pedro Valenzuela Cosmin Paduraru Daiyi Peng Katherine Lee Shuyuan Zhang Somer Greene
Duc Dung Nguyen Paula Kurylowicz Sarmishta Velury Sebastian Krause Cassidy Hardin Lucas Dixon
Lili Janzer Kiam Choo Ziqiang Feng Biao Zhang
Achintya Singhal Tejasi Latkar Mingyang Zhang Quoc Le
Elena Allica Abellan Dayou Du
Dan McKinnon Natasha Antropova Tolga Bolukbasi Orgad Keller
David Reid
Daniel Finchelstein Maria Abi Raad Remi Crocker Peter Hawkins Robert Dadashi Colin Gaffney
Sid Lall Ken Franko
Egor Filonov Anna Bulanova Rémi Leblond
Contributors Luis C. Cobo Kelvin Xu Felix Fischer Jun Xu
克里斯蒂娜·索罗金·克里斯·阿尔贝蒂
Chu- Cheng Lin Colin Evans Hao Zhou
Alek Dimitriev Hannah Forbes Dylan Banarse Zora Tung Jeremiah Liu Mark Omernick Colton Bishop Chintu Kumar Rachel Sterneck Ryan Foley Rohan Jain Swaroop Mishra Jiawei Xia Taylor Bos
Geoffrey Cideron Ehsan Amid Francesco Piccinno Xingyu Wang Praseem Banzal Petru Gurita
Ada Ma Hila Noga
Premal Shah
Daniel J. Mankowitz Alex Polozov
Nate Kushman Victoria Krakovna Sasha Brown
MohammadHossein Bateni Dennis Duan
Vlad Firoiu Meghana Thotakuri Tom Natan
Anhad Mohananey Matthieu Geist Sidharth Mudgal Sertan Girgin
Hui Li Jiayu Ye
贡献者:Ofir Roval Reiko Tojo Michael Kwong
詹姆斯·李-索普·克里斯托弗·尤·泉·袋里
Danila Sinopalnikov Sabela Ramos
John Mellor Abhishek Sharma Aliaksei Severyn Jonathan Lai Kathy Wu Nanxin Chen Heng- Tze Cheng David Miller Nicolas Sonnerat Denis Vnukov Rory Greig Jennifer Beattie Emily Caveness Libin Bai
Julian Eisenschlos Dalia El Badawy Alex Korchemniy Tomy Tsai
Mimi Jasarevic Weize Kong Phuong Dao Zeyu Zheng Frederick Liu Fan Yang
Rui Zhu Mark Geller
Tian Huey Teh Jason Sanmiya Evgeny Gladchenko Nejc Trdin
Andrei Sozanschi Daniel Toyama Evan Rosen Sasan Tavakkol Linting Xue
Chen Elkind Oliver Woodman John Carpenter
George Papamakarios
贡献者:Rupert Kemp Sushant Kafle Tanya Grunina Alice Talbert Abhimanyu Goyal Diane Wu
Denese Owusu- Afriyie Cosmo Du
Chloe Thornton Jordi Pont- Tuset
Pradyumna Narayana Jing Li
Saaber Fatehi John Wieting Omar Ajmeri Benigno Uria Tao Zhu Yeongil Ko Laura Knight Amélie Héliou Ning Niu Shane Gu Chenxi Pang Dustin Tran Yeqing Li
Nir Levine Ariel Stolovich Norbert Kalb
Rebeca Santamaria- Fernandez Sonam Goenka
Wenny Yustalim Robin Strudel Ali Elqursh
Balaji Lakshminarayanan Charlie Deck
Shyam Upadhyay Hyo Lee
Mike Dusenberry Zonglin Li Xuezhi Wang Kyle Levin
Raphael Hoffmann、Dan Holtmann-Rice、Olivier Bachem、Summer Yue
Sho Arora Christy Koh
Soheil Hassas Yeganeh
Contributors Siim Põder Steven Zheng
Francesco Pongetti Mukarram Tariq Yanhua Sun Lucian Ionita
Mojtaba Seyedhosseini Pouya Tafti
Ragha Kotikalapudi Zhiyu Liu Anmol Gulati Jasmine Liu
Xinyu Ye
Bart Chrzaszcz Lily Wang Nikhil Sethi Tianrun Li
Ben Brown Shreya Singh Wei Fan Aaron Parisi Joe Stanton
Chenkai Kuang Vinod Koverkathu
Christopher A. Choquette- Choo Yunjie Li
TJ卢
阿贝·伊蒂切里亚·普拉卡什·施罗夫·裴孙
Mani Varadarajan Sanaz Bahargam Rob Willoughby David Gaddy Ishita Dasgupta
Guillaume Desjardins Marco Cornero Brona Robenek Bhavishya Mittal
Ben Albrecht Ashish Shenoy Fedor Moiseev Henrik Jacobsson
Alireza Ghaffarkhah Morgane Rivière Zongwei Zhou Madhavi Yenugula Dominik Grewe Anastasia Petrushkina
贡献者 汤姆·杜里格 安东尼奥·桑切斯 史蒂夫·亚德洛夫斯基 谌艾米
Amir Globerson Adam Kurzrok Lynette Webb Sahil Dua
Dong Li Preethi Lahoti
Surya Bhupatiraju Dan Hurt
Haroon Qureshi Ananth Agarwal Tomer Shani Matan Eyal
Anuj Khare Shreyas Rammohan Belle Lei Wang
切坦·泰库尔 米希尔·桑杰·卡莱 金亮·魏 若欣·桑 布伦南·塞塔 泰勒·利希蒂
Yi Sun Yao Zhao
Stephan Lee Pandu Nayak Doug Fritz
Manish Reddy Vuyyuru John Aslanides
Nidhi Vyas Martin Wicke Xiao Ma Taylan Bilal
Evgenii Eltyshev Daniel Balle Nina Martin Hardie Cate Pratik Joshi James Manyika Keyvan Amiri Yelin Kim
贡献者:Mandy Guo Austin Waters Oliver Wang Joshua Ainslie Jason Baldridge Han Zhang Garima Pruthi Jakob Bauer Feng Yang Hongkun Yu
Anthony Urbanowicz Jennimaria Palomaki Chrisantha Fernando Kevin Brooks
Ken Durden Nikola Momchev
Elahe Rahimtoroghi Maria Georgaki Amit Raul
Morgan Redshaw Jinhyuk Lee Komal Jalan Dinghua Li Ginger Perng Blake Hechtman Parker Schuh Milad Nasr
Mia Chen Kieran Milan
Vladimir Mikulik Trevor Strohman Juliana Franco
项目负责人 Demis Hassabis Koray Kavukcuoglu
总体技术负责人(平等贡献)Jeffrey Dean
Oriol Vinyals
角色定义如下:
• 领先:项目期间负责子团队的个人
• 核心贡献者:在整个项目中产生了重大影响的个人。
• 贡献者:对该项目做出贡献并在其中部分参与的个人。
• Program Lead:负责Gemini项目的组织方面工作
• 总体技术负责人:负责整个双子座项目的技术指导。
在每个角色中,贡献是平等的,并以随机顺序列出。每个角色内的排序不表示贡献的排序。
Gemini是一个跨谷歌的项目,其中成员来自Google DeepMind(GDM),Google Research(GR),Knowledge and Information(K&I),Core ML,Cloud,Labs等。
我们感谢我们的审稿人和同事对报告的宝贵讨论和反馈。
— Alexandra Belias, Arielle Bier, Eleanor Tomlinson, Elspeth White, Emily Hossellman, Gaby Pearl, Helen King, Hollie Dobson, Jaclyn Konzelmann, Jason Gelman, Jennifer Beroshi, Joel Moss, Jon Small, Jonathan Fildes, Oli Gaymond, Priya Jhakra, Rebecca Bland, Reena Jana, and Tom Lue.
我们的工作得益于谷歌众多团队的奉献和努力。我们要感谢Abhi Mohan,Adekunle Bello,Aishwarya Nagarajan,Alejandro Lince,Alexander Chen,Alexander Kolbasov,Alexander Schiffhauer,Amar Subramanya的支持,Ameya Shringi, Amin Vahdat, Anda Rabatić, Anthonie Gross, Antoine Yang, Anthony Green, Anton Ruddock, Art Khurshudov, Artemis Chen, Arthur Argenson, Avinatan Hassidim, Beiye Liu, Bin Ni,Brett Daw, Bryan Chiang, Burak Gokturk, Carey Radebaugh, Carl Crous, Carrie Grimes Bostock, Charbel Kaed, Charlotte Banks, Che Diaz, Chris Larkin, Christy Lian, Claire Cui, Clement Farabet,Daniel Herndon, Dave Burke, David Battle, David Engel, Dipannita Shaw, Donghyun Koo, Doug Ritchie, Dragos Stefanescu, Emre Sargin, Eric Herren, Estella King, Fatema Alkhanaizi, Fernando Pereira,Gabriel Carvajal, Gaurav Gandhi, Goran Pavičić, Harry Richardson, Hassan Wassel, Hongji Li, Igor Ivanisevic, Ivan Jambrešić, Ivan Jurin, Jade Fowler, Jay Yagnik, Jeff Seibert, Jenna LaPlante,Jessica Austin Jianxing Lu, Jin Huang, Jonathan Caton, Josh Woodward, Joshua Foster, Katrina Wong, Kelvin Nguyen, Kira Yin, Konstantin Sharlaimov, Kun Li, Lee Hong, Lilly Taylor, Longfei Shen,Luc Mercier,Mania Abdi,Manuel Sanchez,Mario Carlos Cortes III,Mehdi Ghissassi,Micah Mosley,Michael Bendersky,Michael Harris,Mihir Paradkar,Nandita Dukkipati,Nathan Carter,Nathan Watson, Nikhil Dandekar, Nishant Ranka, Obaid Sarvana, Olcan Sercinoglu, Olivier Lacombe, Pranesh Srinivasan, Praveen Kumar, Rahul Sukthankar, Raia Hadsell, Rajagopal Ananthanarayanan,Roberto Lupi, Rosie Zou, Sachin Menezes, Sadegh Jazayeri, Sameer Bidichandani, Sania Alex, Sanjiv Kumar, Sarah Fitzgerald, Sebastian Nowozin, Shannon Hepburn, Shayne Cardwell, Sissie Hsiao,Srinivasan Venkatachary,Sugato Basu,Sundar Pichai,Sundeep Tirumalareddy,Susannah Young,Swetha Vijayaraghavan,Tania Bedrax- Weiss,Terry Chen,Ting Liu,Tom Cobley,Tomas Izo,Trystan Upstill,Varun Singhai,Vedrana Klarić Trupčević,Victor Cai,Vladimir Pudovkin,Vu Dang,Wenbo Zhao,Wesley Crow,Wesley Szeng,Xiaodan Song,Yazhou Zu,Ye Tian,Yicong Wang,Yixing Wang,Zachary Jessup,Zhenchuan Pang, Zimeng Yang, and Zoubin Ghahramani.我们还要感谢AlphaCode团队、Borg调度团队、设施团队、Gemini演示团队、全球服务器运营(GSO)团队、JAX团队、法律团队、ML SRE团队、ML超级计算机(MLSC)团队、PartIR团队、平台基础设施工程(PIE)团队和XLA编译器团队。
我们感谢谷歌的所有人,尽管上面没有明确提到,但他们分享了兴奋,对早期的Gemini模型提供了反馈,或者创建了有趣的Gemini演示用途,并与核心Gemini团队合作或支持了该项目的许多方面。
9. 附录
9.1. Chain- of- Thought Comparisons on MMLU benchmark
在本节中,我们对MMLU的几种思路进行了对比,并讨论了它们的结果。我们提出了一种新的方法,模型生成k个思维链样本,如果模型的置信度超过阈值,则选择多数投票,否则采用贪婪样本选择。阈值是根据每个模型在验证集上的表现进行优化的。所提出的方法被称为不确定性路由的思维链。这种方法背后的直觉是,当模型明显不一致时,思维链样本可能会降低性能,与最大似然决策相比。我们在图7中比较了在Gemini Ultra和GPT-4上采用该方法所获得的收益。我们发现与仅使用思维链样本相比,双子座Ultra从这种方法中获益更多。GPT-4的性能从贪婪抽样的84.2%提高到使用32个样本的不确定性路由思维链的87.3%,但它已经通过使用32个思维链样本实现了这些收益。相比之下,Gemini Ultra在使用32个样本的贪婪采样时,性能从84.0%显著提高到90.0%,而仅使用32个思维链样本时,性能略有提高,达到85.0%。
图7 | MMLU上的不确定性路由思维链。
9.2. 能力和基准测试任务
我们使用50多个基准测试作为一个整体的工具来评估Gemini模型在文本、图像、音频和视频方面的表现。我们提供了一个详细的基准任务列表,涵盖了文本理解和生成的六种不同能力:事实性、长篇背景、数学/科学、推理、摘要和多语言。我们还列举了用于图像理解、视频理解和音频理解任务的基准。
• 事实性:我们使用了5个基准:BoolQ(Clark等人,2019年),自然问题-封闭(Kwiatkowski等人。NaturalQuestions- Retrieved(Kwiatkowski等人,2019年)2019年,RealtimeQA(Kasai等人)2022年,TydiQA-无上下文和TydiQA-黄金P(Clark等人)2020年。
• 长篇背景:我们使用6个基准:NarrativeQA(Kočiský等人,2018), Scrolls- Qasper, Scrolls- Quality( Shaham et al.,2022年),XLsum(英文),XLSum(非英语语言)(Hasan等人)2021年),以及另一个内部基准。
• 数学/科学:我们使用8个基准测试:GSM8k(带有CoT)(Cobbe等人,2021), Hendryck的MATH pass@ 1(Hendrycks等人,2021b),MMLU(Hendrycks等2021a,Math-StackExchange,Math-AMC 2022-2023问题,以及其他三个内部基准测试。
• 推理:我们使用了7个基准:BigBench Hard(与CoT一起)(Srivastava等人)2022), CLRS(Veličković等人,2022年,Proof Writer(Tafjord等人)推理-费米问题(Kalyan等人)2021), Lambada( Paperno et al.2016年,HellaSwag(Zellers等人)2019), DROP(Dua等人,2019).
• 摘要:我们使用了5个基准:XL Sum(英语),XL Sum(非英语语言)(Hasan等人)2021年,WikiLingua(非英语语言),WikiLingua(英语)(Ladhak等人,2020年,XSum(Narayan等人,2019年)2018年)。
• 多语言性:我们使用10个基准:XLSum(非英语语言)(Hasan等人,2021年),WMT22(Kocmi等。2022年,WMT23(Tom等人)2023年),FRMT(Riley等人)2023年), WikiLingua(非英语语言)(Ladhak等人,2020年,TydiQA(无上下文),TydiQA(GoldP)(Clark等人,2020年),MGSM(Shi等人。2023年,翻译MMLU(Hendrycks等人)2021a), NTREX( Federmann et al.,2022年,FLORES-200(Team等人)2022年。
• 图像和视频:我们使用9个图像理解基准:MMMU(Yue等人。2023年),TextVQA(Singh等人。2019年),DocVQA(Mathew等人。2021年),ChartQA(Masry等人)。2022年),信息图VQA(Mathew等人。2022年),MathVista(Lu等人。2023年),AI2D(Kembhavi等人,2016), VQAv2( Goyal et al.,2017年),XM3600(Thapliyal等人。2022年)用于多语言图像理解,以及6个视频理解基准:VATEX(Wang等人,2021年)2019年)用于两种不同语言的字幕,YouCook2(Zhou等人,2018年),NextQA(肖等人。2021年),ActivityNet-QA(Yu等人,2019年),以及感知测试MCQA(Pătrăucean等,2019年)。2023年)。
• 音频:我们使用了5个基准测试,包括自动语音识别(ASR)任务,如FLEURS(Conneau等人)2023年,VoxPopuli(Wang等人)2021年),多语言Librispeech(Panayotov等。2015年),以及自动语音翻译任务,如CoVoST 2(Wang等,2019年)。2020年。
9.3. 定性示例
本节展示了通过提示Gemini Ultra模型的样本定性示例。图8、9、11、13、14和15展示了一些多模态推理的示例,用于图表、自然图像和表情包的图像理解任务。图10展示了Gemini Ultra的图像生成能力的一个示例,用户可以生成一个交错的图像和文本序列来设计博客文章。除了英语,图16展示了该模型在多语言环境中理解图像的能力。Gemini模型在多模态图像理解和数学推理方面也表现出色,如图12、18和19所示。图20是一个复杂的多模态推理示例,展示了模型如何为给定的用户任务组合复杂的图像理解、代码生成和指令跟随能力。在图17中,我们看到模型能够生成可工作的代码并遵循复杂的用户指令的另一个例子。最后,图21展示了Gemini Ultra通过对一系列时间上连接的帧进行推理来理解视频的能力的示例。
9.3.1. 图表理解和数据推理
国家/地区 填埋(%) 错误率(%) 焚化(%) 回收率(%)
世界 49 22 19 9
美国 73 4 19 4
欧洲 44 6 38 12
亚洲(不包括中国和印度) 39 34 19 8
Figure 8 解决一个需要多模态图表理解的问题。模型需要阅读文本,理解不同数据点之间的联系,并对其进行推理,以推荐一个有趣的观点,并按照说明生成一个正确渲染的 markdown 表格。
来源:Our World In Data(Ritchie等人,2020年)2023年)。
9.3.2. 多模态问答
提示
你知道这是什么植物吗?我应该如何最好地照顾它?
模型回应
这是一棵波斯盾植物。它是一种生长在东南亚的热带植物。它是一种受欢迎的室内植物,因为它易于护理并且有美丽的紫色叶子。
波斯盾植物喜欢明亮的间接光。它们可以忍受一些直射阳光,但过多的直射阳光会烧焦它们的叶子。它们还喜欢温暖的温度和高湿度。
波斯盾植物需要定期浇水,但不应让其浸泡在水中。土壤应保持湿润但不过湿。它们还受益于定期喷雾。
波斯盾叶植物在生长季节可以每两周施肥一次。平衡肥料是一个不错的选择。
波斯盾叶植物容易受到害虫的侵害,如粉虱和蜘蛛螨。这些害虫可以用杀虫肥皂或印楝油来控制
波斯盾叶植物可以通过茎插法繁殖。扦插应在春季或夏季进行,并应在水中或湿润的培养基中生根。
图9 回答多模态信息查询。该模型能够识别图像中显示的具体植物并提供相关信息。该模型显示出对打字错误的鲁棒性,尽管有错误,它仍能理解用户的问题。
来源:由Gemini团队的一位作者拍摄。
9.3.3. 交替图像和文本生成
提示
请撰写一篇关于一只狗和它的主人在纽约度过愉快时光的博客文章。在不同地标处拍摄的狗狗愉快地摆姿势的几张照片。
模型回应
嗨,我是Cooper。我是一只两岁的Goldendoodle,喜欢旅行。上个月,我和我的家人去了纽约市。这是我第一次来到纽约,我玩得很开心!
我们住在时代广场附近的一家酒店。看到所有明亮的灯光和人群真是太有趣了。我们去看了一场百老汇演出,我甚至还有机会见到了一些演员。
纽约市我最喜欢的地方之一是中央公园。它非常大而美丽。我喜欢四处奔跑和玩接球。我们还去了自由女神像和帝国大厦。我非常兴奋地看到了所有著名的地标。
我在纽约市玩得非常开心。这绝对是我最喜欢的旅行地之一。我迫不及待地想再回去一天!
图10 生成交错的文本和图像。该模型能够按照生成与文本密切相关的博客文章的指示,并且在所有图像中展示出高水平的一致性,其中包括狗的图像。
9.3.4. 图像理解和推理
图11 解决多模态推理问题。模型能够识别图像中的形状,理解它们的属性,并推理它们之间的关系以预测下一个对象。
来源:由Gemini团队的一位作者拍摄。
9.3.5. 几何推理
图12 解决几何推理任务。尽管指令稍微不清楚,但该模型对任务有很好的理解,并能提供有意义的推理步骤。
来源:Lu等人(2021年)。
9.3.6. 关于物体的信息寻求
图13 使用多模态输入解决谜题。该模型识别图像中的对象,并确定连接这两个对象的共同点。
来源:由Gemini团队的一位作者拍摄。
9.3.7. 基于视觉线索的多模态推理
图14 识别图像中的对象(帝国大厦)并在图像中存在小水平的视觉失真时识别它们是什么。根据图像,该模型还能够正确识别拍照人的精确位置。
来源:由Gemini团队的一位作者拍摄的照片。
9.3.8. 多模态幽默理解
图15 模因中幽默的解释。该模型展示了不仅能够描述图像中发生的事情,还能理解其含义的能力,尽管图像或提示中没有明确提及文化背景。
来源:Hwang and Shwartz(2023年)。
9.4. 多语言环境中的常识推理
图16 图像中的常识推理。该模型能够理解图表中所表示的关系,并能在多语言环境中进行推理。
来源:由Gemini团队的一位作者创建的图像。
9.4.1. 推理和代码生成
提示
创建一个名为“Opossum Search”的网络应用程序:
- 每次您进行搜索查询时,它应该将您重定向到一个带有相同查询的 Google 搜索页面,但在查询之前加上单词 opossum。
- 它应该在视觉上与Google搜索相似。
- 与谷歌的标志不同,它应该有一张从互联网上找到的负鼠的图片。
- 它应该是一个单独的HTML文件,没有单独的js或css文件。
- 页脚应该显示"由谷歌搜索提供支持"。
模型响应(渲染代码)这是负鼠搜索的代码:
图17 根据用户请求编写网站代码。该模型遵循用户定义的指令和要求,并将其转换为可运行的代码。
9.4.2. 数学:微积分
图18 解决一个微积分问题。该模型能够通过逐步解释和正确定义的LaTeX方程式来解决微积分问题。
来源:问题由麦克米兰学习提供。
9.5. 多步推理和数学
提示
2018年,A工厂生产了价值5亿福林的商品,而B工厂生产了价值4亿福林的商品。根据他们的长期计划,A工厂每年将增加5%的产量,而B工厂每年将增加6%的产量。
以上计划已在一个经济网站上发布。在文章的评论区引发了一场辩论:一位用户声称在接下来的几年里,两个工厂的产量差距会越来越小。
计算下表中的缺失值,并证明上述说法不正确。标题:| 2018 | 2019 | 2020 | 2021 |
工厂A的生产量(百万)| 500||||
B工厂的生产量(百万)| 400|||| 模型响应(渲染为Markdown)
年 进口量
工厂A(百万) 进口量
工厂B(百万) 差异
(百万)
2018 500 400 100
2019 525 424 101
2020 551.25 449.44 101.81
2021 578.81 476.41 102.4
2019年A工厂的产量为500 * 1.05 = 525百万福林。2019年B工厂的生产量为400 * 1.06 = 424百万福林。2019年生产量的差值为525-424=101百万福林。
2020年A工厂的产量为5251.05=551.25百万福林。2020年B工厂的产量为4241.06=449.44百万福林。
2020年生产量的差异为551.25- 449.44= 101.81百万福林。
2021年A工厂的产量为551.25 * 1.05 = 578.81百万福林。2021年B工厂的生产量为449.44 * 1.06 = 476.41百万福林。2021年生产量的差异为578.81- 476.41= 102.4百万福林。
正如您所看到的,两个工厂的生产量差异实际上是在增加,而不是减少。因此,声称两个工厂之间的生产量差异在接下来的几年中会变得越来越小是不正确的。
图19 解决一个多步骤的数学问题。该模型能够理解任务并生成一个带有正确计算值的 Markdown 表格。它还明确遵循说明,显示数字的来源,并回答任务中给出的问题。
来源:Oktatási Hivatal(2023年,第20页)
9.5.1. 复杂图像理解、代码生成和指令跟随
提示
我希望你将左上子图中所示的函数乘以1000,然后加上左下子图中所示的函数。生成单个结果图的Matplotlib代码。
模型响应(渲染代码)
3
4
5
6
7
8
9
渲染图
图20 多模态推理能力应用于代码生成。Gemini Ultra需要执行逆向图形任务,推断生成绘图的代码,执行额外的数学变换,并生成相关的代码。
来源:由Gemini团队的一位作者生成的图表。
9.5.2. 视频理解和推理
提示(视频)
这个人如何改进他们的技术?模型响应
这位足球运动员需要在球的击球机制上下功夫。他们的脚与球没有良好接触,导致球飞向离球门较远的地方。他们还需要调整身体姿势。他们应该用非踢腿的腿靠近镜头,踢腿的腿在前面,同时他们应该用踢腿的腿做出后续动作。
图21 视频理解和对视频中呈现的情况进行推理。在这里,我们将视频作为模型的输入,同时提供一个文本提示(这里仅提供图像以进行可视化)。该模型能够分析视频中发生的事情,并提供关于如何改进视频中的行动的建议。
视频来源:“足球/足球点球失误”
https://www.youtube.com/watch?v=VmWxjmJ3mvs
源文件在顶部资料,文字太多,图片丢失,请理解~

原创声明
======= ·
- 原创作者: 猫头虎
作者wx: Libin9iOak
微信公众号: 猫头虎技术团队
| 学习 | 复习 |
|---|---|
| ✔ |
本文为原创文章,版权归作者所有。未经许可,禁止转载、复制或引用。
作者保证信息真实可靠,但不对准确性和完整性承担责任。
未经许可,禁止商业用途。
如有疑问或建议,请联系作者。
感谢您的支持与尊重。
点击
下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。