智慧农业随着数字化信息化浪潮的演变有了新的定义,在前面的系列博文中,我们从一些现实世界里面的所见所想所感进行了很多对应的实践,感兴趣的话可以自行移步阅读即可:
《自建数据集,基于YOLOv7开发构建农田场景下杂草检测识别系统》
《轻量级目标检测模型实战——杂草检测》
《激光除草距离我们实际的农业生活还有多远,结合近期所见所感基于yolov8开发构建田间作物杂草检测识别系统》
《基于yolov5的农作物田间杂草检测识别系统》
《AI助力智慧农业,基于YOLOv3开发构建农田场景下的庄稼作物、田间杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv5全系列模型【n/s/m/l/x】开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv6最新版本模型开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv7【tiny/yolov7/yolov7x】开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv4开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
自动化的激光除草,是未来大面积农业规划化作物种植生产过程中非常有效的技术手段,本文是AI助力智慧农业的第六篇系列博文,主要的目的就是想要基于yolov8来开发构建不同参数量级的检测模型,助力智能检测分析。
首先看下实例效果:
实例数据集如下所示:

共包含2种不同类型的目标对象,如下所示:
['crop', 'weed']如果对YOLOv8开发构建自己的目标检测项目有疑问的可以看下面的文章,如下所示:
《基于YOLOv8开发构建目标检测模型超详细教程【以焊缝质量检测数据场景为例】》
非常详细的开发实践教程。本文这里就不再展开了,因为从YOLOv8开始变成了一个安装包的形式,整体跟v5和v7的使用差异还是比较大的。
YOLOv8核心特性和改动如下:
1、提供了一个全新的SOTA模型(state-of-the-art model),包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于YOLACT的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
2、骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。
3、Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based 换成了 Anchor-Free
4、Loss 计算方面采用了TaskAlignedAssigner正样本分配策略,并引入了Distribution Focal Loss
5、训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
官方项目地址在这里,如下所示:
目前已经收获超过1.6w的star量了。官方提供的预训练模型如下所示:
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
| YOLOv8s | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
| YOLOv8m | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
| YOLOv8l | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
| YOLOv8x | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
简单的实例实现如下所示:
from ultralytics import YOLO# yolov8n
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8s
model = YOLO('yolov8s.yaml').load('yolov8s.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8m
model = YOLO('yolov8m.yaml').load('yolov8m.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8l
model = YOLO('yolov8l.yaml').load('yolov8l.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8x
model = YOLO('yolov8x.yaml').load('yolov8x.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)预训练模型可以到官方项目中自行下载即可。
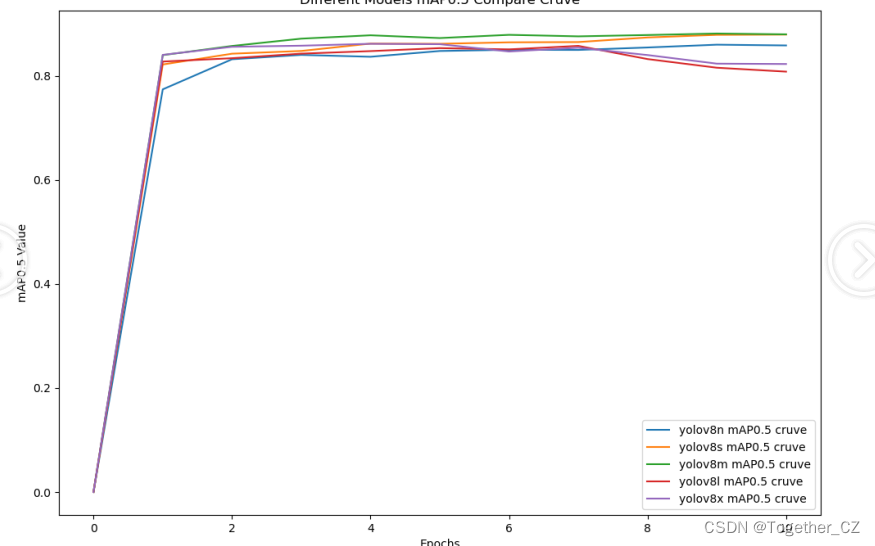
五款不同参数量级的模型保持完全相同的训练参数配置,等待训练完成后,我们对其训练过程进行对比可视化,如下所示:
【mAP0.5】
mAP0.5(mean Average Precision at 0.5 intersection over union)是一种用于评估目标检测算法性能的指标。在目标检测任务中,mAP0.5衡量了检测算法在不同类别目标上的平均精度。
mAP0.5的计算过程包括以下几个步骤:
对于每个类别的目标,首先计算出每个检测结果的置信度(confidence)和相应的预测框的准确度(accuracy)。
根据置信度对检测结果进行排序,通常是按照置信度从高到低进行排序。
采用不同阈值(通常为0.5)作为IOU(Intersection over Union)的阈值,计算每个类别下的Precision-Recall曲线。
在Precision-Recall曲线上,计算出在不同召回率(Recall)下的平均精度(Average Precision)。
对所有类别的平均精度进行求平均,即得到mAP0.5指标。
mAP0.5的取值范围是0到1,数值越高表示检测算法在目标检测任务上的性能越好。它综合考虑了不同类别目标的精度和召回率,并对检测结果进行了排序和评估。
需要注意的是,mAP0.5只是mAP的一种变体,其中IOU阈值固定为0.5。在一些特定的目标检测任务中,可能会使用其他IOU阈值来计算mAP,例如mAP0.5:0.95表示使用IOU阈值从0.5到0.95的范围来计算平均精度。
接下来来看loss走势:
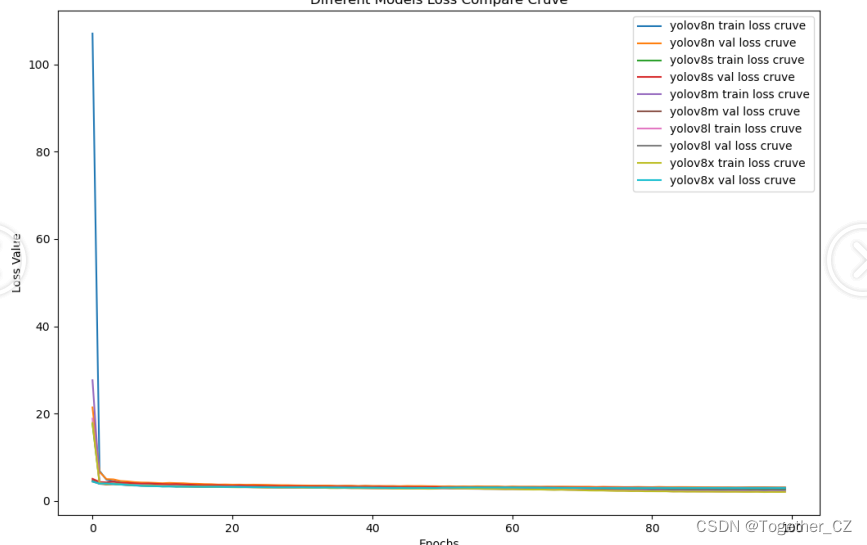
不同模型的差异不大,相对都是比较稳定的。
感兴趣的话也都可以自行尝试下!


![[论文阅读]BEVFusion](https://img-blog.csdnimg.cn/direct/7da3ac93c5bc416f98f79c93e0158589.png)