pytorch使用GPU进行训练
- 1. 数据 模型 损失函数调用cuda()
- 2. 使用谷歌免费GPU gogle colab 需要创建谷歌账号登录使用, 网络能访问谷歌
- 3. 执行
- 4. 代码
B站土堆学习视频: https://www.bilibili.com/video/BV1hE411t7RN/?p=30&spm_id_from=pageDriver&vd_source=9607a6d9d829b667f8f0ccaaaa142fcb
1. 数据 模型 损失函数调用cuda()
if torch.cuda.is_available():net = net.cuda()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()
if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()
2. 使用谷歌免费GPU gogle colab 需要创建谷歌账号登录使用, 网络能访问谷歌
土堆YYDS, colab省事省力好多

3. 执行
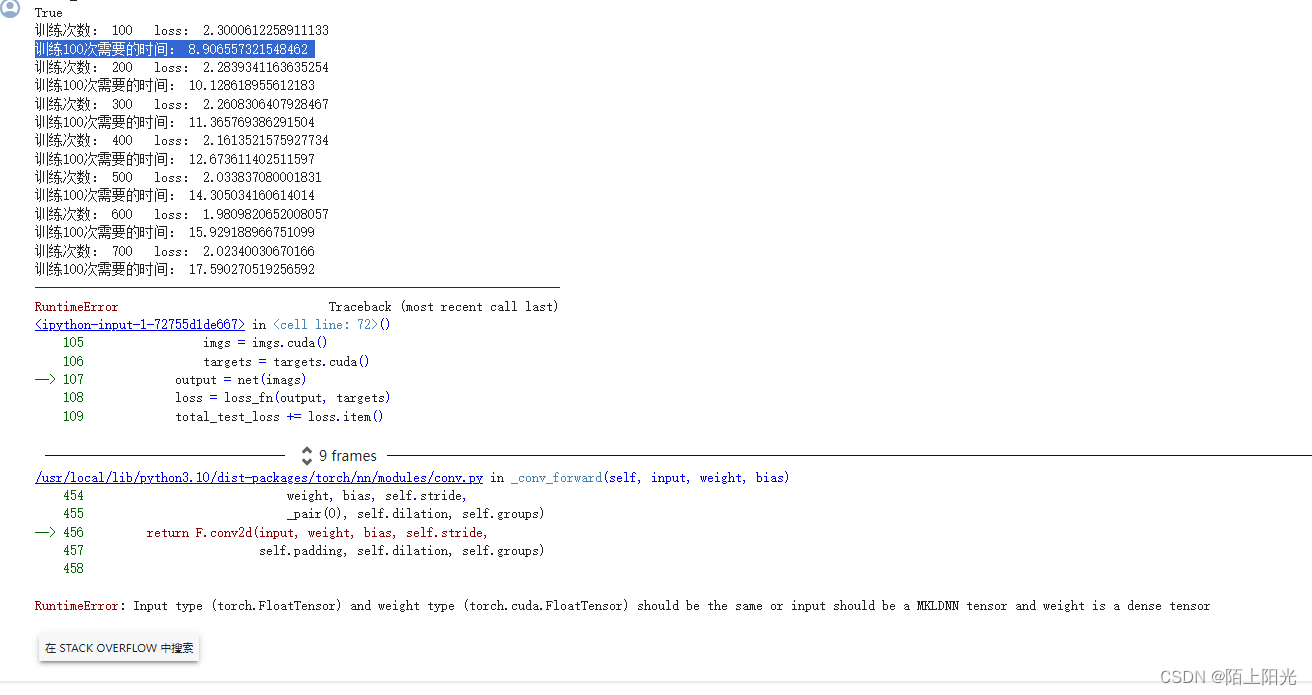
运行报错
https://stackoverflow.com/questions/59013109/runtimeerror-input-type-torch-floattensor-and-weight-type-torch-cuda-floatte
You get this error because your model is on the GPU, but your data is on the CPU. So, you need to send your input tensors to the GPU.
意思是数据在cpu但是模型在gpu导致报错
查看代码测试数据做模型预测的时候,有个变量名写错了,改正后正常运行。

4. 代码
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
# from p24_model import *# 1. 准备数据集
# 训练数据
from torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
# 测试数据
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)# 查看数据大小--size
print("训练数据集大小:", len(train_data))
print("测试数据集大小:", len(test_data))
# 利用DataLoader来加载数据集
train_loader = DataLoader(dataset=train_data, batch_size=64)
test_loader = DataLoader(dataset=test_data, batch_size=64)# 2. 导入模型结构 创建模型
class Cifar10Net(nn.Module):def __init__(self):super(Cifar10Net, self).__init__()self.net = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.net(x)return xnet = Cifar10Net()
if torch.cuda.is_available():net = net.cuda()# 3. 创建损失函数 分类问题--交叉熵
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()# 4. 创建优化器
# learing_rate = 0.01
# 1e-2 = 1 * 10^(-2) = 0.01
learing_rate = 1e-2
print(learing_rate)
optimizer = torch.optim.SGD(net.parameters(), lr=learing_rate)# 设置训练网络的一些参数
epoch = 10 # 记录训练的轮数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数# 利用tensorboard显示训练loss趋势
writer = SummaryWriter('./train_logs')start_time = time.time()
print('start_time: ', start_time)
print(torch.cuda.is_available())
for i in range(epoch):# 训练步骤开始net.train() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用for data in train_loader:imgs, targets = data # 获取数据if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()output = net(imgs) # 数据输入模型loss = loss_fn(output, targets) # 损失函数计算损失 看计算的输出和真实的标签误差是多少# 优化器开始优化模型 1.梯度清零 2.反向传播 3.参数优化optimizer.zero_grad() # 利用优化器把梯度清零 全部设置为0loss.backward() # 设置计算的损失值,调用损失的反向传播,计算每个参数结点的参数optimizer.step() # 调用优化器的step()方法 对其中的参数进行优化# 优化一次 认为训练了一次total_train_step += 1if total_train_step % 100 == 0:print('训练次数: {} loss: {}'.format(total_train_step, loss))end_time = time.time()print('训练100次需要的时间:', end_time-start_time)# 直接打印loss是tensor数据类型,打印loss.item()是打印的int或float真实数值, 真实数值方便做数据可视化【损失可视化】# print('训练次数: {} loss: {}'.format(total_train_step, loss.item()))writer.add_scalar('train-loss', loss.item(), global_step=total_train_step)# 利用现有模型做模型测试# 测试步骤开始total_test_loss = 0accuracy = 0net.eval() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用with torch.no_grad():for data in test_loader:imags, targets = dataif torch.cuda.is_available():imags = imags.cuda()targets = targets.cuda()output = net(imags)loss = loss_fn(output, targets)total_test_loss += loss.item()# 计算测试集的正确率preds = (output.argmax(1)==targets).sum()accuracy += preds# writer.add_scalar('test-loss', total_test_loss, global_step=i+1)writer.add_scalar('test-loss', total_test_loss, global_step=total_test_step)writer.add_scalar('test-accracy', accuracy/len(test_data), total_test_step)total_test_step += 1print("---------test loss: {}--------------".format(total_test_loss))print("---------test accuracy: {}--------------".format(accuracy/len(test_data)))# 保存每一个epoch训练得到的模型torch.save(net, './net_epoch{}.pth'.format(i))writer.close()