作者:vivo 互联网服务器团队 - Zeng Luobin
本文主要介绍了 RocksDB 的基础原理,并阐述了 RocksDB 在vivo消息推送系统中的一些实践,通过分享一些对 RocksDB 原生能力的探索,希望可以给使用RocksDB的读者带来启发。
一、背景
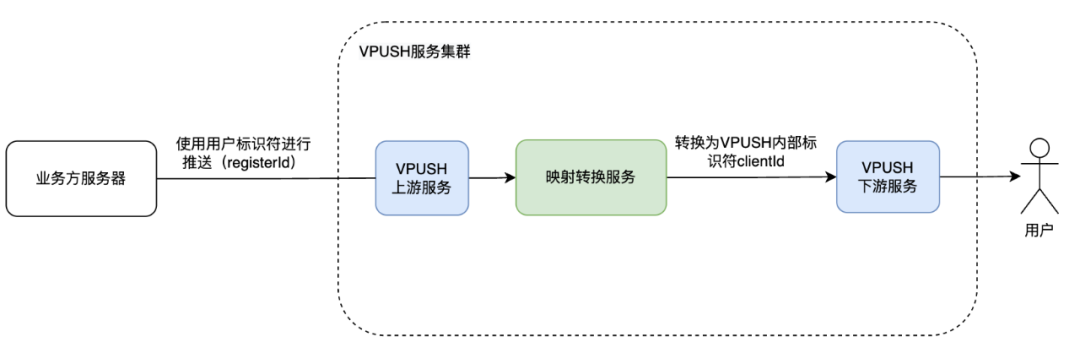
在消息推送系统中,业务方服务器通过调用推送接口向 VPUSH 服务发送消息,请求中会包含一个 registerId,用于标识接收该消息的用户设备。当 VPUSH 服务接收到推送请求时,会使用 registerId 找到对应的用户,并将消息推送给其手机。然而,在 VPUSH 内部处理消息推送时,需要使用一个内部标识符 ClientId 来标识每个用户的设备,可以通过 ClientId 查找到对应的设备信息。
因此,系统中引入了一个映射存储服务 MappingTranformServer(后文简称MT),用于处理 registerId 和 ClientId 之间的转换。MT 服务缓存了所有用户的设备标识符,使用 RocksDB 作为底层存储引擎,RocksDB 可以提供高并发读写能力,以磁盘作为存储介质,节省存储成本。当 VPUSH 服务需要将 registerId 转换为 ClientId 时,会向 MT 服务发起查询请求,MT 服务根据请求中的 registerId 查找对应的 ClientId 并返回,这样系统下游节点就能够通过 ClientId 找到对应的设备,并将消息推送到用户手机上了。
系统中除了 registerId 以外,还有许多其他的标识符,所以引入了 ClientId 来降低后期维护和开发的成本。由于regId 比较有代表性,下文中主要会以 regId 进行举例讲解。
二、RocksDB 原理介绍
在介绍业务场景之前,先简单介绍一下RocksDB的基本原理。RocksDB的前身是LevelDB,由于LevelDB不支持高并发写入,Facebook(Meta)针对于LevelDB的一些痛点进行了改造,便有了RocksDB。RocksDB相比于LevelDB,其支持高并发读写,优化了SST文件布局,提供了多种压缩策略,总的来说,RocksDB 在继承了 LevelDB 的全部功能的基础之上,还针对内存和磁盘数据存储进行了优化,使得 RocksDB 具有更高的吞吐量和更低的延迟,更适合分布式、高可靠性的存储场景。行业内也有许多数据库将RocksDB作为底层的存储引擎,比如 TiDB。
2.1 LSM设计思想
在介绍RocksDB的架构和原理之前,先来了解一下其设计思想:LSM。
LSM全称为log-structured merge-tree。LSM并非一种数据结构,而是一种设计思想,最根本的目的就是要规避对磁盘的随机写入问题,提升写的效率。其思路如下:
写入顺序:从内存到磁盘
-
将数据先写入到内存中。
-
随着内存存储数据越来越多,达到内存阈值,则会将内存中的数据转移到磁盘中。
-
磁盘中数据也分为多层,其中L0层的数据最热,而最冷的数据分布在Ln层,且会定期进行合并操作。
LSM 在 RocksDB 设计中的体现:
-
在写入数据的时候,同时记录操作日志。因为内存具有易失性,当程序崩溃后,内存的数据就丢失了,记录日志用于在程序崩溃或者重启时,内存的数据不会丢失。
-
磁盘中的数据并非使用了整体索引结构,而是使用了有序的文件集合结构。每次将内存中的数据写入到磁盘中或者将磁盘中的数据进行合并时,都会生成新的文件,这一次生成的文件会作为一个层,磁盘上会划分多层,层与层之间相互隔离,并且有序,有序保证了查找数据时可以使用二分查找。磁盘文件层级如下图所示。
-
数据按照key进行字典序排序。由上述可知,数据从内存写入磁盘时,会不断生成新的文件,所以需要不断对磁盘中的文件进行合并,然而如果数据乱序,便无法做到高效合并且保持有序。
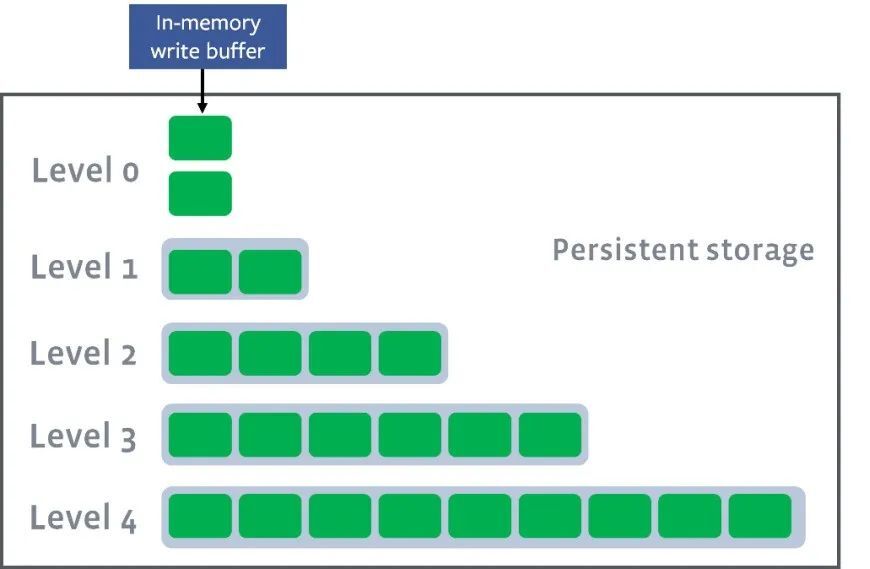
(图片来源:Leveled-Compaction)
当然,LSM也存在一些读放大、写放大、空间放大的问题:
-
【读放大】:读取的时候需要从内存一直寻找到磁盘中
-
【写放大】:程序写入数据一次,系统要写多次(例如:内存一次、磁盘一次)
-
【空间放大】:一份数据在系统中多个地方存在,占用了更多空间
2.2 内部结构
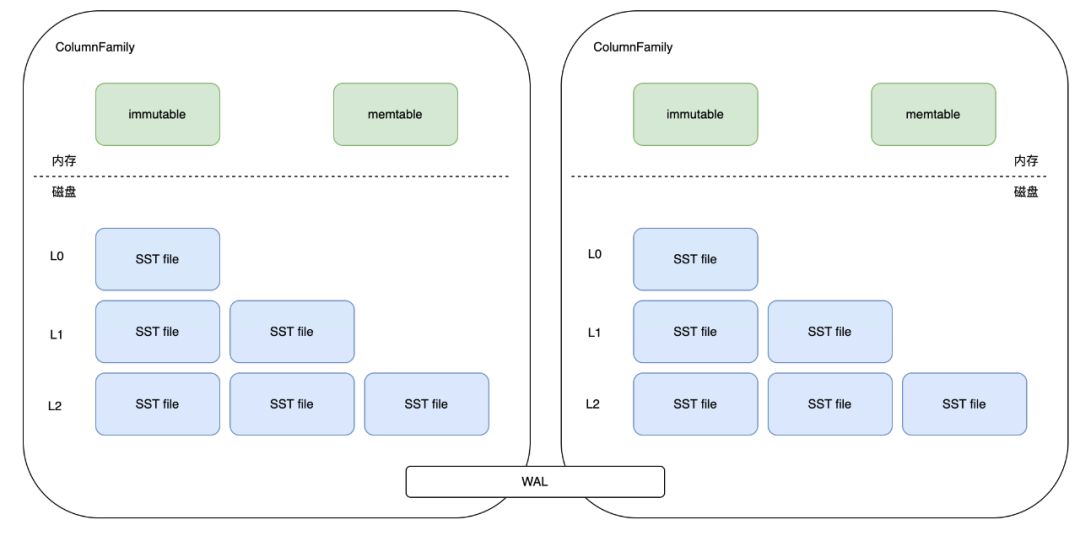
了解完LSM后,可以仔细剖析一下 RocksbDB 的内部结构,下图是 RocksDB 的内部结构图。
RocksDB 中会分出 ColumnFamily(列族,一系列 kv 组成的数据集,可以理解为就是一个namespace),所有的读写操作都需指定 ColumnFamily,每个 ColumnFamily 主要由三部分组成,分别是 memtable/sstfile/wal。
-
memtable 是内存文件数据,新写入的数据会先进入到 memtable 中,当 memtable 内存空间写满后,会有一部分老数据被转移到 sstfile 中。
-
sstfile 便是磁盘中的持久化文件。
-
所有 ColumnFamily 都会共享 WAL(write-ahead-log) 日志文件。
(1)内存部分
① memtable
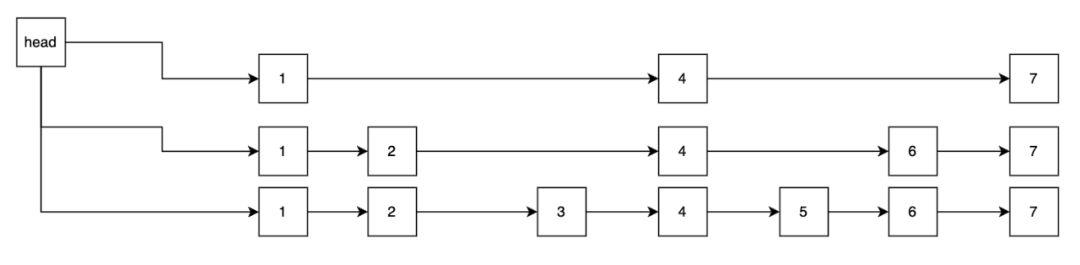
也称为active memtable。热点数据均存在这块内存中,用于快速返回用户的读写请求。一旦memtable被写满之后,就会被转为immutable memtable,并生成一个新的active memtable来提供服务。memtable支持多种结构:
skipList/vector/hashLinkList。写入数据时通过对key进行字典序排序,保持有序。跳跃表的查找速度可以简单理解近似二分查找log(n)。跳表结构如下图所示
② immutable memtable
是由于memtable写满后,转换而来,只提供读,不能做修改。当系统中触发flush时,就会将同一个ColumnFamily中的immutable memtable进行合并,生成一个sst file放入磁盘中,位于磁盘的L0层。
(2)磁盘部分
① sst,全称为sorted sequence table
是存储在磁盘中的持久化数据。sst中也有多种格式,默认设置为BlockBasedTable。其是根据data block来进行归类存储的。block中还分为data block数据块,meta block元数据块,footer块尾。每块的k-v都是有序的。data block也有缓存,名为block cache。顾名思义用于缓存SST文件中的热点数据到内存中,提供高速的读服务,所有ColumnFamily中都共用一块block cache。block cache可以设置两种数据结构:LRU cache和Clock cache。
② WAL,全称为write ahead log。
WAL会把所有写操作保存到磁盘中,当程序发生崩溃时,可以利用WAL重新构建memtable。如果容忍一定数量数据丢失,也可以关闭WAL来提升写入的性能。
③ Manifest
该文件主要用于持久化整个LSM的信息。RocksDB需要将LSM树的信息保存于内存中,以便快速进行查找或者对sst进行compaction压缩合并。而RocksDB也会将这些信息持久化到磁盘中,这个就是Manifest文件。其主要内容便是事务性相关日志以及RocksDB状态的变化。当RocksDB崩溃后重启时,就会先读取Manifest文件对LSM进行重建,再根据WAL对内存memtable进行恢复。
2.3 写入数据流程
了解完RocksDB的内部结构,我们来分析一下 RocksDB 的写入流程如下:
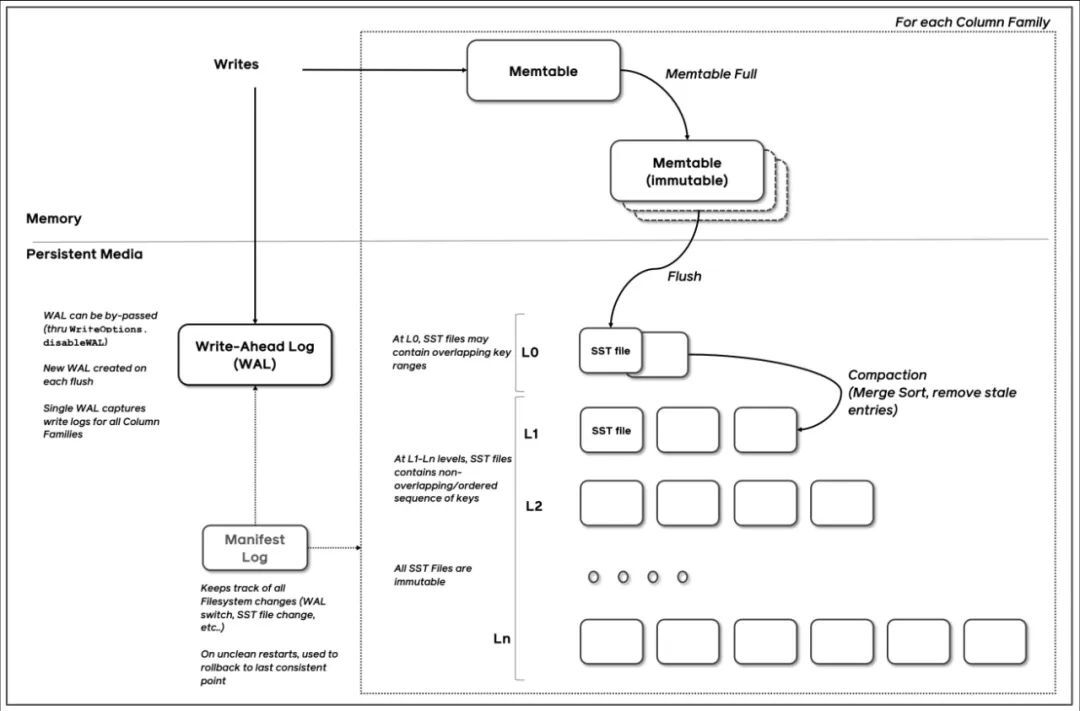
(图片来源:RocksDB-Overview)
写入流程:
-
将数据写入 memtable 的同时也会写 WAL(write-ahead-log)
-
当 memtable 达到一定阈值后,会将数据迁移到 immutable memtable,其中,immutable 中的数据只能读不能写
-
之后 flush 线程会负责将 immutable 中的数据持久化到磁盘中,即 SST file(L0层)
-
compaction 线程会触发 compaction 操作将 L0 的 sst file 合并到 L1-Ln 层中。所有的 sst file 都是只读不写
2.4 读取数据流程
同样地,还有读取流程,RocksDB 的读取流程如下:

简而言之,读流程基于内存到磁盘的顺序,逐层进行查找。
下图为读取过程中所经历的一些数据对象:
-
列族指针ColumnFamilyHandle指向了列族对象ColumnFamily,列族对象中存放有列族相关的数据:ColumnFamilyData。
-
ColumnFamilyData 中关键的数据为 SuperVersion,SuperVersion 为当前最新版本的数据集,内部维护了内存的memtable和immutable memtable的指针以及磁盘数据的指针。
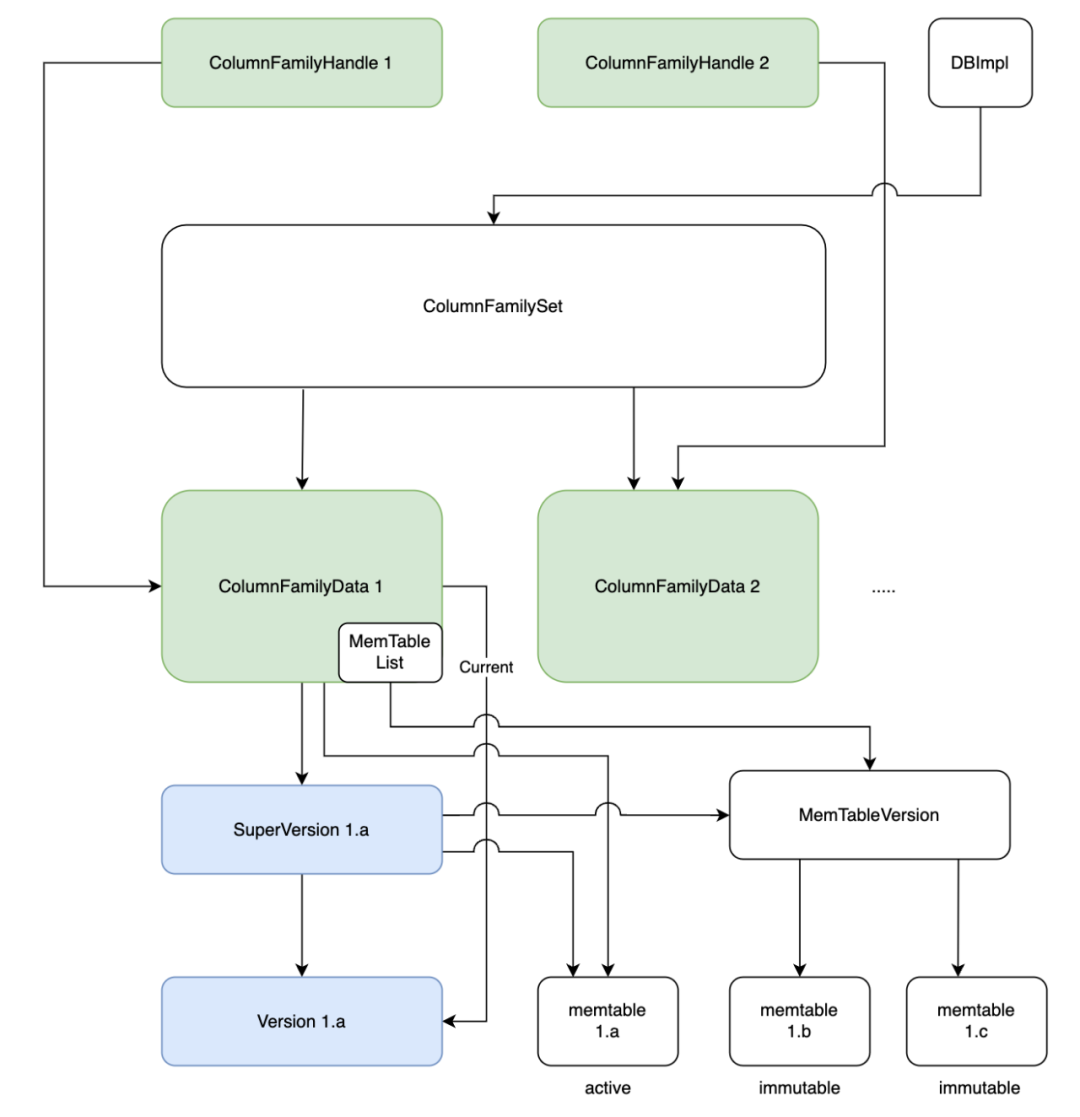
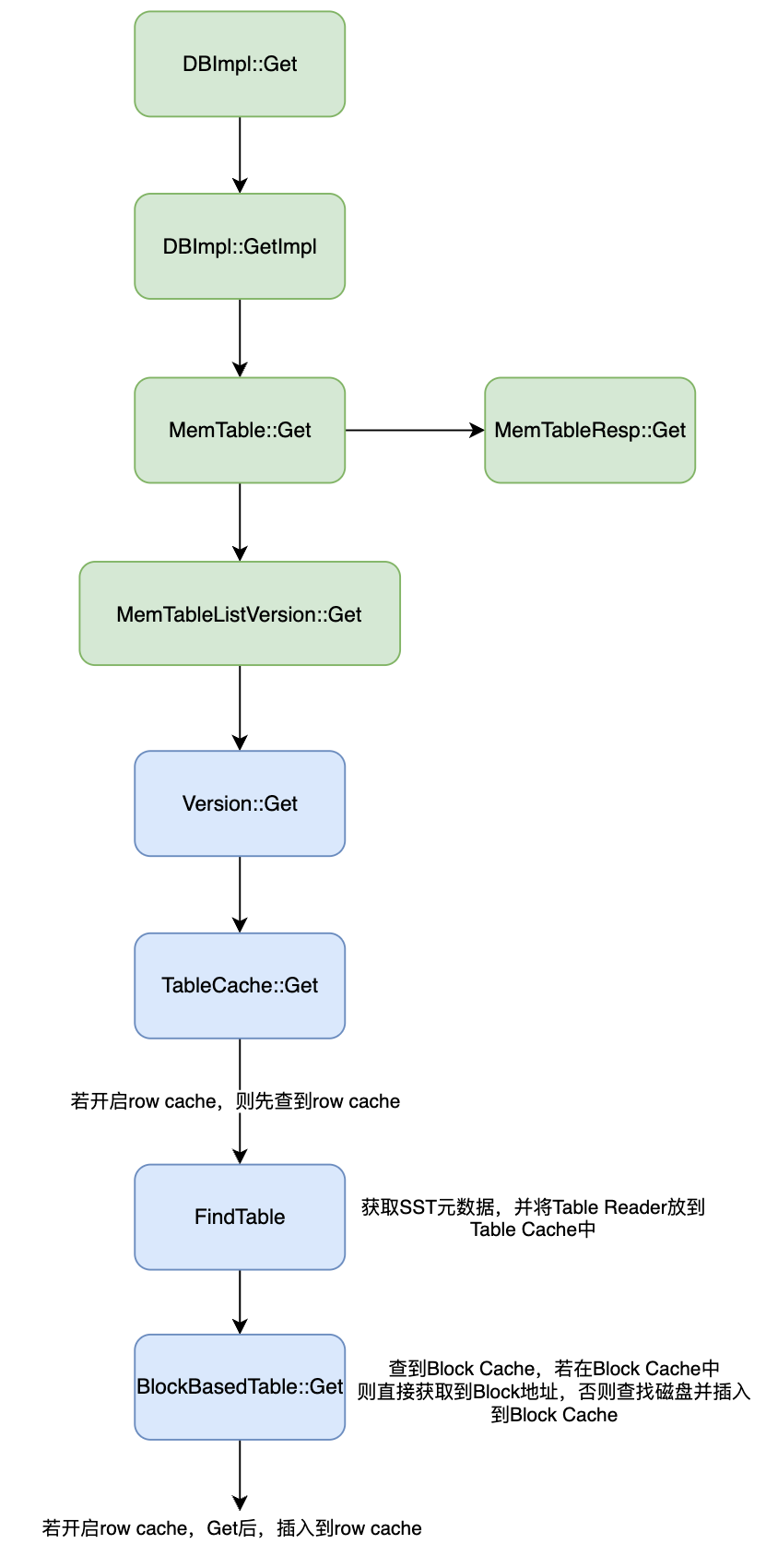
读取细节如下图所示:
-
数据读取的入口为DBImpl的Get方法,通过该入口,先在内存中的MemTable进行遍历。图中的MemTableResp为MemTable的具体实现。
-
当在MemTable中没有读取到数据时,便会到MemTableListVersion中进行读取,MemTableListVersion 内部存放着多个 immutable memtable。
-
当内存中读取不到数据时,便会到磁盘中读取,也就是Version类。Version中FilePicker逐层读取文件,每次读取到文件时,先查看TableCache,TableCache维护了SST读取器的信息,方便快速查找。
-
如果在TableCache中没找到相关的信息,便会执行FindTable,并将读取到读取器放入到TableCache中,方便下次查找。
-
最后,通过读取器对SST进行遍历查找。
2.5 小结
RocksDB 通过在写入数据时先存入内存来保证写入高性能,内存写满后便会将内存的数据转移到磁盘,写入磁盘时保持 key 有序来提升磁盘查询的效率(类似于二分查找),并且对磁盘中的数据进行分层,热点数据所在的层级越低,冷数据存储的层级越高。
三、业务场景介绍
简单了解了 RocksDB 后,来看下具体的一些业务实践场景。
目前,registerId 与 clientId 的映射数量约为数百亿,每个应用为每个用户分配一个 registerId,但每个用户只有一个 clientId,因此,registerId 到 clientId 的映射是多对一的关系。这些数据都存储在RocksDB中。

为了做到服务的高并发、高可用,每个应用的缓存以多副本的形式分散在多台 MT 服务器中,形成多对多的关系。例如,MT1、MT2 和 MT3 中均缓存了app1的全量数据,app2 的全量数据则存放于 MT2 和 MT4 中,如下图所示:
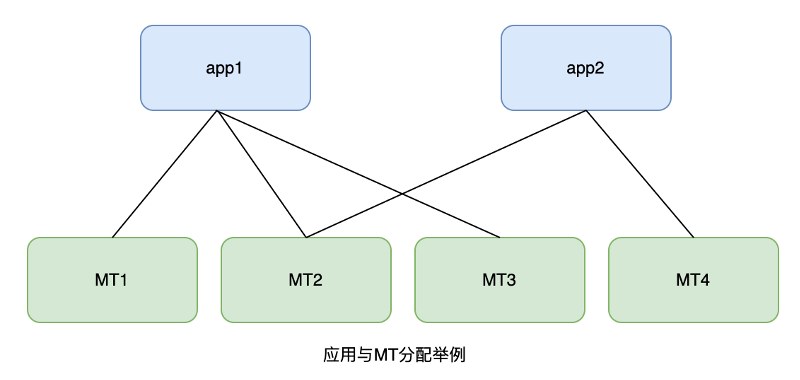
消息推送时,MT的上游服务会根据推送请求内的appId寻址到MT服务器完成映射的转换。
此时,读者可能会想到,不少系统使用 Redis 作为缓存服务,它似乎也可以完成这样的任务,为什么还需要开发一个专门的映射服务?
实际上,主要有以下几个原因:
-
成本问题:作为一种磁盘键值(KV)存储引擎,RocksDB 相比 Redis 更具有成本优势,可以有效降低存储成本。
-
容灾问题:Redis 更倾向于集中存储,如果 Redis 出现故障,就会导致消息推送失败,严重影响系统可用性。相反,使用分布式映射服务则可以在多台机器上部署数据,即使某些 MT 服务崩溃,也不会影响整个系统的消息推送。每个应用至少分配三个缓存分片,即使其中一个分片出现问题,仍有另外两个分片在支撑,容错率更高。
-
MT自定义能力更强,面对多变的业务需求,可以快速满足。
3.1 业务场景一:RocksDB列族的使用
了解了业务场景之后,可以来看一些 MT 中 RocksDB 实践案例。
RocksDB 中列族的设计贯穿了始终,列族可以简单理解为将数据进行分组,MT业务上将一个应用的数据归类到一个列族中,方便管理,也方便对某个应用的缓存进行一些特殊的操作,比如拷贝应用缓存等。
在用户没有指定列族时,RocksDB 默认使用的是 default 列族。而指定了列族之后,只会在对应列族的数据对象中进行读写操作。
(1) 初始化以及列族创建
首先,在使用列族之前,需要在 RocksDB 初始化时进行一些列族的配置,以下是 RocksDB 初始化时的示例代码:
#include "rocksdb/db.h"
#include "rocksdb/slice.h"
#include "rocksdb/options.h"
#include "rocksdb/utilities/checkpoint.h"
#include "rocksdb/metadata.h"
#include "rocksdb/cache.h"
#include "rocksdb/table.h"
#include "rocksdb/slice_transform.h"
#include "rocksdb/filter_policy.h"
#include <fstream>using namespace rocksdb;int32_t RocksDBCache::init(){DB *db; // RocskDB 指针std::string m_dbPath = "/rocksdb"; // RocksDB 文件夹位置Options options; // 初始化配置// 设置一些配置项,RocksDB配置细分较多,此处不一一列举options.IncreaseParallelism();options.OptimizeLevelStyleCompaction();// ...// 列族的相关配置options.create_missing_column_families = true;// 获取当前目录下已有的列族std::vector <std::string> column_families_list;DB::ListColumnFamilies(options, m_dbPath, &column_families_list);// “default”列族是必须要提供的if (column_families_list.empty()) {column_families_list.push_back("default");}// open DB with column_familiesstd::vector <ColumnFamilyDescriptor> column_families;for (auto cfName : column_families_list) {column_families.push_back(ColumnFamilyDescriptor(cfName, ColumnFamilyOptions()));}// 列族指针列表,创建 RocksDB 实例时会将现有的列族指针传入std::vector < ColumnFamilyHandle * > handles;s = DB::Open(options, m_dbPath, column_families, &handles, &db);// 如果列族指针列表if (column_families_list.size() != handles.size()) {return FAILURE;}// 提供一个私有属性Map,记录获取到列族指针,方便后续使用for (unsigned int i = 0; i < column_families_list.size(); i++) {handleMap[column_families_list[i]] = handles[i];}return SUCCESS;
}初始化完成后,也可以创建列族,示例代码如下,主要使用了CreateColumnFamily 接口:
int32_t RocksDBCache::createCF(const std::string &cfName) {// 初始化需要赋值为nullptr,否则出现野指针在rocksdb内会因为assert不通过直接杀掉程序ColumnFamilyHandle *cf = nullptr;Status s;if(handleMap.find(cfName) != handleMap.end()) {// 列族已经存在return FAILURE;}// 创建列族s = db->CreateColumnFamily(ColumnFamilyOptions(), cfName, &cf);if (!s.ok()) {return FAILURE;}// 写入Map,方便使用handleMap[cfName] = cf;return SUCCESS;
}(2) 读、写以及批量写入
初始化完 RocksDB 实例后,可以进行读写等操作。
读操作示例代码:
int32_t RocksDBCache::get(const std::string &cf, const std::string &key,std::string &value){// cf为列族名称,通过名称来获取到列族指针auto it = handleMap.find(cf);if (it == handleMap.end()) {return FAILURE;}std::string value = "";// 根据列族、key来获取到相应的数据,并将数据赋值给value,以参数的形式返回Status s = db->Get(ReadOptions(), it->second, key, &value);if (s.ok()) {return SUCCESS;} else if (!s.IsNotFound()) {// 除了“未找到key”之外的错误return FAILURE;}return FAILURE;
}写操作示例代码:
int32_t RocksDBCache::get(const std::string &cf, const std::string &key,const std::string &value){Status s;// 通过cf列族名称获取到对应的列族指针auto it = handleMap.find(cf);if (it == handleMap.end()) {return FAILURE;}// 通过列族指针、key、value,将数据写入DBrocksdb::WriteOptions options = rocksdb::WriteOptions();s = db->Put(options, handleMap[cf], key, value);if (s.ok()) {return SUCCESS;} else {return FAILURE;}return FAILURE;
}此外,还可以使用批量写入的能力来加快写入的速度:
int32_t RocksDBCache::writeBatch(const std::string &cfName, const std::string& file) { if(handleMap.find(cfName) == handleMap.end()) {// 列族不存在,写入失败return FAILURE;} rocksdb::WriteBatch batch;int32_t count = 0;ColumnFamilyHandle * handle = handleMap[cfName];while (std::getline(file, line)) { // 逐行读取数据流vector <string> infoVec = tars::TC_Common::sepstr<string>(line, ",");// 根据内容构造key与valuestd::string key = buildCacheKey(infoVec);std::string value = buildCacheValue(infoVec);batch.Put(handle, key, value);count++;// 每批次写入1000个kvif (count >= 1000) {db->Write(rocksdb::WriteOptions(), &batch);batch.Clear();count = 0;}}db->Write(rocksdb::WriteOptions(), &batch);return SUCCESS;
}3.2 业务场景二:RocksDB快照的使用
上述场景中,讲到了一些RocksDB的基础用法,也是一些比较常规的用法。而该场景妙用了快照能力来实现了服务器间数据的备份。
最初,用户数据加载到MT RocksDB 的方式为:通过 SQL 批量进行拉取。每批拉取数十万条数据,但随着数据量的不断增加,缓存加载速度变得越来越慢。例如,加载数亿级用户的数据信息需要 3-4 天。
每逢大型促销活动,如双十一、双十二、618 等,许多应用需要提高消息推送速度。此时 MT 服务便需要扩展副本,而每次扩展都需要耗费大量时间和人力成本。
为此,考虑使用复制的方式直接拷贝已有 MT 服务器中的 RocksDB 文件,并将其作为缓存的副本。以下是一个例子:
假如有一台新的MT服务器需要加入到集群中,这台新的MT服务器需要加载app1与app2的用户数据。如下图所示:

其中MT2机器中缓存有app1和app2,所以直接使用 rsync/scp 命令将 MT2 的 RocksDB 文件夹拷贝到新的MT机器中。
rsync 和 scp 都是 Linux/Unix 操作系统中常用的文件传输工具,但是它们在原理、功能和使用场景等方面有很大的不同。
(1)原理
scp 采用的是 SSH 协议进行加密并传输数据,数据传输过程中都经过了加密,保证了数据安全性。而 rsync 采用了类似于增量备份的方式,在本地和远端对比文件的变化,只传输发生变化的部分,从而实现文件数据的同步更新。
(2)功能
rsync 的功能比 scp 更加强大,rsync 不仅可以做到多台服务器文件之间的同步和迁移,还能保持整个文件系统的一致性,支持文件权限、硬连接等信息的同步。而 scp 只能将本地文件传输到远端服务器,或者将远端服务器的文件传输到本地,保持文件本身的特性不变,不能保证系统的一致性。
(3)使用场景
scp 适合小文件传输(少量数据或文件),例如配置文件、代码等文件传输,速度快,方便易用,支持跨平台操作。rsync 适合大量数据或文件的同步和传输,例如在数据中心的大量数据备份、同步和迁移等应用场景。
总的来说,scp 是传统的文件复制命令,使用简单,适合小文件传输,而 rsync 是专门针对同步和迁移等大量数据和大量文件的异步传输工具,优点是高效、安全、节省带宽和磁盘空间等特殊用途。因此,在实际应用中,应选择合适数量、合适的文件传输工具来满足不同的需求。
拷贝完成后,新的MT服务启动后便能直接提供服务。这个方案远比原有 SQL 方案要快不少,一般在1-2小时内便可以完成。
但是也存在一些问题,MT2服务器中还缓存有app3的数据,而app3并不是新MT服务器想要缓存的应用,这便导致了新MT服务器中RocksDB中存在一些无用数据,浪费了磁盘空间,也加深了sst文件的层级深度,拖慢了数据读取的速度。
因此,便考虑是否可以只拷贝 RocksDB 中的部分sst文件,而列族可以满足这个需求。
列族可以简单理解为将数据进行分组,业务上将一个应用的数据归类到一个列族中。这样做的好处在于,在导出RocksDB文件时,可以针对单个列族生成快照文件,然后将该快照文件导出到新机器上,便可以解决上述提到的问题。
原先 RocksDB 中设计该快照功能主要是用于同一台机器中的数据备份,但稍加改造便可以实现跨服务器备份。
这个快照文件是一个硬链接,链接到了真实的sst文件中。如下图所示,该文件夹内便是生成的快照文件,其与真实的sst别无二致:
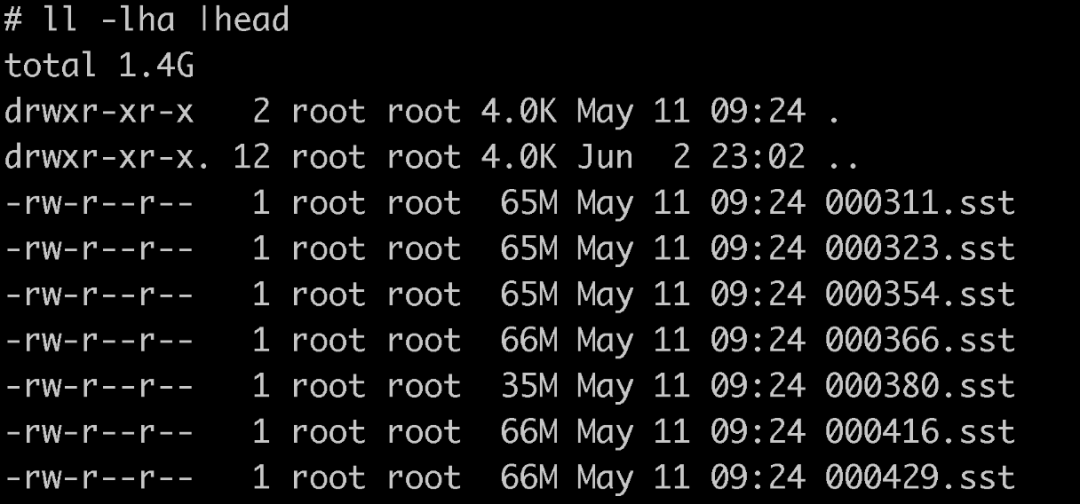
这个快照文件中,只包含了某个应用的数据。下文中,会阐述如何生成快照,并将这类快照文件导入到新机器的 RocksDB 文件夹中使用。
代码实现
(1)首先,是生成快照的接口,关键方法是 ExportColumnFamily ,此接口将会根据现有的app数据生成该列族的快照文件,示例代码如下:
void RocksDBCache::createCfSnapshot(const std::string &cfName){if(handleMap.find(cfName) == handleMap.end()) {// 列族不存在,写入失败return FAILURE;}// 上游初始化好的ColumnFamilyHandle指针ColumnFamilyHandle* app_cf_handle = handleMap[cfName]; // 应用列族对应的指针// 生成快照文件的目录地址std::string export_files_dir_ = "/rocksdb_app_snapshot";// 生成快照后会有一个meta元数据指针,该指针指向的对象中存储了快照文件的内容和信息ExportImportFilesMetaData* metadata_ptr_ = nullptr;// 初始化CheckPoint实例,所有的快照都需要经过CheckPoint来生成Checkpoint* checkpoint;Checkpoint::Create(db, &checkpoint);// 生成app的数据快照checkpoint->ExportColumnFamily(app_cf_handle, export_files_dir_, &metadata_ptr_);// 由于在新机器导入快照文件时需要meta元数据,但RocksDB中没有提供meta元数据的序列化方法// 所以自行补充了序列化方法。将meta元数据序列化后写入到json文本中,方便在不同的机器中传输std::string jsonMetaInfo;metaToJson(metaData, jsonMetaInfo); // 将meta转换成jsonofstream ofs;ofs.open(export_files_dir_ + "/meta.json", ios::out);if (ofs.is_open()) {// 将json 元数据写入到文本文件中ofs << jsonMetaInfo << endl;ofs.close(); }}序列化方法的具体实现:
// 传入元数据指针,json字符串通过jsonRes参数返回
void RocksDBCache::metaToJson(ExportImportFilesMetaData *meta, std::string &jsonRes) {Json::Value record;record[std::string("db_comparator_name")] = meta->db_comparator_name;Json::Value arrayFileInfos;for (size_t j = 0; j < meta->files.size(); j++) {Json::Value fileInfo;auto &file = meta->files[j];fileInfo[string("column_family_name")] = file.column_family_name;// ...将字段写入到file中arrayFileInfos.append(fileInfo);}record[string("files")] = arrayFileInfos;Json::StyledWriter sw;jsonRes = sw.write(record);return;
}// 传入json文件,解析出元数据并写入到meta对象中
void RocksDBCache::jsonToMeta(ifstream &payload, ExportImportFilesMetaData& meta) {Json::Value metaData;Json::Reader reader;try{bool parseResult = reader.parse(payload, metaData);if(!parseResult) {cout << "jsonToMeta parse error" << endl;return;}std::vector<LiveFileMetaData> files;meta.db_comparator_name = metaData[string("db_comparator_name")].asString();for(unsigned int i = 0; i < metaData[string("files")].size(); i ++) {const Json::Value& fileInfo = metaData[string("files")][i];LiveFileMetaData fileMetaData;fileMetaData.column_family_name = fileInfo["column_family_name"].asString();// ...字段赋值files.push_back(fileMetaData);}meta.files = files;} catch (const std::exception& e) {cout << "jsonToMeta parse error: " << e.what() << endl;}
}(2)生成好某个应用的快照文件后,便可通过 rsync/scp 传输文件。
(3)传输完成后,在新的MT服务器中,可以通过CreateColumnFamilyWithImport 方法来将快照文件引入到现有的RocksDB中,示例demo如下:
// path为拷贝过来的快照目录,cfName为准
int32_t RocksDBCache::importSnapshot(const std::string &cfName, const std::string &path){if(handleMap.find(cfName) != handleMap.end()) {// 列族存在,导入失败return FAILURE;} ColumnFamilyHandle* app_cf_handle; // 应用列族对应的指针// 元数据对象ExportImportFilesMetaData meta;// 通过拷贝过来的元数据json,生成元数据对象metastd::string metaJsonPath = path + "/meta.json";ifstream fin(metaJsonPath, ios::binary);if(!fin.is_open()) {return FAILURE;}ExportImportFilesMetaData meta;jsonToMeta(fin, meta);fin.close();// 将快照文件导入rocksdb中db->CreateColumnFamilyWithImport(ColumnFamilyOptions(), cfName,ImportColumnFamilyOptions(),meta, &app_cf_handle);
}RocksDB官方文档中的实例demo>> 点击查看
通过上述的方法,扩容一台新的MT服务器流程变为如下,以新MT加载app1和app2的缓存为例:
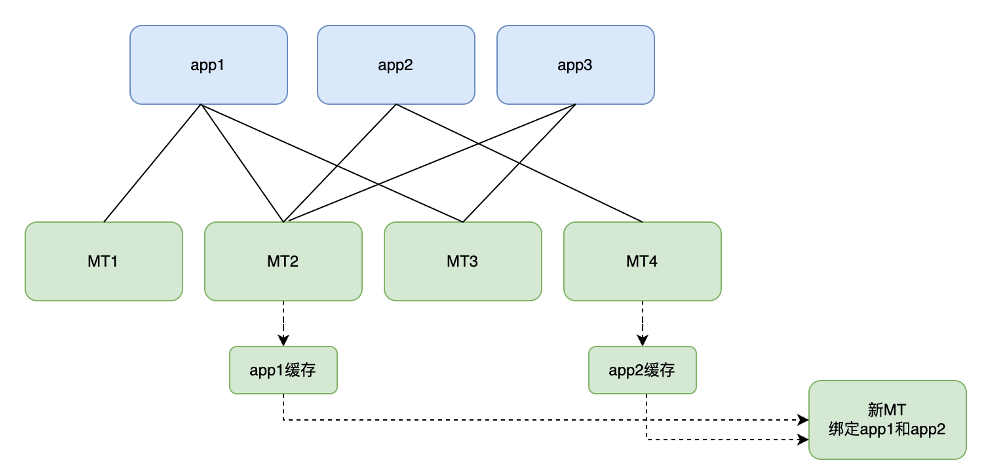
- 从MT2中导出app1的缓存快照、从MT4中导出app2的缓存快照。
-
分别从MT2和MT4中拷贝生成的快照文件到新的MT服务器中。
-
通过接口的方式,触发新的MT服务器加载app1和app2的快照到RocksDB中。
-
新的MT服务器扩容完成,对外提供服务。
四、总结
本文从介绍 RocksDB 的设计和特性入手,结合消息推送系统的业务场景,对 RocksDB 在分布式高可用存储方面的优势和应用进行了阐述,并探讨了如何使用 RocksDB 来优化消息推送系统的性能和效率。
作为一种高性能的嵌入式 KeyValue 存储引擎,RocksDB 具有多样的特性和优点,如支持内存表和文件存储引擎、支持多维度数据分区和多层次存储模型、支持高并发和快速写入等。在消息推送系统中,RocksDB 可以有效地存储分布式实时数据,并支持高吞吐量。同时,文章还介绍了一些消息推送场景下的 RocksDB 应用案例,如如何利用快照功能实现跨服务器备份、如何充分利用 RocksDB 的快速写入和高并发特性等。
本文的价值在于,通过对 RocksDB 的介绍和实际应用案例的分析,对读者产生一些启示性和实用性价值。读者可以从中了解 RocksDB 的基本特性和使用方法,如何应对高并发、高可用常见的分布式系统问题,同时,也可以了解到基于RocksDB的有状态服务中,快速扩容的可行方案。
同时,需要注意的是,RocksDB 作为一种嵌入式的存储引擎,在局限性和短板方面可能存在一些挑战,例如数据模型和数据结构的适用性等。针对这些问题,需要读者自行进行一些额外的适配,并调整 RocksDB 的配置参数等,来改善 RocksDB 的性能和适用性。
参考文献:
-
facebook- rocksdb-wiki
-
facebook- rocksdb