文章目录
- 一、前言
- 二、主要内容
- 三、总结
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
Jason Wei 的主页:https://www.jasonwei.net/
Jason Wei,一位于 2020 年从达特茅斯学院毕业的杰出青年,随后加盟了 Google Brain 团队。在那里他作为研究科学家,为大语言模型的发展贡献了若干关键性的理念。这些理念包括:思维链提示(Chain-of-Thought Prompting)、指令调整(Instruction Tuning)以及涌现现象(Emergent Phenomena)。目前,Jason Wei 在 OpenAI 担任人工智能研究员,继续在人工智能领域进行着前沿的探索和研究。
近期,他作为斯坦福大学 CS 330 深度多任务学习与元学习课程的客座讲师,就大语言模型进行了一次讲座,分享了他对该领域的直观见解。尽管斯坦福大学尚未发布该讲座的视频,但演讲内容已由他本人在个人博客上做了主要总结。
博客链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
二、主要内容
在当前的人工智能研究领域,一个悬而未决的问题引起了学术界和工业界的广泛关注:为何大语言模型能够展现出如此卓越的性能?
对此,Jason Wei 分享了六项基于直觉的见解。其中很多都是从手动检查数据以及做实验中得到的启发,我认为这种做法很有帮助,值得推荐。尽管语言模型的预训练目标似乎仅仅局限于预测文本中下一个单词,但它们实际上学习到了远超预期的知识,这一现象令人倍感惊奇。那么,这些模型究竟从简单的下一个单词预测任务中学到了哪些知识呢? 以下是一些具体的例证。
直觉 1:在大规模的自监督数据上进行下一个单词预测是大规模多任务学习
尽管下一个单词的预测是一项非常简单的任务,但当与大规模数据集结合时,它迫使模型学习许多任务。考虑一下传统自然语言处理任务的例子,这些任务可以通过在语料库中预测下一个单词来学习。

以上任务很明确,但有点理想化。实际上,预测下一个单词涉及进行许多 “奇怪” 的任务。考虑以下句子:

从这样的角度审视数据,显而易见,下一个单词预测任务不仅激励模型掌握语言的句法和语义,还促进了对标点符号使用、事实内容甚至推理过程的学习。这些实例有效支持了以下论断:即便是简单的目标,结合大规模(复杂)数据也能催生出高度智能化的行为表现。(假设您认同语言模型是智能的)
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,这也被称为上下文学习
在过去数十年里,机器学习领域的研究重心一直聚焦于学习输入与输出之间的映射关系。鉴于下一个单词预测的普遍适用性,我们可以将其视作机器学习的一个典型代表。这种方法被称为上下文学习,亦即少样本学习或少样本提示工程。在这一领域中,GPT-3 的研究成果标志性地提出了在自然语言指令后附加输入与输出对的概念。如图所示,在左侧图示中可以看到这一方法的具体应用实例。

在右侧的图表中,我们可以观察到通过增加上下文中的示例数量,能够显著提高 GPT-3 在论文中所述任务的性能。研究成果表明,向模型提供一系列的 <输入,输出> 示例对于其性能的提升是有益的。
上下文学习作为利用大语言模型的一种典型方法,其便捷性在于 <输入,输出> 对与过去数十年来人们实施机器学习的方式高度吻合。然而,我们为何应当坚持使用 <输入,输出> 对作为训练模型的主要手段呢?目前我们仍缺乏基于第一性原理的解释。在人类交流中,我们不仅向对方提供指令和解释,还会通过互动的方式进行教学。这提示我们,在设计人工智能学习和调整策略时,或许应当考虑更加符合人类自然交流习惯的方法。
直觉 3:token 可能有非常不同的信息密度,所以请给模型思考的时间
在信息理论的视角下,不同的词元(token)所携带的信息量是有显著差异的。
- 例如,某些词元在语境中的出现是高度可预测的,因此它们贡献的信息量相对较低。以句子 “I am Jason Wei, a researcher at OpenAI working on large language …” 为例,大多数情况下,“models” 将是一个合理且可预期的续词。这种情况下,即便省略该词元,句子的信息损失也是微乎其微。
- 相反,其他词元可能含有丰富的信息量,并且难以预测。例如,在 “My favorite color is …” 这一句式中,几乎无法准确预测接下来的词元,因为它可能是任何颜色,每个选项都携带了大量未知的新信息。
- 此外,有些词元的预测难度不仅仅是因为信息量大,还因为它们涉及复杂的计算过程。例如,在处理 “Question: What is the square of ((8-2)*3+4)^3/8? [A] 1,483,492; [B] 1,395,394; [C] 1,771,561;\nAnswer: (” 这类句子时,正确预测下一个词元需要进行数学运算,这无疑增加了预测任务的复杂性。
可以设想,若您扮演的角色是 ChatGPT,在接收到提示(Prompt)的瞬间便需立即开始键入回复,这无疑会增加正确回答问题的难度。为了解决这一问题,我们可以通过赋予大语言模型更多的计算能力(给大语言模型一些时间思考),让大语言模型在给出最终答案之前进行自然语言推理,进而输出更为准确且符合上下文的最终答案。这可以通过一个简单技巧来实现,即思维链提示工程,其可以通过提供少样本「思维链」示例来鼓励模型执行推理,如下图蓝色高亮部分。

这项技术可用于增强大语言模型在处理那些即便对人类而言也需花费一定时间进行复杂推理的任务的性能。对于超越基础算术问题的更为复杂的挑战,该技术能够辅助大语言模型先将问题分解为若干子问题,并依照提示工程的复杂度,从最简到最繁复,逐一解答。这一范式极具潜力,因为我们期待人工智能最终能够应对人类所遭遇的一些最为棘手的难题,如生命科学、医学、气候变化等。在解决这些问题的过程中,推理能力是不可或缺的核心要素。
下一个单词预测有效的关键原因是 Scaling,意味着在更多数据上训练更大的深度神经网络。显然,训练先进的大规模语言模型需要大量资金。而我们之所以还这么做,是因为我们有信心使用更大的深度神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。
直觉 4:预计增大语言模型规模(模型大小和数据)会继续改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,即扩展律。如下图所示,随着计算量增长,测试损失也会平稳地下降。
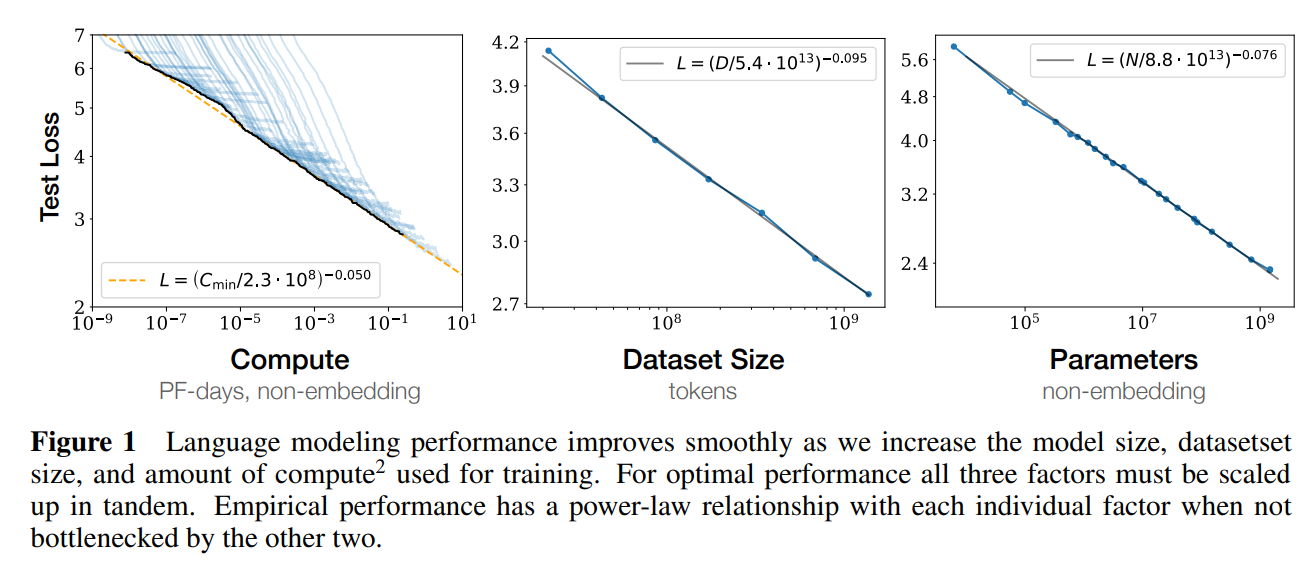

有进一步的研究结果表明:通过监测较小规模模型的损失曲线,我们能够以远低于万分之一的计算成本预测出 GPT-4 的损失趋势。尽管扩展模型规模的益处尚未完全明了,但以下两点假设仍待验证。
- 一是小规模语言模型的参数无法记忆那么多的知识,而大语言模型可以记忆大量有关世界的事实信息。
- 第二个猜测是小规模语言模型能力有限,可能只能学习数据中的一阶相关性。而大语言模型则可以学习数据中的高阶(复杂)启发式知识。
直觉 5:尽管总体损失会平稳地扩展,但个别的下游任务的扩展情况则可能发生突变
让我们更仔细地看看当损失改善时到底发生了什么。您可以将整体损失视为所学任务的加权平均值,例如:

现在考虑你的损失从 4 变成 3。所有任务都会均匀地变得更好吗?可能不会。也许损失为 4 的模型的语法已经完美了,所以已经饱和了,但是损失为 3 的模型数学能力可能会有较大提升。
已有研究表明,在评估模型在 200 个下游任务上的表现时,可以观察到一个多样化的效果模式:某些任务的性能稳步提升,而其他任务则没有明显改进,还有某些任务的性能会出现跳跃式增长。
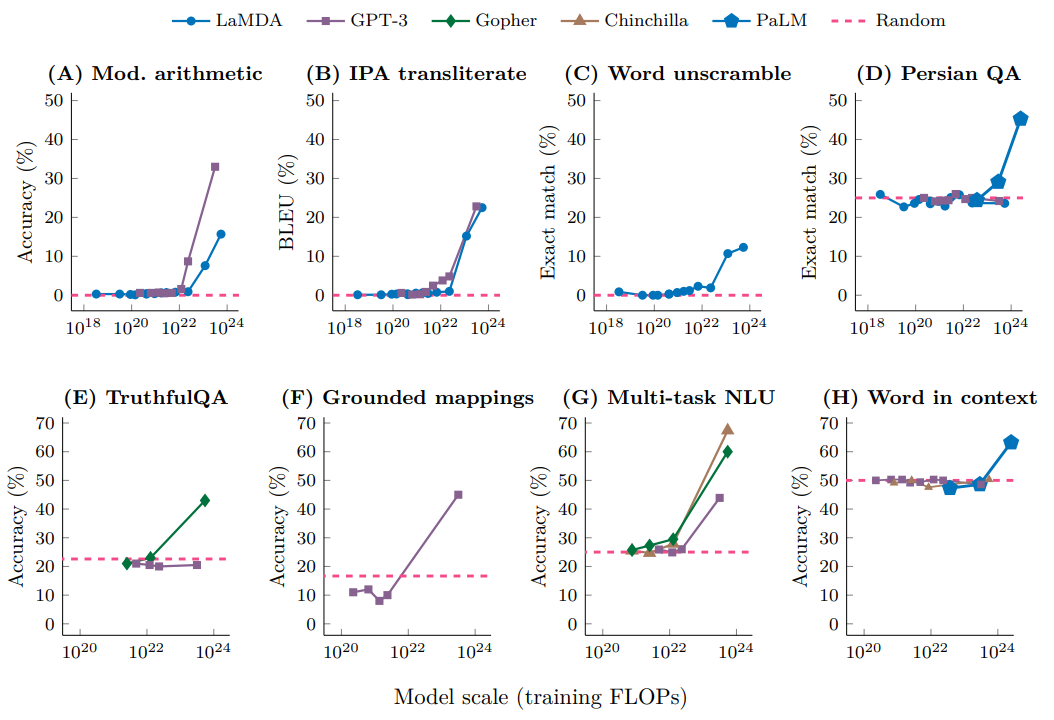
图示中展示了 8 个代表性任务的例证,在这些例证中,当模型规模较小时,其性能表现接近随机水平;但是,一旦模型规模超过特定的临界点,其性能便会显著地超越随机水平。这种由规模增长引发的质的飞跃被称作 “涌现” 现象。更精确地说,当一个能力在较小规模的模型中未曾显现,而在扩大规模后却突然出现时,我们将这种能力描述为 “涌现” 的能力。在此类任务中,我们通常观察到小规模模型所展现的能力近乎随机,但是一旦模型达到某一阈值以上的规模,则其性能会明显地跃升至超越随机水平,正如图中所示。
涌现现象在 AI 研究中具有三个关键的内涵:
- 涌现现象的预测不宜简单依赖于对较小模型能力扩展曲线的外推。这意味着涌现特性并非通过线性或者可预见的方式随模型规模增加而增强。
- 涌现能力并非由语言模型的训练者直接设定,它超出了明确的编程和指令范畴,体现了模型在学习过程中自发形成的复杂行为。
- 规模的扩展被视为解锁新的涌现能力的关键,因此有理由期待,随着模型规模的进一步增大,将可能触发更多未知的、高级的能力涌现。
直觉 6:真正的上下文学习只会发生在足够大的语言模型中
GPT-3 的研究成果揭示了一个有趣的现象:通过扩充上下文中的示例数量,模型的性能会得到增强。我们本能地期望这种性能提升源自模型对于 <输入,输出> 映射关系的学习。然而,这种提升也可能由其他因素导致,例如,这些示例可能向模型传达了特定的格式规范或潜在的标签信息。
更具启发性的是,《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》一文对此进行了深入探讨。研究发现即便是在使用随机标签的上下文示例中,GPT-3 的表现几乎未受影响。这一结果暗示着性能提升并不单纯是因为模型掌握了 <输入,输出> 之间的映射规律,而是上下文中包含的格式和潜在标签信息对模型有着决定性的指导作用。
然而,在对比目前业界最先进的模型时,GPT-3 并不能被视为一个 “超级” 大语言模型。通过实验设置中采用更为极端的标签翻转策略(即将正面标签解释为负面,负面标签解释为正面),我们观察到大语言模型在遵循这种翻转标签的规则上表现出了更高的敏感性,而较小的模型则对此不受影响。正如下图所示,包括 PaLM-540B、code-davinci-002 和 text-davinci-002 在内的大语言模型在处理能力上显示出了明显的下降。

这一现象揭示了一个重要的发现:大语言模型确实能够处理 <输入,输出> 的映射关系,但这种能力的发挥依赖于模型的规模必须达到一定的庞大程度。
三、总结
Jason Wei 分享了六项基于直觉的见解。其中很多都是从手动检查数据和做实验中得到的启发,我认为这种做法很有帮助,值得推荐。
- 直觉 1:在大规模的自监督数据上进行下一个单词预测是大规模多任务学习
- 直觉 2:学习输入 - 输出关系的任务可以被视为下一个单词预测任务,这也被称为上下文学习
- 直觉 3:token 可能有非常不同的信息密度,所以请给模型思考的时间
- 直觉 4:预计增大语言模型规模(模型大小和数据)会继续改善损失
- 直觉 5:尽管总体损失会平稳地扩展,但个别的下游任务的扩展情况则可能发生突变
- 直觉 6:真正的上下文学习只会发生在足够大的语言模型中
📚️ 参考链接:
- Jason Wei - Some intuitions about large language models
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., … & Fedus, W. (2022). Emergent Abilities of Large Language Models. Transactions on Machine Learning Research.
- Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048–11064, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Wei, J., Wei, J., Tay, Y., Tran, D., Webson, A., Lu, Y., … & Ma, T. (2023). Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
- LLMs 扩展率和计算最优模型 Scaling laws and compute-optimal models
- GPT-4 大模型硬核解读,看完成半个专家
- 解析大模型中的 Scaling Law
- 【自然语言处理】【ChatGPT 系列】大模型的涌现能力
- 沈向洋:致 AI 时代的我们 —— 请不要忽视写作的魅力