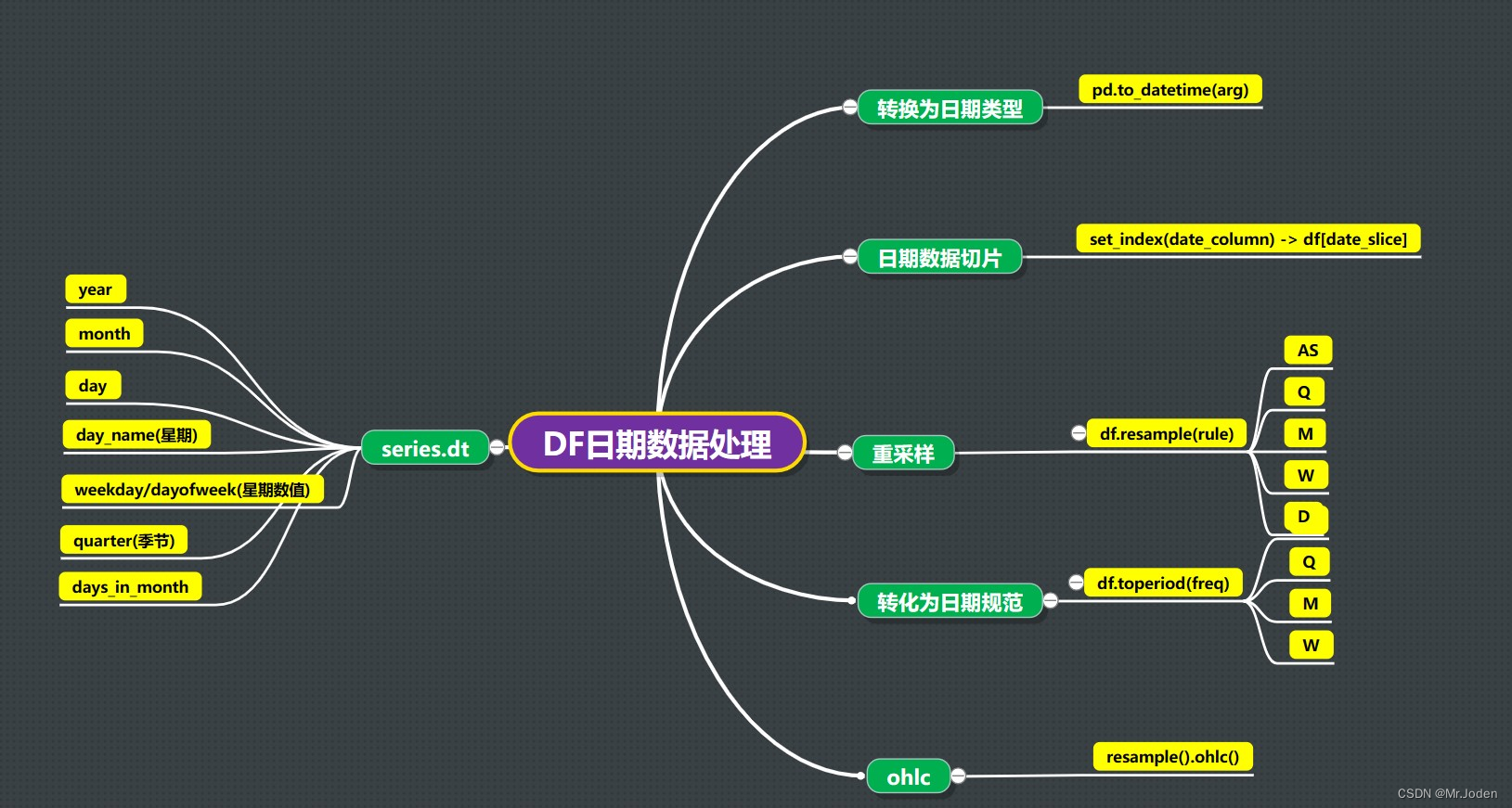
本章主要介绍文件系统的管理
- 了解什么是文件系统
- 对分区进行格式化的操作
- 挂载分区
- 查找文件
在Windows系统中,买了一块新的硬盘加到电脑后,需要对分区进行格式化才能使用,Linux系统中也是一样,首先我们需要了解什么是文件系统
1.1 了解文件系统
分区很复杂,但是为了好理解不妨先简化介绍。首先来看图,记住这是一个分区
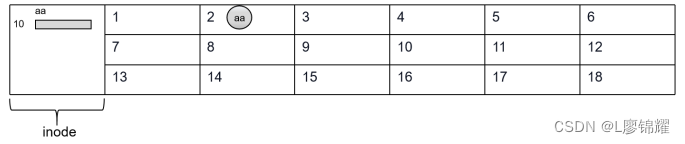
当对一个分区格式化时,分区被分成两部分
(1)右侧部分被划分成很多小格子,每个小格子称为block,默认大小为4KB
(2)左侧部分为inode,用于记录文件的属性,每个文件都会占用一个 inode
每个block中只能存储一个文件,假设一个文件aa只有 1KB存放在2号block中,则2号block还剩余3KB的空间,但 是这3KB的空间也不会存储其他数据了。所以,此文件大 小为1KB,占用空间为4KB
如果一个文件的值大于4KB,一个block存放不下,则会占用多个 block。例如,某文件 大小为9KB,则需要占用3个block
Windows 中常见的文件系统包括FAT、NTFS等,Linux中常见的 文件系统包括EXT3、EXT4、XFS等。这些不同的文件系统具有不同的功能,包括所支持的单 个文件最大能有多大,整个文件系统最大能有多大,RHEL8/CentOS8中默认的文件系统是 XFS
1.2 了解硬链接
前面讲了inode记录的是某文件的属性信息
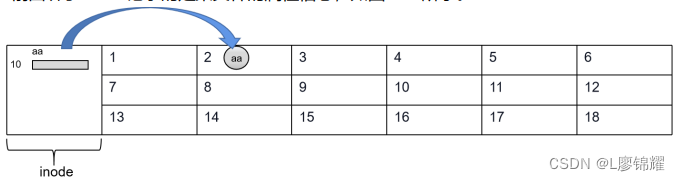
10号 inode记录了aa文件的属性,包括aa文件的名称、大小、权限等,及其所在的 block,可以在10号inode中给aa文件再起一个名称bb

此时对10号inode来说,用两个名称aa和 bb来记录2号block中的文件,所以 aa和 bb对 应的是同一个文件,那么aa和 bb就是硬链接关系
练习:先拷贝一个测试文件
[root@node1 ~]# cp /etc/hosts aa查看aa的属性
[root@node1 ~]# ll aa
-rw-r--r-- 1 root root 158 12月 5 10:07 aa
[root@node1 ~]#此处的加粗字1,指的是aa文件只有一个硬链接,即存储在 block中的文件只有一个名称 aa。下面对aa做硬链接
[root@node1 ~]# ln aa bb查看aa和bb的属性
[root@node1 ~]# ll aa bb
-rw-r--r-- 2 root root 158 12月 5 10:07 aa
-rw-r--r-- 2 root root 158 12月 5 10:07 bb
[root@node1 ~]#硬链接数显示为2,说明存储在 block中的那个文件有两个名称aa和 bb。aa和 bb是在同 一个inode上记录的两个名称,通过ls -i可以查看aa和 bb分别是在哪个inode上记录的
[root@node1 ~]# ls -i aa ; ls -i bb
33574987 aa
33574987 bb
[root@node1 ~]#可以看到, inode值是--样的。即在同-个inode上用两个名称来记录 block中的那个文 件。换言之就是aa和bb对应的是同一个文件,修改aa之后会发现.bb的内容也做了相同的修 改,修改协之后会发现aa也做了相应的修改
因为block中的文件现在有两个名称,所以删除任意一个之后,block中的数据是不会跟 着删除的。所以,删除aa是不会影响bb的,或者删除bb也不会影响aa。但是aa和bb两个同 时删除,则block中的文件就没有名称了,则此文件会从 block中删除
block中的文件只要还有一个名称,那么数据就不会删除。如果所有名称都没有了,则此 数据会从 block中删除
同一个分区的inode只能记录同一个分区 block中的数据,不能在第二个分区中产生一个 inode来记录第一个分区中的文件,所以硬链接不能跨分区
1.3 创建文件系统
再看看前面已经在/dev/sdb 上创建过的分区
[root@node1 ~]# fdisk -l /dev/sdb磁盘 /dev/sdb:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x01aa58a7设备 Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 8390655 2097152 82 Linux swap / Solaris
/dev/sdb4 8390656 41943039 16776192 5 Extended
/dev/sdb5 8392704 12587007 2097152 8e Linux LVM
/dev/sdb6 12589056 16783359 2097152 83 Linux
/dev/sdb7 16785408 20979711 2097152 83 Linux
[root@node1 ~]#下面对分区进行格式化
1. mkfs ‐f 文件系统 ‐选项 /dev/分区
2. 或
3. mkfs.文件系统 ‐选项 /dev/分区练习:把/dev/sdb1格式化为XFS文件系统
[root@node1 ~]# mkfs.xfs /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=131072 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=524288, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node1 ~]#从上面的 bsize=4096可以看到,block的大小默认设置为了4KB,如果指定为1KB,需要 加上-b size=1024选项
[root@node1 ~]# mkfs.xfs -b size=1024 /dev/sdb1
mkfs.xfs: /dev/sdb1 appears to contain an existing filesystem (xfs).
mkfs.xfs: Use the -f option to force overwrite.
[root@node1 ~]#再次格式化时,因为/dev/sdbl已经存在文件系统了,所以再次格式化失败,需要加上-f 选项表示强制格式化

block size的大小只能在格式化时指定,不可以后期修改
每个文件系统都会有唯一的一个UUID来记录,查看系统中所有的UUID
[root@node1 ~]# blkid
/dev/sda1: UUID="905690d2-02f6-4c70-b8d4-a1336f91b917" TYPE="xfs"
/dev/sda2: UUID="s1C6RX-Myb6-Wij5-U7pQ-SANf-fsjk-ISLXkt" TYPE="LVM2_member"
/dev/sdb1: UUID="0df996ac-5a19-4573-ae7f-b2747a376a1a" TYPE="xfs"
/dev/sdb2: UUID="1d8bfb35-d673-4ea0-97d9-6612a2304f15" TYPE="swap"
/dev/sr0: UUID="2018-11-26-14-22-58-00" LABEL="CentOS 7 x86_64" TYPE="iso9660" PTTYPE="dos"
/dev/mapper/centos-root: UUID="50688382-ff3a-4797-a679-685737f462a7" TYPE="xfs"
/dev/mapper/centos-swap: UUID="bf9bb061-39f5-4328-ad7a-3993ea9e1eef" TYPE="swap"
[root@node1 ~]#如果想单独查看某个XFS格式的文件系统的UUID,可以通过“xfs admin -u分区名”来 查看
[root@node1 ~]# xfs_admin -u /dev/sdb1
UUID = 0df996ac-5a19-4573-ae7f-b2747a376a1a
[root@node1 ~]#可以看到,/dev/sdb1文件系统的UUID是0df996ac-5a19-4573-ae7f-b2747a376a1a,这个UUID也是可以切换成其他值的
通过uuidgen命令手动生成一个新的UUID
[root@node1 ~]# uuidgen
c841332d-3705-4c20-a829-4da1b1441996
[root@node1 ~]#把/dev/sdb1的UUID切换成新生成的UUID
[root@node1 ~]# xfs_admin -U c841332d-3705-4c20-a829-4da1b1441996 /dev/sdb1
Clearing log and setting UUID
writing all SBs
new UUID = c841332d-3705-4c20-a829-4da1b1441996
[root@node1 ~]#再次查看/dev/sdb1的UUID
[root@node1 ~]# xfs_admin -u /dev/sdb1
UUID = c841332d-3705-4c20-a829-4da1b1441996
[root@node1 ~]#可以看到,现在已经是新的UUID 了
1.4 挂载文件系统
分区格式化好了之后是不可以直接访问的,要想访问此分区,必须把它挂载到某个目录上才行,如同在 Windows中创建一个分区,必须给它一个盘符或装在某个NTFS文件夹中
要查看哪些分区已经挂载及分区的使用情况,可以使用df命令
[root@node1 ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/mapper/centos-root 18860032 4874848 13985184 26% /
devtmpfs 480884 0 480884 0% /dev
tmpfs 497944 0 497944 0% /dev/shm
tmpfs 497944 8536 489408 2% /run
tmpfs 497944 0 497944 0% /sys/fs/cgroup
/dev/sda1 1038336 169476 868860 17% /boot
tmpfs 99592 12 99580 1% /run/user/42
tmpfs 99592 0 99592 0% /run/user/0
[root@node1 ~]#这里文件系统为tmpfs的是临时文件系统,可以忽略不管,上面结果中的分区大小都是以 K为单位,看起来不方便,可以加上-hT选项,-h会以合适的单位显示,-T会显示文件系统
[root@node1 ~]# df -Th | grep -v tmpfs
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 18G 4.7G 14G 26% /
/dev/sda1 xfs 1014M 166M 849M 17% /boot
[root@node1 ~]#挂载语法的命令如下
mount ‐o optl,opt2,... /dev/设备/目录首先创建一个目录/xx,并拷贝进去几个测试文件
[root@node1 ~]# mkdir /xx
[root@node1 ~]# cp /etc/hosts /etc/services /xx/
[root@node1 ~]# ls /xx
hosts services
[root@node1 ~]#下面把/dev/sdb1挂载到/xx 上,注意/xx中内容的变化
[root@node1 ~]# mount /dev/sdb1 /xx
[root@node1 ~]#以后访问/xx就是访问/dev/sdb1中的内容了,现在查看/xx中的内容
[root@node1 ~]# ls /xx
[root@node1 ~]#此时发现/xx中的内容看不到了,原因是如果某个目录挂载了一个分区,则这个目录中原 有的内容就会被隐藏。为了更好地理解可以看图
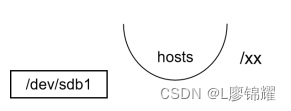
此时是没有挂载的情况,/xx中有自己的文件,然后把/dev/sdb1挂载到/xx 上,如图
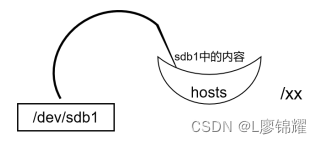
例如,有一个碗把/xx中原有的内容盖住了,现在看到的是上层碗中的内容
即/dev/sdbl中的内容。只有卸载掉才能再次看到,卸载的命令是umount
1. /umount /挂载点
2. 或
3. umount /dev/设备现在把/dev/sdb1卸载掉,然后查看/xx中的内容
[root@node1 ~]# umount /dev/sdb1
[root@node1 ~]# ls /xx
hosts services
[root@node1 ~]#卸载后又能看到/xx中的内容了,就相当于又把盖在/xx上面的那个“碗”拿掉了,所以能 看到/xx中的内容了
这里需要注意两个问题,第一个问题是假设在/xx没有挂载之前,往里面写了一个200GB 的文件file,然后又把/dev/sdb1挂载到/xx上,这时的file会被隐藏。有一天发现少了200GB 的空间,然后到每个目录中找/xx,怎么都找不到这200GB。此时要想到哪些目录是挂载 点,这些目录在挂载分区之前,里面是不是存在文件
第二个问题是有时卸载时可能无法正常卸载,类似于在 Windows中卸载U盘时,提示进 程正在占用。先模拟一下这个文件,再次把/dev/sdb1挂载到/xx上
[root@node1 ~]# mount /dev/sdb1 /xx
[root@node1 ~]#打开第二个终端执行如下命令
[root@node1 ~]# cd /xx
[root@node1 xx]#这样cd /xx之后,bash进程会一直占用/xx
再回到第一个终端,卸载/xx
[root@node1 ~]# umount /xx
umount: /xx:目标忙。(有些情况下通过 lsof(8) 或 fuser(1) 可以找到有关使用该设备的进程的有用信息)
[root@node1 ~]# umount /dev/sdb1
umount: /xx:目标忙。(有些情况下通过 lsof(8) 或 fuser(1) 可以找到有关使用该设备的进程的有用信息)
[root@node1 ~]#发现根本卸载不了,说明/xx现在正在被某个进程占用。那如何查看是哪个进程占用的呢? 可以使用fuser命令
[root@node1 ~]# fuser -mv /xx用户 进程号 权限 命令
/xx: root kernel mount /xxroot 9379 ..c.. bashroot 9425 f.... sftp-server
[root@node1 ~]#可以看到,有一个进程号为2322的进程正在占用,就是第二个终端中运行的cd命令
利用kill命令杀死进程号为2322的进程,然后再次卸载
[root@node1 ~]# kill -9 9379
[root@node1 ~]# umount /xx
[root@node1 ~]#此时可以正常卸载了。这里kill -9 2322的意思是强制杀死进程号为2322的进程,-9表示 强制的意思
挂载时还可以指定一些选项,先看一下默认的选项
[root@node1 ~]# mount /dev/sdb1 /xx
[root@node1 ~]# mount | grep /xx
/dev/sdb1 on /xx type xfs (rw,relatime,attr2,inode64,noquota)
[root@node1 ~]#通过执行mount命今可以看到所有已经挂裁了的设冬,地可以看到/dev/edh1的默认挂载 选项。其中rw的意思是可读可写,测试往/xx中写入内容
[root@node1 ~]# ls /xx
[root@node1 ~]# cp /etc/services /xx
[root@node1 ~]# ls /xx
services
[root@node1 ~]#现在是可以正常写进去的,然后卸载并重新以ro的方式挂载
[root@node1 ~]# umount /xx
[root@node1 ~]# mount -o ro /dev/sdb1 /xx
[root@node1 ~]#查看挂载选项

现在是以ro的方式挂载的,测试往/xx中写入内容
[root@node1 ~]# cp /etc/issue /xx
cp: 无法创建普通文件"/xx/issue": 只读文件系统
[root@node1 ~]#此时就写不进去了
如果想换选项也不用每次都卸载然后再挂载
mount ‐o remount,新选项/挂载点现在把/dev/sdb1 以 rw的方式挂载
[root@node1 ~]# mount -o remount,rw /xx
[root@node1 ~]# mount | grep /xx
/dev/sdb1 on /xx type xfs (rw,relatime,attr2,inode64,noquota)
[root@node1 ~]#然后再次拷贝测试文件进去
[root@node1 ~]# cp /etc/issue /xx
[root@node1 ~]# ls /xx
issue services
[root@node1 ~]# 可以看到,已经可以正常拷贝过去了
1.5 设置永久挂载
前面使用mount挂载设备也只是临时生效,重启系统之后此设备不会自动挂载。如果希 望重启之后能自动挂载,需要写入/etc/fstab中
1. 设备 挂载点 文件系统 挂载选项 dump值 fsck值
2. 或
3. 设备UUID 挂载点 文件系统 挂载选项 dump值 fsck值最后两列的意义如下
(1)dump值:意思是能否被dump备份命令作用,dump是一个用来作为备份的命令,通 常这个参数的值为0或1
(2)fsck值:是否检验扇区,开机的过程中,系统默认会以fsck检验系统是否完整(clean)。 这两列值建议写0,不要写其他值
现在希望/dev/sdb1在重启之后能自动挂载到/xx 上,/etc/fstab的写法如下
[root@node1 ~]# grep /xx /etc/fstab
/dev/sdb1 /xx xfs defaults 0 0
[root@node1 ~]#这样开机就会自动挂载
1.6 find的用法
find是一款功能强大的工具,可以基于文件名、创建及修改时间、所有者、大小、权限等 进行查询
find 目录 ‐属性 值(1)目录:指的是限定在哪个目录下查询,如果不指定则是在当前目录下查询
(2)属性:指的是基于什么查询,可以根据name、size、user、perm 等进行查询
(3)值:依赖于前面的属性,例如,-name lduanxx,这里根据名称进行查询,查询名称 为1duanxx的文件
也可以表示否定的意思,在属性前面加上叹号“!”
find 目录 ! ‐属性 值这里的意思是查找属性不是这个值的文件
例如,!-name lduanxx,这里根据名称进行查询,查询名称不是 lduanxx的文件
下面的演示都在新创建的目录11下进行查询
[root@node1 ~]# mkdir 11 ; cd 11
[root@node1 11]#在此目录下创建几个测试文件
[root@node1 11]# dd if=/dev/zero of=file1 bs=1M count=1
记录了1+0 的读入
记录了1+0 的写出
1048576字节(1.0 MB)已复制,0.0012748 秒,823 MB/秒
[root@node1 11]# dd if=/dev/zero of=file2 bs=1M count=2
记录了2+0 的读入
记录了2+0 的写出
2097152字节(2.1 MB)已复制,0.00260521 秒,805 MB/秒
[root@node1 11]# dd if=/dev/zero of=file3 bs=1M count=3
记录了3+0 的读入
记录了3+0 的写出
3145728字节(3.1 MB)已复制,0.00440493 秒,714 MB/秒
[root@node1 11]# dd if=/dev/zero of=file4 bs=1M count=4
记录了4+0 的读入
记录了4+0 的写出
4194304字节(4.2 MB)已复制,0.0112357 秒,373 MB/秒
[root@node1 11]# dd if=/dev/zero of=file5 bs=1M count=5
记录了5+0 的读入
记录了5+0 的写出
5242880字节(5.2 MB)已复制,0.0312296 秒,168 MB/秒
[root@node1 11]#这里file1到file5的大小如下
[root@node1 11]# du -sh file*
1.0M file1
2.0M file2
3.0M file3
4.0M file4
5.0M file5
[root@node1 11]#为了测试方便,按下面的命令修改文件的权限
[root@node1 11]# chgrp 888 file2 ; chown 888.888 file3
[root@node1 11]# chmod 326 file1 ; chmod 226 file2 ; chmod 327 file3
[root@node1 11]# chmod 441 file4
[root@node1 11]# chown 888 file1下面查看所有文件
[root@node1 11]# ls -lh
总用量 15M
-rw-r--r-- 1 root root 0 12月 5 11:27 blab001
-rw-r--r-- 1 root root 0 12月 5 11:27 Blab001
--wx-w-rw- 1 888 root 1.0M 12月 5 11:28 file1
--w--w-rw- 1 root 888 2.0M 12月 5 11:28 file2
--wx-w-rwx 1 888 888 3.0M 12月 5 11:28 file3
-r--r----x 1 root root 4.0M 12月 5 11:28 file4
-rw-r--r-- 1 root root 5.0M 12月 5 11:28 file5
[root@node1 11]#1.6.1 基于名称的查询
根据名称进行查询
[root@node1 11]# find -name blab001
./blab001
[root@node1 11]#这里只显示了blab001,并没有显示Blab001,因为 Linux中是严格区分大小写的。如果 要忽略大小写,可以使用-iname选项
[root@node1 11]# find -iname blab001
./Blab001
./blab001
[root@node1 11]#这样不管是大写还是小写都能够查询出来
在使用find命令时,还是可以使用通配符的,记得要用双引号引起来
[root@node1 11]# find -name "file*"
./file1
./file2
./file3
./file4
./file5
[root@node1 11]#这里查询的是文件名以file开头的那些文件
1.6.2 基于文件大小的查询
根据文件的大小进行查询,用-size选项。查询文件大小等于2M的文件
[root@node1 11]# find -size 2M
./file2
[root@node1 11]#查询文件大小大于3M的文件
[root@node1 11]# find -size +3M
./file4
./file5
[root@node1 11]#如果大小前面加上加号“+”,表示大于:如果大小前面加上减号“-”,表示小于
1.6.3 基于文件时间的查询
根据文件的时间进行查询,用-mtime选项,单位是天,这里天的表示如下
(1)24小时以内,即一天以内,用-1表示
(2)24~48小时,算1天,用1表示
(3)超过48小时,算超过1天,用+1表示
查询创建时间为1天的文件
[root@node1 11]# find -mtime 1
[root@node1 11]#查询创建时间超过1天的文件
[root@node1 11]# find -mtime +1
[root@node1 11]#查询创建时间低于1天的文件
[root@node1 11]# find -mtime -1
.
./Blab001
./blab001
./file1
./file2
./file3
./file4
./file5
[root@node1 11]#还可以用-mmin选项,单位是分钟。查找创建时间低于50分钟的文件
[root@node1 11]# find -mmin -50
.
./Blab001
./blab001
./file1
./file2
./file3
./file4
./file5
[root@node1 11]# 这里查询多少分钟,大家可以根据自己的实际情况进行替换
1.6.4 基于文件类型的查询
根据文件的类型进行查询,用-type选项。常见的文件类型包括以下4种
(1)d:表示目录(文件夹)
(2)f:表示普通文件
(3)l:表示软链接(快捷方式)
(4)b:可用于存储数据的设置文件,如硬盘、光盘等
在当前目录中找出所有的文件夹
[root@node1 11]# find -type d
.
[root@node1 11]# 这里只找到表示当前目录的点“.”
在当前目录中找出所有的普通文件
[root@node1 11]# find -type f
./Blab001
./blab001
./file1
./file2
./file3
./file4
./file5
[root@node1 11]#1.6.5 基于文件权限的查询
根据文件的权限进行查询,用-perm选项。例如,我们要查找权限 为326的文件,查询时有3种用法,如图
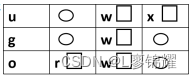
(1)326:必须完全匹配326,权限不能多也不能少,方块位置的权限都必须有,圆圈的位置不能有权限
(2)/326:文件的权限只要配置326中的一个权限即可,如图只要具备方跌中的一个权限就可以查询到
(3)-326:可以比326权限多,但是不能少,如图在方块位置的权限都满E的 情况下,圆圈的位置可以多
通过326来查询
[root@node1 11]# find -perm 326
./file1
[root@node1 11]#这里只有一个文件的权限完全满足326
通过/326来查询
[root@node1 11]# find -perm /326
.
./Blab001
./blab001
./file1
./file2
./file3
./file5
[root@node1 11]#这里file4没有查询到,因为file4 的权限中没有一个上面的图方块中的权限
通过-326来查询
[root@node1 11]# find -perm -326
./file1
./file3
[root@node1 11]#只要图中方块位置的权限都满兄,具不右圆圈中的权限就可以不符,这里找到file1和 file3