上文介绍了如何计算并行度和slot的数量,本文介绍Flink代码提交后,如何生成计算的DAG数据流图。
程序和数据流图

- 所有的Flink程序都是由三部分组成的:Source、Transformation和Sink。
- Source负责读取数据源,Transformation利用各种算子进行处理加工(Flink不区分transfer算子和action算子,统一都认为算子),Sink负责输出
- 在运行时,Flink上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了这三部分
- 每一个dataflow以一个或者多个Source开始,以一个或者多个sink结束。dataflow类似于任意的有向无环图(DAG)
- 在大部分情况下,程序中的转换运算(transformations)跟dataflow中的算子(operator)是一一对应的关系
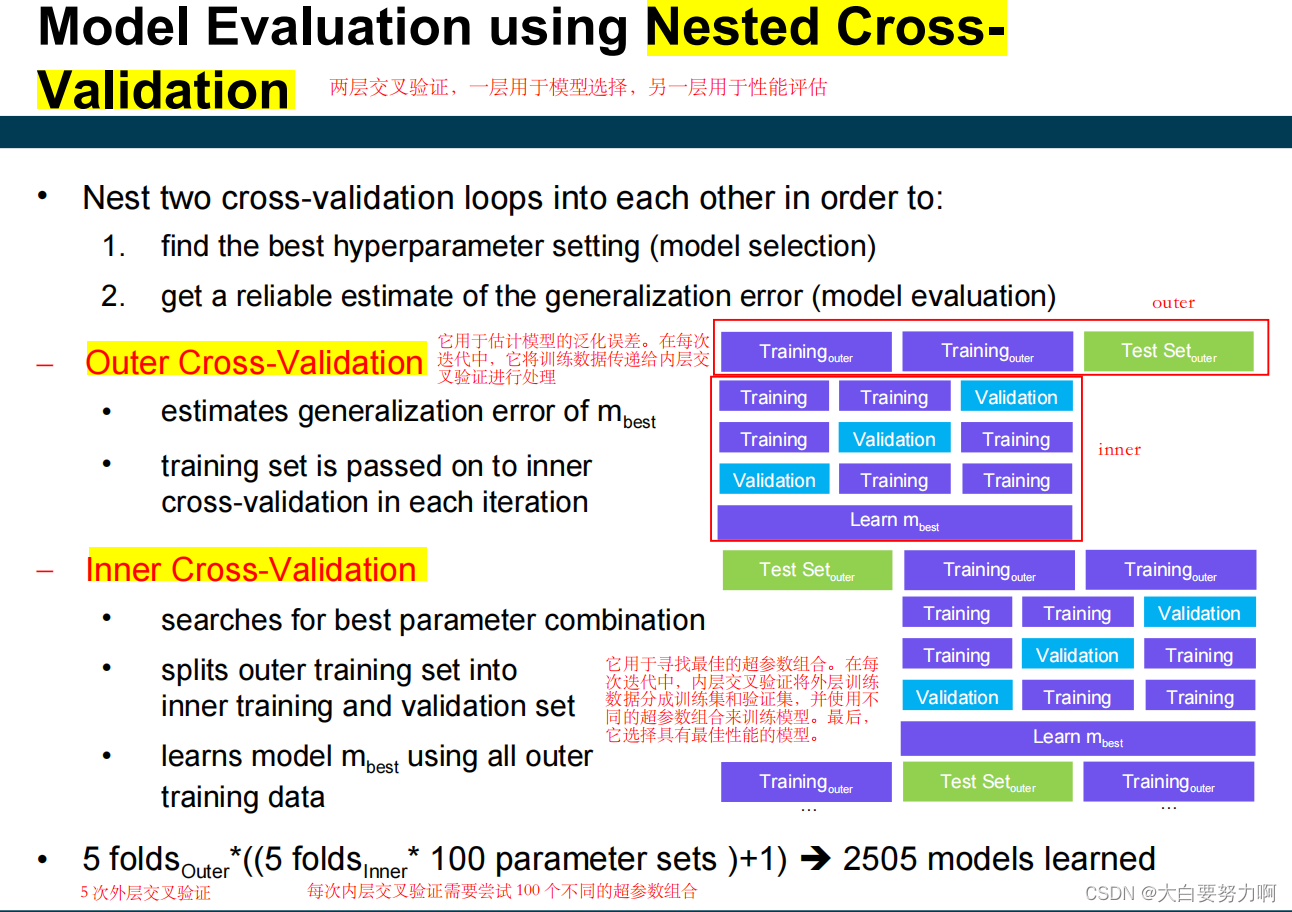
最终生成的数据流图

执行图(ExecutionGraph)
Flink中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph ->物理执行图
- StreamGraph:是根据用户通过Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构
- JobGraph:StreamGraph经过优化后生成了JobGraph,提交给JobManager的数据结构。主要的优化为,将多个符合条件的节点chain在一起作为一个节点(注意这个符合条件的计算方式)
- ExecutionGraph: Jobanager根据JobGraph生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构
- 物理执行图:JobManager根据ExecutionGraph对Job进行调度后,在各个TaskManager上部署Task后形成的“图”, 并不是一个具体的数据结构。
用一张图表达

- 代码提交运行后,会在Client生成StreamGraph初始化版本,有一个操作就会生成一个算子任务
- keyby操作不会进行计算,只是简单的分区,aggregation操作才是计算,所以一开始keyby和Aggregation都是合并在一个算子任务中
- 将满足条件的算子合并成一个大任务(one-to-one),所以讲keybyAggregation 和Sink合并成一个任务
- 在JM上生成ExecutionGraph,按并行度将任务展开,通过ExecutionEdge连接
- 执行图和物理执行图已经非常相似了,目前只需要关心ExecutionGraph即可
数据传输形式
- 一个程序中,不同的算子可能具有不同的并行度
- 算子之间的传输数据的形式可以是one-to-one(forwarding)的模式,也可以是redistributing的模式,具体是哪一种形式,可以取决于算子的种
- One-to-One:Stream维护着分区以及元素的顺序(比如source和map之间)。这意味着map算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同,map、filter、flatmap等算子都是one-to-one的对应关系。
- Redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如keyBy基于hashCode重分区、而broadcast和rebanlance会算计重新分区,这些神算子都会引起redistribute过程,而redistribute过程就类似于spark中的shuffle过程。
任务链(Operator Chains)
- Flink采用了一种称为任务链的优化技术,可以在特定的条件下减少通过本地通信的开销。为了满足任务链的要求,必须将两个或者多个算子设为下个年头给你的并行度,通过本地转发(local forward)的方式进行连接
- 相同并行度的one-to-one操作,Flink这样相连的算子链接在一起形成一个task,原来的算子称为里面的subtask
- 并行度相同,并且是one-to-one操作,两个条件缺一不可
如下图,红框标注的 Forward代表数据是one-to-one的,可以进行任务合并,但是Hash和Reblance不行。(图中为了分开展示设置了不同的slotGroup)

如果不设置共享组的话,算子任务会合并

下面来看一下一个视图
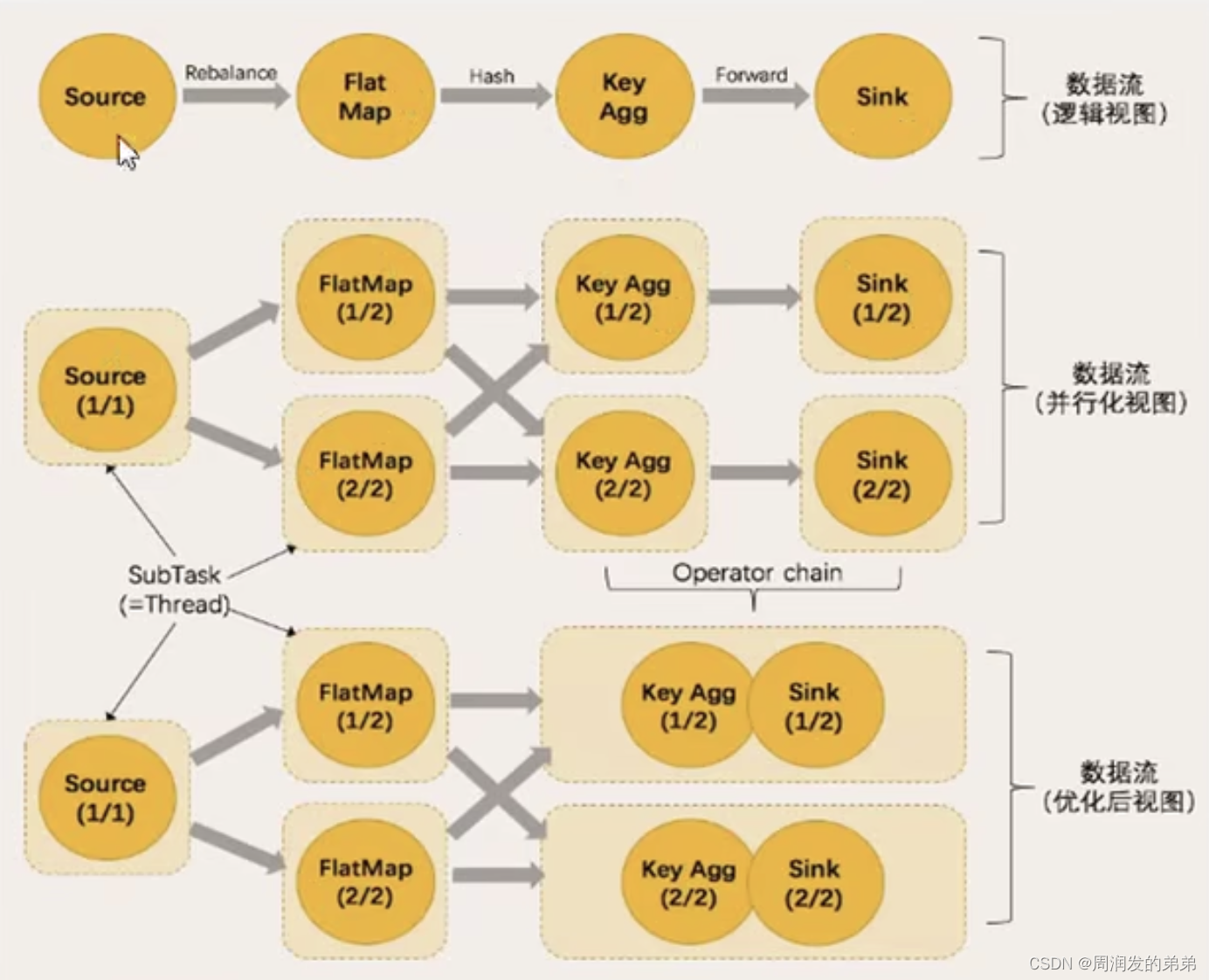
大家可以看出,只有并行度相同,且one-to-one操作才能合并task
如果不想合并task呢,大家可以思考一下,这里给出答案
- 设置共享组(上一篇文章有介绍),但是这种方式会造成资源的浪费
- 通过disableOperatorChaining来设置,可以作用于env上(表达所有算子任务都不合并),作用于单个算子上时使用disableChaining或者startNewChain,具体使用看具体业务场景





![[原创][6]探究C#多线程开发细节-“ConcurrentDictionary<T,T>解决多线程的无顺序性的问题“](https://img-blog.csdnimg.cn/direct/6c82d2c3cf914c4c81003f29b93ac9b8.gif)