BEVFusion
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
BEVFusion:简单而强大的激光雷达相机融合框架
论文网址:BEVFusion
论文代码:BEVFusion
简读论文
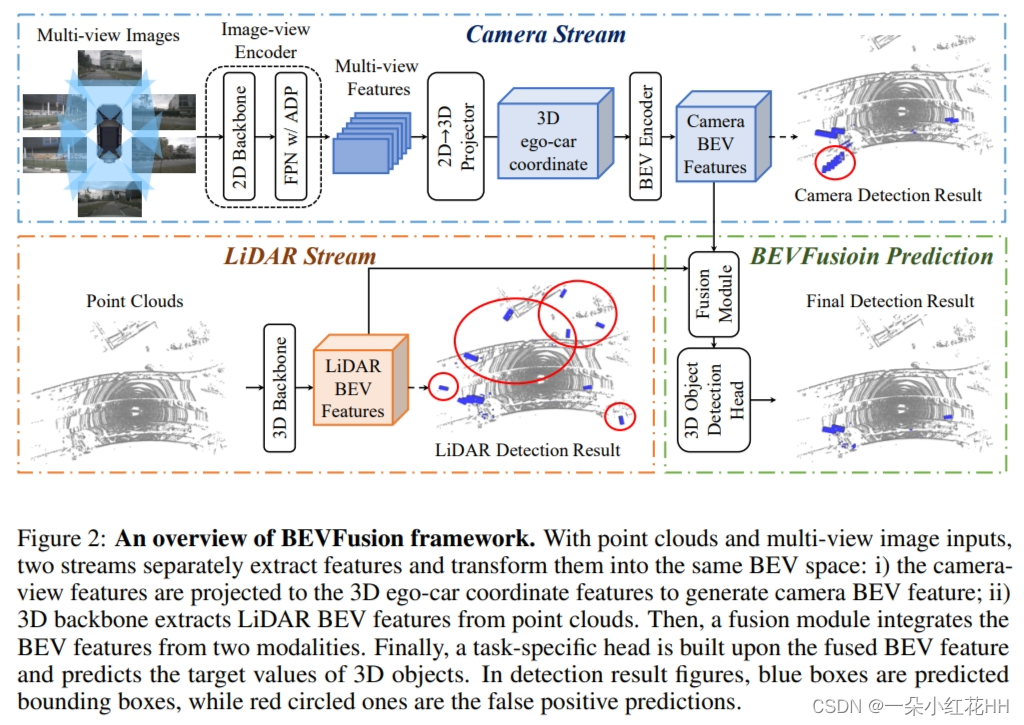
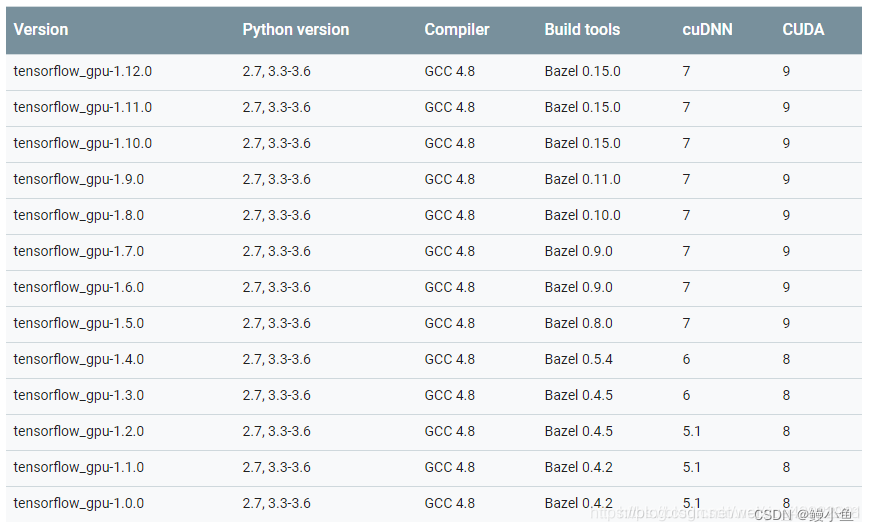
论文背景:激光雷达和摄像头是自动驾驶系统中常用的两种传感器。如何有效地融合它们的特征表示,提高3D物体检测的性能,是一个重要的研究问题。本文方法:本文提出了一种简单而有效的激光雷达-摄像头融合框架BEVFusion。主要思想是:1. 设计两个独立的子网络,分别处理激光雷达点云和摄像头图像,将它们转换为鸟瞰图(BEV)特征表示。2. 在BEV空间中融合两个模态的特征表示。3. 通过一个检测头将融合特征转换为3D边界框预测。关键创新:1. 提出了一种新的融合框架,将激光雷达和摄像头处理解耦,不依赖于激光雷达输入。这提高了系统的鲁棒性。2. 在BEV空间中融合特征,可以保留空间信息。3. 实验证明,在正常训练和鲁棒性训练下,BEVFusion均优于当前最先进水平。(下次有时间我会讲解代码)
摘要
融合相机和 LiDAR 信息已成为 3D 目标检测任务的事实上的标准。当前的方法依赖于激光雷达传感器的点云来生成图像特征的查询。然而,人们发现,这一基本假设使得当前的融合框架在激光雷达出现故障时无法产生任何预测,无论是轻微还是严重。这从根本上限制了现实自动驾驶场景的部署能力。相比之下,本文提出了一种令人惊讶的简单而新颖的融合框架,称为 BEVFusion,其摄像头流不依赖于 LiDAR 数据的输入,从而解决了以前方法的缺点。本文的实验表明,BEVFusion超越了正常训练环境下最先进的方法。在模拟各种 LiDAR 故障的鲁棒性训练设置下,BEVFusion明显超越了最先进的方法 15.7% 至 28.9% mAP。据本文所知,BEVFusion是第一个处理现实 LiDAR 故障的框架,并且可以部署到现实场景中,而无需任何后处理程序。
引言
基于视觉的感知任务,例如检测 3D 空间中的边界框,一直是全自动驾驶任务的一个关键方面 。在传统视觉车载感知系统的所有传感器中,激光雷达和摄像头通常是最关键的两个传感器,它们提供周围世界的精确点云和图像特征。在感知系统的早期阶段,人们为每个传感器设计单独的深度模型,并通过后处理方法融合信息。请注意,人们发现鸟瞰图(BEV)已成为自动驾驶场景事实上的标准,因为一般来说,汽车无法飞行。然而,由于缺乏深度信息,通常很难在纯图像输入上回归 3D 边界框,同样,当 LiDAR 没有接收到足够的点时,很难对点云上的对象进行分类。
最近,人们设计了激光雷达相机融合深度网络,以更好地利用两种模式的信息。具体来说,大部分工作可以概括如下:i)给定LiDAR点云中的一个或几个点,LiDAR到世界的变换矩阵和基本矩阵(相机到世界); ii)人们将LiDAR点、或提议转换到相机世界中并将它们用作查询,以选择相应的图像特征。这些工作构成了 3D BEV 感知的最先进方法。
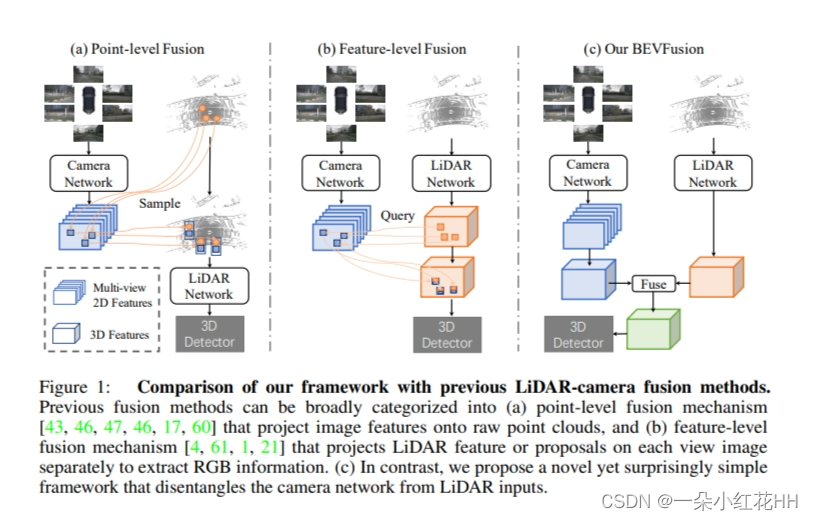
然而,人们忽视的一个基本假设是,由于需要从 LiDAR 点生成图像查询,当前的 LiDAR-相机融合方法本质上依赖于 LiDAR 传感器的原始点云,如图 1 所示。现实世界中,人们发现如果LiDAR传感器输入缺失,例如由于物体纹理、内部数据传输的系统故障而导致LiDAR点反射率较低,甚至由于硬件限制LiDAR传感器的视场角无法达到360度,当前的融合方法无法产生有意义的结果。这从根本上阻碍了这一工作在现实自动驾驶系统中的适用性。
本文认为,激光雷达-相机融合的理想框架应该是,无论另一种模态是否存在,单一模态的每个模型都不应失败,而同时拥有两种模态将进一步提高感知准确性。为此,本文提出了一个令人惊讶的简单而有效的框架,它消除了当前方法对 LiDAR-相机融合的依赖性,称为 BEVFusion。具体来说,如图 1 © 所示,本文的框架有两个独立的流,将来自相机和 LiDAR 传感器的原始输入编码为同一 BEV 空间内的特征。然后,本文设计一个简单的模块来在这两个流之后融合这些 BEV 级特征,以便最终特征可以传递到现代任务预测头架构中 。
由于本文的框架是通用方法,因此可以将当前用于相机和 LiDAR 的单模态 BEV 模型纳入本文的框架中。本文适度采用 Lift-Splat-Shoot 作为相机流,它将多视图图像特征投影到 3D 汽车坐标特征上,以生成相机 BEV 特征。同样,对于 LiDAR 流,本文选择三种流行的模型,两种基于体素的模型和一种基于pillar的模型 ,将 LiDAR 特征编码到 BEV 空间中。
在 nuScenes 数据集上,BEVFusion显示出很强的泛化能力。在相同的训练设置下,BEVFusion 将 PointPillars 和 CenterPoint 的平均精度 (mAP) 分别提高了 18.4% 和 7.1%,并且与 TransFusion 的 68.9% mAP 相比,实现了 69.2% mAP 的卓越性能,这被认为是最先进的。在以 0.5 的概率将 LiDAR 点随机丢弃在对象边界框内的鲁棒设置下,本文提出了一种新颖的增强技术,表明BEVFusion显着超越了所有基线 15.7% ~28.9% mAP,并证明了本文的方法。
本文的贡献可以总结如下:i)本文发现了当前 LiDAR-相机融合方法的一个被忽视的局限性,即 LiDAR 输入的依赖性; ii)本文提出了一个简单而新颖的框架,将激光雷达相机模态分解为两个独立的流,可以推广到多种现代架构; iii)本文在正常和鲁棒设置下都超越了最先进的融合方法。
相关工作
在这里,本文根据输入模式对 3D 检测方法进行了广泛的分类。
Camera-only. : 在自动驾驶领域,由于 KITTI 基准,近年来仅通过摄像头输入检测 3D 物体已得到广泛研究。由于 KITTI 中只有一个前置摄像头,因此大多数方法都是为了解决单目 3D 检测而开发的。随着具有更多传感器的自动驾驶数据集的发展,例如 nuScenes和 Waymo ,存在开发以多视图图像作为输入的方法的趋势,并且发现这些方法显着优于单目方法。然而,体素处理往往伴随着高计算量。
与常见的自动驾驶数据集一样,Lift-Splat-Shoot (LSS) 使用深度估计网络来提取多视角图像的隐含深度信息,并将相机特征图转换为 3D Ego-car 坐标。方法[Categorical depth distribution network for monocular 3d object detection, Bevdet, M2bev]也受到LSS的启发,并参考LiDAR进行深度预测的监督。类似的想法也可以在 BEVDet 中找到,这是多视图 3D 目标检测中最先进的方法。 MonoDistill 和 LiGA Stereo 通过将 LiDAR 信息统一到相机分支来提高性能。
LiDAR-only. : LiDAR 方法最初根据其特征模态分为两类:i)直接在原始 LiDAR 点云上运行的基于点的方法 ; ii)将原始点云转换为欧几里德特征空间,例如3D体素和特征柱。最近,人们开始在单个模型中利用这两种特征模式来提高表示能力 。另一项工作是利用鸟瞰平面的优势 。
LiDAR-camera fusion. : 由于 LiDAR 和相机产生的特征通常包含互补信息,因此人们开始开发可以在两种模式上联合优化的方法,并很快成为 3D 检测的事实上的标准。如图 1 所示,这些方法根据其融合机制可以分为两类,(a)点级融合,其中通过原始 LiDAR 点查询图像特征,然后将它们连接回作为附加点特征 ; (b) 特征级融合,首先将 LiDAR 点投影到特征空间或生成建议,查询关联的相机特征,然后连接回特征空间。后者构成了 3D 检测中最先进的方法,具体来说,TransFusion 使用 LiDAR 特征的边界框预测作为查询图像特征的建议,然后采用类似 Transformer 的架构来融合信息回到激光雷达功能。类似地,DeepFusion 将 LiDAR 特征投影到每个视图图像上作为查询,然后利用两种模式的交叉注意力。
当前融合机制的一个被忽视的假设是它们严重依赖激光雷达点云,事实上,如果激光雷达输入丢失,这些方法将不可避免地失败。这将阻碍此类算法在现实环境中的部署。相比之下, BEVFusion 是一个令人惊讶的简单而有效的融合框架,它通过将相机分支与 LiDAR 点云分离,从根本上克服了这个问题,如图 1© 所示。此外,并行工作 [Feature pyramid networks for object detection, Deepinteraction] 也解决了这个问题,并提出了有效的 LiDAR 相机 3D 感知模型。
Other modalities. : 还有其他工作可以利用其他模式,例如通过特征图串联来融合相机雷达。虽然很有趣,但这些方法超出了本文的工作范围。尽管一项并行工作[Futr3d]旨在将多模态信息融合在单个网络中,但其设计仅限于一个特定的检测头,而本文的框架可以推广到任意架构。
BEVFusion
如图 2 所示,详细介绍了本文提出的用于 3D 目标检测的框架 BEVFusion。由于基本贡献是将相机网络与 LiDAR 功能分离,因此首先介绍相机和 LiDAR 流的详细架构,然后提出一个动态融合模块来合并这些模式的功能。
相机流架构:从多视图图像到 BEV 空间
由于本文的框架能够合并任何相机流,因此从一种流行的方法开始,即 Lift-Splat-Shoot (LSS) 。由于LSS最初是为BEV语义分割而不是3D检测而提出的,本文发现直接使用LSS架构性能较差,因此适度调整LSS以提高性能。在图 2(顶部)中,详细介绍了相机流的设计,包括将原始图像编码为深层特征的图像视图编码器、将这些特征转换为 3D ego-car坐标的视图投影仪模块以及将这些特征转换为 3D ego-car坐标的编码器。最后将特征编码到鸟瞰(BEV)空间中。
Image-view Encoder.(图像视图编码器) : 旨在将输入图像编码为语义信息丰富的深层特征。它由用于基本特征提取的 2D 主干和用于尺度变量对象表示的颈部模块组成。与LSS使用卷积神经网络ResNet作为主干网络不同,本文使用更具代表性的Dual-Swin-Tiny作为主干网络。继LSS之后,本文在主干网之上使用标准特征金字塔网络(FPN)来利用多尺度分辨率的特征。为了更好地对齐这些特征,首先提出一个简单的特征自适应模块(ADP)来细化上采样的特征。具体来说,在连接之前对每个上采样特征应用自适应平均池化和 1 × 1 卷积。
adp_list = []
for i in range(self.num_outs):if i==0:resize = nn.AdaptiveAvgPool2d(self.target_size)else:resize = nn.Upsample(size = self.target_size, mode='bilinear', align_corners=True)adp = nn.Sequential(resize,ConvModule(self.out_channels,self.out_channels,1,padding=0,conv_cfg=fuse_conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg,inplace=False),)adp_list.append(adp)
self.adp = nn.ModuleList(adp_list)
View Projector Module.(投影模块):由于图像特征仍然是 2D 图像坐标,本文设计了一个视图投影仪模块将它们转换为 3D efo-car坐标。本文应用LSS中提出的2D→3D视图投影来构建Camera BEV特征。所采用的视图投影仪以图像视图特征为输入,通过分类方式密集地预测深度。然后,根据相机外在参数和预测的图像深度,可以导出要在预定义点云中渲染的图像视图特征,并获得伪体素 V ∈ RX×Y×Z×C。
BEV Encoder Module.(BEV 编码器模块):为了进一步将体素特征 V ∈ RX×Y×Z×C 编码到 BEV 空间特征(FCamera ∈ RX×Y×CCamera )中,设计了一个简单的编码器模块。本文没有应用池化操作或堆叠步长为 2 的 3D 卷积来压缩 z 维度,而是采用空间到通道 (S2C) 操作通过重塑将 V 从 4D 张量转换为 3D 张量 V ∈ RX×Y×(ZC)保留语义信息并降低成本。然后,使用四个 3×3 卷积层逐渐减少 CCamera 的通道维度并提取高级语义信息。与基于下采样低分辨率特征提取高级特征的 LSS 不同,本文的编码器直接处理全分辨率相机 BEV 特征以保留空间信息。
LiDAR 流架构:从点云到 BEV 空间
类似地,本文的框架可以合并任何将 LiDAR 点转换为 BEV 特征的网络,FLiDAR ∈ RX×Y×CLiDAR ,作为本文的 LiDAR 流。一种常见的方法是学习原始点的参数化体素化以减少 Z 维度,然后利用由稀疏 3D 卷积组成的网络来有效地生成 BEV 空间中的特征。在实践中,采用三种流行的方法:PointPillars 、CenterPoint 和 TransFusion 作为 LiDAR 流来展示本文框架的泛化能力。
Dynamic fusion module(动态融合模块)
为了有效融合来自相机(FCamera ® RX×Y×CCamera )和LiDAR(FLiDAR ® RX×Y×CLiDAR )传感器的BEV特征,本文在图3中提出了一个动态融合模块。给定相同空间维度下的两个特征,一个直观的想法是将它们连接起来并将它们与可学习的静态权重融合。受Squeeze-and-Excitation mechanism的启发,本文应用一个简单的通道注意模块来选择重要的融合特征。本文的融合模块可以表述为:
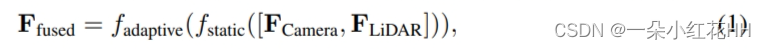
其中[·,·]表示沿通道维度的串联操作。 fstatic 是一个静态通道和空间融合函数,由 3×3 卷积层实现,用于减少 CLiDAR 中连接特征的通道维度。对于输入特征 F ∈ RX×Y×CLiDAR ,fadaptive 的公式为:
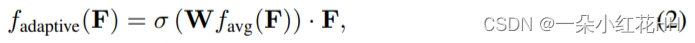
其中 W 表示线性变换矩阵(例如 1x1 卷积),favg 表示全局平均池化,σ 表示 sigmoid 函数。
Detection head
由于本文框架的最终功能是在 BEV 空间中,因此可以利用早期作品中流行的检测头模块。这进一步证明了本文框架的泛化能力。本质上,将本文的框架与三种流行的检测头类别进行比较:基于锚点的、基于无锚点的和基于变换的。
结论
在本文中,介绍了 BEVFusion,这是一种非常简单但独特的 LiDAR-相机融合框架,它消除了先前方法对 LiDAR-相机融合的依赖性。本文的框架包含两个独立的流,将原始相机和 LiDAR 传感器输入编码为同一 BEV 空间中的特征,然后是一个简单的模块来融合这些特征,以便它们可以传递到现代任务预测头架构中。大量的实验证明了我们的框架针对各种相机和激光雷达故障的强大鲁棒性和泛化能力。本文希望本文的工作能够激发对自动驾驶任务的强大多模态融合的进一步研究。