在此专栏的上一篇文章的基础上,进行交叉实验获取最佳的K值
上一篇文章:KNN算法案例-鸢尾花分类
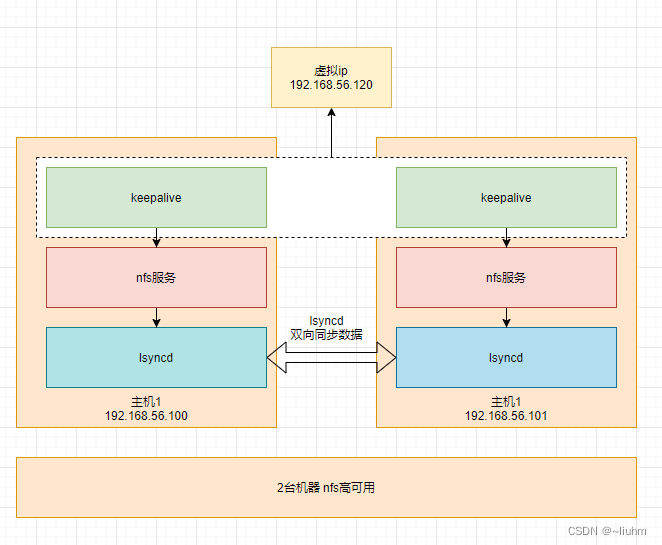
数据拆分的过程:
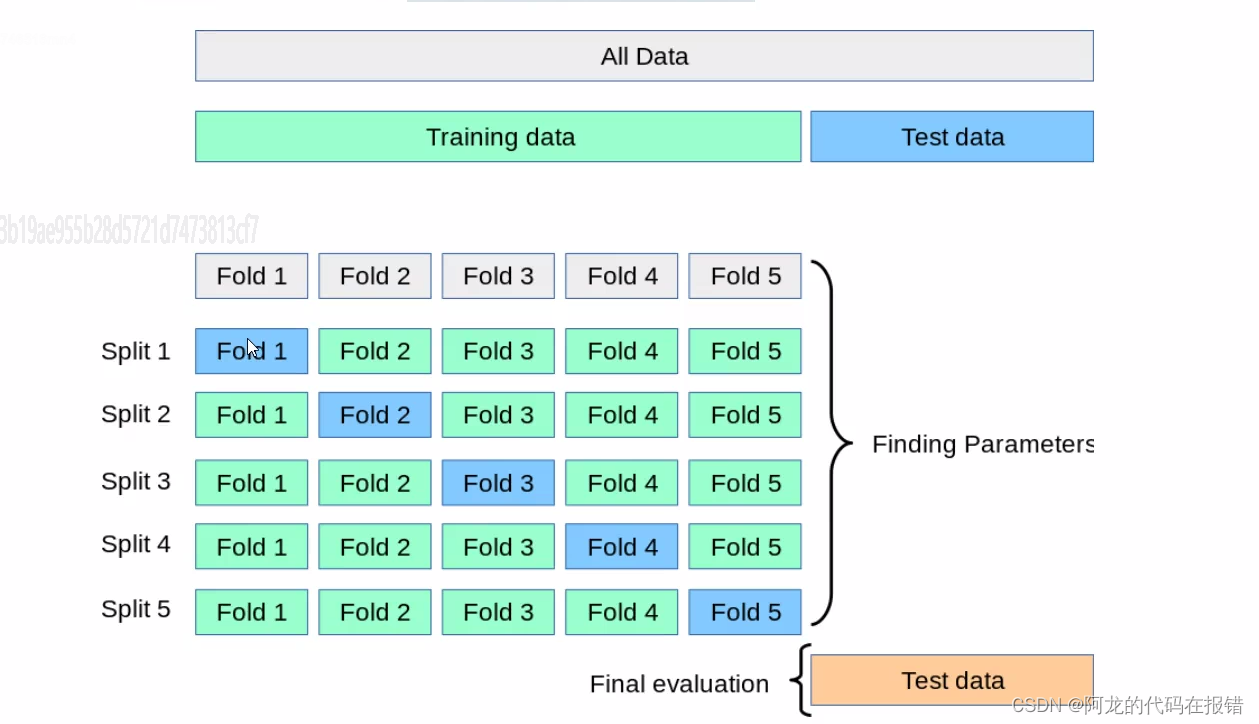
交叉验证(Cross Validation) 是一种在机器学习中广泛使用的模型评估和参数调优方法。在训练模型时,我们通常将数据集和测试集,其中训练集用于训练模型,测试集用于评估模型的性能,但是这种方法可能会受到数据集划分方式的影响,导致苹果结果的不稳定。交叉实验通过对数据集进行多次划分和评估,可以更可靠的评估模型的性能。
交叉验证的常见方法是k折交叉验证(k-Fold Cross Validation)
步骤如下:
1、将数据集随机分成k个互不重叠的自己每个子集称为一个‘折’。
2、对于每个折,执行以下操作:
a.将当前折作为验证集,其余的折作为训练集
b.使用训练集训练模型
c.使用验证集评估模型性能(如计算分类准确率,均方误差等指标)
3.计算K次迭代中模型性能指标的平均值作为模型最终的苹果结果。
交叉验证的优点如下:
1.降低模型评估结果的方差:通过多次评估模型,交叉验证可以提供更稳定、更可靠的性能评估。
2.更充分的利用数据:交叉验证可以确保每个样本都被用于训练和验证,使得模型学习和评估更为全面
在算法调优中,交叉验证可以帮助我们找到最佳的超参数(如KNN中的K值)。我们可以尝试不同的的超参数组合。这种方法可以有效地防止过拟合,提高模型在新数据上的泛化性能。
前期导入包和加载数据以及切分数据
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
对超参数进行交叉验证筛选
scores = []
params_k = np.arange(1, 31)
for k in params_k:knn = KNeighborsClassifier(n_neighbors=k)score = cross_val_score(knn, # 选择模型X_train, # 数据y_train, # 目标值cv=2, # 将数据切分为多少份scoring='accuracy' # 验证方式).mean()scores.append(score)
print(scores)
验证方式的具体如下:

选择最佳的超参数
# 使用numpy argmax() 找出最佳的超参数
k_best = np.argmax(scores) + 1
print("得分最高的超参数K值为:", k_best)
使用最佳的超参数进行模型的训练
estimator = KNeighborsClassifier(n_neighbors=k_best)
estimator.fit(X_train, y_train)
y_ = estimator.predict(X_test)
print('真实的',y_test)
print('预测值',y_)
对模型进行评分
estimator.score(X_test,y_test)
坚持学习,整理复盘